Why JPA
자바 애플리케이션에서 객체를 RDB로 관리할 때 발생하는 문제를 해결하기 위해 JPA가 등장했다.
패러다임의 불일치
객체지향 언어와 관계형 데이터베이스의 차이는 다음과 같다.
1. 상속
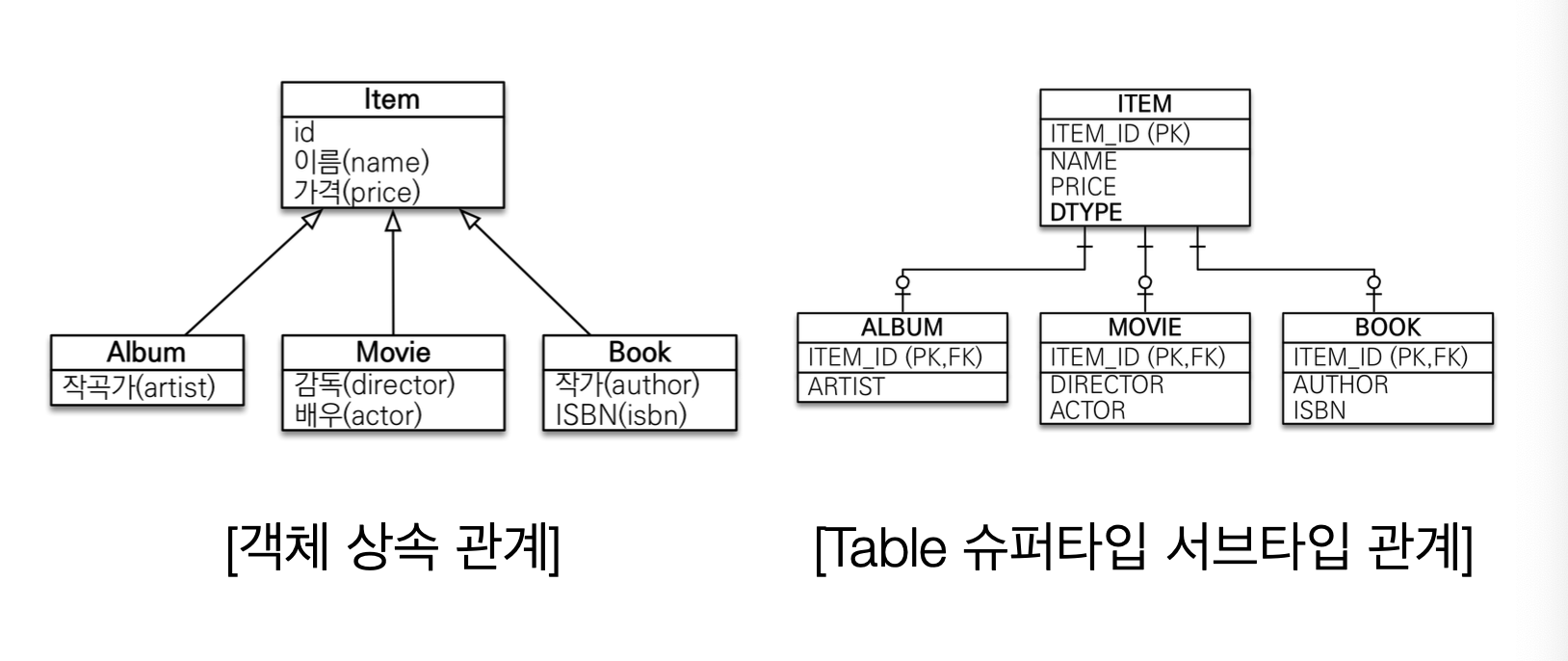
RDB에는 상속 관계가 없다. 다만 객체의 상속 관계를 굳이 테이블에서 표현한다면 위처럼 표현할 수 있다.
하지만 이 경우 Album 객체 하나를 저장하기 위해 다음 과정을 거쳐야 한다.
- Item 객체와 Album 객체 분리
- ITEM insert
- ALBUM insert
조회할 때도 이런 과정이 필요하다
- ITEM, ALBUM JOIN
- Item, Album 객체 생성
위 과정을 JDBC로 작성하면 꽤나 많은 코드를 작성해야 한다.
JPA는 이러한 과정을 자바 컬렉션에 데이터를 저장하듯 편리하게 작성할 수 있도록 해준다.
// 컬렉션에 객체 저장
list.add(album);
// JPA 영속성 컨텍스트에 객체 저장
em.persist(album);
// 컬렉션에서 객체 조회
list.get(albumId);
// JPA 영속성 컨텍스트에서 객체 조회
em.find(Album.class, albumId);2. 연관관계
객체는 참조하고 있는 다른 객체를 자유롭게 탐색할 수 있어야 한다.
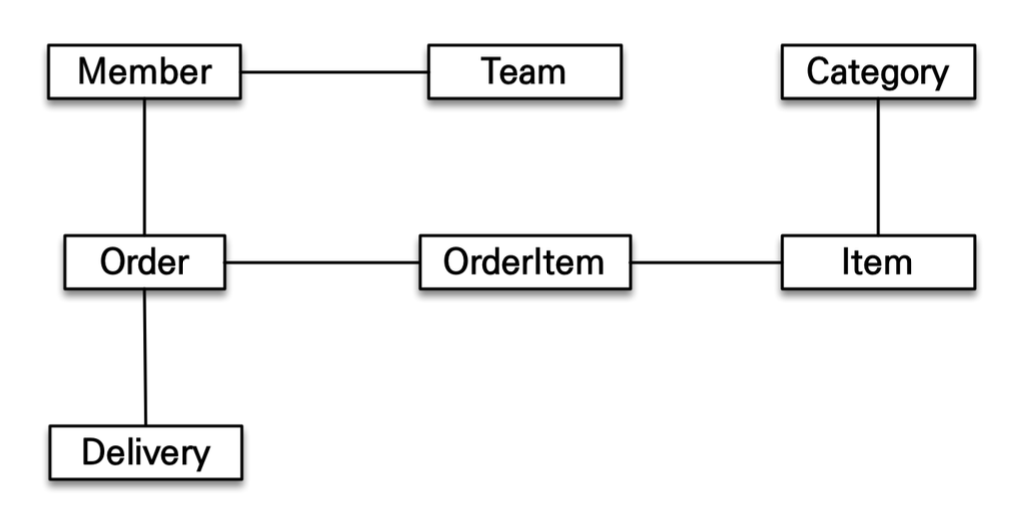
하지만 RDB에서 데이터를 조회해 생성한 객체들은 처음 실행한 SQL의 범위에 따라 탐색할 수 있는 객체들이 제한된다.
SELECT M.*, T.*
FROM MEMBER M
JOIN TEAM T ON M.TEAM_ID = T.TEAM_ID;member.getTeam(); //OK
member.getOrder(); //null그렇다고 객체에 연관된 모든 데이터를 매번 SQL로 조회하면 매번 불필요한 데이터까지 조회하게 되어 성능 저하가 발생한다.
JPA는 지연 로딩을 통해 이러한 문제를 해결한다.
3. 객체 비교
String memberId = "100";
Member member1 = memberDAO.getMember(memberId);
Member member2 = memberDAO.getMember(memberId);
System.out.println("isSame = " + (member1 == member2)); // false같은 데이터를 조회해도 매번 새로운 객체를 생성하면 비교연산자를 사용했을 때 서로 다른 객체 인스턴스로 취급된다.
JPA는 자바 컬렉션에서 객체를 조회하듯 트랜잭션 내에서 같은 데이터는 같은 객체 인스턴스로 취급한다.
// 컬렉션에서 객체를 꺼내 비교하기
Member member1 = list.get(1);
Member member2 = list.get(1);
System.out.println("isSame = " + (member1 == member2)); // true
// JPA 영속성 컨텍스트에서 객체를 꺼내 비교하기
Member memberA = em.find(Member.class, 1);
Member memberB = em.find(Member.class, 1);
System.out.println("isSame = " + (memberA == memberB)); // true이처럼 JPA는 패러다임의 불일치를 해소하고 번거로운 객체와 테이블간의 매핑 작업을 줄여준다.
What is JPA
그래서 JPA를 무엇이라 정의해야 할까?
ORM
JPA는 ORM(Object-relational mapping, 객체 관계 매핑) 기술이다.
객체는 객체대로 설계하고 RDB는 RDB대로 설계하되, ORM 기술이 이 둘을 중간에서 매핑해주는 것이다.
자바 진영의 ORM 기술 표준이 JPA인 것이다.
JPA는 인터페이스의 모음으로 기술 표준이 되며, 이를 구현한 구현체로 Hibernate, EclipseLink 등이 있다.
Architecture
JPA는 자바 애플리케이션과 JDBC 사이에서 동작한다.
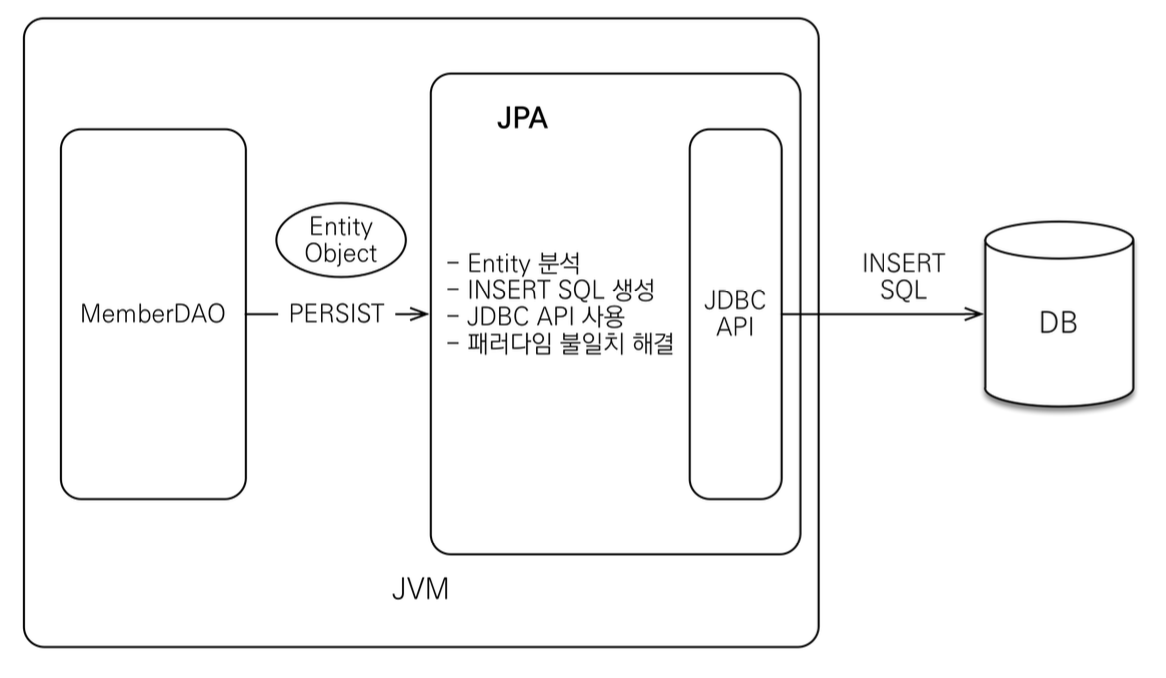
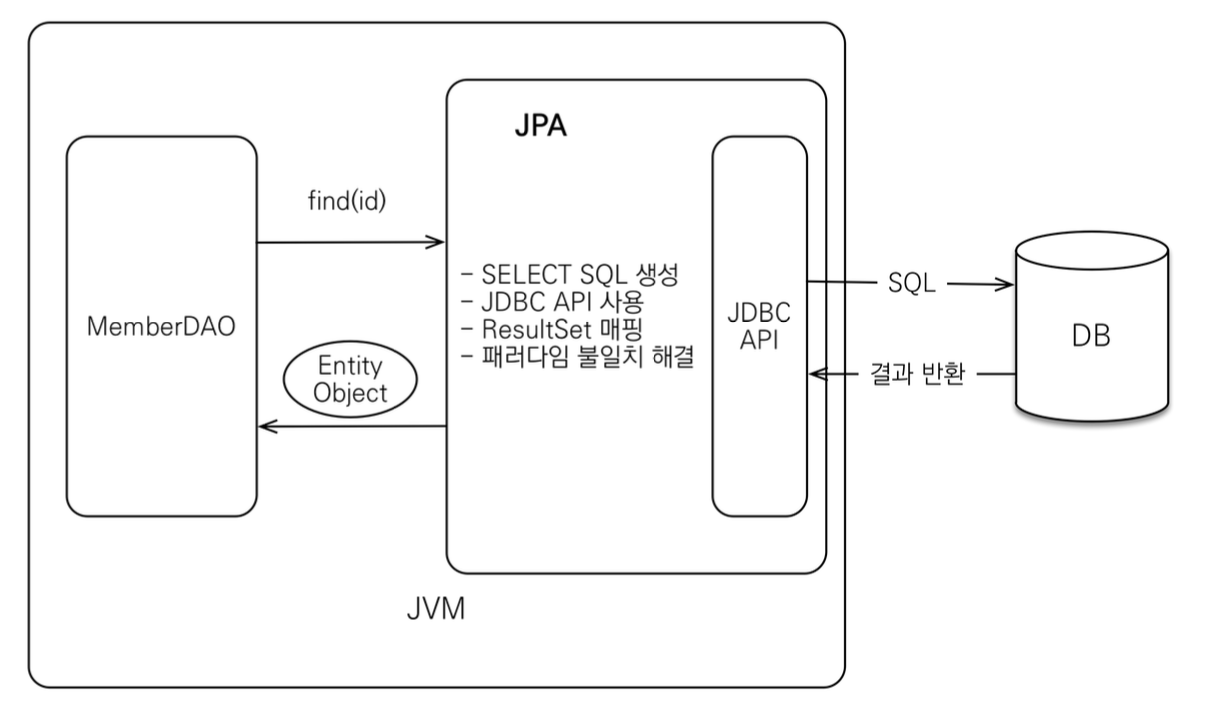
즉, SQL 중심 개발이 필요했던 부분을 JPA가 추상화하는 것이다.
