구조화된 데이터를 효과적으로 처리하고 저장할 수 있는 라이브러리. Numpy를 기반으로 만들어져 다양한 기능들을 제공함. 특히 행과열을 가진 2차원과 엑셀 데이터를 효과적으로 처리. 데이터베이스 프레임워크 사용자들에게 익숙하고 강력한 연산을 제공.
Series
numpy array가 보강된 형태로 데이터와 인덱스를 가지고 있음.
import pandas as pd
data = pd.series([1, 2, 3, 4], index = ['a', 'b', 'c', 'd'])
data['b']데이터 앞에 인덱스가 0, 1, 2, 3으로 붙음. array의 보강 형태이기 때문에 데이터 타입도 있음. 따라서 인덱스로 접근이 가능하다는 것이 가장 큰 특징. 딕셔너리로도 변환 가능.
population = pd.series(population_dict)딕셔너리의 키값들이 시리즈의 인덱스가 됨.
DaTAfRAME
여러개의 sERIES가 모여서 행과 열을 이룬 데이터. 딕셔너리로 만들 수 있다. SERIES도 넘파이 어레이처럼 연산자를 쓸 수 있다.
저장과 불러오기
.to_csv
.to_excel
country = pd.read_csv("파일명")
loc[]
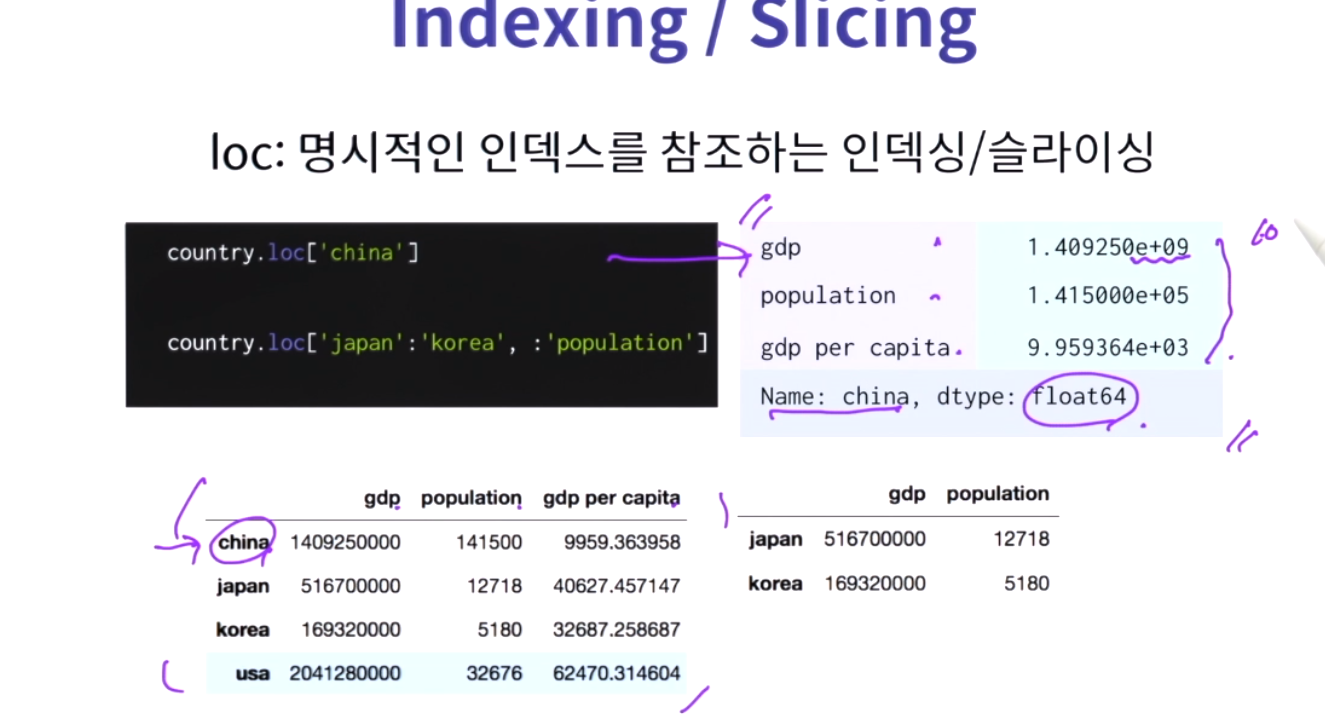
명시적인 인덱스를 참조하는 인덱싱/슬라이싱.
