한국어 자연어 처리
자연의 처리의 기본 요소는 단어 추출에서 시작. 텍스트의 단어를 통해 문장의 의미, 구성 요소 및 특징을 파악 가능. 문장을 단어 기준으로 나누면 인물, 시간 등을 의미하는 단어를 알 수 있음. 영어는 주로 띄어쓰기, 공백으로 나누면 원하는 단어를 쉽게 추출할 수 있음. 하지만 한국어에서의 단어의 기준은 명확하지 않음. 단어를 문법 단위 중 가장 기본이 되는 언어 단위의 하나이나 그 정의는 쉽지 않으며, 아직도 일정하게 내려지지 못하고 있다고 정의되어 있음. 한국어는 영어와 다르게 교착어 형태의 언어. 이 뜻은 우리가 생각하는 문장의 최소 단위인 단어는 의미적 기능을 하는 부분과 문법적인 기능을 하는 부분의 조합으로 구성되어 있음. '먹다', '먹었다', '먹는다' 에서는 '먹'이 의미를 뜻하고 나머지는 문법적인 기능을 하는 문자가 조합되어 있는 것. 자연어 처리에서는 의미적 기능을 하는 부분을 사용하는 것이 모델링과 분석에 있어서 더 중요. 데이터의 양이나 원하는 자연어 처리의 목적에 따라 문법적인 기능을 하는 부분을 전처리 하는 것이 필요. 따라서 한국어 자연어 처리에서는 단어의 의미적 기능과 문법적인 기능을 구분하는 것이 중요.
KoNLPy
한국어 자연어 처리에서 가장 중요한 것은 단어 추출이고 단어 추출 안에서는 의미적인 기능을 하는 부분과 문법적인 기능을 하는 부분을 구분해서 처리하는 것이 중요. 형태소 분석이 매우 중요함. 주어진 한국어 텍스트를 단어의 원형 형태로 분리해주는 작업. 의미적 부분 + 문법적인 부분 으로 나누는것.
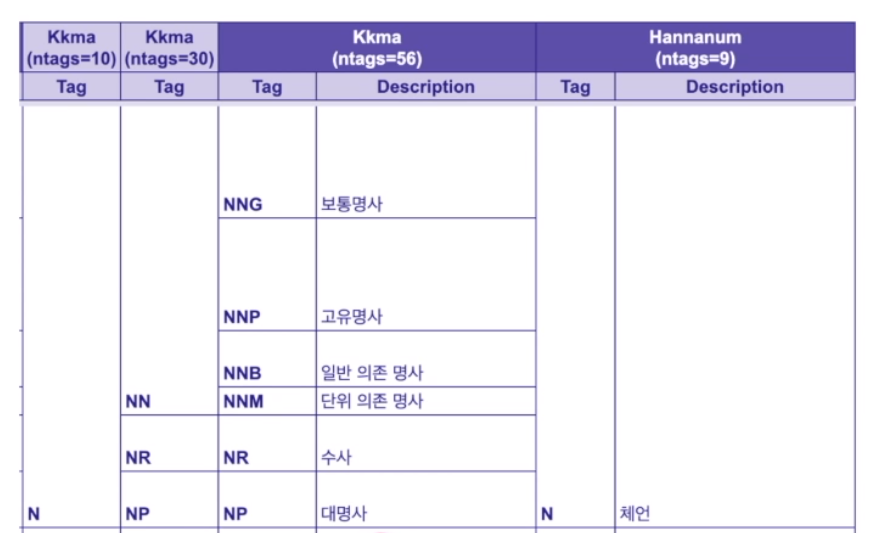
KoNLPy 는 이러한 형태소 분석을 해주는 파이썬 라이브러리. 여러 한국어 형태소 사전을 기반으로 한국어 단어를 추출해 줌. Mecab, 한나눔, 꼬꼬마, Komoran, Open Korean Text 5종류의 형태소 사전을 사용.
from konlpy.tag import Kkma, Okt
kkma = Kkma()
okt = Okt()
## 다른 형태소 분석기를 호출하는 방식. 당연히 import가 선행되어야 함.
hannanum = Hannanum()
mecab = Mecab()
komoran = Komoran(userdict=경로)Kkma 사용법
from konlpy.tag import Kkma
sent = '안녕 나는 엘리스야 반가워. 너의 이름은 뭐야?'
