
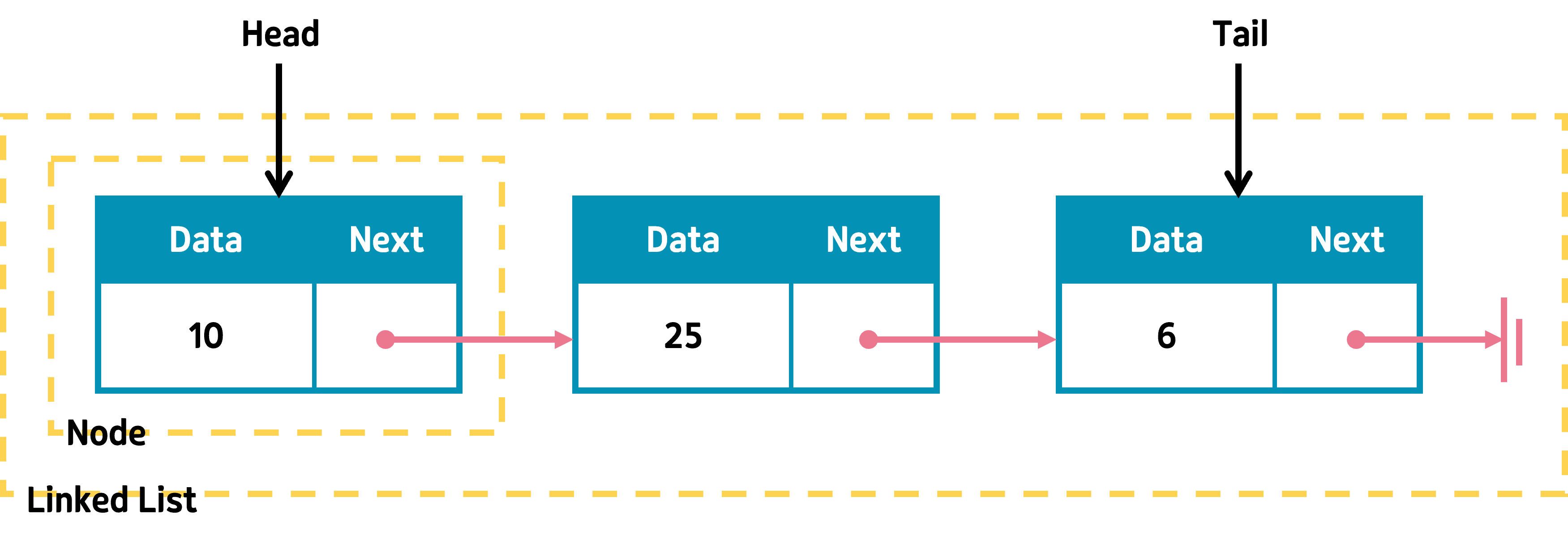
1. 연결 리스트(Linked List)
하나의 개체를 이루는 노드가 연결되어 리스트를 이루는 구조를 말한다.
노드에는 값을 담고 있는 '데이터'와 다음 노드를 가리키는 '링크' 정보를 저장하고 있는 것이 기본이다. '데이터'에는 숫자, 문자열, 또다른 연결리스트 등 다양한 형식을 가질 수 있다.
일반적으로 리스트의 맨 앞 노드를 헤드(Head), 맨 마지막 노드를 테일(Tail)이라고 한다.
배열과 연결리스트는 언뜻 비슷해 보이나, 차이점은 분명히 있다.
배열은 메모리의 연속한 위치에 저장되고, 연결 리스트는 각 노드가 임의의 위치에 저장된다.
또한 배열은 특정 원소를 지칭하는 것이 인덱스를 활용하는 등으로 간편하나(), 연결 리스트는 선형 탐색을 하듯 한 노드에서 다음 노드를 따라가야 한다().
하지만 배열보다 연결리스트는 비교적 삽입과 삭제가 용이하다.
연결 리스트는 앞뒤로 연결이 되었는지 아닌지 여부에 따라 단일(Singly) 연결 리스트와 이중(양방향, Doubly) 연결 리스트가 있다.