덕분에 개발자는 객체 중심 개발이 가능하고 벤더 독립성을 가지게 되며 데이터 접근 추상화를 통해 생산성과 유지보수 측면에서도 이점을 얻게 된다.
JPA 구동 방식
JPA는 특정 DB에 종속되지 않는다. 하지만 각 DB가 제공하는 SQL 문법과 함수는 조금씩 다르기 때문에 사용하고자 하는 DB의 Dialect를 지정해 사용하게 된다.
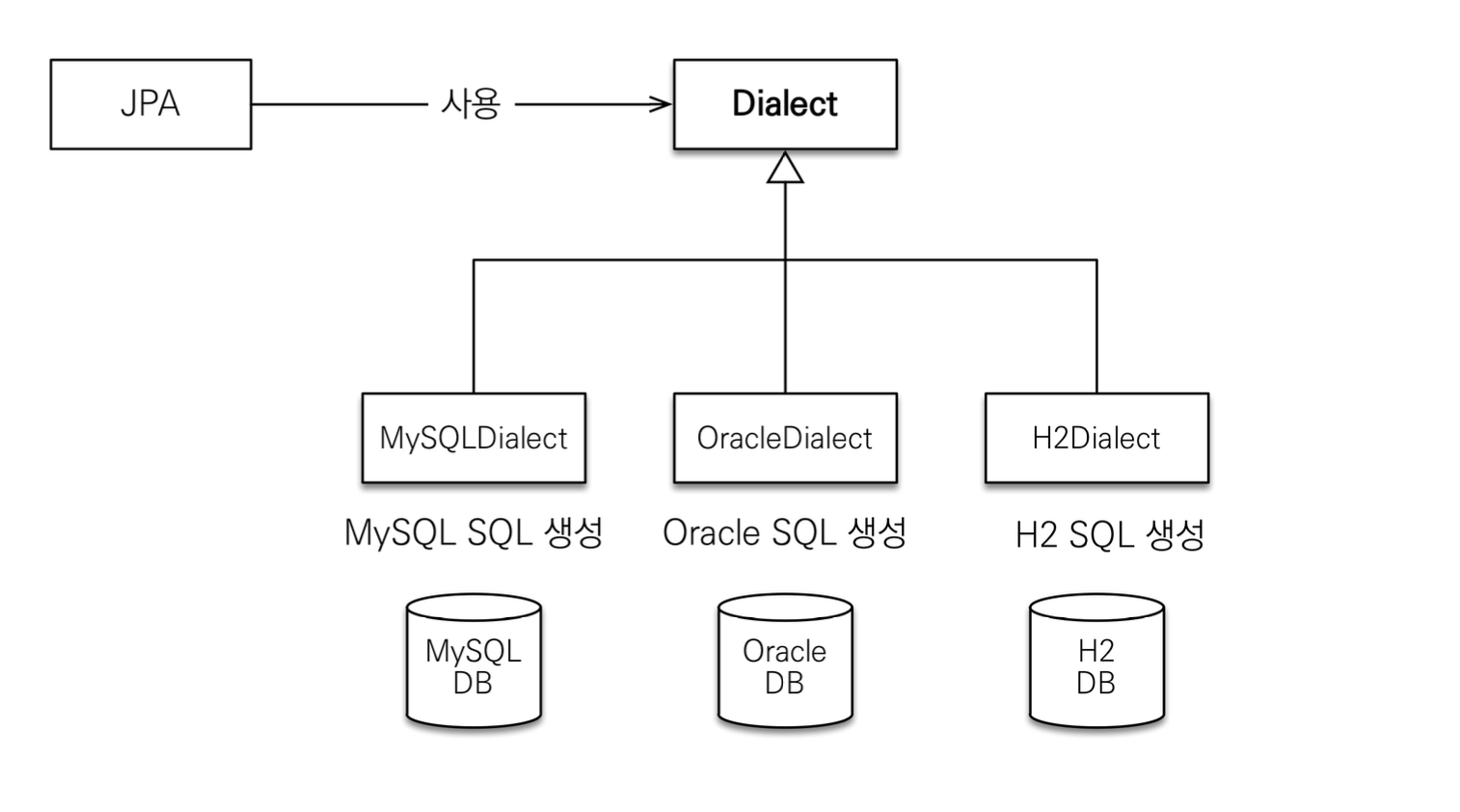
스프링 없이 JPA만 단독으로 사용할 경우 src/resources/META-INF/persistence.xml에 JPA 설정 정보를 입력한다.
아래 예시에서는 h2 Dialect를 사용하고 있다.
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.2" xmlns="http://xmlns.jcp.org/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence http://xmlns.jcp.org/xml/ns/persistence/persistence_2_2.xsd">
<persistence-unit name="hello">
<properties>
<!-- 필수 속성 -->
<property name="jakarta.persistence.jdbc.driver" value="org.h2.Driver"/>
<property name="jakarta.persistence.jdbc.user" value="sa"/>
<property name="jakarta.persistence.jdbc.password" value=""/>
<property name="jakarta.persistence.jdbc.url" value="jdbc:h2:tcp://localhost/~/test"/>
<property name="hibernate.dialect" value="org.hibernate.dialect.H2Dialect"/>
<!-- 옵션 -->
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="hibernate.use_sql_comments" value="true"/>
<property name="hibernate.jdbc.batch_size" value="10"/>
<property name="hibernate.hbm2ddl.auto" value="create" />
</properties>
</persistence-unit>
</persistence>JPA는 이 파일을 읽어 EntityManagerFactory를 생성하고 이를 기반으로 EntityManager를 생성하게 된다.
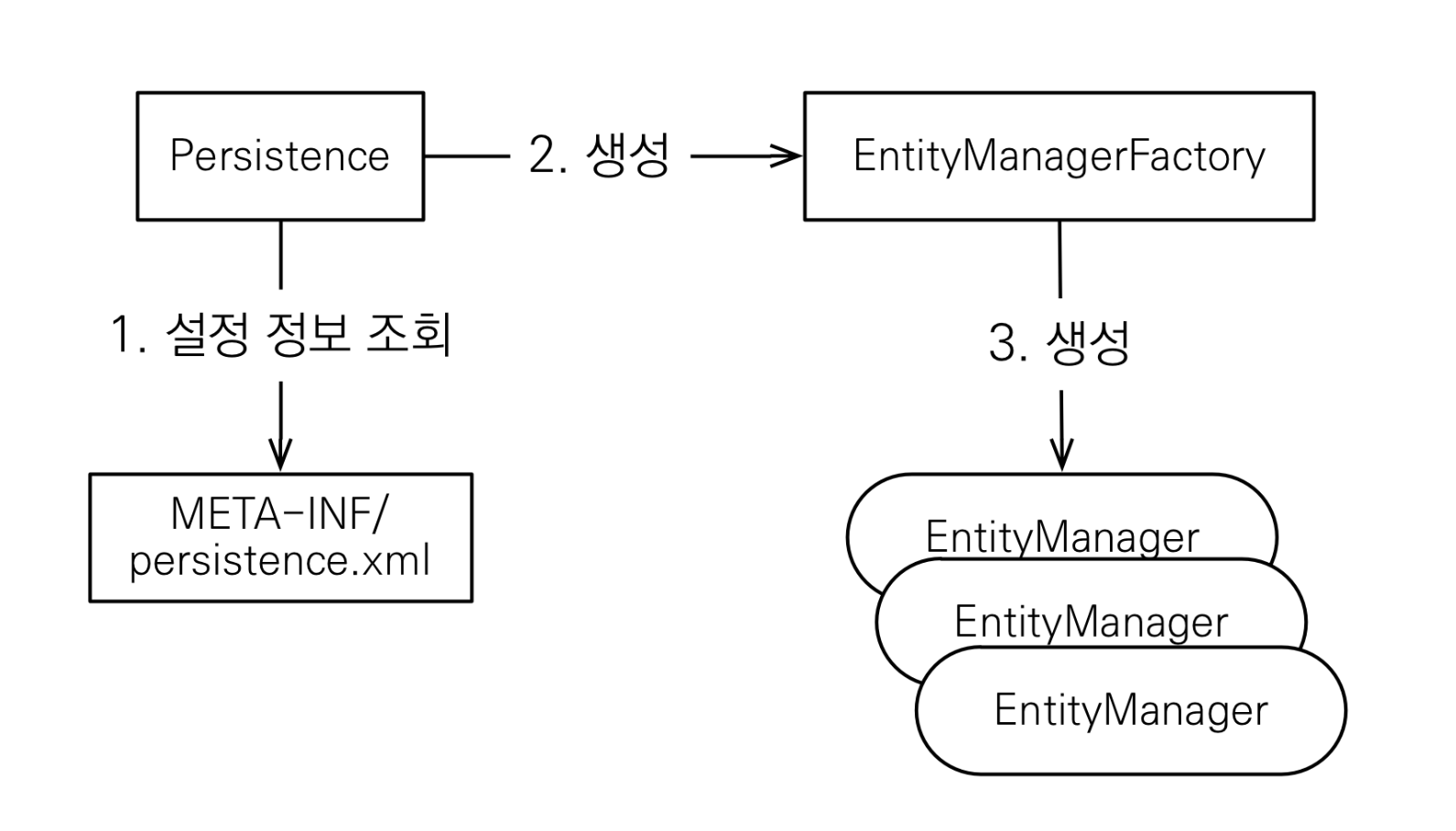
코드로 표현하면 다음과 같다.
EntityManagerFactory emf = Persistence.createEntityManagerFactory("hello");
EntityManager em = emf.createEntityManager();EntityManagerFactory는 애플리케이션 전체에서 하나만 생성해 공유해야 하며 EntityManager는 쓰레드 간 공유해서는 안 된다.
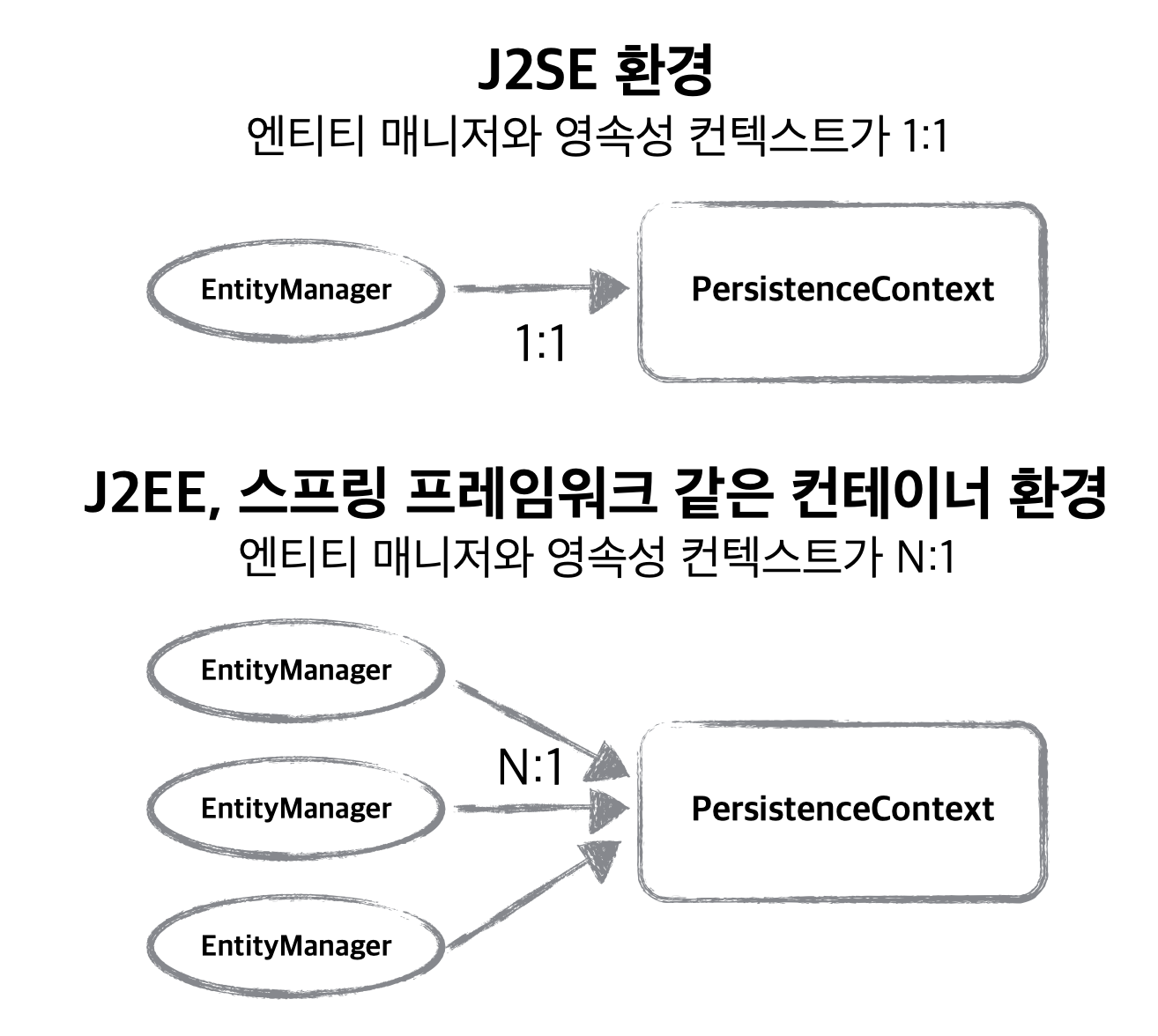
JPA가 설정 정보를 읽어 EntityManagerFactory를 초기화 한다는 것은 알았다. 그런데 여기서 생성되는 EntityManager는 뭘까?
EntityManager
EntityManager는 영속성 컨텍스트에 접근하기 위해 사용하는 객체이다.
스프링 프레임워크 환경에서는 여러 엔티티 매니저가 하나의 영속성 컨텍스트에 접근하는 방식이 사용된다.
그리고 이러한 EntityManager를 생성하는 것이 EntityManagerFactory이다.