## 꼬꼬마 클래스 객체 만들기
kkma = Kkma()
## 꼬꼬마 형태소 분석기를 통해 문장 안에있는 명사들을 추출
print(kkma.nouns(sent))
# ['안녕', '나', '엘리스', '너', '이름', '뭐']
## 꼬꼬마 형태소 분석기를 통해 형태소 분석. 단어의 원형 형태로 구분
print(kkma.pos(sent))
# [('안녕', 'NNG'), ('나', 'NP'), ('는', 'JX'), ('엘리스', 'NNG'), ('야', 'JX'), ...]
## 꼬꼬마 형태소 분석기를 통해 문장을 구분해 리스트로 반환
print(kkma.sentences(sent))
# ['안녕 나는 엘리스야 반가워.', '너의 이름은 뭐야?']Okt 사용법
from konlpy.tag import Okt
sent = '안녕 나는 엘리스야 반가워. 너의 이름은 뭐야?'
## Okt 클래스 객체 만들기
okt = Okt()
## Okt 형태소 분석기를 통해 문장 안에있는 명사들을 추출
print(okt.nouns(sent))
# ['안녕', '나', '엘리스', '너', '이름', '뭐']
## Okt 형태소 분석기를 통해 형태소 분석. 단어의 원형 형태로 구분
print(okt.pos(sent))
# [('안녕', 'Noun'), ('나', 'Noun'), ('는', 'Josa'), ('엘리스', 'Noun'), ...]
## Okt 형태소 분석기를 통해 형태소를 분석할 때 stem = True를 넣어주면 분석한 형태소의 원형을 반환
print(okt.pos(sent, stem = True))
# ...('반갑다', 'Adjective')...주의할 점은 각각의 형태소 사전은 사전별 형태소 표기 방법 및 기준의 차이가 존재.
soyNLP
위에서 살펴본 KONLPY는 어떤 것들이 단어라고 명시가 된 사전을 통해 단어를 처리하고 형태소 분석을 하고 단어 추출을 진행함. 사전 기반의 단어 처리의 경우, 신종어나 자주 사용하지 않는 단어등 미등록 단어 문제가 발생할 수 있음.

SOYNLP는 학습 데이터 내 자주 발생하는 패턴을 기반으로 단어의 경계선을 구분.
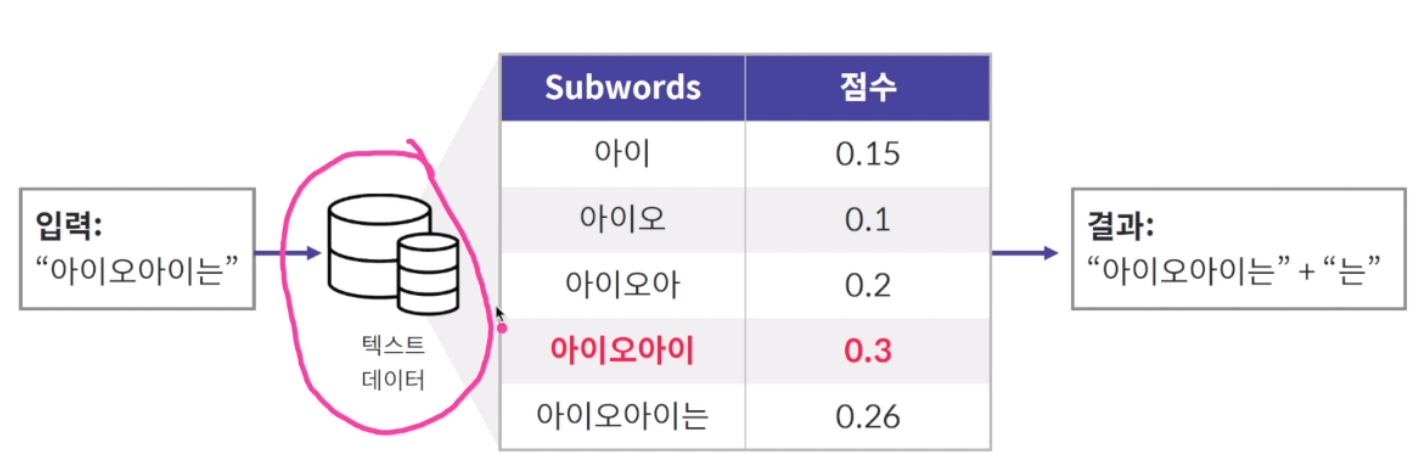
대량의 학습 데이터가 주어졌을 때 띄어쓰기 기준으로 토큰화해 해당 토큰 안에서 발생하는 문자열의 각각 문자의 조합들이 전체 데이터에서 얼마나 발생하는지 점수화를 진행.
