1. 자연어 처리
자연어 처리(Natural Lnguage Processing, NLP) 는 컴퓨터를 통해 인간의 언어를 분석 및 처리하는 인공지능의 한 분야. 인간의 언어는 다양한 구조, 체계, 규칙, 문법 등 복잡한 요소들로 구성되어 있음. 자연어 처리는 이러한 요소들을 컴퓨터에게 전달해 인간의 언어를 이해할 수 있도록 패턴을 추출하는등의 방법을 통해 분석 및 처리할 수 있도록 하는 방법.
적용 사례로는 문서 분류, 키워드 추출, 감정 분석이 있음.
자연어 처리는 언어의 복잡한 부분을 학습시켜야 하는데 학습 가능한 데이터양이 증가하였고 연산 처리 속도의 발전으로 자연어 처리 또한 더욱 복잡한 머신러닝 알고리즘이 적용 가능해졌음.
머신러닝 기반 자연어 처리의 적용 사례
(1) 문서 요약 : 장문의 문장들로 이루어진 문서를 컴퓨터가 판별해 내용을 가장 잘 요약해주는 문서를 작성. 또는 제목을 뽑음.
(2) 기계 번역
(3) Chat bot
2. 텍스트 전처리
전처리를 하는 이유는 모델이 효율적으로 작동하기 위해서.
(1) 데이터 탐색 : 데이터의 가장 최소 단위를 기준으로 데이터의 통계치를 살펴보거나 변수별 특징을 살펴봄. 최소 단위라는 것은 테이블 형태의 자료에서 column을 기준으로 살펴볼 수도 있고 이후 여러 조합으로 살펴볼 수도 있음
-> 단어의 개수(문서 전체에서 몇가지 종류의 단어가 존재하는지), 단어별 빈도수 등을 진행후 특정 키워드를 살펴볼 수 있고 단어들의 조합인 문장, 문단을 기준으로 데이터를 살펴볼 수 있음.
(2) 데이터 전처리 : 탐색을 통해 얻은 지식을 기반으로 이상치를 제거하거나 정규화를 진행.
-> 특수기호 제거, 단어 정규화
토큰화
토큰화(tokenization)는 주어진 텍스트를 각 단어 기준으로 분리하는 것을 의미. 토큰화를 통해 생성된 각각의 단어를 토큰이라고 명칭. 가장 기본적인 토큰화의 기준은 공백. 다만 공백기준으로 분리했을 때 문장기호들이 붙게되면 컴퓨터는 같은 단어도 다른 단어라고 인식하기 때문에 소문자 처리, 특수기호 제거 등을 통해 동일한 의미의 토큰은 동일한 형태로 변환할 수 있도록 해야함.
**단어의 개수 및 빈도수 확인
counter = dict()
with open(파일명, 'r') as f :
for line in f :
for word in line.rstrip().split() :
if word not in word_counter :
word_counter[word] = 1
else :
word_counter[word] += 1.rstrip() 은 문자열을 대상으로 사용 가능한데 문서를 열어봤을 때 줄바꿈 기호가 있을 때 이것을 사용하기 위한 방법.
✨ 지프의 법칙(Zipf's law)
대부분 단어 빈도수의 분포는 지프의 법칙을 따름. 주어진 텍스트에서 각각 단어의 빈도수를 높은 순서대로 나열해 순위를 매기면, 그 빈도가 해당 단어의 순위에 반비례하는 수학적인 법칙. 즉, 글에서 가장 많이 나오는 단어는 두 번째로 많이 나오는 단어보다 빈도가 약 2배 높으며, 세 번째로 많이 나오는 단어보다는 빈도가 3배 높다는 뜻.
=> 데이터 관점에서는 빈도수가 많지 않은 단어들로 인해 노이즈가 많이 발생할 수 있음을 의미. 따라서 단어와 빈도수 기준으로 텍스트 전처리를 할 경우 분포를 그려본 후 빈도수가 낮게 발생하는 단어들을 살펴보는 것이 좋음.