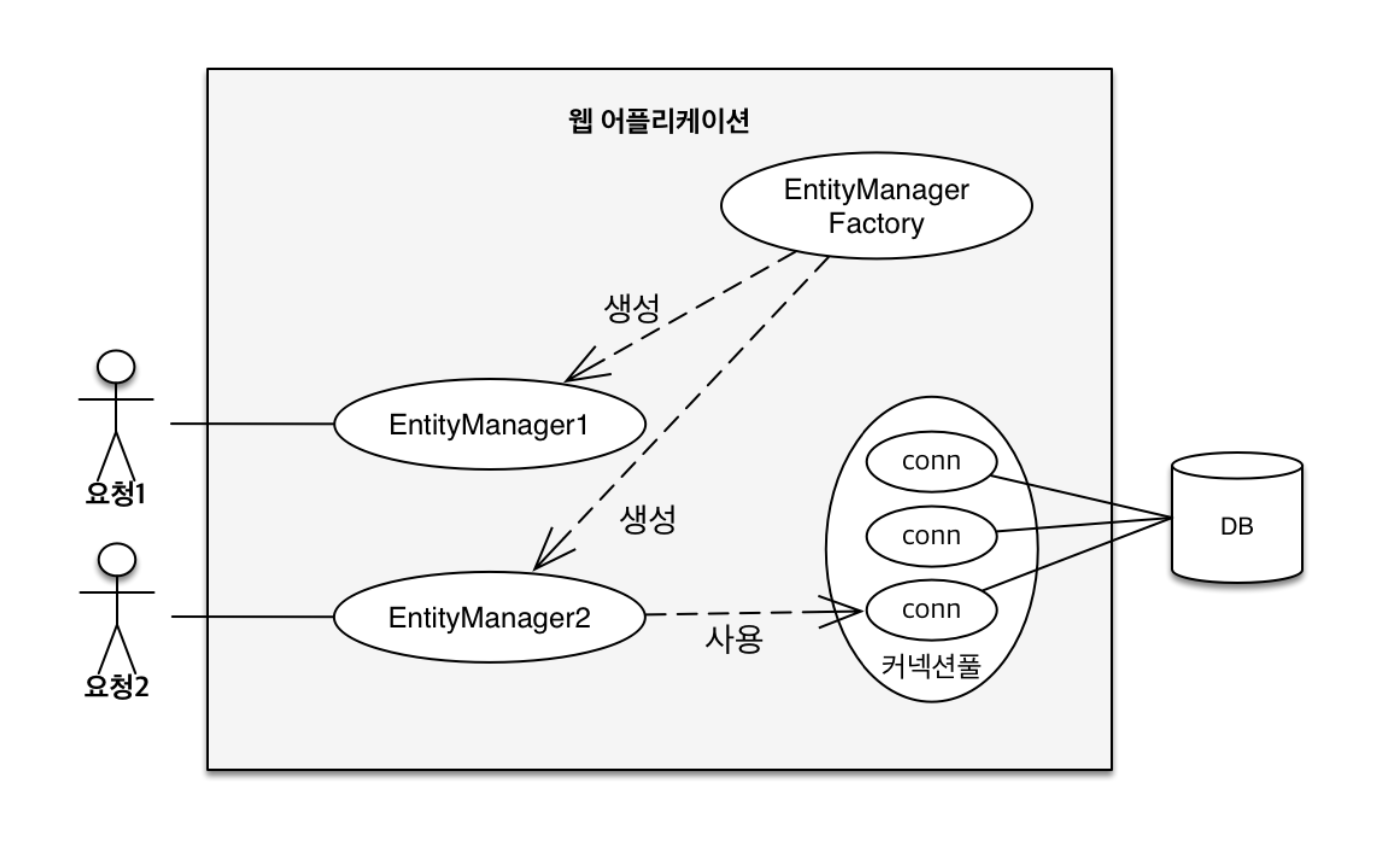
영속성 컨텍스트에 직접 접근하지 않고 EntityManager를 통해 접근하는 이유는 영속성 컨텍스트에 대해 이해한 뒤에 살펴보자.
Persistence context
영속성 컨텍스트는 JPA에서 가장 중요한 개념이다.
강의에서는 "엔티티를 영구 저장하는 환경"으로 풀어서 해석하고 있다.
영속성 컨텍스트에서 엔티티는 어떻게 저장되고 관리되는지 알아보자.
엔티티의 생명주기
영속성 컨텍스트는 엔티티를 관리하는 환경이다. 엔티티는 다음과 같은 생명주기를 갖는다.
- 비영속(new/transient)

//객체를 생성한 상태(비영속)
Member member = new Member();
member.setId("member1");
member.setUsername("회원1");- 영속(managed)
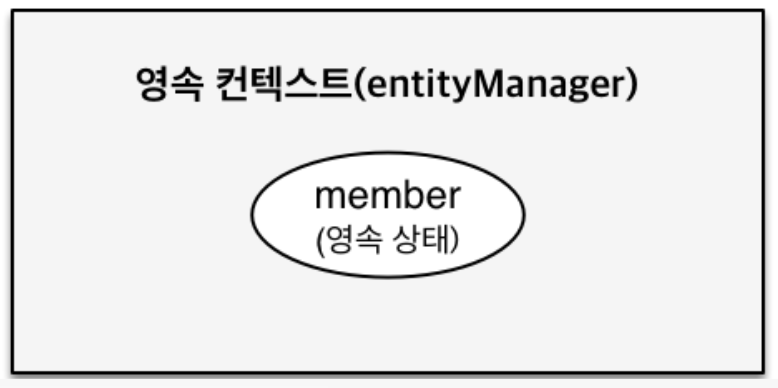
//객체를 생성한 상태(비영속)
Member member = new Member();
member.setId("member1");
member.setUsername(“회원1”);
EntityManager em = emf.createEntityManager();
em.getTransaction().begin();
//객체를 저장한 상태(영속)
em.persist(member);- 준영속(detached)
//회원 엔티티를 영속성 컨텍스트에서 분리, 준영속 상태
em.detach(member);- 삭제(removed)
//객체를 삭제한 상태(삭제)
em.remove(member);영속성 컨텍스트의 동작 원리
1차 캐시
JPA에서 엔티티를 저장하면 1차 캐시에 저장된다.
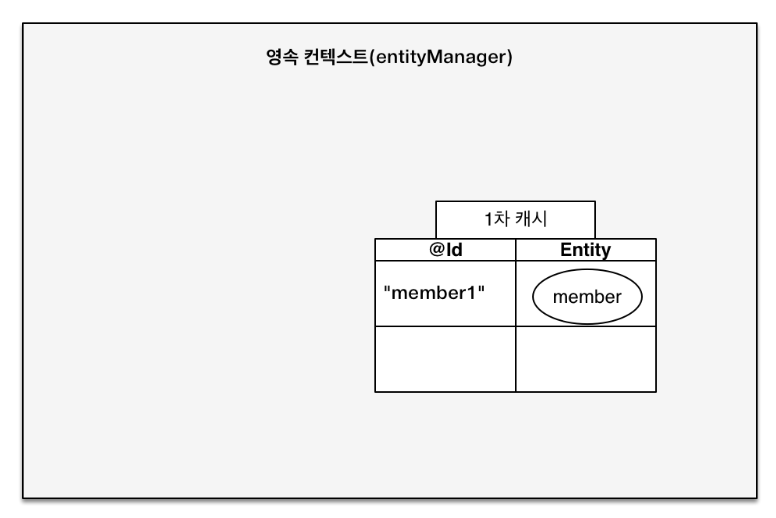
//엔티티를 생성한 상태(비영속)
Member member = new Member();
member.setId("member1");
member.setUsername("회원1");
//엔티티를 영속
em.persist(member);캐시에서 조회
엔티티를 조회할 때 1차 캐시에 엔티티가 있다면 DB 조회 없이 캐싱된 값을 조회한다.
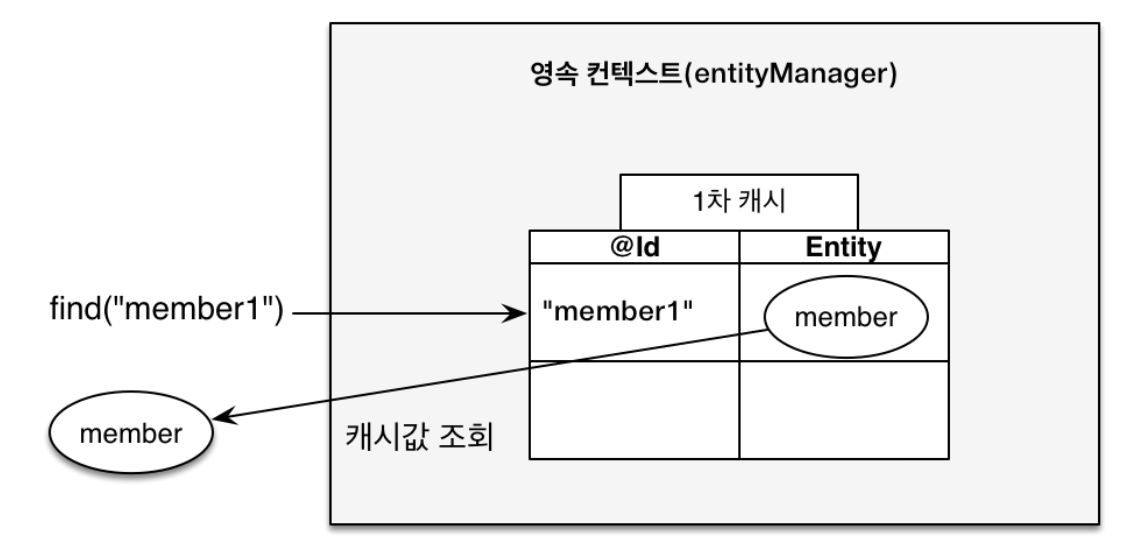
Member member = new Member();
member.setId("member1");
member.setUsername("회원1");
//1차 캐시에 저장됨
em.persist(member);
//1차 캐시에서 조회
Member findMember = em.find(Member.class, "member1");DB에서 조회
1차 캐시에서 ID로 조회했을 때 캐싱된 엔티티가 없다면 DB 조회 후 1차 캐시에 저장하고 해당 엔티티를 반환한다.
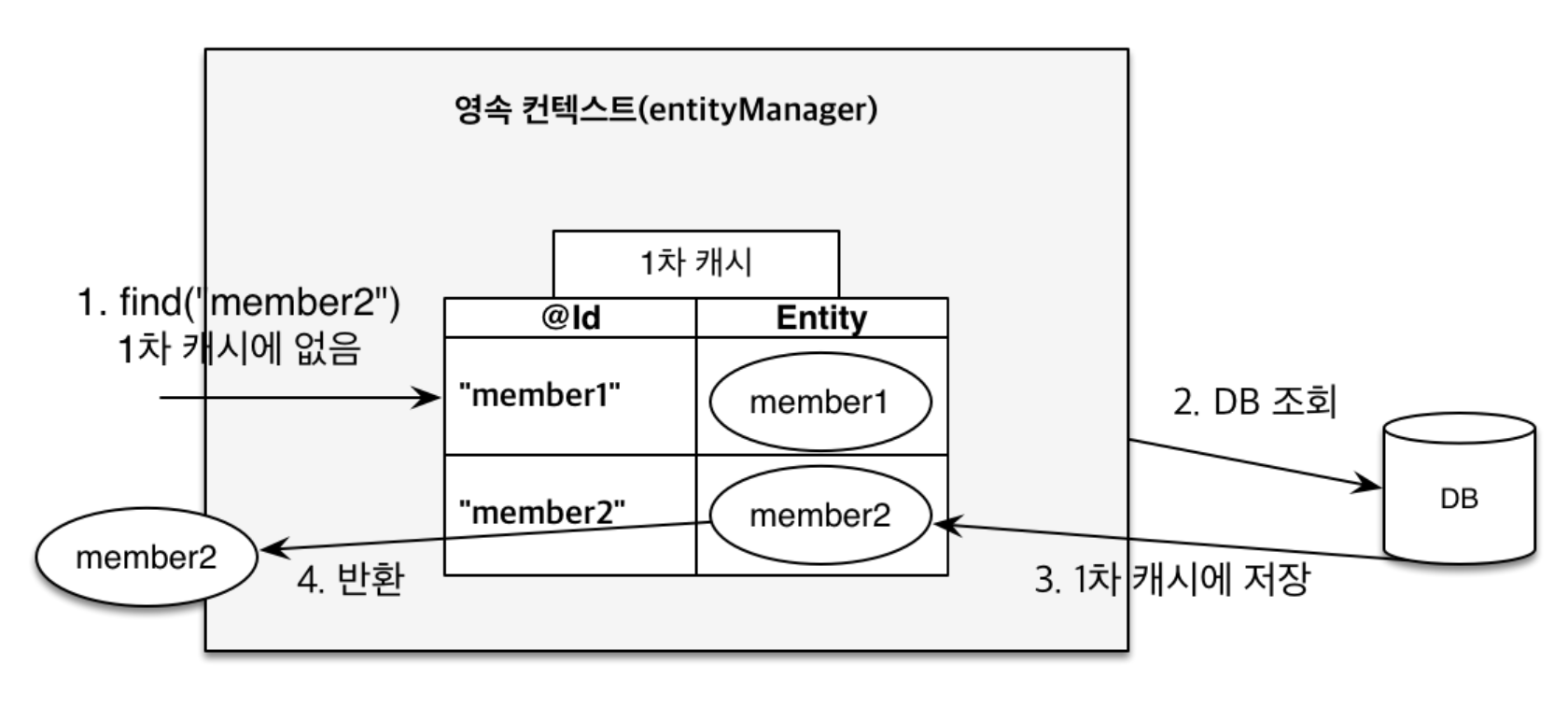
Member findMember2 = em.find(Member.class, "member2");동일성 보장
1차 캐시 덕분에 동일 트랜잭션 내에서 동일한 엔티티를 조회할 경우 같은 객체를 꺼내오기 때문에 비교 연산자를 사용했을 때 같은 객체라는 결과를 얻게 된다.
