TIL
1.[TIL] 2021.09.14 TUE
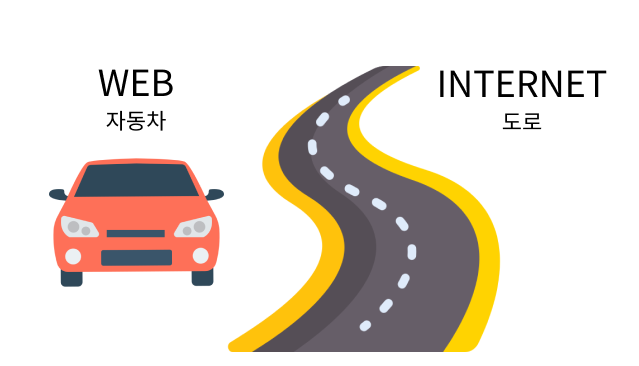
WEB/InternetVS CodeHTML/CSS WEB이 한 대의 자동차라면 Internet은 도로. Internet 안에 WEB이 부분으로 존재. clien와 서버 모두 host. 웹 서버 컴퓨터에 저장된 파일(index.html)을 웹 브라우저 컴퓨터가 요청. 웹
2.[TIL] 2021.09.15 WED
HTML 레이아웃 구성1-1. 실제 화면 구성과 태그 구성 : 목차, 본문, 부록1-2. HTML 태그의 2가지 속성 : Block, InlineCSS2-1. HTML에 CSS 적용하는 방법 : Inline, Internal, External2-2. CSS 적용 우선순
3.[TIL] 2021.09.16 THU
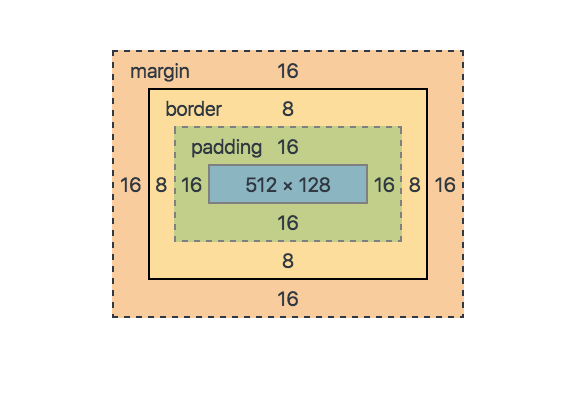
HTML1-1.박스 모델CSS2-1. 마진 병합 현상 : 형제, 부모-자식 2-2. 레이아웃에 영향을 미치는 속성 : display, float, clear(1) content : 텍스트, 이미지 등 실질적인 내용 부분(2) padding : 내용과 테두리 사이의 간격
4.[TIL] 2021.09.17 FRI
CSS1-1. 움직이는 웹사이트 : transition, transform, animation1-2. 반응하는 웹사이트 : media query모바일 웹 만들기