텍스트 전처리 방식
(1) 특수 기호 제거
import re # 정규표현식(정의하는 규칙을 가진 문자열 집합) 라이브러리
word = '123hello993 $!@*#@(%ga@*yean'
# 잡아내고 싶은 패턴을 담고 있는 변수(regex) 생성
regex = re.compile('[^a-z A-Z]')
# word안에서 우리가 regex에 정의하지 않은 문자열과 매칭되지 않는 문자열은 ''으로 교체
regex.sub('', word)
# hello gayean(2) Stopword 제거
문법적인 기능을 지닌 단어 및 불필요하게 자주 발생하는 단어를 제거. 텍스트에서 특징, 체계를 잡아내려면 정보력이 있는 단어를 찾아야함. 하지만 불필요하게 자주 발생하는 단어는 어디서나 쓰이기 때문에 우리가 분석하려는 문서에서는 중요하지 않을 수도 있음. 일종의 노이즈 제거.
import nltk
form nltk.corpus import stopwords
# stopwords는 언어학자들이 정의한 단어들을 리스트 형태로 가지고 있음
sentence = ['the', 'green', 'egg', 'and', 'ham', 'a', 'an']
stopwords = stopwords.words('english')
new_sentence = [word for word in sentence if word not in stopwords]
# ['green', 'egg', 'ham']❓ stopword에 새로운 stopword를 추가하고 싶다면?
import nltk
from nltk.corpus import stopwords
new_stopwords = ['none', '은', '는', '이', '가'] # 신규 stopwords
stopwords = stopwords.words('english') # 리스트 반환
stopwords += new_stopwords(3) Stemming
동일한 의미의 단어이지만, 문법적인 이유 등 표현 방식이 다양한 단어를 공통된 형태로 변환
import nltk
from nltk.stem import PorterStemmer
words = ['studies', 'studied', 'studying', 'cats', 'cat']
stemmer = PorterStemmer()
for word in words :
stemmer.stem(word)
# studi, studi, studi, cat, cat3. 단어 임베딩
컴퓨터는 텍스트를 포함하여 모든 데이터를 0과 1로 처리. 그래서 자연어의 기본 단위인 단어를 수치형 데이터로 표현하는 것이 중요함.
단어 임베딩이란 각 단어를 연속형 벡터(방향성이 있고 방향성에 대한 길이가 있는 것)로 표현하는 방법을 의미. 비슷한 문맥에서 발생하는 단어는 유사한 의미를 지님. 예를 들어 서울에 살고 있는 엘리스는 강아지를 좋아한다. 뉴욕에 살고 있는 찰리는 고양이를 좋아한다. 에서 서울의 문맥은 주변에 발생하는 단어를 의미. 살고, 있는이 문맥이 됨. 문맥은 단어에 중요한 역할을 함. 문장 기준으로 살펴보면 뉴욕과 서울 근처에 살고, 있는 이라는 비슷한 문맥을 가지고 있기 때문에 유사한 특징을 가지고 있는 단어일 수 있다. 유사한 단어의 임베딩 벡터는 인접한 공간에 위치.