Member a = em.find(Member.class, "member1");
Member b = em.find(Member.class, "member1");
System.out.println(a == b); //동일성 비교 true쓰기 지연
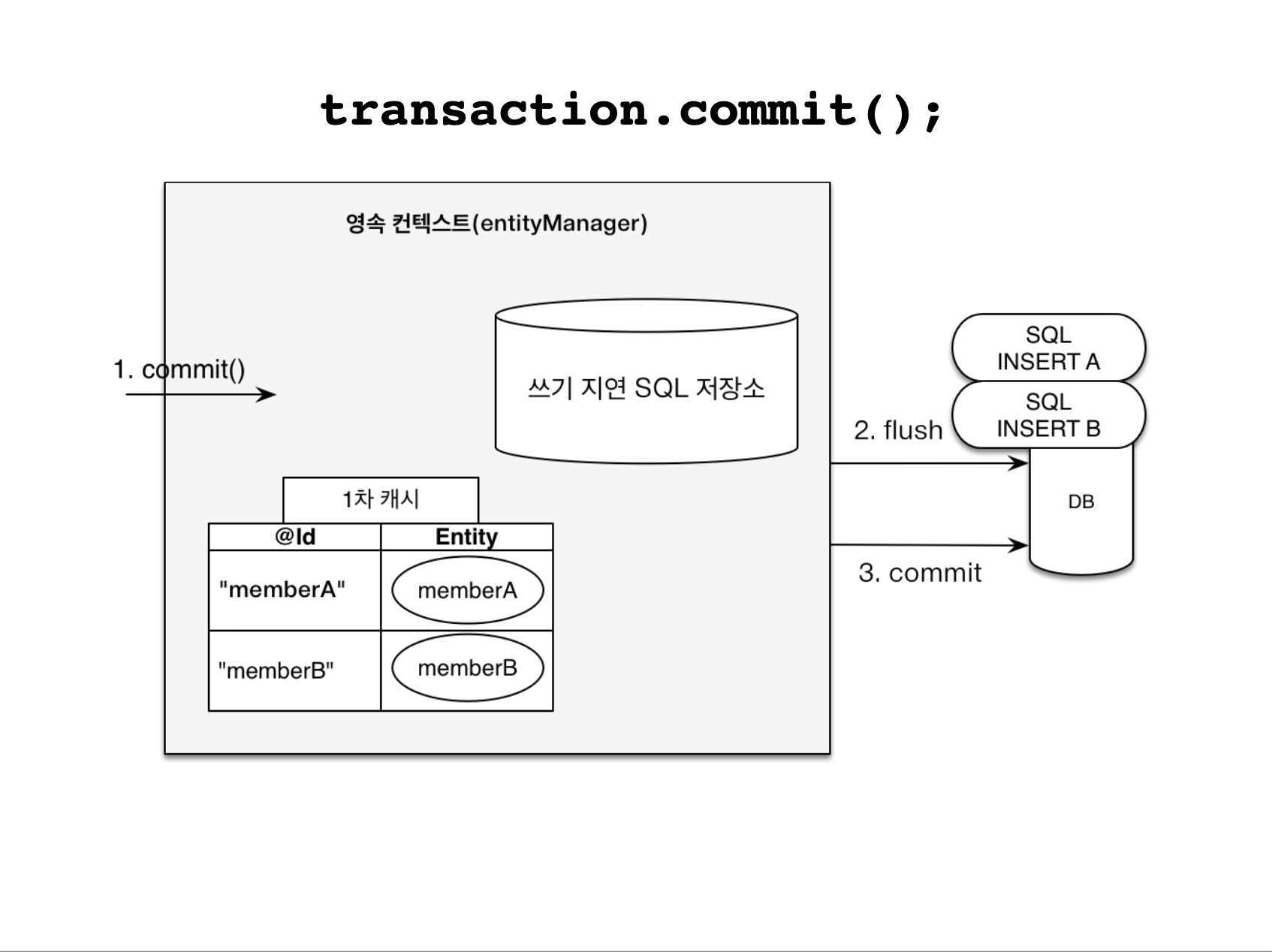
영속 컨텍스트에는 쓰기 지연 SQL 저장소가 있다.
persist() 메서드 호출 시 INSERT문을 생성해 쓰기 지연 SQL 저장소에 INSERT문을 저장하고 COMMIT 시점에 모아져있는 SQL을 flush한다.
EntityManager em = emf.createEntityManager();
EntityTransaction transaction = em.getTransaction();
//엔티티 매니저는 데이터 변경시 트랜잭션을 시작해야 한다.
transaction.begin(); // [트랜잭션] 시작
em.persist(memberA);
em.persist(memberB);
//여기까지 INSERT SQL을 데이터베이스에 보내지 않는다.
//커밋하는 순간 데이터베이스에 INSERT SQL을 보낸다.
transaction.commit(); // [트랜잭션] 커밋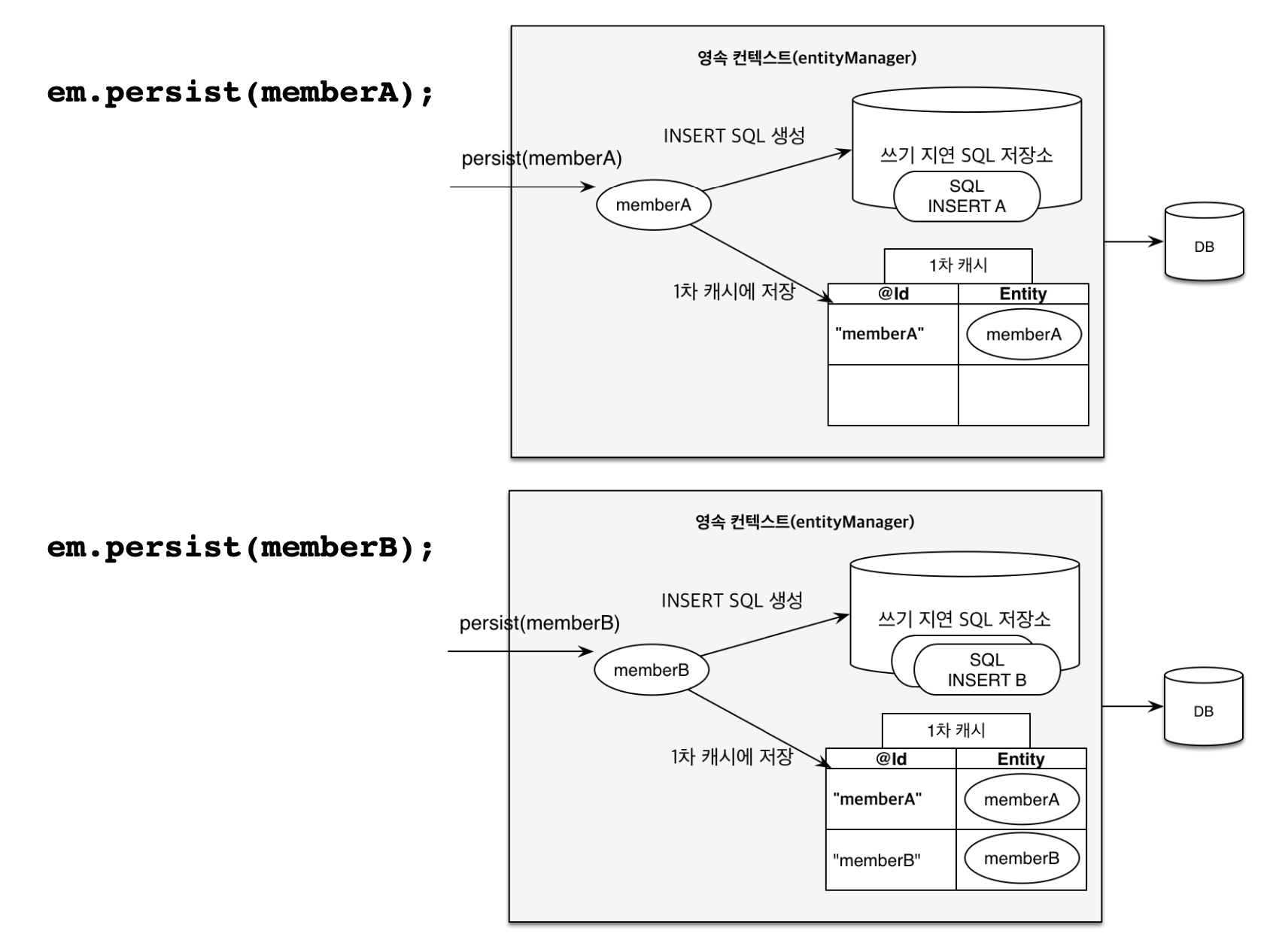
변경 감지(Dirty checking)
UPDATE의 경우 변경 감지(Dirty checking)을 수행하며 그 과정은 다음 그림과 같다.
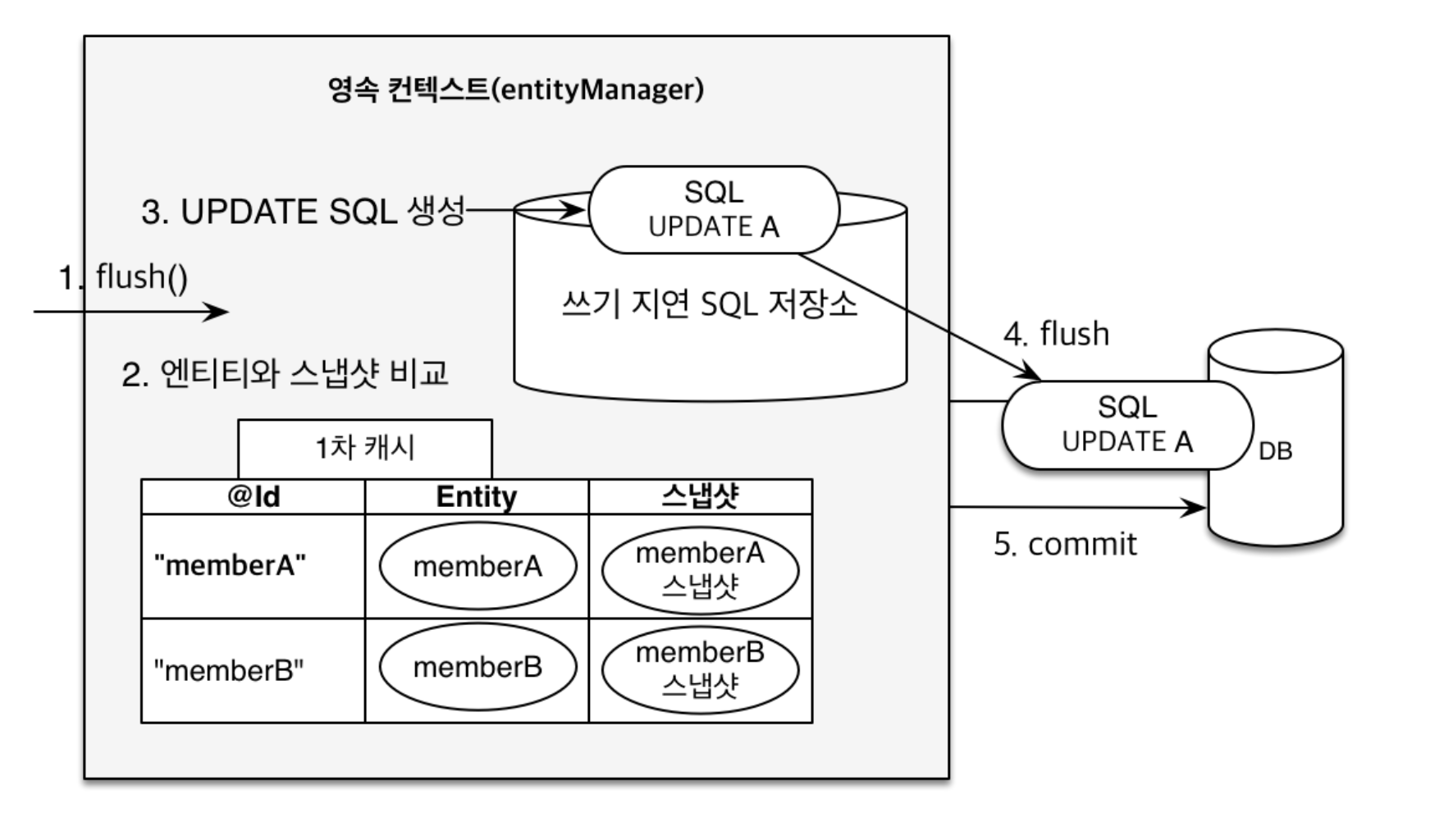
이 때, 스냅샷의 생성 시점은 다음 3가지가 있다.
- 엔티티를 영속화(
persist()) 할 때 - 엔티티를 DB에서 조회(
find())할 때 - 트랜잭션 커밋 전
flush()가 실행될 때
a. UPDATE된 엔티티가 flush 되면 새로운 스냅샷이 생성된다.
UPDATE를 수행하는 코드는 다음과 같다.
영속성 컨텍스트에서 엔티티 변경사항을 감지하고 알아서 UPDATE 쿼리를 수행하기 때문에 엔티티의 속성값만 변경해도 UPDATE가 수행되는 것을 볼 수 있다.
EntityManager em = emf.createEntityManager();
EntityTransaction transaction = em.getTransaction();
transaction.begin(); // [트랜잭션] 시작
// 영속 엔티티 조회
Member memberA = em.find(Member.class, "memberA");
// 영속 엔티티 데이터 수정
memberA.setUsername("hi");
memberA.setAge(10);
//em.update(member) 이런 코드가 없어도 된다!
transaction.commit(); // [트랜잭션] 커밋Flush
flush는 영속성 컨텍스트의 변경사항을 DB에 반영하는 것이다.
즉, 쓰기 지연 SQL 저장소의 쿼리를 DB에 전송하는 것이다.
flush는 다음과 같은 경우 발생한다.
- 직접 호출 -
em.flush() - 트랜잭션 커밋 -
tx.commit() - JPQL 쿼리 실행
그런데 JPQL 실행 시에는 왜 flush가 실행될까? 아래 코드를 보자.
em.persist(memberA);
em.persist(memberB);
em.persist(memberC);
//중간에 JPQL 실행
query = em.createQuery("select m from Member m", Member.class);
List<Member> members= query.getResultList();JPQL은 SQL로 변환되어 바로 실행된다. 그런데 앞서 영속화한 3개의 객체는 1차 캐시에 등록되었을 뿐, DB에는 저장되지 않았다. 따라서 flush가 일어나지 않고 JPQL이 실행되면 DB에서 SELET할 데이터가 없는 상황이 발생한다. 이러한 상황을 방지하기 위해 JPQL 실행 전에 flush가 호출된다.
⚠️ 유의사항
flush는 영속성 컨텍스트를 비우지 않는다.
