Support Vector Machine
Definition of Support Vector Machine(SVM)
- 어떠한 데이터값에 대해 임의의 클래스를 지정하여 Linear Classification을 진행한다. 해당 Linear Classification의 Hyperplane에 대해 각 클래스 별로 Hyperplane에 가장 가까운 점에 대해 Hyperplane에 평행한 선을 긋는다. 이 두 선을 만드는 것을 Support Vector Machine이라고 한다.
이것을 정리하면 아래와 같이 적을 수 있다.
minimize w so that w^{t}x > 1 if x has postive class and <-1 if x has negative class.
class가 positive이면 y=1, negative이면 y=-1이라고 가정시 다음과 같이 줄어든다.
minimize w so that yw^{t}x > 1
이때 w를 가장 가까운점까지의 직선거리의 두배라고 가정하면 Margin은 w에 대한 역수임을 알 수 있다. 또, 이를 수학적으로 나타내면 아래와 같다.

Advantages and Disadvantages of SVM
- SVM에 대한 장점은 다음과 같다. 1. 분류문제와 예측문제 동시에 쓸 수 있다. 2. 신경망 기법 대비 오버핏팅이 덜하다. 3. 예측의 정확도가 높은 편이었기 때문에 오랫동안 사용되었다는 장점이 있다. 4. 사용하기 쉽다.
- 단점은 다음과 같다. 선형으로 구성이 되지 않을 경우, 차원을 하나 더 늘려서 평면형 Decision Surface를 만들어 구성하여야 한다. 이를 Kernel이라고 하며 더 자세한 Kernel의 종류에 대해서는 이후에 다룬다. 다음으로 모형 구축에 대한 시간이 오래 걸리고 결과에 대한 설명력이 떨어지는 경향이 있다. 마지막으로 Outlier에 대한 대책능력이 떨어진다. 이에 대한 설명도 이후에 다룬다.
Kernel With Decision Surfaces
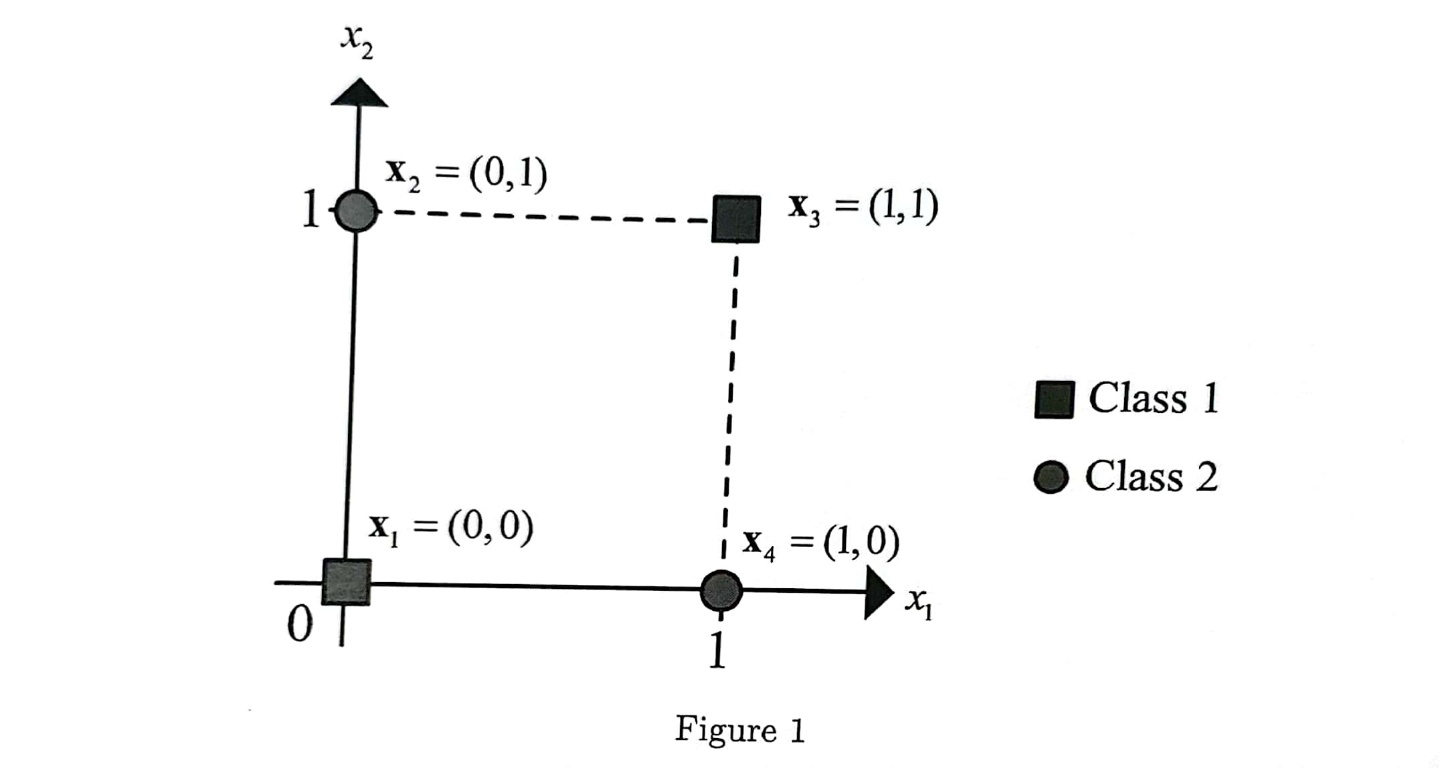
데이터 sample들이 서로 linearly seperable하지 않을 때 그 차수를 높여서 linearly seperable하게 만드는 과정으로, 다음과 같은 상황에 대해 성립한다. 예시를 위해 본교 AI 응용시스템 2020년도 1학기 기말고사 문제 1번을 사용한다. 내가 배울때는 없었는데 언제 생겼는지는 잘 모르겠다.