데이터에서 단어의 기준을 학습하기 위해 몇가지 가정을 사용함.
(1) 단어는 연속으로 등장하는 글자의 조합이며 글자 간 연관성이 높다는 가정
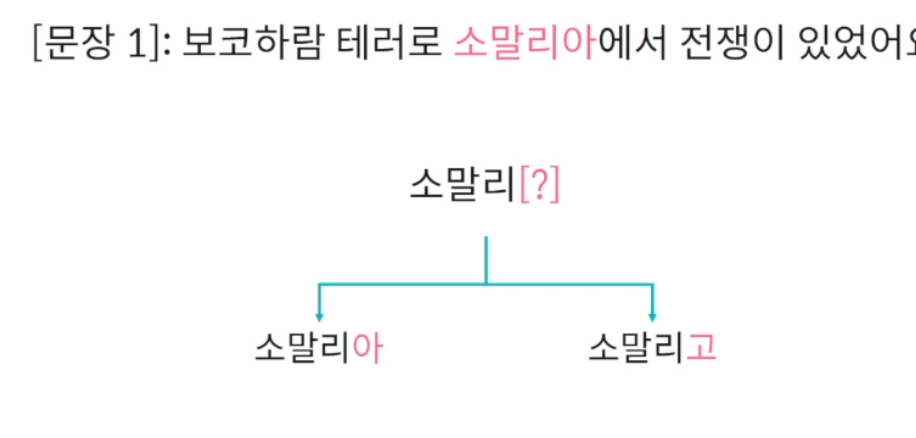
한마디로 대량의 학습 데이터가 주어지면 종종 오타가 발생을 하더라도 제대로 표기된 단어가 훨씬 많이 발생할 것이며 이 패턴을 학습할 때 제대로 표현된 단어가 더 많은 점수를 받게됨.
(2) 한국어의 어절(띄어쓰기 기준으로 나눈 것)은 좌-우 구조로 2등분 할 수 있음
좌측에서 발생하는 것은 주로 의미적 기능을 하고 우측에서 발생하는 것은 문법적 기능을 한다고 가정. 즉 의미적인 좌측을 뽑아내면 명사를 추출할 수 있다는 가정이기 때문에 명사추출에서 특히 유용하게 사용할 수 있음.
from soynlp.utils import DoublespaceLineCorpus
from soynlp.word import WordExtractor
from soynlp.noun import LRNounExtractor_v2
# 데이터 기반 패턴 학습
train_data = DoublespaceLineCorpus(학습데이터의 경로)
noun_extractor = LRNounExtractor_v2()
nouns = noun_extractor.train_extract(train_data)
# [할리우드, 모바일게임 ... ]
word_extractor = WordExtractor()
words = word_extractor.train_extract(train_data)
# [클린턴, 트럼프, 프로그램 ... ]문장 유사도
텍스트 처리를 하다보면 다양한 문장을 만나게 됨. 문장들 간 서로 얼마나 비슷한지, 다른지 살펴볼 수 있음. 문장 간 유사도는 공통된 단어 혹은 의미를 기반으로 계산.
자카드 지수
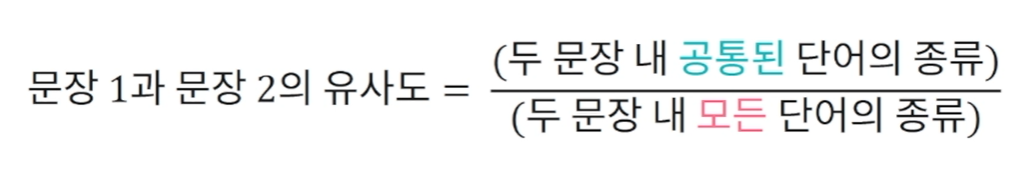
자카드(Jaccard) 지수는 문장 간 공통된 단어의 비율로 문장 간 유사도를 정의. 자카드 지수는 문장 간 유사도를 0~1 사이로 정의

자카드 지수는 순전히 단어의 기준으로만 문장 유사도를 비교하기 때문에 의미적인 내용을 부여할 수 없어서 종종 유사도의 의미가 정확히 나오지 않을 수 있음. 하지만 무엇보다 쉽고 간단하고 빠르게 사용할 수 있음.
(2) 코사인 유사도
코사인 유사도는 문장 벡터 간의 각도를 기반으로 계산. 많이 사용.