쓰기 지연 SQL 저장소에 쌓인 쿼리를 DB에 전달할 뿐!
엔티티 매핑
@Entity
@Entity가 붙은 클래스를 엔티티라 하며 JPA가 관리하게 된다.
속성
name- JPA에서 사용할 엔티티 이름을 지정한다
- 기본값: 클래스 이름을 그대로 사용
- 가급적 기본값을 사용하자
⚠️ 유의사항
- 기본 생성자 필수
- JPA가 프록시 객체를 생성할 때 사용하기 때문
- 자세한 내용은 이 글을 참고
- DB에 저장할 필드에
final을 사용하면 안 됨
@Table
@Table은 엔티티와 매핑할 테이블을 지정한다.
속성
name: 매핑할 테이블 이름(기본값: 엔티티 이름)catalog: DB catalog 매핑schema: DB schema 매핑uniqueContstaints: DDL 생성 시 유니크 제약 조건 생성
DB 스키마 자동 생성
DDL을 애플리케이션 실행 시점에 생성해주는 기능이다.
선택한 DB Dialect에 맞는 적절한 DDL을 생성해준다.
이렇게 생성된 DDL은 개발 환경에서만 사용하는 것이 좋다.
생성된 DDL은 운영 서버에는 사용하지 않거나 적절히 다듬어서 쓰는 것이 좋다.
DB 스키마 자동 생성 옵션
create: 기존 테이블 삭제 후 다시 생성(DROP + CREATE)create-drop: create와 같으나 종료시점에 테이블 DROPupdate: 변경분만 반영, 컬럼 삭제는 반영 안 됨.(운영 DB에는 사용하면 안 됨)validate: 엔티티와 테이블이 정상 매핑되었는지만 확인none: 사용하지 않음
⚠️ 유의사항
- 운영 장비에는 절대 create, create-drop, update를 사용하지 말자
- 개발 초기 단계는 create 또는 update
- 테스트 서버는 update 또는 validate
- 스테이징과 운영 서버는 validate 또는 none
- (강의에서는 왠만하면 로컬에서만 스키마 자동 생성 기능을 사용하고 다른 사람들과 함께 사용하는 DB에는 그냥 쓰지 않는게 낫다고 한다..)
DDL 생성 기능
DDL 생성 기능은 DDL을 자동 생성할 때만 사용되고 JPA의 실행 로직에는 영향을 주지 않는다.
-
@Column// 회원 이름은 유니크 O, 필수, 10자 초과 X @Column(unique = true, nullable = false, length = 10) -
@UniqueConstraint@Table(uniqueConstraints = {@UniqueConstraint(name = "NAME_AGE_UNIQUE", columnNames = {"NAME", "AGE"})}) -
제약 조건 추가 가능
@Column(nullable = false, length = 10)
-
유니크 제약조건 추가
@Table(uniqueConstraints = {@UniqueConstraint( = name"NAME_AGE_UNIQUE", columnNames = {"NAME", "AGE"})})
필드와 컬럼 매핑
@Column
컬럼 매핑에 사용하는 어노테이션
unique 속성의 단점
하나의 컬럼에만 적용할 수 있고 제약조건 이름 또한 랜덤한 값으로 설정된다.
따라서 실무에서는 @Table의 uniqueContstaints를 사용하는 것을 더욱 선호한다고 한다.
@Enumerated
자바 enum 타입을 매핑할 때 사용

⚠️ 유의사항
- Enum 타입의 기본값은
ORDINAL이다.- 단, 절대로
ORDINAL을 사용하지 말자!- Enum에 USER, ADMIN 두 가지가 있다가 맨 앞에 GUEST라는 값을 추가하면 0번에 해당하는 값이 USER에서 GUEST로 변경되면서 섞이는 대참사가 발생한다..
@Temporal
날짜 타입(java.util.Date, java.util.Calendar)을 매핑할 때 사용
참고: LocalDate, LocalDateTime을 사용할 때는 생략 가능(최신 하이버네이트 지원)

@Lob
데이터베이스 BLOB, CLOB 타입과 매핑
@Lob에는 지정할 수 있는 속성이 없다- 매핑하는 필드 타입이 문자면 CLOB 매핑, 나머지는 BLOB 매핑
- CLOB:
String,char[],java.sql.CLOB - BLOB:
byte[],java.sql.BLOB
- CLOB:
@Transient
필드 매핑을 하지 않을 때 사용한다.
해당 필드는 DB에 저장되지도, 조회할 수도 없다.
주로 메모리에서만 임시로 어떤 값을 보관하고 싶을 때 사용한다.
기본 키 매핑
기본 키를 직접 할당할 때는 @Id 어노테이션만 사용한다.
기본 키를 자동으로 생성할 경우 @GeneratedValue 어노테이션을 함께 사용한다.
전략은 3가지를 지정할 수 있다.
AUTO (기본값)
SQL Dialect에 따라 전략을 자동으로 지정한다.
IDENTITY
@Entity
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
...
}Id 생성을 DB에 위임한다.
주로 MySQL, PostgreSQL, SQL Server, DB2에서 사용한다.
앞서 알아본 것처럼 JPA는 주로 트랜잭션 커밋 시점에 INSERT SQL을 몰아서 실행한다.
이 Id 생성 방식은 DB에 INSERT문을 실행한 이후에 ID 값을 알 수 있다.
영속성 컨텍스트에 엔티티를 저장하려면 Id를 반드시 알아야 하기 때문에 이 전략을 사용할 경우 em.persist() 시점에 즉시 INSERT 문을 실행하고 DB에서 식별자를 가져오게 된다.
INSERT 시점마다 DB로 네트워크 요청을 보내기 때문에 큰 비효율이 생긴다고 느낄 수도 있으나, 강의에서는 이 정도 요청으로 큰 성능 저하가 있다고 보긴 어렵다는 의견.
SEQUENCE
@Entity
@SequenceGenerator(
name = “MEMBER_SEQ_GENERATOR",
sequenceName = “MEMBER_SEQ", //매핑할 데이터베이스 시퀀스 이름
initialValue = 1, allocationSize = 1)
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE,
generator = "MEMBER_SEQ_GENERATOR")
private Long id; 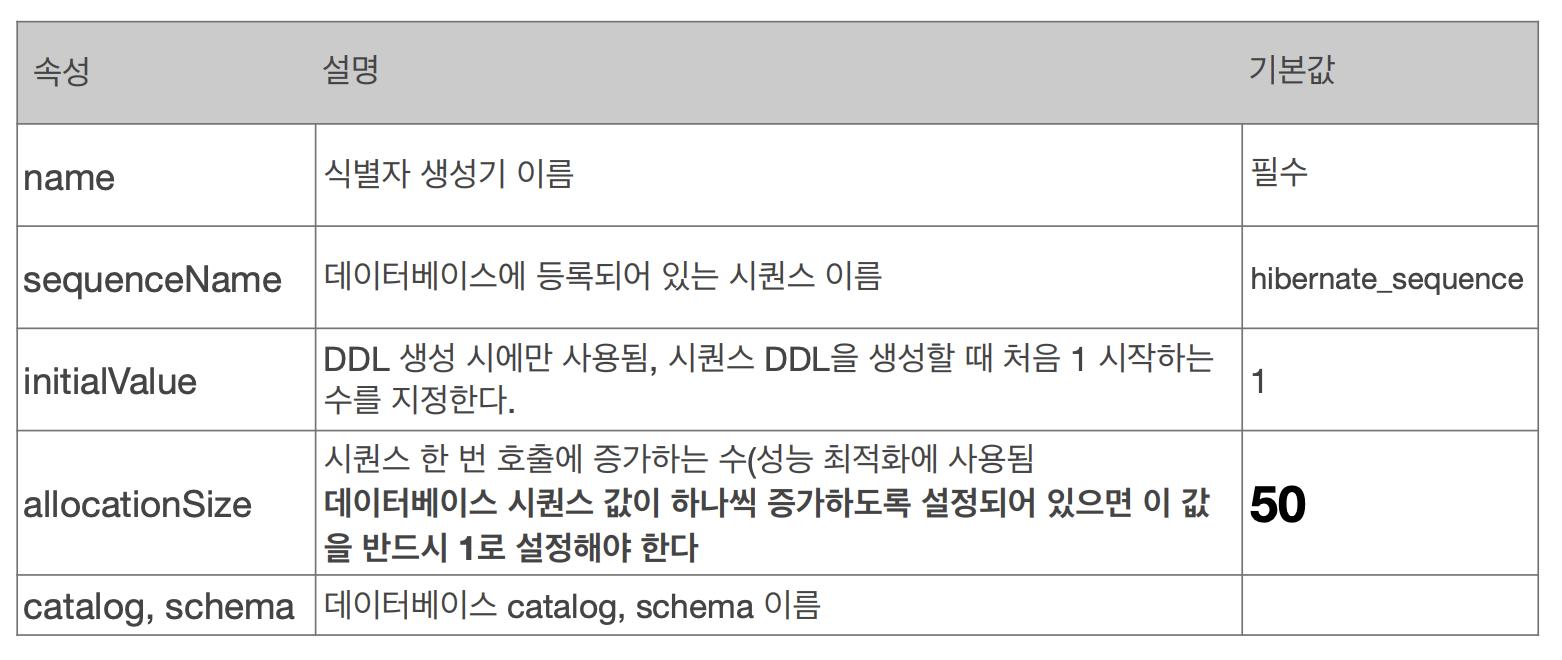
DB Sequence는 유일한 값을 순서대로 생성하는 데이터베이스 오브젝트이다.
주로 오라클, PostgreSQL, DB2, H2에서 사용한다.
이 전략은 allocationSize 조절을 통해 네트워크 요청 횟수를 최적화할 수 있다.
DB Sequence를 사용하고 allocationSize를 50으로 설정했다고 가정해보자.
그럼 WAS는 DB Sequence를 50 단위로 늘리고 그 수만큼 WAS는 메모리에서 Id를 관리한다. 50번의 레코드 생성 동안은 DB로 Id 생성 요청을 하지 않아도 되는 것이다. 따라서 allocateSize마다 DB로 요청을 보내도록 최적화가 가능하다.
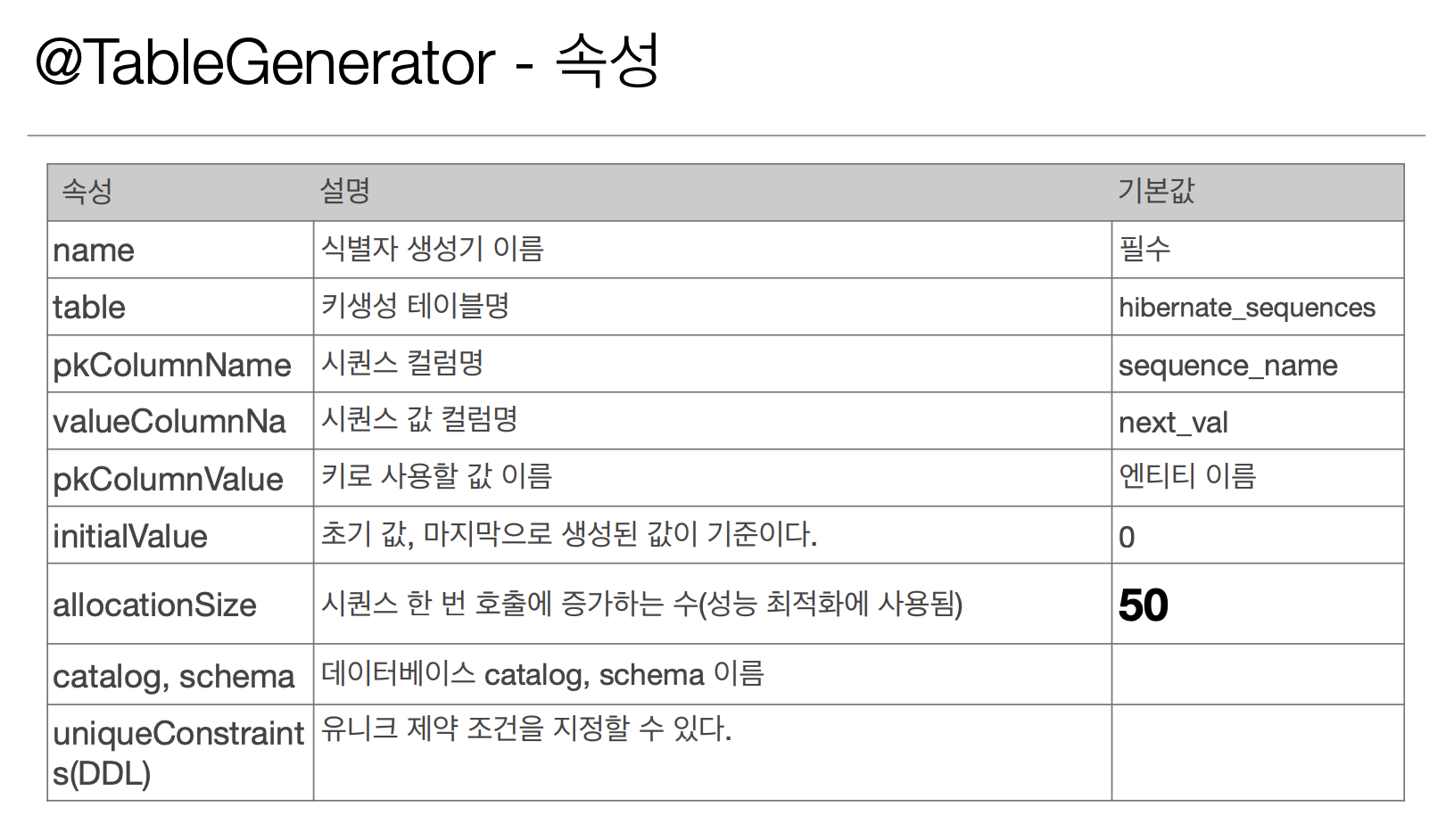
TABLE
@Entity
@TableGenerator(
name = "MEMBER_SEQ_GENERATOR",
table = "MY_SEQUENCES",
pkColumnValue = “MEMBER_SEQ", allocationSize = 1)
public class Member {
@Id
@GeneratedValue(strategy = GenerationType.TABLE,
generator = "MEMBER_SEQ_GENERATOR")
private Long id;
...create table MY_SEQUENCES (
sequence_name varchar(255) not null,
next_val bigint,
primary key ( sequence_name )
)TABLE 전략은 키 생성 전용 테이블을 하나 만들어 DB Sequence를 흉내내는 전략이다.