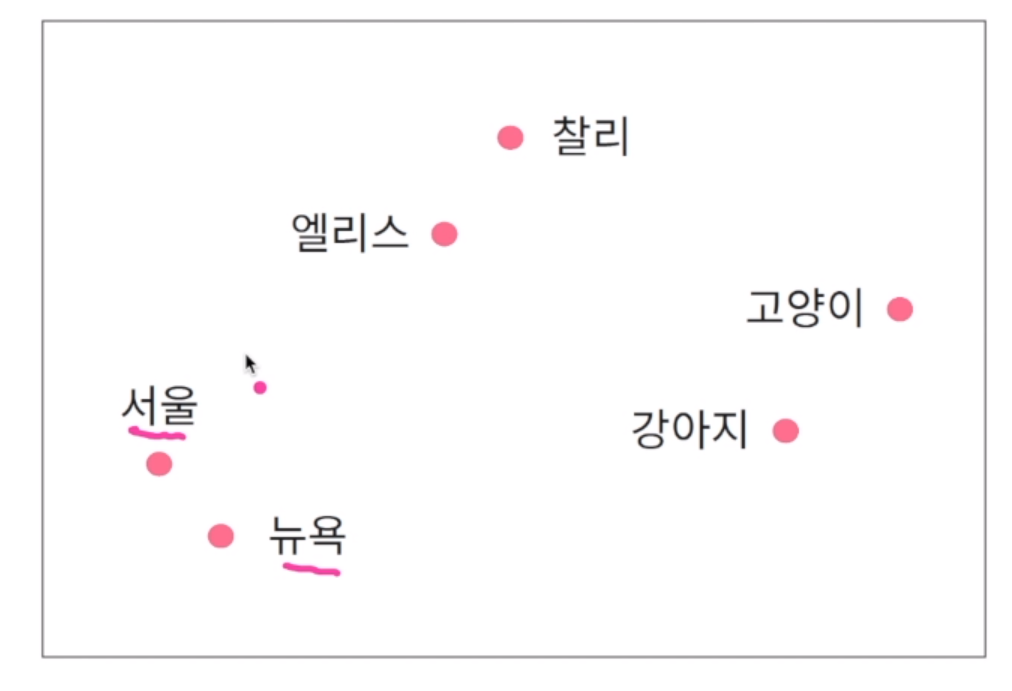
단어 임베딩을 벡터(수치형 데이터인 연속적 벡터)로 유지하면 어떤 장점이 있는가. 임베딩 벡터 간 합과 차로 단어의 의미적 특징을 보존하고 활용 가능. 서울과 한국의 벡터 값의 합 또는 차로 서로간의 의미적 의존성, 유사성, 문맥적 특징을 활용 가능
4. word2vec
단어 임베딩 벡터를 학습하는 알고리즘. word2vec은 단일 신경망을 통해 단어 임베딩 벡터를 학습하게 됨. 주어진 문맥에서 발생하는 단어를 예측하는 문제로 통해 단어 임베딩 벡터를 학습.
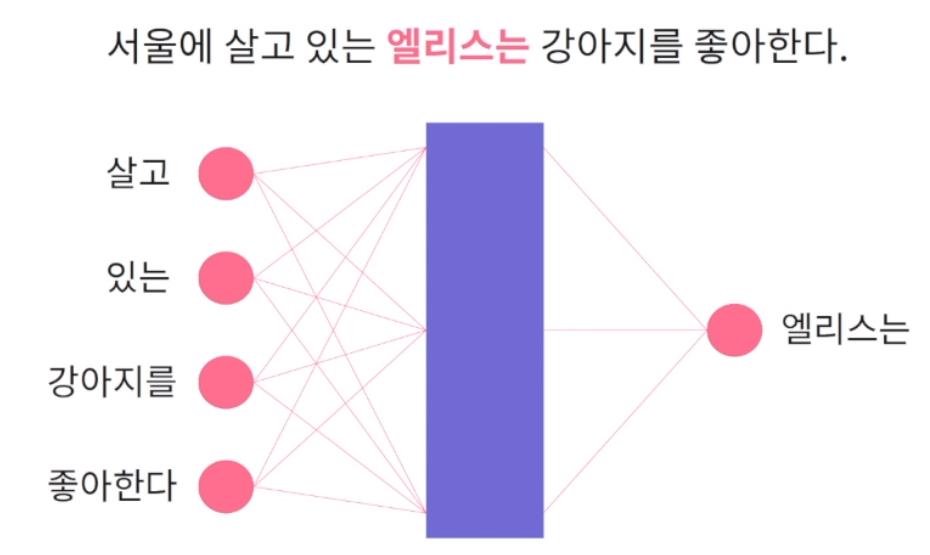
문장 단어의 주변 단어를 통해 문맥을 활용. '엘리스는'을 예로 들자면 주변의 단어들을 통해 이런 단어가 나오면 '엘리스는' 이라는 단어가 나오겠구나 라고 학습. 이 학습이 끝나면 다음 단어를 학습. 신경망 학습이 끝나면 문장에서 발생하는 문맥이 주어지면 문맥 내 발생하는 단어를 잘 맞추는 모델이 생성될텐데 그럼 여기서 단어 임베딩 벡터는 어떻게 생성되는가? 학습된 신경망의 은닉층을 활용해서 단어의 임베딩 벡터를 표현. '엘리스는' 이라는 문제를 잘 해결하게 되었다면 주위의 문맥이 주어졌을 때 최종적으로 계산되는 은닉층 node의 값을 '엘리스는' 이라는 단어의 벡터로 사용.