5.[TIL] 2021.09.18 SAT

Linux:컴퓨터 운영체제. 자유 소프트웨어와 오픈 소스 개발의 가장 유명한 표본.구조하드웨어 < kernel <kernel 하드웨어 제어, 소프트웨어와 커뮤니티하게하는 시스템 관리자shell 명령어 해석기. 사용자의 명령을 해석해 kernel에 전달.응용
6.[TIL] 2021.09.26 SUN
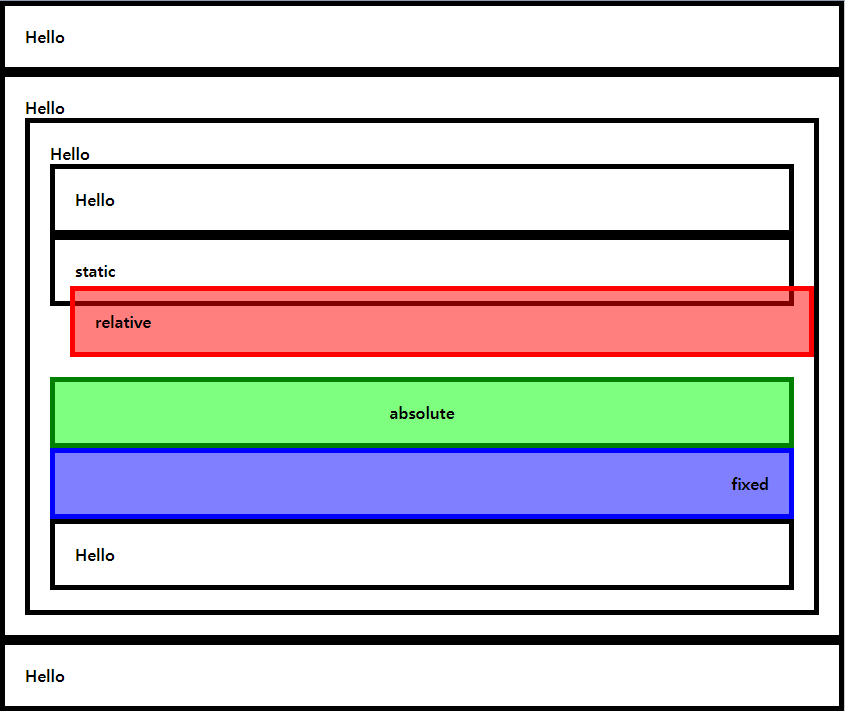
💻 오늘 배운 내용1\. CSSZ축 : Z축을 사용한다는 것은 평면이 아닌, 3차원적 공간을 사용한다는 것을 의미. 따라서 POSITION이 3차원인 경우에만 사용할 수 있음position이 3차원인 경우는? relative, absolute, fixed알아두면 좋은
7.[TIL] 2021.10.12 TUE
기본적으로 Component와 원하는 값을 넘겨줄 때 사용하며 넘겨줄 수 있는 값은 변수, 함수, 객체, 배열 등 JavaScript의 요소라면 제한이 없음. 주로 Component의 '재사용'을 위해 사용함.또한 props는 읽기 전용. 임의로 변경해서 사용하지 말자
8.[TIL] 21.12.04 SAT
split을 하면 알아서 리스트 안에 넣어줌.: 한 줄만 보고싶다면 readline! 다 보고싶다면 readlines!▶ 가장 위의 첫번째 줄만 출력▶ 모든 줄을 출력▶ 모든 줄을 출력