모든 DB에 적용 가능한 장점이 있지만 성능이 다소 떨어진다는 단점이 있다.
권장하는 식별자 전략
기본 키의 제약 조건은 not null, unique, 불변이다.
먼 미래까지 이 조건을 만족하는 자연키는 찾기 어렵다.
따라서 강의에서는 Long type + 대체키 + 키 생성 전략 사용을 권장한다.
연관관계 매핑 기초
객체를 테이블에 맞춰 설계했을 때의 문제
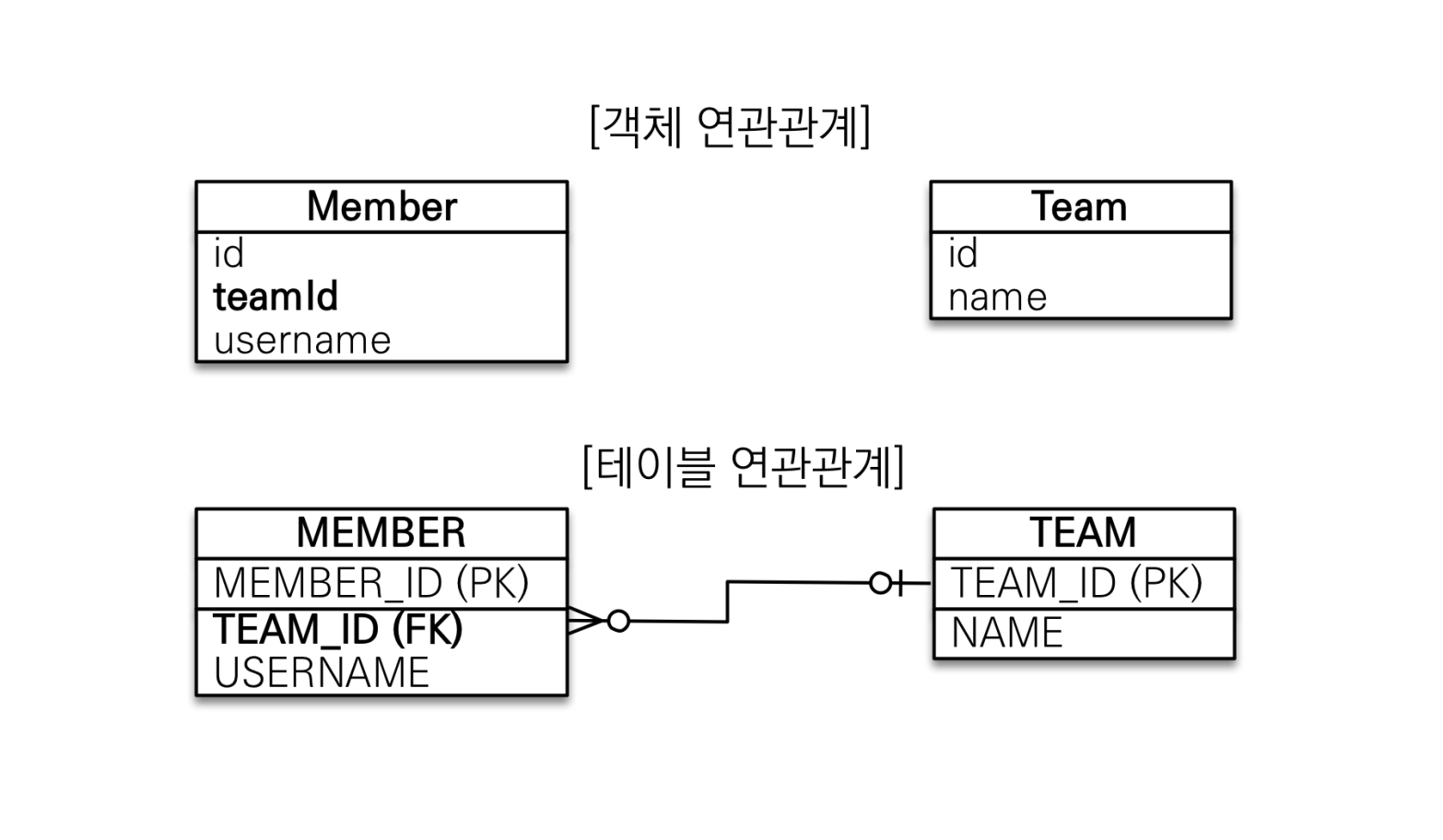
위 이미지처럼 참조를 사용해 객체의 연관관계를 맺지 않고 외래키 정보만을 들고 있게 하면 다음과 같은 문제가 발생한다.
//팀 저장
Team team = new Team();
team.setName("TeamA");
em.persist(team);
//회원 저장
Member member = new Member();
member.setName("member1");
member.setTeamId(team.getId());
em.persist(member);
//조회
Member findMember = em.find(Member.class, member.getId());
//객체 간 연관관계가 없음
Team findTeam = em.find(Team.class, team.getId());테이블 중심 설계로 인해 객체 간 참조를 맺을 수 없어 객체들이 서로 협력하는 객체지향적 설계가 불가능해진다.
이전 회사에서 이렇게 테이블에 종속된 객체 설계를 사용했다. 연관된 테이블의 정보를 조회하기 위해서 매번 SQL에 Id 값을 매핑하는 노가다를 해야 했는데, 정말 인간 SQL 매퍼가 된 것 같은 노가다를 수없이 반복해야 했다.
이를 해결하기 위한 방법을 알아보자.
단방향 연관관계
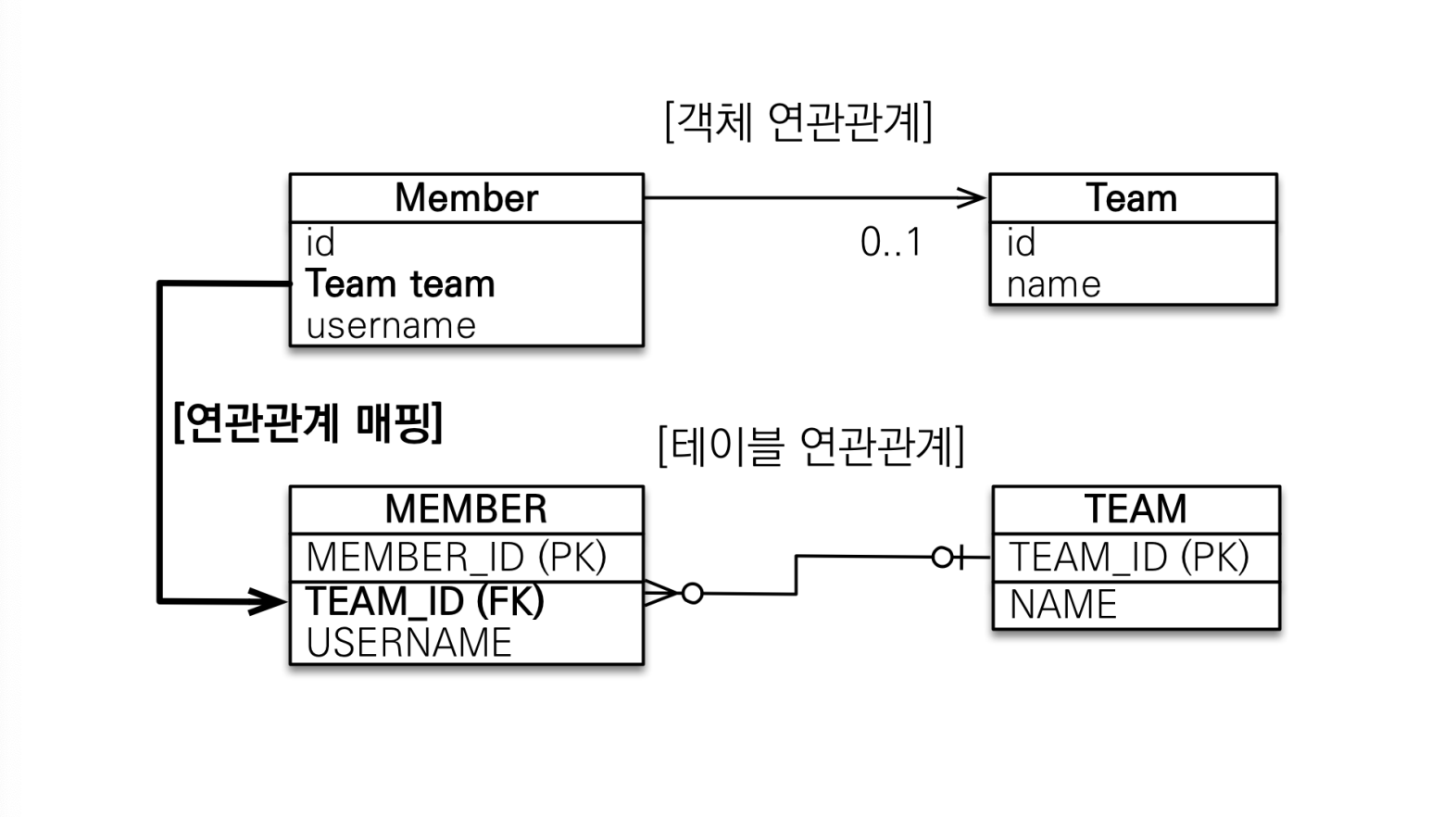
@Entity
public class Member {
@Id
@GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
@Column(name = "USERNAME")
private String username;
// 외래 키 저장 X
// @Column(name = "TEAM_ID")
// private Long teamId;
// 객체를 참조
@ManyToOne
@JoinColumn(name = "TEAM_ID")
private Team team;
...단방향 연관관계는 객체의 참조와 테이블의 외래 키를 매핑한다.
객체에서 외래 키 정보를 저장하지 않고, 해당 객체를 참조하는 것이다.
이 방식을 사용하면 훨씬 객체 지향적인 코드를 작성할 수 있다.
//팀 저장
Team team = new Team();
team.setName("TeamA");
em.persist(team);
//회원 저장
Member member = new Member();
member.setName("member1");
//단방향 연관관계 설정, 참조 저장
//JPA가 team 객체에서 Id 값을 꺼내 FK로 Insert한다
member.setTeam(team);
em.persist(member);
//INSERT문 flush
em.flush();
//영속성 컨텍스트 초기화
em.clear();
//DB에서 조회
//여기서 member 조회 시 Team을 join으로 바로 가져오는 EAGER Loading이 기본 세팅
Member findMember = em.find(Member.class, member.getId());
//참조를 사용해서 연관관계 조회
// LAZY Loading으로 설정하면 Team에 접근하는 시점에 별도의 select 쿼리를 실행
Team findTeam = findMember.getTeam();
// 새로운 팀B
Team teamB = new Team();
teamB.setName("TeamB");
em.persist(teamB);
// 회원1에 새로운 팀B 설정
member.setTeam(teamB);양방향 연관관계
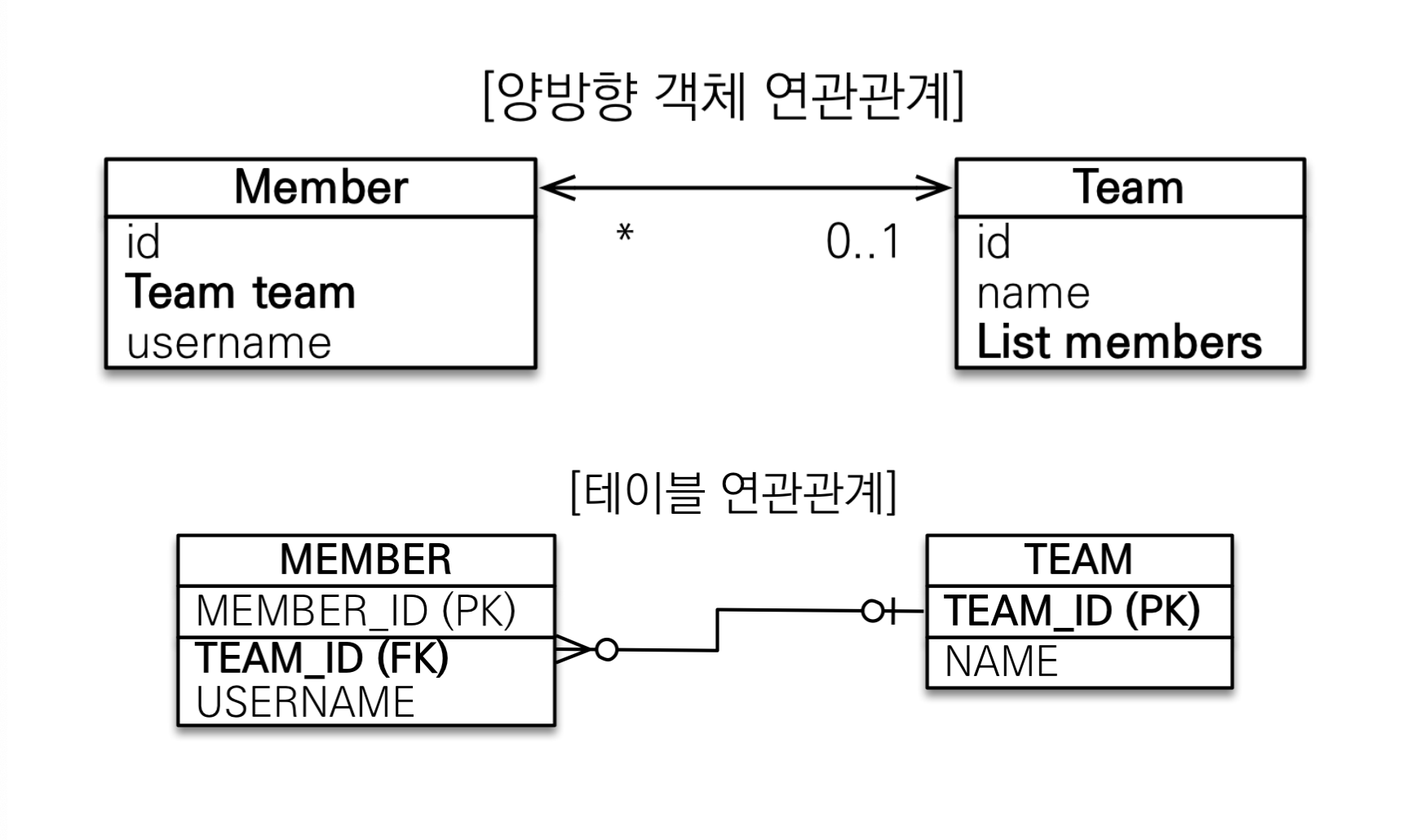
테이블은 FK 하나로 양방향 연관관계가 설정된다.
