딥러닝 모델 학습의 문제점
- 학습 속도 문제 : 데이터의 개수가 폭발적으로 증가하여 딥러닝 모델 학습 시 소요되는 시간도 함께 증가
- 기울기 소실 문제 : 더 깊고 더 넓은 망을 학습시키는 과정에서 출력값과 멀어질 수록 학습이 잘 안되는 현상 발생.
- 초기값 설정 문제 : 초기값 설정 방식에 따른 성능 차이가 매우 크게 발생
- 과적합 문제 : 학습데이터에 모델이 과하게 최적화되어 테스트 데이터에 대한 모델 성능이 저하
학습 속도 문제와 최적화 알고리즘
전체 학습 데이터셋을 사용하여 손실 함수를 계산하기 때문에 계산량이 너무 많아짐. 전체 데이터가 아닌 부분데이터만 활용하여 손실 함수를 계산하자
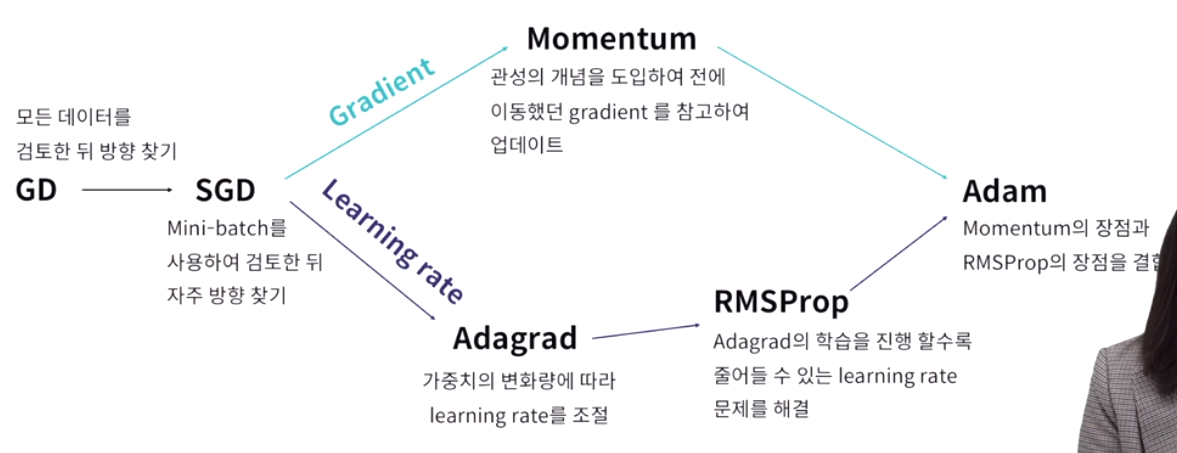
sgd(stochastic gradient discent)
전체 데이터를 조그마한 데이터 모음인 미니 배치에 대해서만 손실 함수를 계산. 다소 부정확할 수 있지만 훨씬 계산 속도가 빠르기 때문에 같은 시간에 더 많은 step을 갈 수 있음

learning late를 너무 높게 설정할시 변동값이 크고 너무 작을 경우 계산이 많아짐

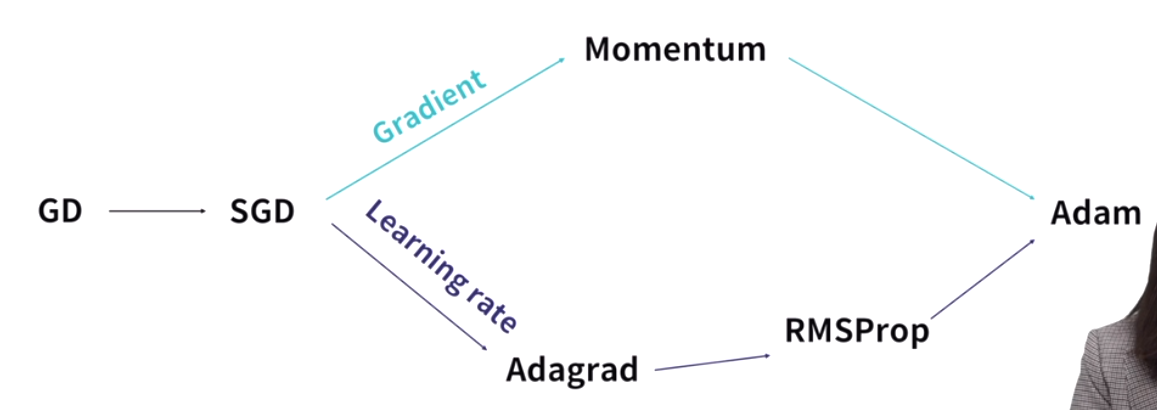
momentum : 과거 이동했던 방식을 기억하면서 그 방향으로 일정 정도를 추가적으로 이동하는 방식
adagrad : 많이 변화하지 않은 변수들은 lr을 크게하고 많이 변화했던 변수들은 lr을 작게 하는 것. 과거의 기울기를 제곱해서 계속 더하기 때문에 학습이 진행될 수록 갱신 강도가 약해짐.
rmspop : 무한히 학습하다보면 순간 갱신량이 0에 가까워 합습이 되지 않는 adagrad의 단점을 해결. 과거의 기울기는 잊고 새로운 기울기 정보를 크게 반영.
adam : momentum + rmsprop : 최근 가장 많이 쓰임
기울기 소실

유가연