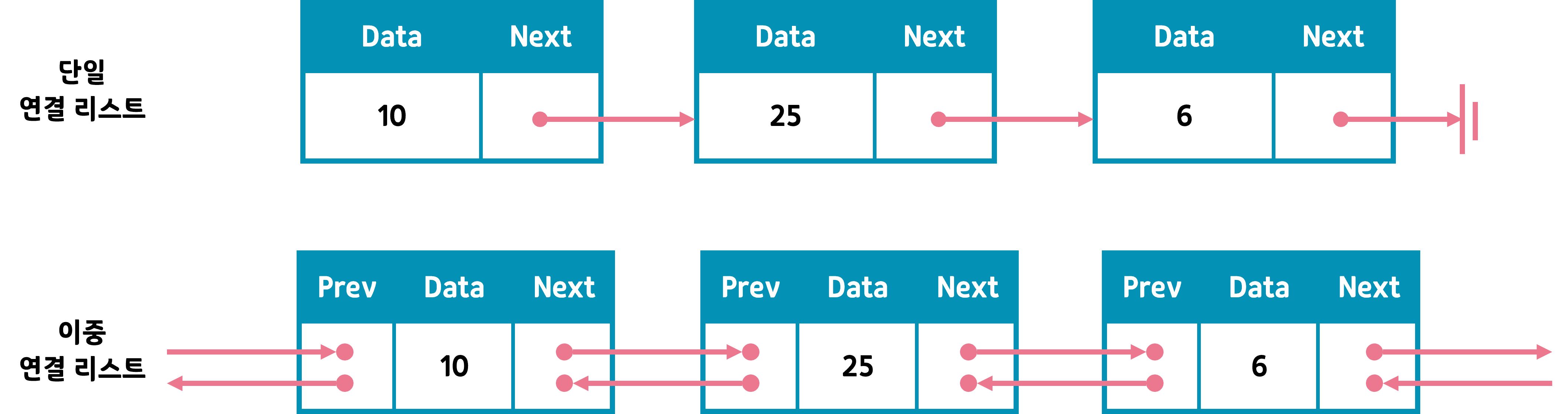
단일 연결 리스트는 한 방향으로만 연결되어 있다. 따라서 나와 연결된 다음 노드는 알 수 있지만 내 이전 노드는 알 수 없다. 그러므로 역행해서 바로 이동할 수도 없다.
반면 이중 연결 리스트는 이전과 이후 노드를 모두 저장하고 있어 양방향 이동이 자유롭다.
2. 단일 연결 리스트
2-1. 단일 연결 리스트의 구현
⓪ 노드와 연결리스트 클래스
노드 클래스는 데이터와 next를 저장할 멤버 변수를, 연결리스트 클래스는 노드의 개수, head, tail을 저장할 멤버 변수를 마련해둔다.
① 특정 원소(k 번째) 참조하기
시작 노드로부터 k번째에 있는 노드까지 next를 따라가며 위치를 이동시킨 뒤 해당 위치에서 데이터를 얻는다.
② 리스트 순회
시작 노드로부터 끝 노드까지 next를 따라가며 위치를 이동시킨다.