9.[데이터분석] 데이터 분석 기초2
{ key : value }key : 값을 찾기 위해 넣어 주는 데이터value : 찾고자 하는 데이터
10.[데이터분석] 고급 파이썬
함수를 생성할 때 사용하는 예약어로 def와 동일한 역할을 함. 자주 사용하지 않거나 복잡하지 않을 때, 한 줄로 간결하게 표현하고 싶을 때 사용함.debug용 명령어. True 혹은 False로 반환되며 두 값이 같으면 통과, 아니면 에러를 발생시켜서 테스트할 때 많
11.[PYTHON] Numpy

Numerical Python. 대규모 다차원 배열을 다룰 수 있게 도와주는 라이브러리. 왜 필요한가? 데이터의 대부분은 차원이 다른 숫자 배열로 볼 수 있기 때문.파이썬 리스트에는 int, float, str이 한 번에 들어갈 수 있다면 numpy에서는 불가능. 즉,
12.[PYTHON] PANDAS
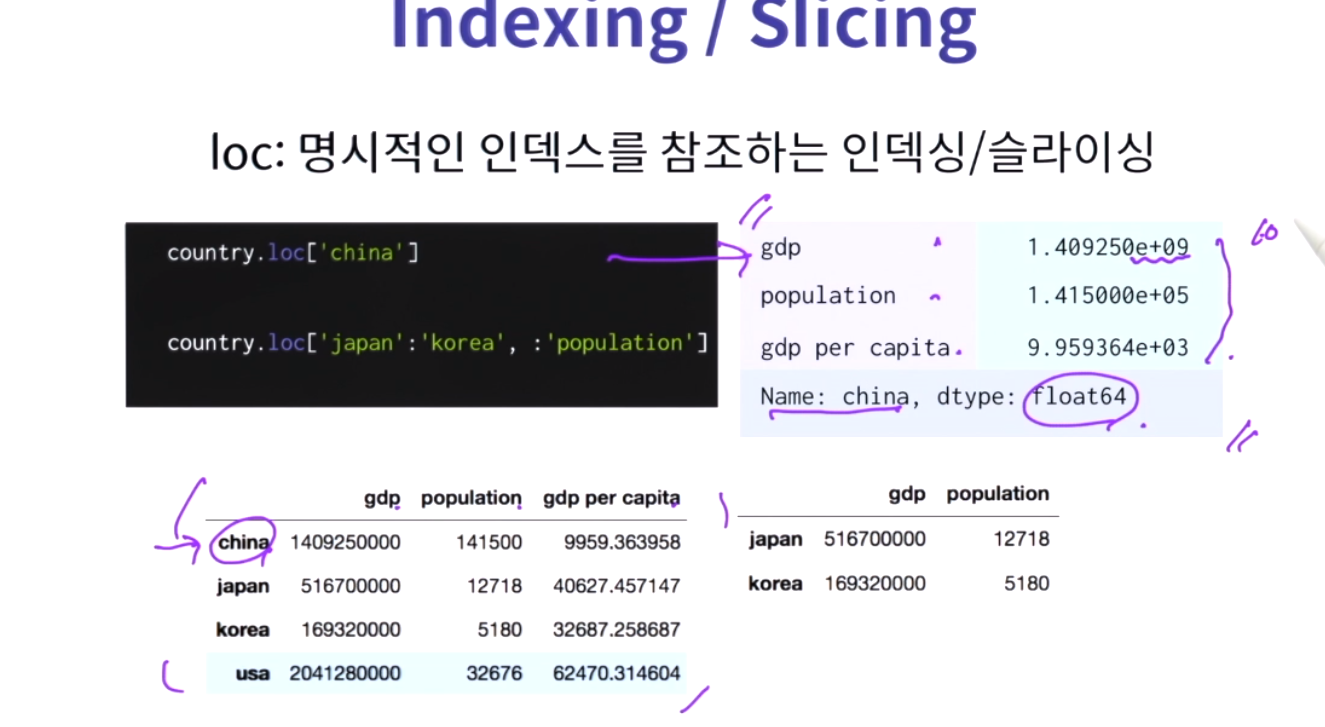
구조화된 데이터를 효과적으로 처리하고 저장할 수 있는 라이브러리. Numpy를 기반으로 만들어져 다양한 기능들을 제공함. 특히 행과열을 가진 2차원과 엑셀 데이터를 효과적으로 처리. 데이터베이스 프레임워크 사용자들에게 익숙하고 강력한 연산을 제공. numpy array
13.[bag of words]
