💡EDA?
- EDA(=탐색적 데이터 분석)란 수집한 데이터를 분석하기 전에 데이터 특성을 관찰하고 이해하는 단계이다.
수집한 데이터에 대해 잘 모르는 상태에서 무작정 분석을 할 수는 없다. 본격적인 분석 전에 데이터를 파악하는 시간이 필요하고, 이 과정에는 시각화 같은 도구를 통해 패턴을 발견하거나 데이트의 특이성을 확인하는 등이 포함된다.
EDA의 방법은 여러 가지가 있으며, 다양한 EDA를 진행하면서 나만의 방식을 연구해보면 좋겠다.
❗EDA와 preprocessing의 차이?
: EDA는 알고리즘을 돌리기 전에 비용을 줄이기 위해 체크하는 과정
: 전처리는 수집 데이터를 사용 전에 정제하고 가공하여 변환하는 과정
⚫ preprocessing 에는 cleaning, integration, transformation, reduction 과정이 있다.
▪️ cleaning : noise 제거, inconsistency 보정하는 과정 (결측치, Binning, Regression 등)
▪️ Integration : 데이터들을 분석하기 편하게 하나로 합치는 과정 (concat, merge 등)
▪️ Transformation : 데이터의 형태를 변환하는 작업. 즉, scaling (normalize 등)
▪️ Reduction : 데이터를 의미있게 줄이는 것 (PCA 등)
✍️ EDA의 목적
- 어떤 변수가 예측력이 높고 낮은지 확인 할 수 있다.
- 여러가지 시각화 도구 및 통계 기법을 사용해 데이터를 한눈에 파악하고 이해할 수 있다.
- 예측 모델 구축 전 적합한 통계 도구를 선택할 수 있다.
- 도출하고자 하는 결과의 기본이 되는 가설 검증 과정이 될 수 있다.
- 데이터를 다양한 각도에서 확인하며 패턴들을 발견하고, 더 좋은 가설을 세울 수 있다.
✍️ EDA의 종류
어떤 방식으로 EDA를 할 것인지는 2가지로 결정할 수 있다.
1. EDA의 타켓(데이터)가 일변량인지 다변량인지.
2. 시각화를 할 것인지, 비시각화를 할 것인지.
! 참고로 일변량과 다변량은 EDA를 통해 파악하려는 변수가 하나인지 여러개인지로 나뉜다.
일변량은 데이터를 설명하고 그 안에서 패턴을 찾는 것이 목적이라면
다변량은 여러 변수들간에 관계를 파악하는 것이 목적이다.
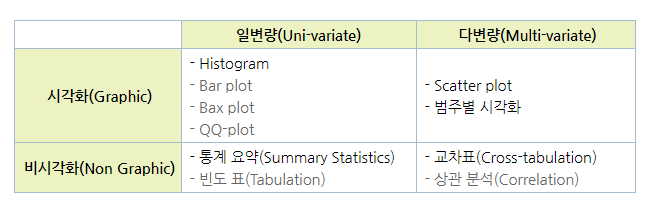
Uni-variate Non Graphic
- Histogram, Bar plot : 데이터 분포 확인, 이상치(Outlier) 파악에 주로 사용되며, 연속적인 데이터에 사용하면 효과적
- Bax plot : 이상치 파악, 데이터의 치우침 정도(symmetry) 파악에 효과적
- QQ-plot : 왜도(skewness)와 첨도(kurtosis)를 파악할 때 주로 사용
Uni-variate Graphic
- Summary Statistics : Numeric data 분석에 주로 사용
- Center (Mean, Median, Mode)
Spread (Variance, SD, IQR, Range)
Modality (Peak)
Shape (Tail, Skewness, Kurtosis)
Outliers
- Center (Mean, Median, Mode)
Multi-variate Graphic
- Scatter plot : 두 변수가 양적 변수일 때, 종속변수를 y축에 두고 빈도를 확인
- 범주별 시각화 : Category에 따라 일변량 시각화 적용
Multi-variate Non Graphic
- Cross tabulation : categorical data에 주로 사용