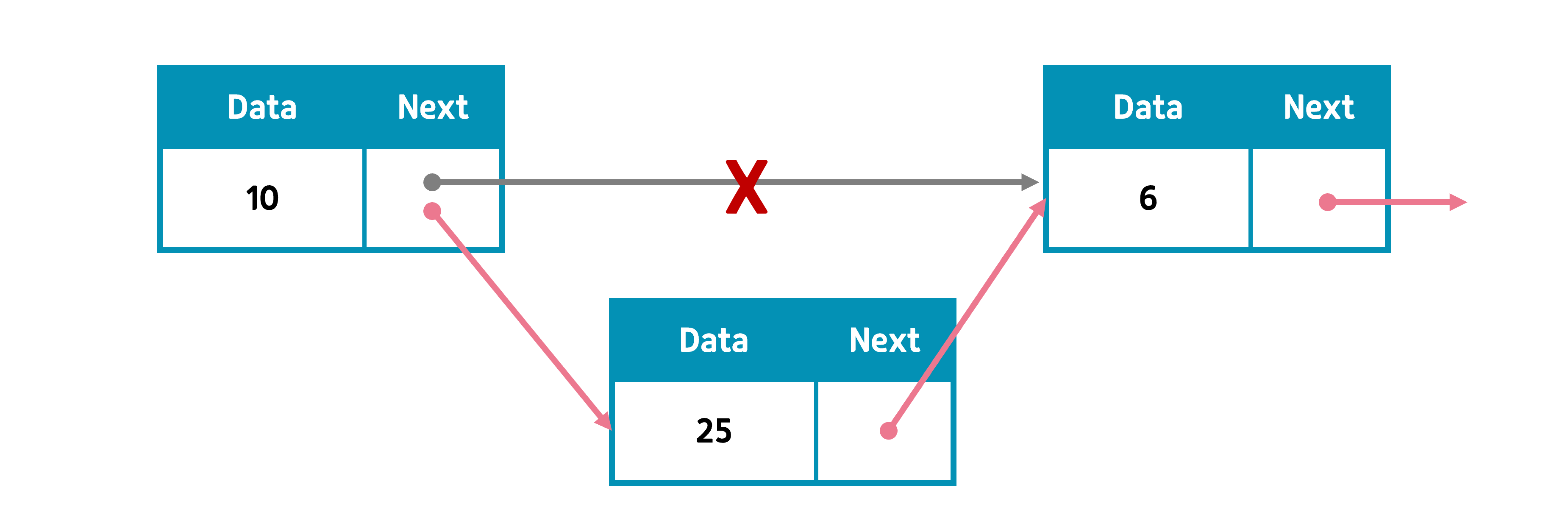
③ 원소 삽입
pos 노드가 있는 위치에 새 원소를 삽입하려면 pos의 직전 노드를 pre라 하고, pre의 next를 새 원소로, 새 원소의 next를 pos로 한다. pre가 pos를 가리키던 링크를 끊고 새 노드를 넣어주는 것이다.
단, 삽입하려는 위치가 리스트 맨 앞, 즉 head로 삽입하려면, head를 조정해야 한다.
반대로 맨 마지막에 삽입하려면 tail을 조정해야 한다. 이 경우 앞에서부터 순차적으로 탐색하기 보단 클래스에서 tail을 지정하고 있으므로 바로 찾아 링크를 조정하는 것이 빠르다.
빈 리스트에 삽입할 때는 head, tail을 동시에 조정해야 한다.
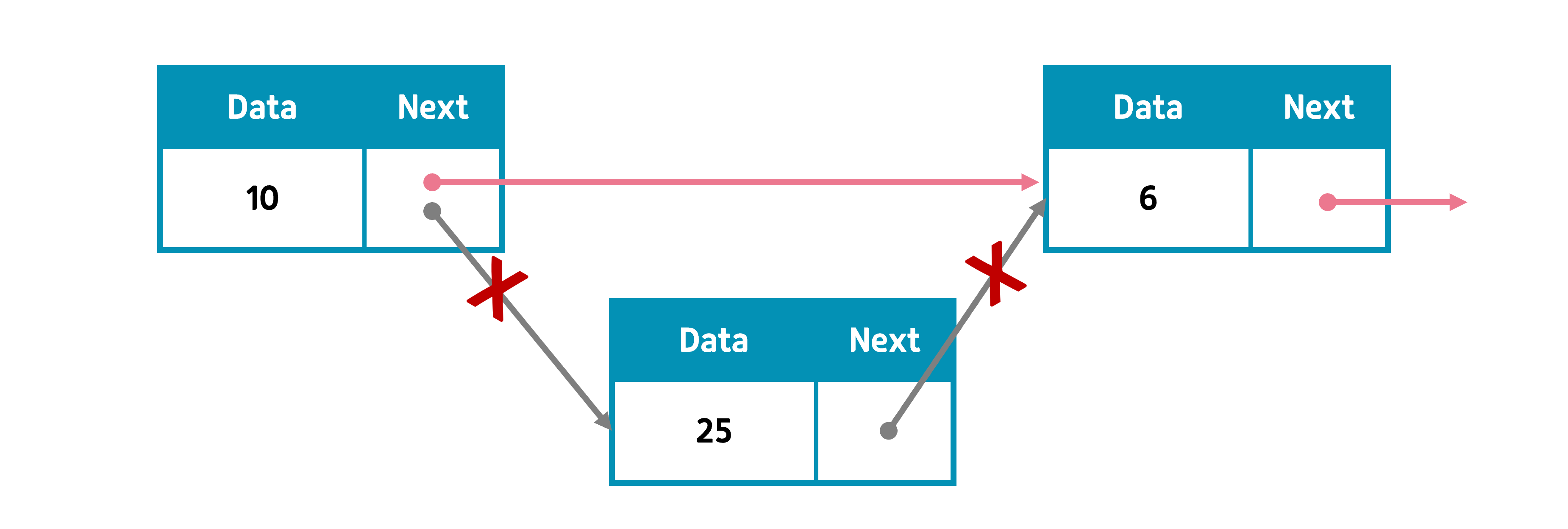
④ 원소 삭제
pos 노드가 있는 위치의 원소를 삭제하려면 pos의 직전 노드를 pre라 하고, pre의 next를 pos의 next로 한다. 노드의 링크를 끊어주었으므로 노드가 삭제된 것으로 본다.
단, 삭제하려는 노드가 head, tail일 때는 각각 head와 tail의 조정이 필요하다. 원소의 삽입과는 다르게 tail을 한 번에 삭제할 수는 없다. 노드는 자기 next만 알 뿐이므로 pre를 바로 알 수 없기 때문이다.
하나만 있는 노드, 즉 head와 tail이 같은 경우에는 head, tail을 모두 None으로 바꾸면 된다.
⑤ 두 리스트의 연결
두 연결리스트 L1, L2가 있다 할 때 L1에 L2를 붙이려면, L1의 tail의 next를 L2의 head로 하고, tail이 가리키는 곳을 L2의 tail로 바꾼다.
class Node:
def __init__(self, item):
self.data = item
self.next = None
class LinkedList:
def __init__(self):
self.nodeCount = 0
self.head = None
self.tail = None
def getAt(self, pos):
if pos < 1 or pos > self.nodeCount:
return None
i = 1
curr = self.head
while i < pos:
curr = curr.next