텍스트를 기계가 이해할 수있는 수단으로 만들어주는 것. 형태로 바꿔주는 작업. : Bag of Words텍스트 데이터 전처리 : NLP특수 문자 제거, 토큰화. 일반적으로는 공백으로 잘라내는 것. 한국어는 조사, 형태소로 나누는 작업도 필요함. bow 모델에서 순서는
14.[머신러닝]k-means클러스트링
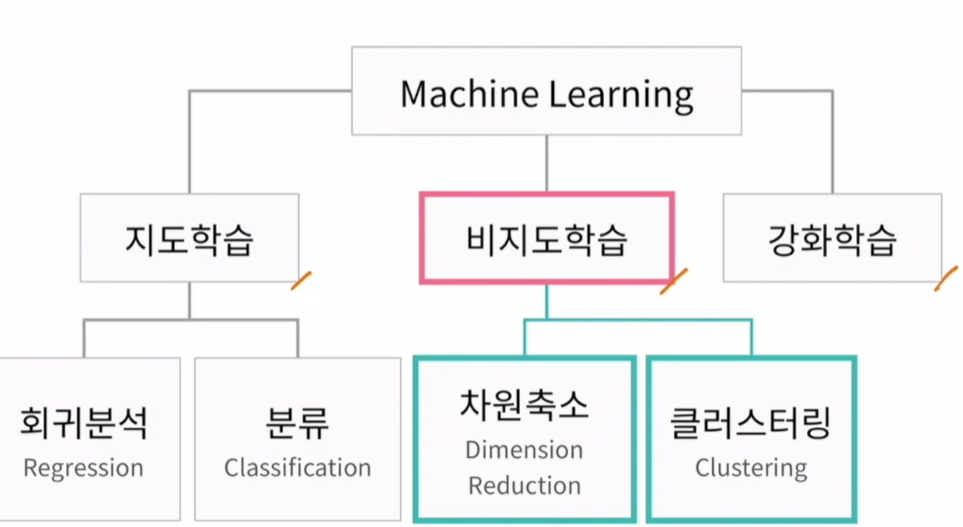
비지도학습 : 회귀분석 : 알고이거나 예측하기 위한 값. 키가 주어졌을때 몸무게 예측. 선형.분류 : 클래스 같은 것 나누는 것. 새로운 것이 왔을 때 어떤 클래스인가. 나이브베이즈.비지도 : 값이 없어도 할 수 있는것. 지도학습 : 얻고자 하는 답으로 구성된 데이터비
15.[딥러닝] 퍼셉트론
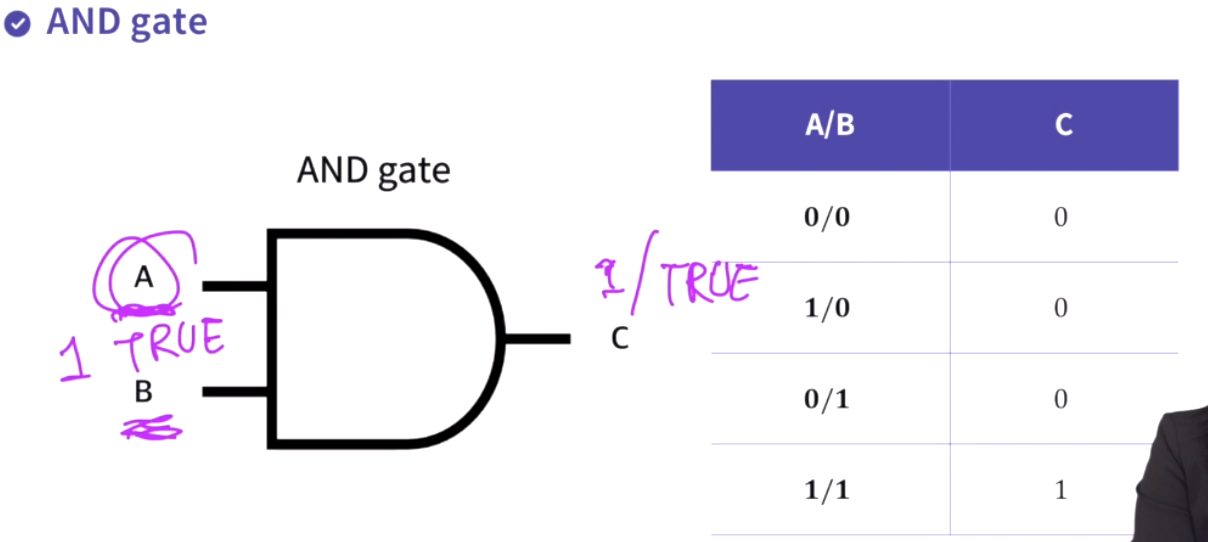
퍼셉트론신경망 이전에는 명시적 프로그래밍. if() then {} 룰이 명확하면 잘 되지만 많은 exception이 있어 불가능. 자율 주행 자동차는 직접 사람이 일일이 기계에 입력을 하고 가르치지 않아도 기계가 스스로 사람처럼 일할 수 있도록 해줘야함. 데이터가 들어
16.[딥러닝] 학습 방법과 텐서플로우
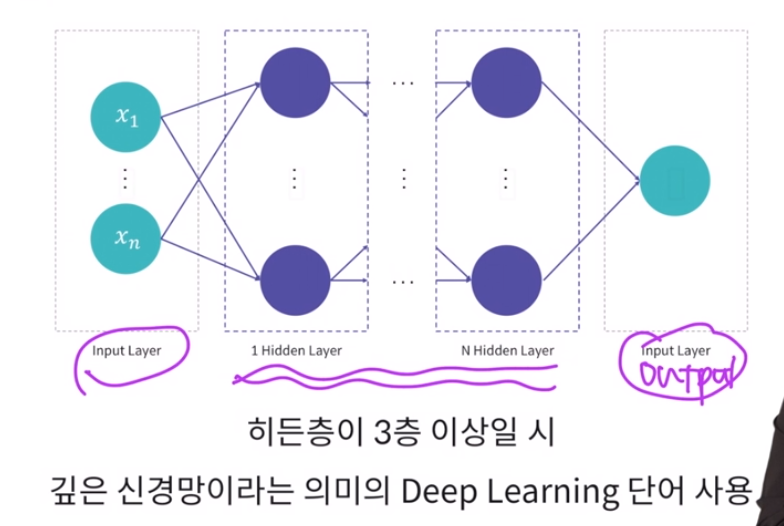