from gensim.models import Word2Vec
# gensim의 학습데이터는 리스트의 리스트 형태로 표현해야함. 각 리스트는 문장이나 문서 하나, 그 안에는 문장을 토큰화한 결과가 들어가야함.
doc = [['서울에', '살고', '있는', '엘리스는', '강아지를', '좋아한다']]
# min_count는 학습할 때 이 인자의 숫자보다 적게 발생하는 단어들은 학습하지 않음을 의미.
# window는 문맥을 기준으로 단어를 예측. 문맥의 범위를 뜻함. 엘리스는 예측 문제에서는 앞 2단어, 뒤 2단어 총 4개를 입력값으로 사용한다는 의미.
# vector_size는 생성하는 임베딩 벡터의 차원의 개수와 동일. 즉, 은닉층의 node의 개수.
w2v_model = Word2Vec(min_count = 1, window = 2, vector_size = 300)
# 인자로 학습데이터를 줌. 학습데이터를 각각 정수 인덱스 부여.
w2v_model.build_vocab(doc)
# total_examples는 입력 데이터 안에 총 문서가 몇 개인지.
# w2v_model.corpus_count는 build_vocab을 하면 저절로 생성되는 인자.
# 저절로 학습 데이터의 총 문서 개수를 사용할수 있게 됨.
# epochs는 word2vec을 한 번 학습할 때 모든 단어들을 살펴보며 예측 문제를 푸는데
# 이 과정을 몇 번 반복할지. 학습 데이터를 몇 번 순환하며 학습할지.
w2v_model.train(doc, total_examples = w2v_model.corpus_count, epochs = 20)
# 인자로 주어지는 단어의 임베딩 벡터를 기준으로 가장 유사한 단어들을 반환. 순전히 수치들간의 유사성을 통해서 단어와 유사한 단어를 출력
similar_word = w2v_model.wv.most_similar('엘리스는')
print(similar_word)
# > [('있는', 0.05005...), ('좋아한다', 0.03316...), ('강아지를', 0.02574...), ('서울에', 0.01304...), ('살고', -0.03427...)]
# 두 개의 문자열을 인자로 주면 각각의 임베딩 벡터를 통해 서로 얼마나 비슷한지 계산해주는 함수.
score = w2v_model.wv.similarity('엘리스는', '좋아한다')
print(score)
# > 0.033168...5. fastText
앞서 word2vec에서는 주어지는 문맥을 통해서 단어를 예측하는 문제로 신경망을 학습해서 신경망의 은닉층을 단어 벡터로 사용. 이러한 word2vec의 치명적인 문제는 미등록 단어 문제가 있음. out-of-vocabulary 혹은 ov라고 표현. 바로 학습 데이터 내 존재하지 않았던 단어 벡터는 생성할 수 없음. 왜냐하면 입력 데이터나 출력 데이터 모두 학습 데이터 내에 존재했던 단어들로 구성되어 있기 때문. 학습데이터에 없었던 애들이 신경망에 들어오면 처리를 할 수 없음. 이를 개선하기 위해 각 단어를 문자 단위로 나누어서 단어 임베딩 벡터를 학습.
