- 딥러닝의 묘사는 여러가지 조건에 의해 상당한 제약을 받고 있음을 먼저 알린다.
(severely constrained representation of deep learning algorithm)
Problems with Deep learning Representation
- 어떠한 경우에 대해 딥러닝 알고리즘의 묘사(representation)은 어떻게 해야 한다는 실질적인 시스템이 없어 어떤 조건을 만족해야하는지, 어떠한 과정을 통해 묘사가 이루어졌는지에 대해 알 수 있는 방법이 없다는 것이다.
Experiments with Regularized representations
- 각 정규화된 표현에 대해 묘사를 진행하였을 때 어떤 방식으로 Plotting이 이루어지는지를 확인하는 실험을 진행
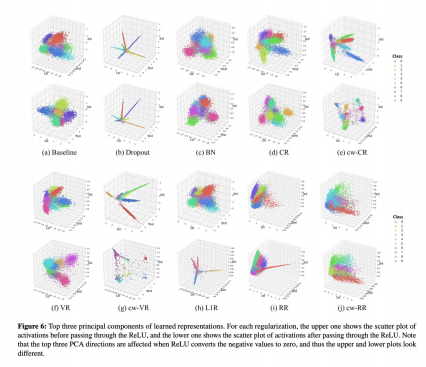
실험간에 찾아낸 좋은 뉴스는
1. 어떠한 알고리즘을 학습하던 간에 좋은 네트워크를 사용했다는 것을 알았다는 점
2. 각 알고리즘은 각각의 묘사가 다르다는 것을 알았다는 점 (어찌보면 당연한 이야기;;)
나쁜 점은 각 결과값에 대해 어떻게 해석해야할지에 대해 더욱 어려움을 느꼈다는 점이었다.
이러한 것을 잘 나타내는게 Disentangled Representation인데, 일반적인 Linear Regression 또는 Classification과 같은 경우 명확한 근거를 필두로 구분을 진행하지만 이러한 경우가 아예 없는 Deep learning의 경우, 결국은 Regression-Classification의 과정처럼 만들어 놔야 '아 이 알고리즘은 결과가 잘 나오네요'라고 할 수 있다는 것이다.
Task and Representation

여기 플라톤이 썼던 일화들 중 하나인 동굴의 우화('국가' 7권)를 아는가? 이 감옥에 구속되어 벽을 마주본 사람들은 그림자만을 봐 그것을 실체라고 믿어 버린다. 이 우화를 만든 플라톤은 우리가 현실에 보고 있는 것은 이데아의 '그림자'에 지나지 않다고 플라톤은 생각했다고 말하고 있다. 물론 이과생들 중에는 이게 뭔 말을 하는지 못알아듣는 사람들이 있을 거고, 문돌이 친구들만 고개를 끄덕거릴 거다. (문과인데 모르는 사람은 상경계열일 수 있고, 그게 아니면 100% 도덕시간에 졸은 거다)
어쨌든 간에 이 우화를 차용한게 아래 이미지다.
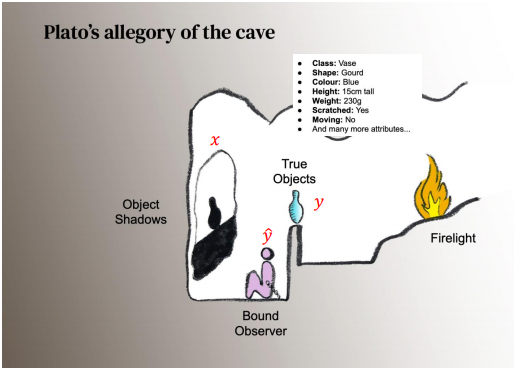
일반적으로 어떤 머신러닝에 대해 사람들이 관심을 가지는 건 Y, 실제 사물이다. 이러한 사물을 우리 눈으로 관측 또는 기계로 학습시킨 과정이 x이고, 이것이 잘 관측되어 결과로 나타난 게 y hat이다.