Node = x1, x2 ...가중치(weight) : 노든간의 연결강도loss function을 최소화하기 위해 최적화 알고리즘을 적용input -> hidden -> output\-> 는 weight를 의미. loss function : 예측값과 실제값간의 오차값o
17.[딥러닝] 딥러닝 학습의 문제점
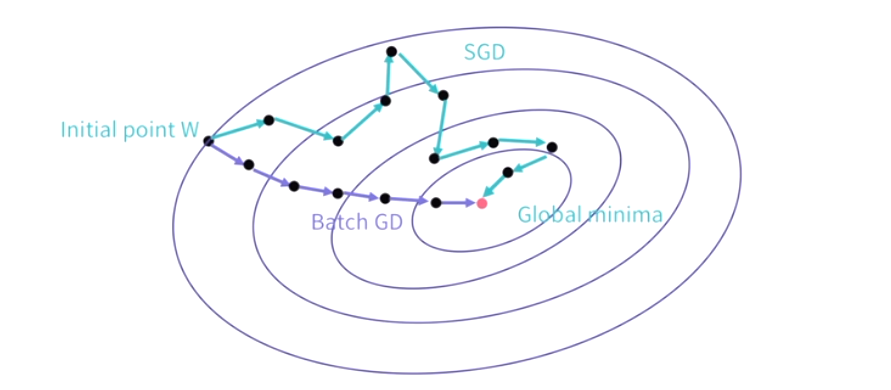
학습 속도 문제 : 데이터의 개수가 폭발적으로 증가하여 딥러닝 모델 학습 시 소요되는 시간도 함께 증가기울기 소실 문제 : 더 깊고 더 넓은 망을 학습시키는 과정에서 출력값과 멀어질 수록 학습이 잘 안되는 현상 발생.초기값 설정 문제 : 초기값 설정 방식에 따른 성능
18.[CNN] 이미지 데이터

CNN은 대표적인 딥러닝 모델. 이미지 분석 작업에 최적화된 성능을 보임. CNN이 이미지 데이터를 잘 학습하는 원리를 알기 위해 이미지 데이터를 이해할 필요가 있음. EX. 사진, 그림, 게임 그래픽, JPG, PNG. 사진, 그림등을 컴퓨터로 저장한 데이터.디지털
19.[CNN] Convolution 연산
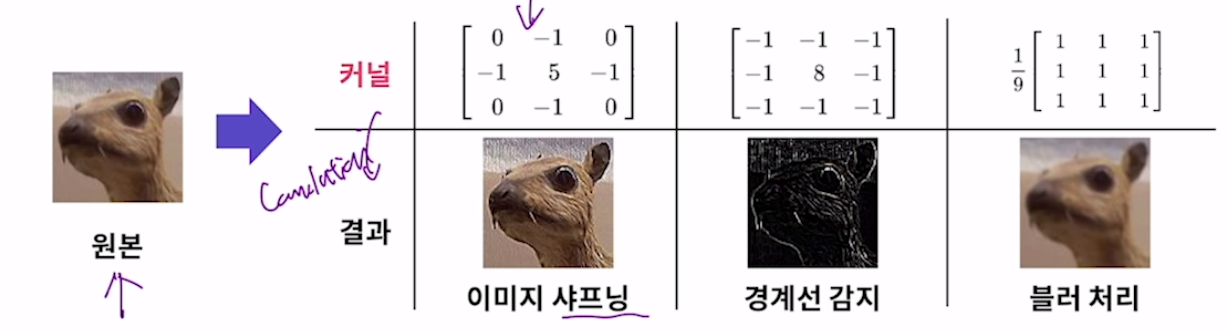
퍼셉트론은 FULLY-CONNECTED LAYER. 1차원 데이터를 요구. 이미지를 단순하게 1차원으로 바꾸면 2차원상에서 가지는 정보를 포기해야 함. (이미지 내 사물간의 거리 관계 등, 색의 변화:특히 세로로 변하는 상황) 즉, 공간 정보가 무너짐. 따라서 이미지
20.[RNN] RNN