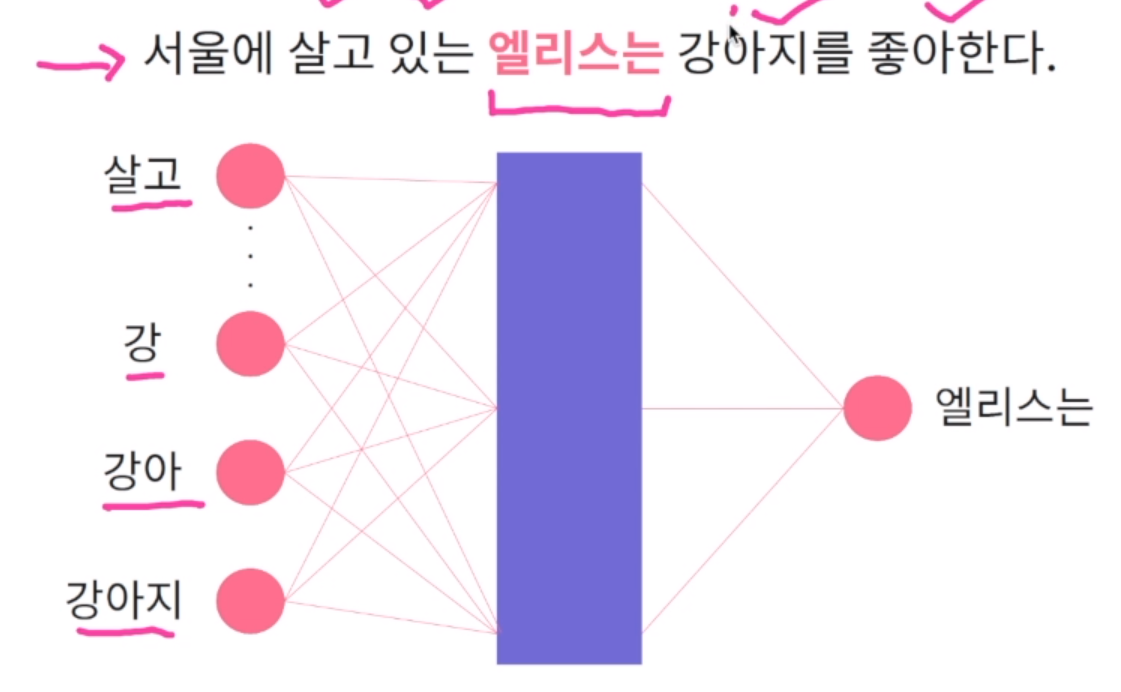
나머지 학습 방법은 word2vec과 유사.