1. 4개의 훈련데이터 x1,x2,...,x4가 classification 문제를 해결하려고 한다. x1= (0,0)과 x3 = (1,1)은 class 1에, 그리고 나머지 (0.1)과 (1.0)은 class 2에 속해있다.
1) basis function이 포함된 모델 y(x,w) = w^Tphi(x)+b로 classification error가 0인 decision boundary를 결정할 수 있을 지 논의하시오. -> Kernel Trick을 사용하는 모델을 기술하라는 의미이다. Multilayer Perceptron을 사용하는 방법으로 1969년 MIT에서 수학적으로 증명되었다.
2)Feature Space에서의 Decision Boundary가 hyperplane phi_3(x) = 0.7로 주어졌을 때 margin을 계산하시오.
3) C= infinity인 SVM을 kernel k(x,z) = phi(x)^Tphi(z)로 훈련했을 때 얻을 수 있는 decision boundary를 예측하시오.
이와 같이 데이터가 선형적으로 분리가능하지 않은 경우 Kernel Trick을 사용하여 공간적으로 이를 분리할 수 있다. 이중 가장 사용되는 Trick의 종류에는 대략 세가지 방식이 있으며 Polynomial, Gaussian Radial Basis Function(RBF), Hyperbolic Tangent(Multilayer Perceptron Kernel)등이 있다. 이를 아래와 같이 나타낼 수 있다.
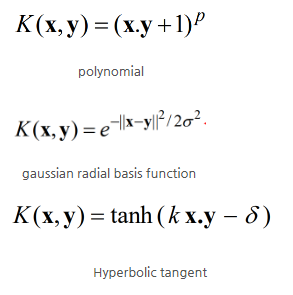
이때 Polynomial의 p인자, Gaussian Radial Basis Function의 sigma, Hyperbolic Tangent의 k와 delta인자는 사용자가 반드시 골라야 하는 파라미터에 해당한다. 이중 -1/2(sigma)^2에 해당하는 gamma의 경우 너무 크면 Gaussian에 대해 민감하게 반응하여 Overfitting의 가능성이 있다.
Artificial Neural Network
ANN(Artificial Neural Network)
- nonlinear classification model을 제공
- deep neural network의 기본이 됨
- score값을 sigmoid 함수와 같이 nonlinear 관계로 맵핑을 해주는 역할을 수행한 후 출력
- 대표적인 activation functions - ReLU: gradient값이 1로 유지됨
- computer vision, image recognition과 같은 최근의 연구에 많이 활용
- gradient vanishing problem으로 인해 깊은 계층에 대해서는 학습이 효과적으로 진행이 안됨
- ANN을 계층을 쌓아서 깊게 쌓게 되면 DNN(Deep Neural network)가 됨
- DNN : 각각의 계층에 따라서 feature의 어떤 형태가 달라짐, 더욱 복잡한 모델들도 잘 분류 가능
Multilayer Perceptron(MLP)
- neural network를 여러 개의 층으로 쌓은 것으로, XOR Problem과 같은 nonlinear한 문제들을 풀 수 있다.
- breakthrough in back propagation
-> convolutional neural network와 같은 ANN에서 고도화되어서 이미지나 비디오 같은 고차원의 신호를 효과적으로 다룸 - 이를 효과적으로 사용한 것이 MNIST data Recognition으로, 현재 사용되는 글자인식기능이다.
-> 하지만 현재 글자인식기능은 신경망의 활성함수의 도함수값이 계속 곱해지다보면 기울기가 0이 되어 버려서 GD를 사용할 수 없는 문제가 있다.
-> 그래서 ReLU(Sigmoid Function이 아니라 Semiconductor Diode의 Functions와 같은 파형을 가진다.) 활성함수를 개선하는 방법, 층을 건너뛴 연결을 하는 ResNet, 배치 정규화(batch normalization) 등을 통해 이를 개선하고자 하는 방법들이 연구되고 있다.