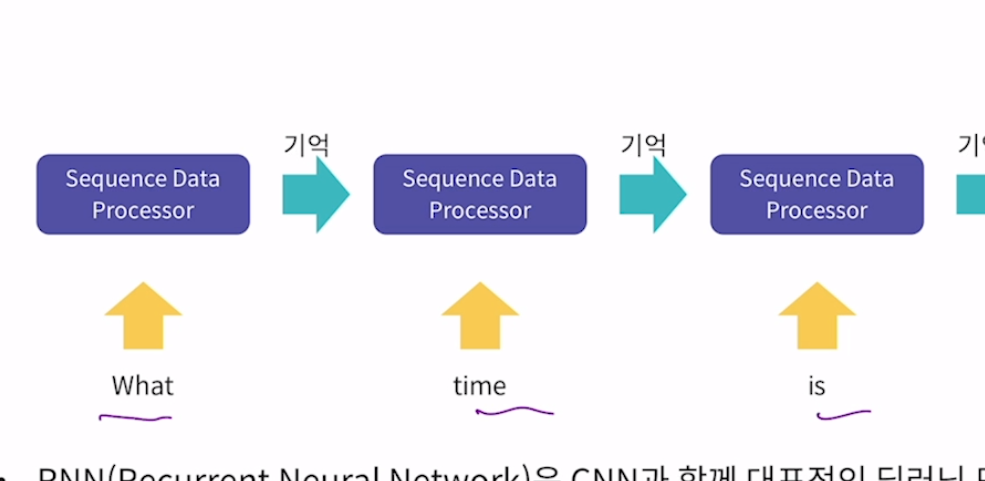
RNN은 CNN과 함께 대표적인 딥러닝 모델. 시계열 데이터 같은 순차 데이터 처리를 위한 모델. RNN이해에는 순차 데이터가 가지는 특징의 이해가 필요. 문장같이 일렬로 이루어진 데이터를 보고 그 다음 무엇이 나올지 예측하는 방식으로 많이 활용. 순서(ORDER)를
21.[RNN] LSTM과 GRU
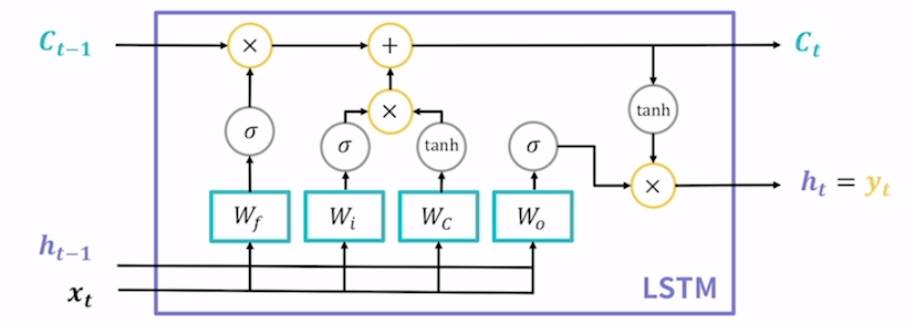
vanila rnn의 기울기 소실 문제를 해결하고자 등장. Long Short Term Memory(장단기 메모리)의 약자. vanila rnn은 기울기 소실 때문에 장기 의존성을 기억할 수 없다는 단점이 있었는데 해당 모델은 장기 의존성과 단기 의존성을 모두 기억할
22.[CNN/RNN 활용]

Tensorflow: 구글이 개발. 사용이 복잡했으나 2.0 이후 개선됨. colab에서 간편하게 gpu 사용을 지원. Tensorboard를 통한 강력한 시각화. TF lite를 통한 간편한 모바일 변환Keras : Tensorflow의 모델 구현과 학습을 편리하게
23.[CNN, RNN] 모델 서비스하기
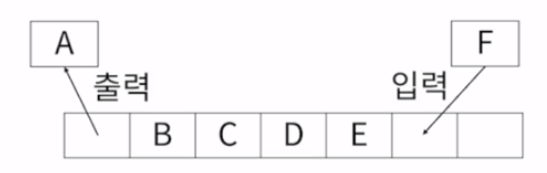