위와 같이 인간이 잘 조절한 라벨을 가지고 저렇게 생각했다는 것은 Y의 개념이 제대로 정립되었다는 것이다.
Examples of Good Representation, with Vague Ones
Supervised
'모호한 컨셉을 지도 방식으로 나타냈을 때'의 좋은 표현은 개념을 어떠한 지도 방식을 통해 정확하게 나타낸 것이라고 할 수 있다.
ex) Information Bottleneck: 중간 계층이 하는 일은 밑에 쪽에서 올라온 정보에서 Y에 관한 정보, 즉 최종적으로 남기고 싶어하는 정보를 살려두면서 그것과 상관없는 x의 나머지 정보들을 지우는 것
Unsupervised
'모호한 컨셉을 비지도 방식으로 나타냈을 때'의 경우, 문제를 근본적으로 접근하지 못하기에 downstream task(어떠한 알고리즘에 대해 미리 몇 개의 필터링을 거치는 것)을 몇가지 거쳐 표 현 결과를 만든 후 한가지 계층에 이를 트레이닝 하는 방식으로 지정한 기준들을 다 만족해야 한다.
ex) Word Embedding – 단어 하나하나를 어떤 백터나 숫자로 맵핑하는 기법
스스로 배우는 self-supervised learning을 사용 - masked languaged model을 만드는 형식으로 좋은 성능을 내는 representation을 학습할 수 있다.
Differences with General and Professional Views with Deep Learning Representatons
일반적인 사회에서의 딥러닝 결과값들은 컴퓨터가 어느 정도 개념을 이해하고 있고, 그 결과에 따라 정량적인 규칙을 가지고 표현을 하고 있다고 생각하는 반변, 실제 Deep learning에 대한 과정 분석은 내부 파라미터의 정보가 전무하고, 결과에 의존성을 가지고 있어 세간의 상식들과는 차이가 있다.
Family Tree: Radical Point #1
- 가족도와 같은 분포로서 나타낼 수 있는 정보 데이터들은 해석이 가능하고 쉽게 설명이 가능한 것들이다. 이를 이용하여 일부 가족 관계를 입력 데이터로 제공한 후 적지 않은 가족관계를 맞추는 문제가 주어졌다고 가정한다.
-> 이와 같은 경우 통상적으로 Visualization에 대해 사람들은 저계층에서 고계층으로 순차적으로 build-up해나가고 있다는 관점을 가지지만....
Problematic Issues
최고위 계층부터 시작해서 결과를 망가뜨려도 개념이 잡히고 시각화이 되어있다는 결과를 통해 제대로 이렇게 개념을 잡고 있느냐 안잡고 있느냐 그걸 보는게 아니라 그냥 그걸 One step의 기준으로서(윤곽이라던가) 보고 있다는 것이다. 즉, 개념을 이해했다 정리했다고 말할 수 없다.
- Example 1의 의미: Representation Network이 배우는 Representation은 상당히 의미 있는 것들이고 이를 확적하게 말할 수는 없으나 인간과 기계 모두에게 좋은 것이다.
Intelligence Without Representation : Radical Point #2
-
The Paper: 중간 representation에 대해 신경 쓸 필요는 없다
문제를 어떤식으로 표현할지, 어떤식으로 정리해서 다른 방식으로 표현할지 등 인간이 개입하면 안되며 인간이 문제가 어떤식으로 정리되어야 하는지 생각조차 할 필요가 없다는 관점 -
인간은 representation이 잘 정리되고 의미있는 룰을 가지고 돌아가느냐에 대한 의문을
가지며, 평가에 대해 결과와 과정이 확실해야 한다고 생각한다. 하지만, 과정에 대해 실재적으로 표현되지 않은 이상 평가를 할 이유가 없다고 할 수 있으며, 실패하였다고 판단할 수 도 없게 된다.