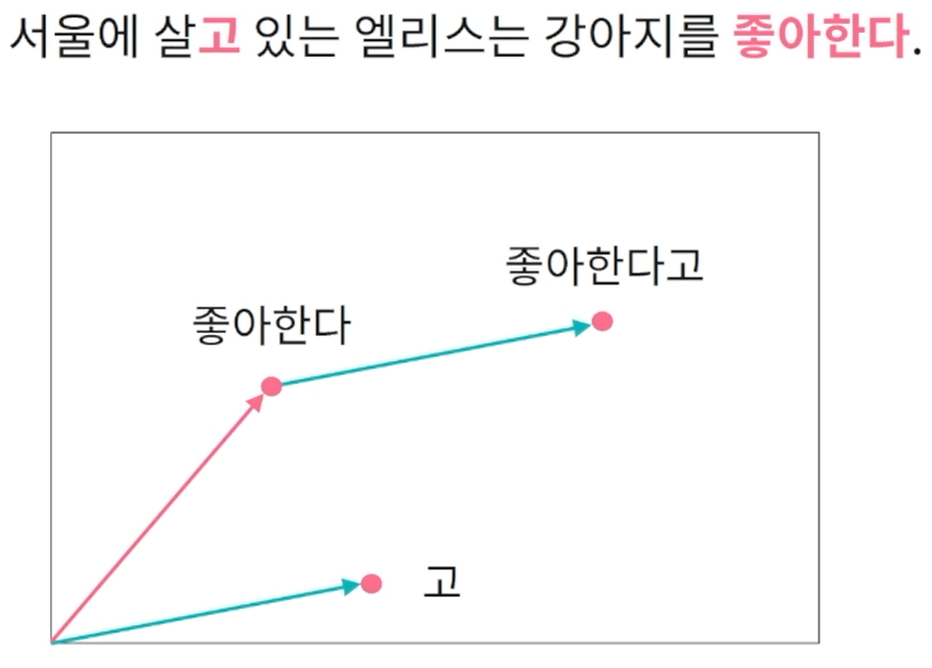
이 문장안에 '좋아한다고'는 존재하지 않지만 각각의 문자 단위로도 임베딩 벡터를 학습했기 때문에 기존에 학습된 단어와 문자의 조합으로 신규 단어들의 임베딩 벡터를 생성할 수 있음. '좋아한다고'의 임베딩 벡터를 생성하기 위해서 기존의 '좋아한다'와 '살고'에서 나온 '고'에 벡터를 더해 '좋아한다고'의 임베딩 벡터를 추정 가능.
from gensim.models import FastText
# gensim의 학습데이터를 사용하기 때문에 word2vec과 유사하게 리스트의 리스트 형태로 표현해야함. 각 리스트는 문장이나 문서 하나, 그 안에는 문장을 토큰화한 결과가 들어가야함.
doc = [['서울에', '살고', '있는', '엘리스는', '강아지를', '좋아한다']]
# min_count는 학습할 때 이 인자의 숫자보다 적게 발생하는 단어들은 학습하지 않음을 의미.
# window는 문맥을 기준으로 단어를 예측. 문맥의 범위를 뜻함. 엘리스는 예측 문제에서는 앞 2단어, 뒤 2단어 총 4개를 입력값으로 사용한다는 의미.
# vector_size는 생성하는 임베딩 벡터의 차원의 개수와 동일. 즉, 은닉층의 node의 개수.
ft_model = FastText(min_count = 1, window = 2, vector_size = 300)
# 인자로 학습데이터를 줌. 학습데이터를 각각 정수 인덱스 부여.
ft_model.build_vocab(doc)
# total_examples는 입력 데이터 안에 총 문서가 몇 개인지.
# ft_model.corpus_count는 build_vocab을 하면 저절로 생성되는 인자.
# 저절로 학습 데이터의 총 문서 개수를 사용할수 있게 됨.
# epochs는 FastText 한 번 학습할 때 모든 단어들을 살펴보며 예측 문제를 푸는데
# 이 과정을 몇 번 반복할지. 학습 데이터를 몇 번 순환하며 학습할지.
ft_model.train(doc, total_examples = ft_model.corpus_count, epochs = 20)
# 인자로 주어지는 단어의 임베딩 벡터를 기준으로 가장 유사한 단어들을 반환. 순전히 수치들간의 유사성을 통해서 단어와 유사한 단어를 출력
similar_word = ft_model.wv.most_similar('엘리스는')
print(similar_word)
# > [('좋아한다', 0.03110...), ('살고', 0.01565...), ('강아지를', -0.09297...), ('서울에', -0.10255...), ('있는', -0.10588...), ]
# ft_model.wv에 학습하지 않았던 데이터를 넣어줘도 벡터값을 반환
new_vector = ft_model.wv['좋아한다고']
print(new_vector)
# > array([-5.8544..., -1.5485..., -1.3994..., -9.1309...])