반면, 객체의 양방향 연관관계는 단방향 연관관계 2개를 맺는 것과 동일하다.
- 회원 -> 팀 연관관계 1개 (단방향)
- 팀 -> 회원 연관관계 1개 (단방향)
그렇다면, 여기서 한 가지 궁금한 점이 생긴다.
2개의 단방향 관계 중, 외래 키 등록을 수행하는 관계는 둘 중 무엇일까?
아래 그림에서 Member 객체에 teamA를 할당하고 Team 객체에는 Member 객체를 추가하지 않는다면 DB의 Member 테이블에는 team_id 외래키의 값이 들어갈까? 아니면 null이 될까?
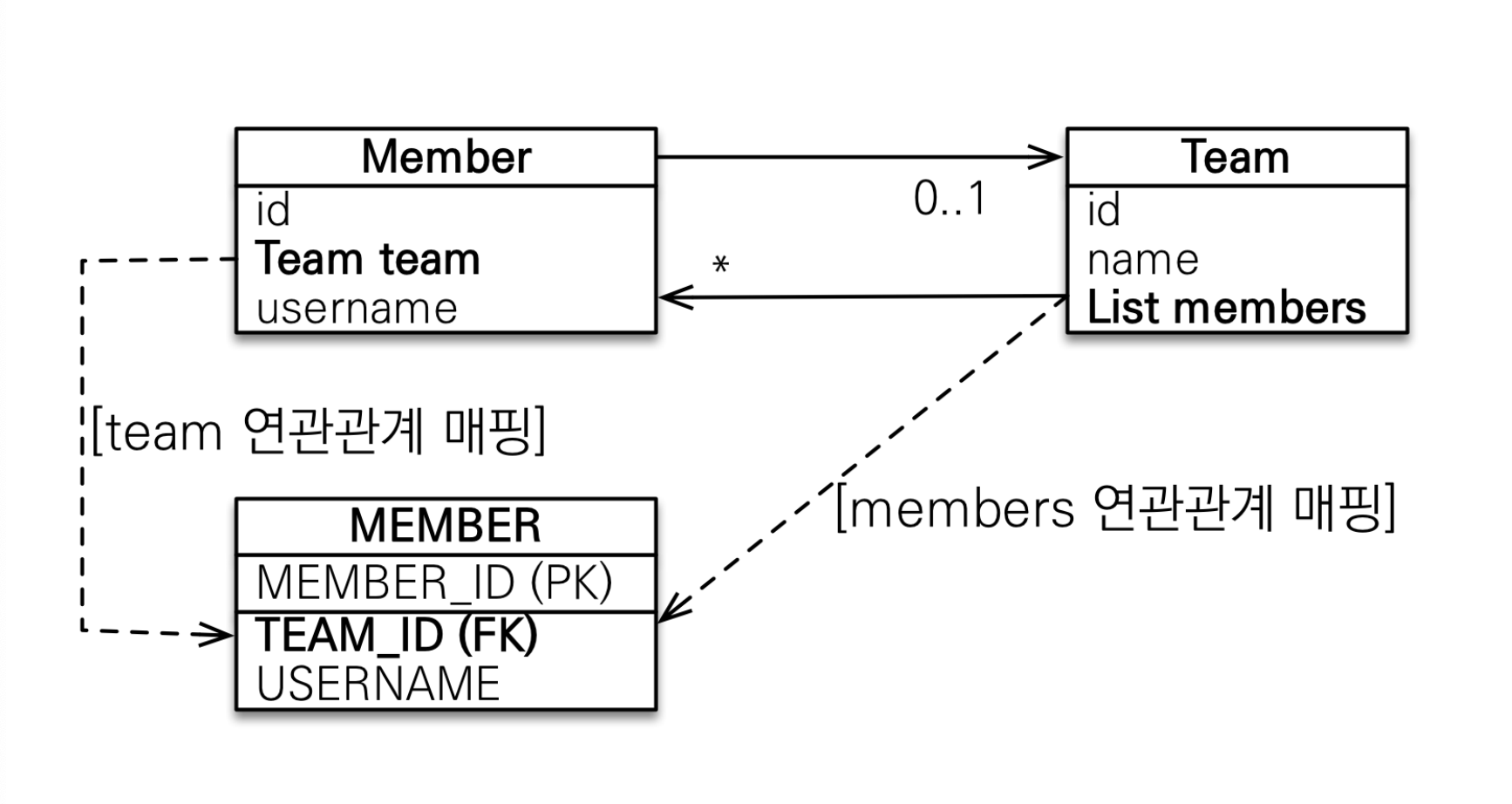
JPA는 이 문제를 해결하기 위해 어떤 연관관계가 데이터 변경사항에 영향을 줄지 규칙을 정해두고 있다.
강의에서는 "연관관계의 주인"이라는 개념으로 소개하고 있다.
이 규칙은 다음과 같다.
- 두 관계 중 하나를 연관관계의 주인으로 지정한다.
- 연관관계의 주인만이 외래키를 관리(등록, 수정)한다.
- 주인이 아닌 쪽은 읽기만 가능하다.
- 주인은
mappedBy속성을 사용하지 않는다. - 주인이 아니면
mappedBy속성으로 주인을 지정한다.
코드로 보면 다음과 같다.
//연관관계의 주인인 Member 클래스
@Entity
public class Member {
@Id
@GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
@Column(name = "USERNAME")
private String username;
@ManyToOne
@JoinColumn(name = "TEAM_ID")
private Team team;
...//Team 클래스
@Entity
public class Team {
@Id
@GeneratedValue
@Column(name = "TEAM_ID")
private Long id;
private String name;
//주인 클래스를 mappedBy로 표시
@OneToMany(mappedBy = "team")
private List<Member> members = new ArrayList<>();
...그렇다면, 어떤 객체를 주인으로 설정해야 할까?
강의에서는 외래 키가 있는 곳을 주인으로 정하라고 안내한다.
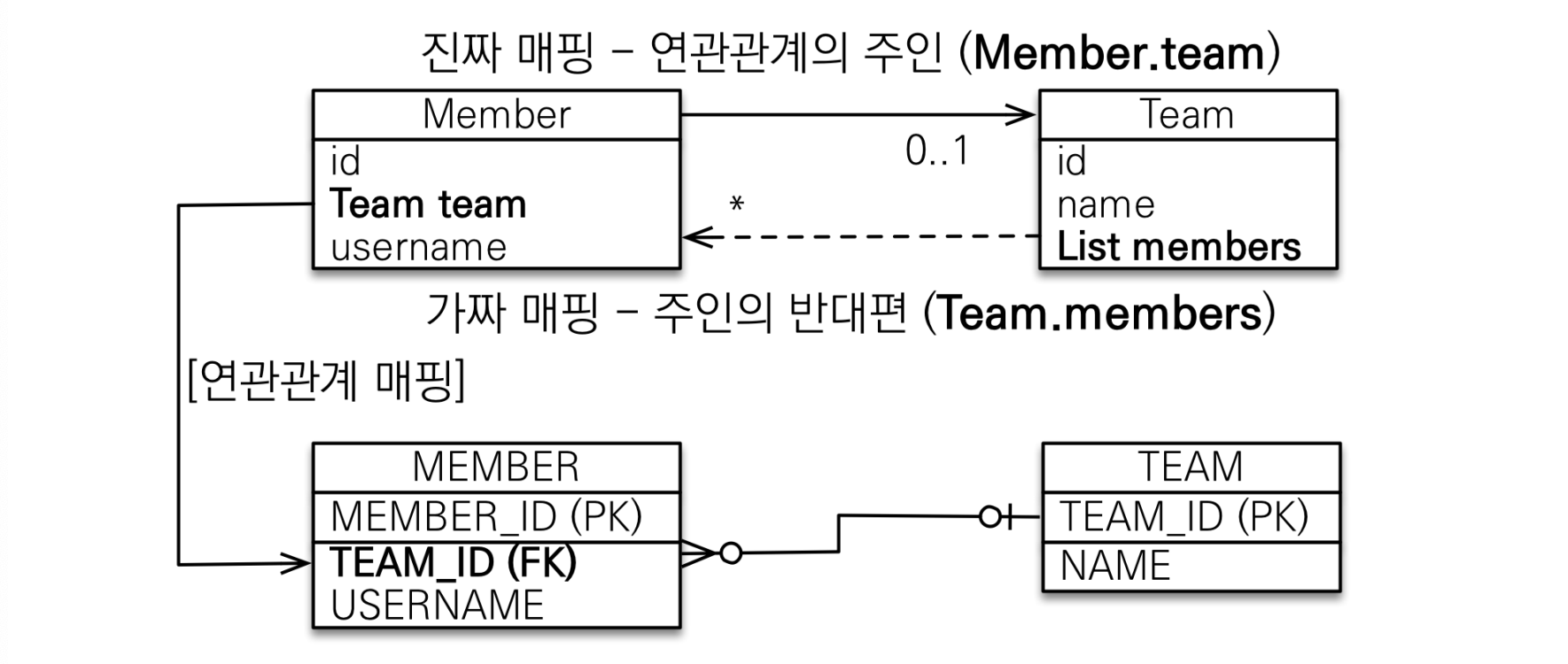
양방향 매핑 시 주의사항
연관관계의 주인에 변경사항을 적용하라
연관관계의 주인이 아닌 객체에 변경사항을 적용해도 DB에는 아무런 변화가 일어나지 않는다.
주인이 아닌 객체는 읽기 전용이기 때문이다.
따라서 데이터 변경사항을 DB에 반영하려면 반드시 연관관계의 주인에 변경사항을 적용하자.
//Team 생성, 영속화
Team team = new Team();
team.setName("TeamA");
em.persist(team);
//Member 생성, 영속화
Member member = new Member();
member.setName("member1");
//역방향(주인이 아닌 방향)만 연관관계 설정
team.getMembers().add(member);
em.persist(member);
//DB에 반영되지 않음
// ID USERNAME TEAM_ID
// 1 member1 null//Team 생성, 영속화
Team team = new Team();
team.setName("TeamA");
em.persist(team);
//Member 생성, 영속화
Member member = new Member();
member.setName("member1");
//연관관계의 주인에 값 입력
//JPA가 insert문 생성 시 team 객체의 id 값을 Member의 외래 키로 사용
member.setTeam(team);
//DB에 반영됨
// ID USERNAME TEAM_ID
// 1 member1 2연관관계의 주인이 아닌 객체에도 변경사항을 적용하라
그렇다고 해서 연관관계의 주인이 아닌 객체에 변경사항을 적용할 필요가 없는 것은 아니다.
바로 위 코드에서 트랜잭션 종료 전 team 객체의 members size를 확인해보자.
//Team 생성, 영속화
Team team = new Team();
team.setName("TeamA");
em.persist(team);
//Member 생성, 영속화
Member member = new Member();
member.setName("member1");
//연관관계의 주인에 값 입력
member.setTeam(team);
//team 객체에서 member 조회
int memberCnt = team.getMembers().size();
// memberCnt = 0 출력
System.out.println("memberCnt = " + memberCnt);
//커밋 완료 후 DB 상태
// ID USERNAME TEAM_ID
// 1 member1 2team 객체의 members의 크기는 0인 것을 알 수 있다.
커밋 전 영속성 컨텍스트의 team 객체는 아무런 변화가 없기 때문이다.
이러한 현상을 방지하기 위해 연관관계의 주인이 아닌 객체에도 변경사항을 반영해주자.
//Team 생성, 영속화
Team team = new Team();
team.setName("TeamA");
em.persist(team);
//Member 생성, 영속화
Member member = new Member();
member.setName("member1");
//연관관계의 주인에 값 입력
member.setTeam(team);
//연관관계 주인이 아닌 객체에도 변경사항 반영
team.getMembers().add(member);
//team 객체에서 member 조회
int memberCnt = team.getMembers().size();
// memberCnt = 0 출력
System.out.println("memberCnt = " + memberCnt);
//커밋 완료 후 DB 상태
// ID USERNAME TEAM_ID
// 1 member1 2이처럼 양쪽 모두 값을 설정해주는 것이 좋기 때문에 아래처럼 연관관계 편의 메서드를 생성하는 것도 좋은 방법이다.
@Entity
public class Team {
...
//양쪽 모두에 값을 설정해주는 편의 메서드
//어느 쪽에 편의 메서드를 만들지는 상황에 맞게
public void addMember(Member member) {
members.add(member);
member.setTeam(this);
}순환 참조 주의
양방향 연관관계 설정 시에는 순환 참조를 조심해야 한다.
대표적으로 toString() 사용이나, JSON 라이브러리 사용 시 주의해야 한다.
toString()을 예시로 순환 참조 문제 예시를 살펴보자.
@Entity
public class Member {
...
@Override
public String toString() {
return "Member{" +
"id=" + id +
", username='" + username + '\'' +
", team=" + team +
'}';
}
}@Entity
public class Team {
...
@Override
public String toString() {
return "Team{" +
"id=" + id +
", name='" + name + '\'' +
", members=" + members +
'}';
}
}이렇게 양방향 관계가 설정된 두 객체에 toString() 메서드를 추가하고 출력하면 순환 참조로 인한 스택 오버플로가 발생한다.
Team team = new Team();
team.setName("TeamA");
em.persist(team);
Member member = new Member();
member.setUsername("member1");
member.setTeam(team);
em.persist(member);
team.addMember(member);
//출력 시 순환 참조로 인한 스택 오버플로 발생
System.out.println("member = " + member);
// Exception in thread "main" java.lang.StackOverflowError이처럼 순환 참조가 발생하지 않도록 toString() 메서드 생성 시 주의해야하며
Spring MVC에서는 Entity를 바로 반환하기보다 DTO로 변환하는 과정을 거쳐 JSON 변환 과정에서 순환 참조 발생을 막는 것이 좋다.