데이터프레임.loc['china']
데이터프레임.loc['japan':'korea', :'population'] : 데이터프레임으로 반환
iloc은 파이썬 스타일로 정수로 인덱스를 인덱싱/ 슬라이싱 할 수 있게 해줌
데이터프레임.iloc[1:3, :2] : 데이터프레임
데이터프레임.iloc[0] : 시리즈
데이터프레임에 새 데이터 추가/수정
리스트로 추가하는 방법

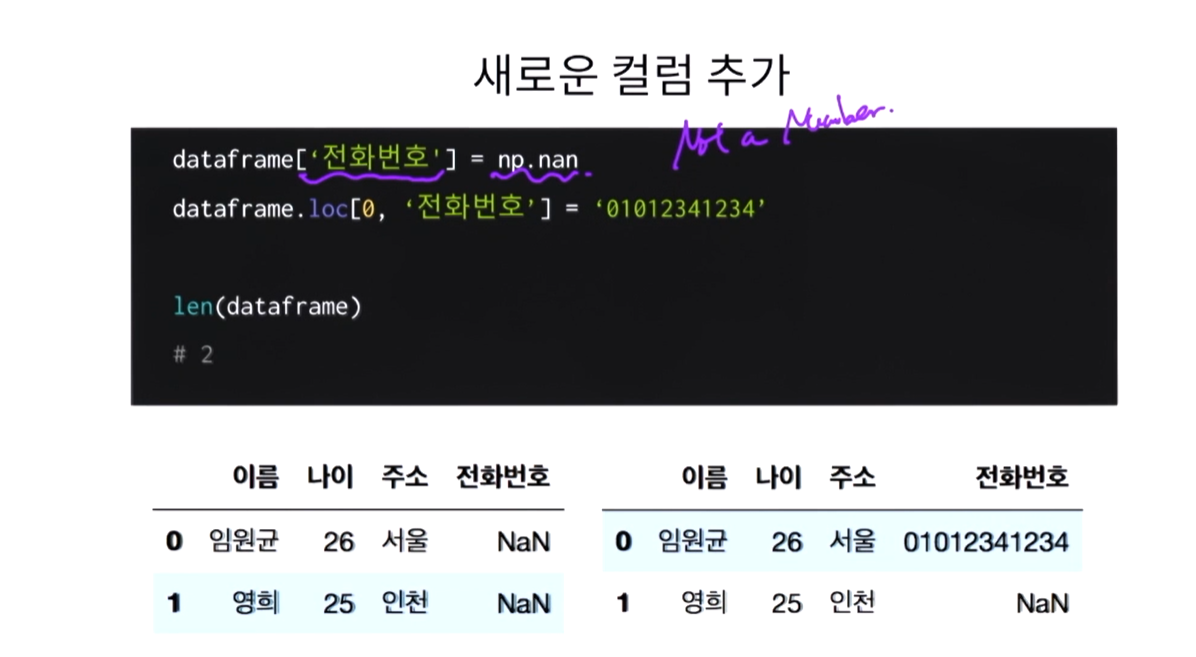
첫번째는 값이 nan인 컬럼을 추가한 것. 그 이후 값을 바꿔준 것.

누락된 데이터 체크
.isnull()
.notnull()
.dropna() : 빈값행완전히삭제
.fillna('채울값') : 값을 채워주세요
A.add(B, fill_value=0) 빈 값은 0으로 채워주세요
array에서 활용했던 사칙연산은 물론, sum, mean을 활용할 수 있다.
sort_values('컬럼명', ascending=False) 그러면 인덱스가 막 뒤바뀜. 값대로 변하는거라서. ascending False는 내림차순으로 정렬.
컬럼을 여러개 적어서 넣으면 먼저 쓴 컬럼에 대해서 정렬을 하고 만약 첫번째 컬럼에 같은 값이 있다면 그 때는 두번째 컬럼을 참고해서 정렬.
masking 연산
df[(df["a"] < 0.5) & (df["b"] > 0.3)]
df.query("a < 0.5 and b > 0.3")apply
함수로 데이터 처리하기
.replace({"키":값}, inplace = True)
inplace = True를 넣으면 시리즈로 반환되는 것이 아니라 바로 데이터 프레임으로 바꿔주는 것
멀티인덱스
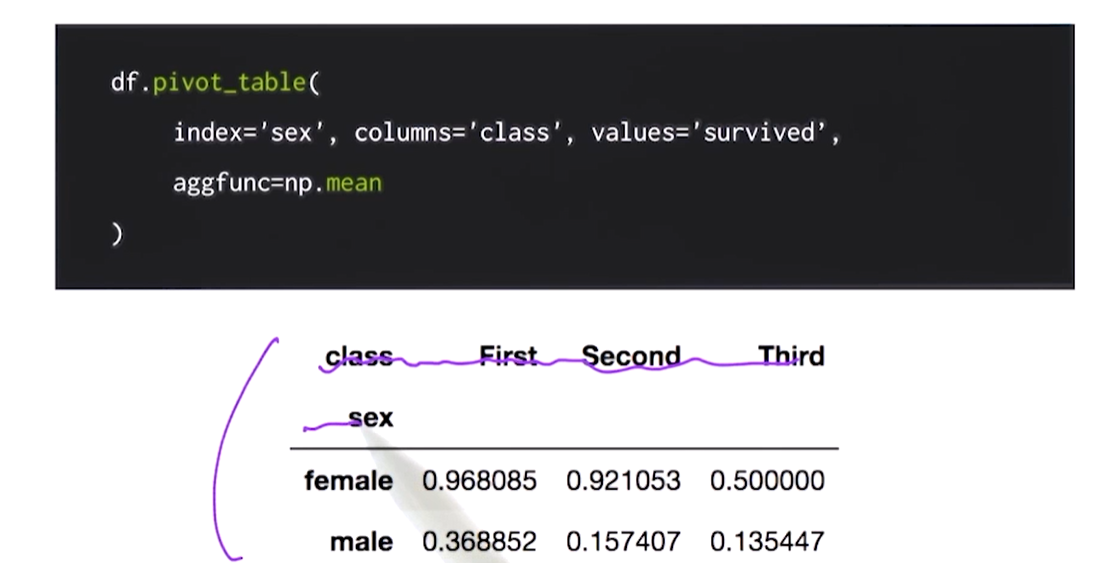
피봇테이블
데이터에서 필요한 자료만 뽑아서 새롭게 요약. 엑셀의 피봇테이블과 같음
index에는 행인덱스로 들어갈 key
columns에는 열 인덱스로 라벨링될값
values에는 분석할 데이터