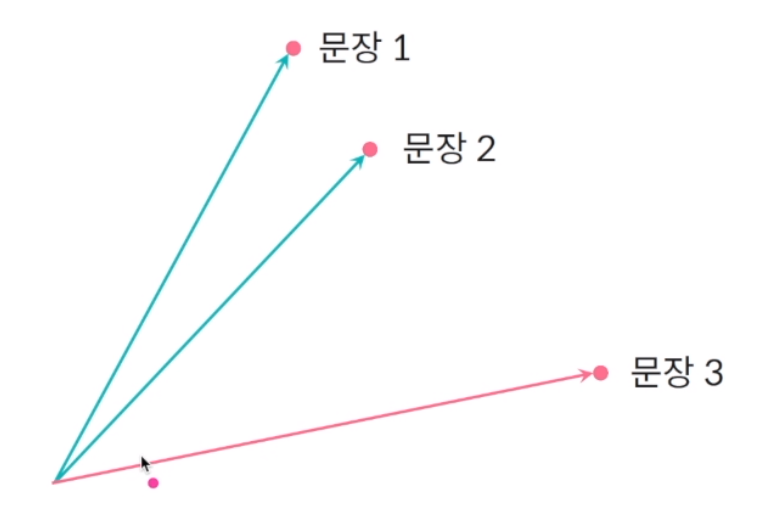
임베딩 벡터는 결국 어떠한 문장이나 문서, 단어 등을 수치형 벡터로 표현하고 벡터간의 각도를 사용해 유사도 비교. 문장들을 벡터로 표현한 후 문장 간 각도가 얼마나 작은지에 따라 비슷한 문장이라는 가정하에 유사도 계산.
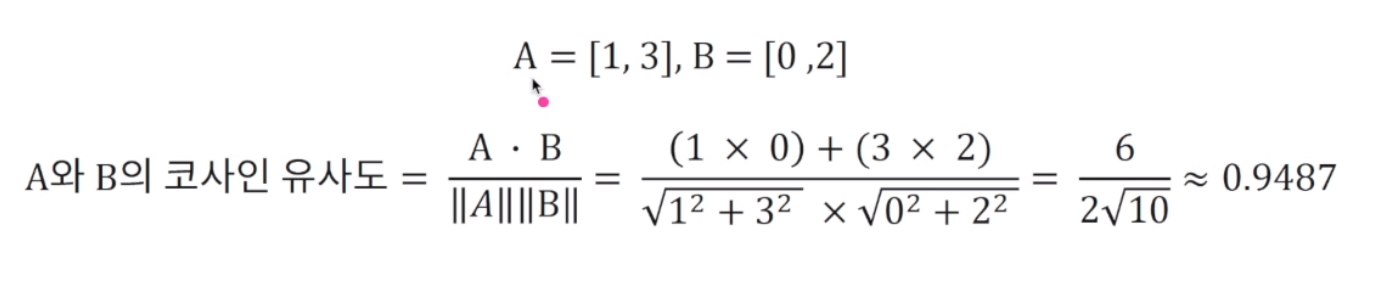
코사인 유사도는 벡터 간 내적을 사용해서 계산. 동일한 위치에 있는 값들을 모두 곱한 후 더함.
벡터의 길이 = 각각 항목을 제곱한 후 모든 항목을 더해서 루트. 그 후 문장의 길이끼리 곱해줌.
WORD2VEC이나 FASTTEXT에서 SIMILARITY에서 임베딩 벡터간 유사도를 계산하는데 그 기준이 바로 코사인 유사도.
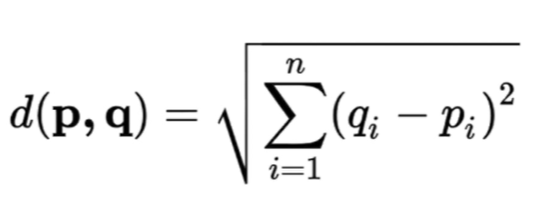
유클리드 거리 : 벡터안에서 같은 컬럼에 해당하는 값들을 서로 뺀 후 제곱해서 모두 더하고 루트.
자연어처리는 대부분의 경우 코사인 유사도를 많이 사용. 그 이유는 코사인 유사도는 고차원의 공간에서 벡터 간의 유사성을 잘 보존하는 장점이 있기 때문. 단어, 문장, 문서를 임베딩 벡터, 즉 벡터화 하기 때문에 벡터가 굉장히 긺. 즉 고차원의 공간에서 벡터가 존재하게 됨. 고차원에서는 앞선 유클리드 거리 보다는 각 벡터간의 각도를 사용하는 코사인 유사도가 더욱 잘 보존. 기본적인 유사도는 코사인 유사도를 사용.