(1) 모델의 구조 : 레이어의 종류와 형태 / 입력 값의 형태 (행렬의 틀과 연산방법에 대한 정보)(2) 가중치 값 : 각 레이어의 행렬에 저장된 실제 float32 실수 값들 / 모델의 학습 = loss 값이 낮아지도록 가중치 값을 수정하는 과정의 연속 / 같은 모
24.[자연어처리] 텍스트 전처리 및 단어 임베딩
자연어 처리(Natural Lnguage Processing, NLP) 는 컴퓨터를 통해 인간의 언어를 분석 및 처리하는 인공지능의 한 분야. 인간의 언어는 다양한 구조, 체계, 규칙, 문법 등 복잡한 요소들로 구성되어 있음. 자연어 처리는 이러한 요소들을 컴퓨터에게
25.[자연어처리] ... 문제
지시사항IMDB dataset이 들어 있는 text.txt 파일을 확인해 봅니다. 파일 내 각 줄은 하나의 리뷰에 해당합니다.텍스트 데이터를 불러오면서 단어가 key, 빈도수가 value로 구성된 딕셔너리 변수인 word_counter를 만드세요.파일 내 각 줄 끝에는
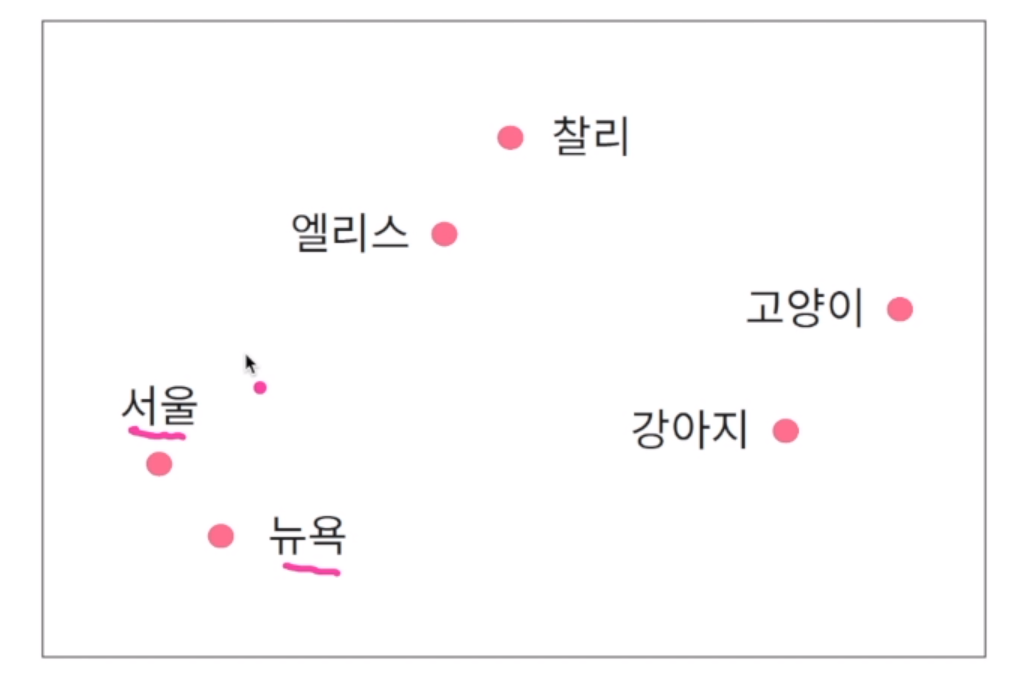
26.[자연어처리] 한국어 자연어 처리 및 문장 유사도
자연의 처리의 기본 요소는 단어 추출에서 시작. 텍스트의 단어를 통해 문장의 의미, 구성 요소 및 특징을 파악 가능. 문장을 단어 기준으로 나누면 인물, 시간 등을 의미하는 단어를 알 수 있음. 영어는 주로 띄어쓰기, 공백으로 나누면 원하는 단어를 쉽게 추출할 수 있음
27.[자연어처리]2 ...실습...