i += 1
return curr
def insertAt(self, pos, newNode):
if pos < 1 or pos > self.nodeCount + 1:
return False
if pos == 1:
newNode.next = self.head
self.head = newNode
else:
if pos == self.nodeCount + 1:
prev = self.tail
else:
prev = self.getAt(pos - 1)
newNode.next = prev.next
prev.next = newNode
if pos == self.nodeCount + 1:
self.tail = newNode
self.nodeCount += 1
return True
def popAt(self, pos):
if pos < 1 or pos > self.nodeCount:
raise IndexError
else:
if self.nodeCount == 1:
data = self.head.data
self.head = None
self.tail = None
elif pos == 1:
data = self.head.data
self.head = self.head.next
elif pos == self.nodeCount:
data = self.tail.data
prev = self.getAt(pos-1)
prev.next = None
self.tail = prev
else:
prev = self.getAt(pos-1)
data = prev.next.data
prev.next = prev.next.next
self.nodeCount -= 1
return data
def traverse(self):
result = []
curr = self.head
while curr is not None:
result.append(curr.data)
curr = curr.next
return result
2-2. dummy node가 추가된 형태
지금까지는 맨 첫 번째 노드를 head라고 했다. 그러나 아무 데이터도 담고 있지 않은 빈 노드, 즉 dummy node를 맨 앞에 두어 head로 삼을 수도 있다. 이 경우 몇몇 구현이 조금 더 편리해진다.