KoNLPy를 통한 한국어 전처리KoNLPy는 한국어 형태소 사전을 기반으로 한국어 단어를 추출해 주는 파이썬 라이브러리입니다.이번 실습에서는 KoNLPy를 사용하여 한국어 문장 간 유사도 측정용 데이터셋인 KorSTS 데이터셋을 전처리하도록 하겠습니다.변수 sent에
28.[자연어처리] 감정분석

(1) 객관적인 정보 : 뉴스, 백과 사전 같은 텍스트(2) 주관적인 평가나 감정 : 리뷰, 소설 같은 텍스트감정 분석이란 주관적인 평가나 감정이 들어가있는 문서를 대상으로 함. 대량의 텍스트가 있는 경우, 일일이 데이터를 하나씩 살펴보고 판단하기 어려움. 모델링을 통
29.[자연어처리2] 문서 유사도 및 언어 모델

문서 : 문서는 다양한 요소와 이들의 상호작용으로 구성. 단어 -> 형태소 -> ... -> 문장 -> ... -> 문단가장 기본 단위인 단어 조차 문서와 관련된 다양한 정보를 포함.문서 유사도를 측정할 때는 가장 기본 단위인 단어를 활용하여 문서를 표현. 문서 유사도
30.[TIL] 22.02.18 BERT 뜯어보기
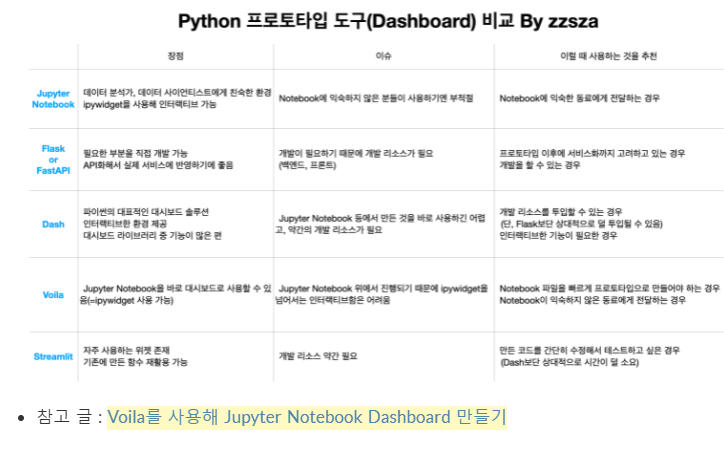
https://zzsza.github.io/mlops/2021/02/07/python-streamlit-dashboard/input처음 오류bert-extractive-summarization 컴퓨터에서 실행해보기해당 모델 ai_modeltest 브랜치 만들어
31.[TIL]22.02.19 (SAT) Colab으로 Bert 학습

오늘 내가 해보려고 한 것은 COLAB으로 BERT 학습시키기!하지만! 무참히 패배했다.wget해서 가져올 때... 꼭 raw 다운로드 하렴..python3.7 -m pip install tensorflow-gpu==1.15.0ptrhon entry"paragraphs
32.[TIL] 22.02.21 Git hub 폴더 클릭 안됨 해결법
원래 사용했던 모델은 누군가 재수정해둔것이라 다소 우리 팀 프로젝트의 입맛과 맞지 않았음. 그래서 원본을 찾아가 논문을 읽어보며 구현해보려 했지만 너무 어려워서 성과가 나온게 없는 것 같음.알면 알수록, 하면 할수록 내가 너무 무지하고 할건 많은데 시간은 조급하다는 생