노드 클래스는 전과 같으므로 생략하고 표시했다.
class LinkedList:
def __init__(self):
self.nodeCount = 0
self.head = Node(None) # dummy head이다.
self.tail = None
self.head.next = self.tail
def traverse(self):
result = []
curr = self.head
while curr.next: # 첫 번째 head는 아무 내용이 없으므로 그 다음부터 탐색한다.
curr = curr.next
result.append(curr.data)
return result
def getAt(self, pos):
if pos < 0 or pos > self.nodeCount:
return None
i = 0
curr = self.head
while i < pos:
curr = curr.next
i += 1
return curr
def insertAfter(self, prev, newNode):
newNode.next = prev.next
if prev.next is None:
self.tail = newNode
prev.next = newNode
self.nodeCount += 1
return True
def insertAt(self, pos, newNode):
if pos < 1 or pos > self.nodeCount + 1:
return False
if pos != 1 and pos == self.nodeCount + 1:
prev = self.tail
else:
prev = self.getAt(pos - 1)
return self.insertAfter(prev, newNode)
def popAfter(self, prev):
curr = prev.next
if curr == None:
return None
elif curr == self.tail:
data = curr.data
prev.next = None
self.tail = prev
else:
data = curr.data
prev.next = curr.next
self.nodeCount -= 1
return data
def popAt(self, pos):
if pos < 1 or pos > self.nodeCount:
raise IndexError
else:
data = self.popAfter(self.getAt(pos-1))
return data3. 이중 연결 리스트
3-1. 이중 연결 리스트의 구현
위에서 잠시 설명한 바와 같이 이중 연결 리스트에서 한 노드는 prev와 next를 함께 갖는다. 따라서 노드 구조를 확장할 필요가 있으며, 탐색, 삽입, 삭제가 비교적 더 자유롭다.
또한 dummy head를 처음과 끝, 즉 head와 tail에 두면 더욱 편리하게 이용할 수 있다.
class Node:
def __init__(self, item):
self.data = item
self.prev = None
self.next = None
class DoublyLinkedList:
def __init__(self):
self.nodeCount = 0
self.head = Node(None)
self.tail = Node(None)
self.head.prev = None
self.head.next = self.tail
self.tail.prev = self.head
self.tail.next = None
def getLength(self):
return self.nodeCount
def concat(self, L):
self.tail.prev.next = L.head.next
L.head.next.prev = self.tail.prev
self.tail = L.tail
self.nodeCount += L.nodeCount
def traverse(self):
result = []
curr = self.head
while curr.next.next:
curr = curr.next
result.append(curr.data)
return result
def reverse(self):
rev = []
curr = self.tail.prev
while curr != self.head:
rev.append(curr.data)
curr = curr.prev
return rev
def getAt(self, pos):
if pos < 0 or pos > self.nodeCount:
return None
if pos > self.nodeCount // 2: # 찾으려는 위치가 중간보다 뒤쪽에 위치할 경우 tail부터 시작해 찾음
i = 0
curr = self.tail
while i < self.nodeCount - pos + 1:
curr = curr.prev
i += 1
else:
i = 0
curr = self.head
while i < pos:
curr = curr.next
i += 1
return curr
def insertAfter(self, prev, newNode):
next = prev.next
newNode.prev = prev
newNode.next = next
prev.next = newNode
next.prev = newNode
self.nodeCount += 1
return True
def insertBefore(self, next, newNode):
prev = next.prev
newNode.prev = prev
newNode.next = next
prev.next = newNode
next.prev = newNode
self.nodeCount += 1
return True
def insertAt(self, pos, newNode):
if pos < 1 or pos > self.nodeCount + 1:
return False
prev = self.getAt(pos - 1)
return self.insertAfter(prev, newNode)
def popAfter(self, prev):
next = prev.next.next
data = prev.next.data
prev.next = next
next.prev = prev
self.nodeCount -= 1
return data
def popBefore(self, next):
prev = next.prev.prev
data = next.prev.data
prev.next = next
next.prev = prev
self.nodeCount -= 1
return data
def popAt(self, pos):
if pos < 1 or pos > self.nodeCount:
raise IndexError
else:
return self.popAfter(self.getAt(pos).prev)