양방향 매핑 정리
연관관계 매핑은 단방향 매핑만으로도 완료된다.
다만 양방향 매핑은 반대 방향으로 조회하는 것을 보다 용이하게 할 뿐이다.
따라서 처음 설계할 때는 단방향 매핑만으로 코드를 작성하고 디벨롭 과정에서 역방향 조회가 필요한 부분에만 양방향 매핑을 추가하면 된다.
다양한 연관관계 매핑
JPA는 4가지 연관관계 매핑 방법을 제공한다.
- 다대일:
@ManyToOne - 일대다:
@OneToMany - 일대일:
@OneToOne - 다대다:
@ManyToMany
다대일 연관관계는 가장 많이 사용되고 권장되는 방식이다. 다대일 매핑으로 연관관계 주인을 설정하고 역방향 조회가 필요할 경우 읽기 전용 일대다 매핑을 통해 양방향 매핑을 설정하는 방법을 알아보았으니 다대일 매핑 설명은 생략한다.
일대다 단방향
일대다 단방향은 1:N에서 1이 연관관계의 주인이 되는 방식이다.
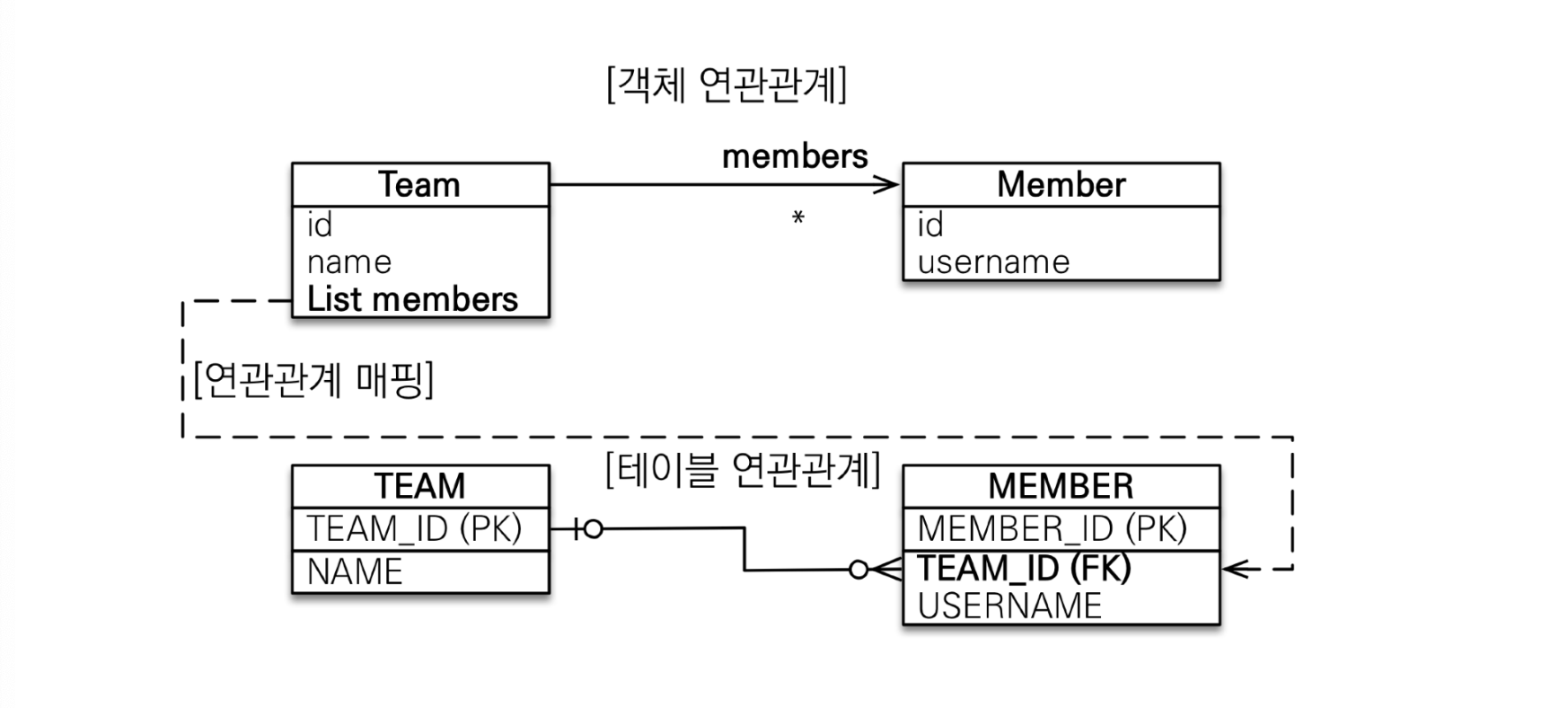
이 방식은 두 가지 단점이 있다.
첫째, 엔티티가 관리하는 외래 키가 다른 테이블에 있다. 위 그림을 보면 Team 객체가 Member 테이블의 외래 키를 관리하는 주체가 된다. 이것부터가 혼란을 야기하는 큰 단점이다.
둘째, 연관관계 관리를 위해 추가적인 UPDATE 쿼리가 실행된다. 직접 코드를 실행해 로그를 살펴보면 Team 객체를 INSERT할 때, Member 객체도 수정해야 하기 때문에 UPDATE 쿼리가 실행되는 것을 볼 수 있다.
따라서 왠만하면 이 방법 대신, 다대일 단방향, 다대일 양방향 매핑을 사용하자.
일대다 양방향
애초에 공식적으로 지원하는 스펙도 아니며, 안티패턴이나 마찬가지이므로 왠만하면 쓰지 말자.
일대일
일대일 매핑은 아래 두 가지 방법 중 하나를 사용하면 된다.
여기서 주 테이블이란, 주로 조회가 많이 일어나는 테이블을 말한다.
주 테이블에 외래 키 양방향
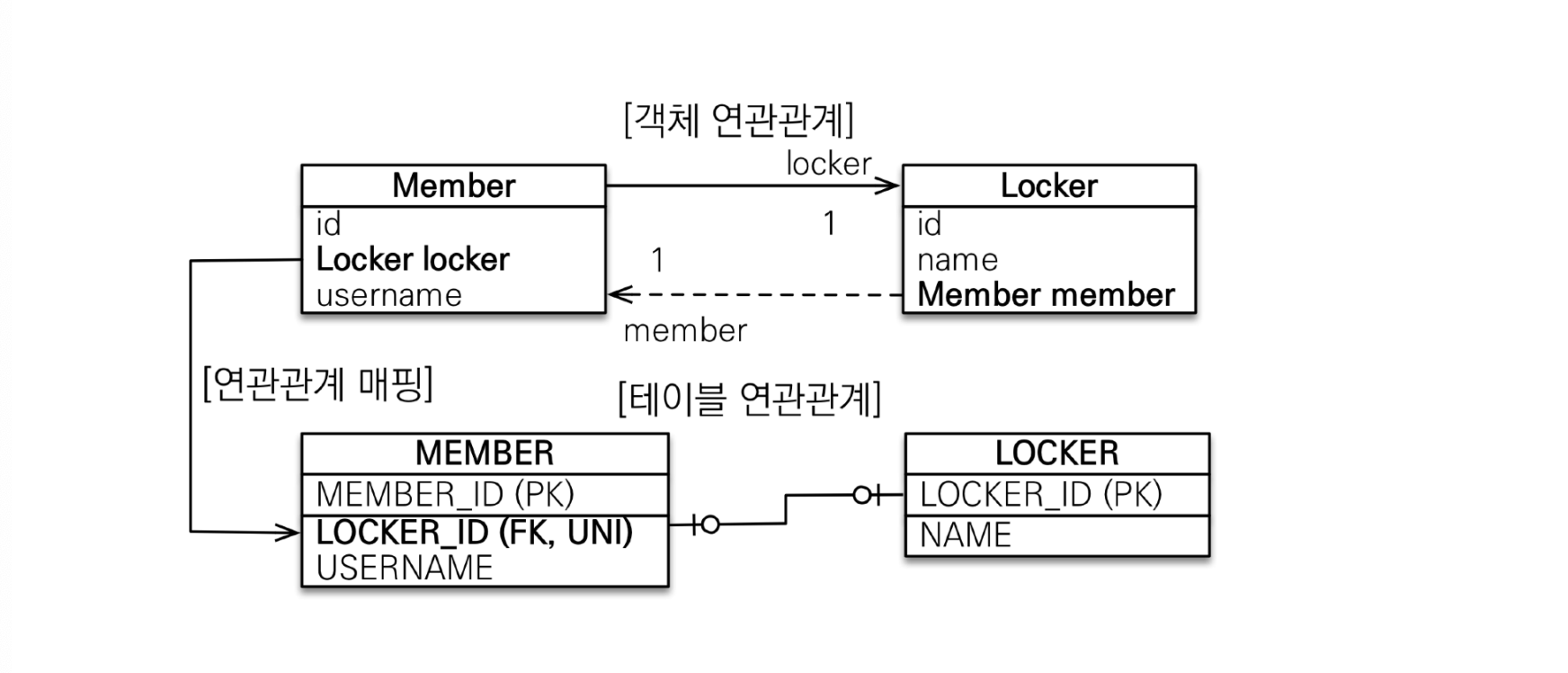
위와 같은 매핑은 아래와 같은 코드로 작성할 수 있다.
다대일 매핑과 거의 동일하다.
@Entity
public class Member {
...
@OneToOne
@JoinColumn(name = "LOCKER_ID")
private Locker locker;
...@Entity
public class Locker {
@Id
@GeneratedValue
@Column(name = "LOCKER_ID", unique = true)
private Long id;
private String name;
@OneToOne(mappedBy = "locker")
private Member member;
}이 방식의 장점은 주 테이블만 조회해도 대상 테이블에 데이터가 있는지 확인할 수 있다는 것이다.
단, 값이 없으면 외래 키에 null을 사용해야 하는 단점이 있다.
대상 테이블에 외래 키 단방향
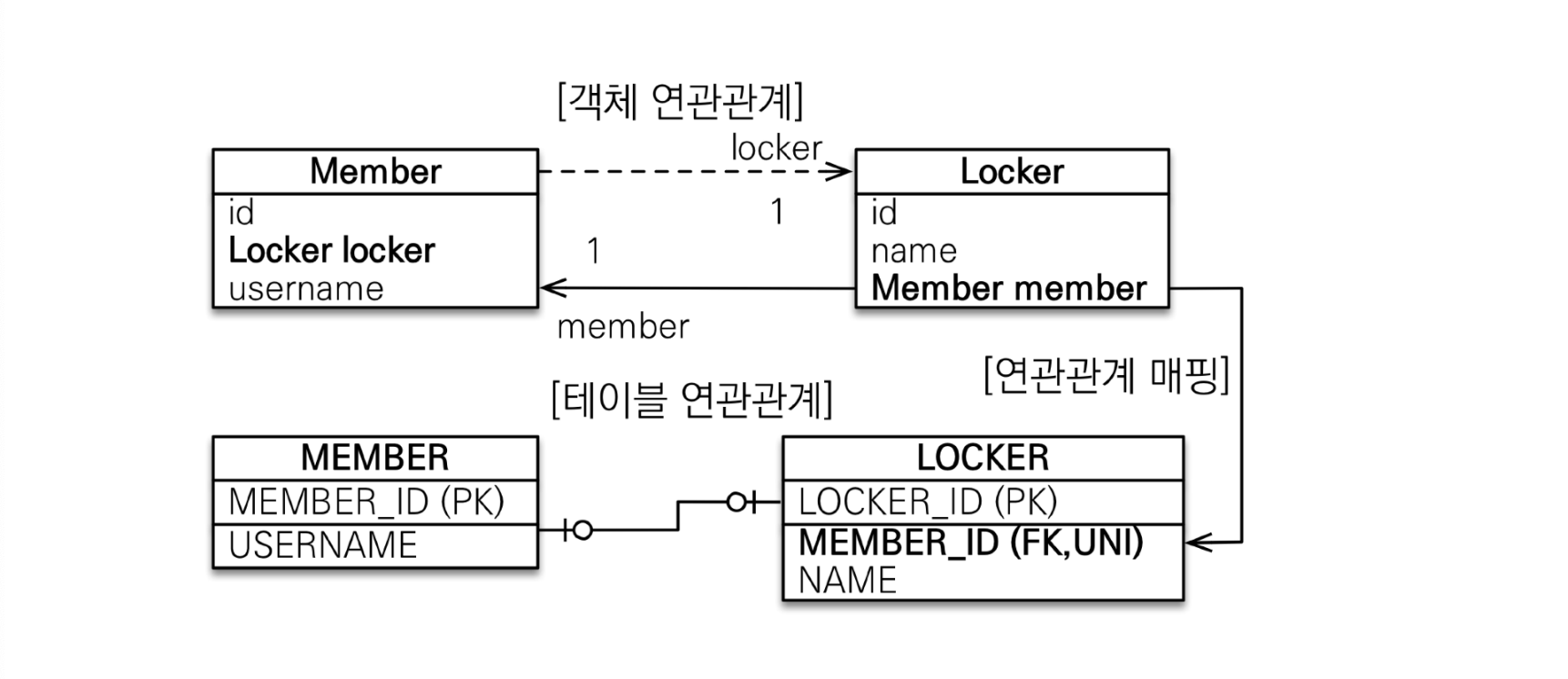
이 방식은 위 방법에서 매핑만 반대로 해주면 된다.
이 방식의 장점은 주 테이블과 대상 테이블을 일대일에서 일대다 관계로 변경할 때 유니크 제약조건만 제거하면 테이블 구조를 유지할 수 있다는 장점이 있다.
단, JPA 프록시 기능의 한계로 인해 지연 로딩을 설정해도 항상 즉시 로딩된다는 단점이 있다.
JPA 입장에서는 Member 객체를 조회할 때, Locker를 갖고 있는지 확인하려면 어차피 Locker 테이블에 쿼리를 날려야 하기 때문에 하이버네이트 구현체는 항상 즉시 로딩을 수행한다.
다대다
다대다 관계를 위해 테이블은 연결 테이블이 반드시 필요하지만, 객체는 컬렉션을 사용해 곧바로 다대다 관계가 가능하다.
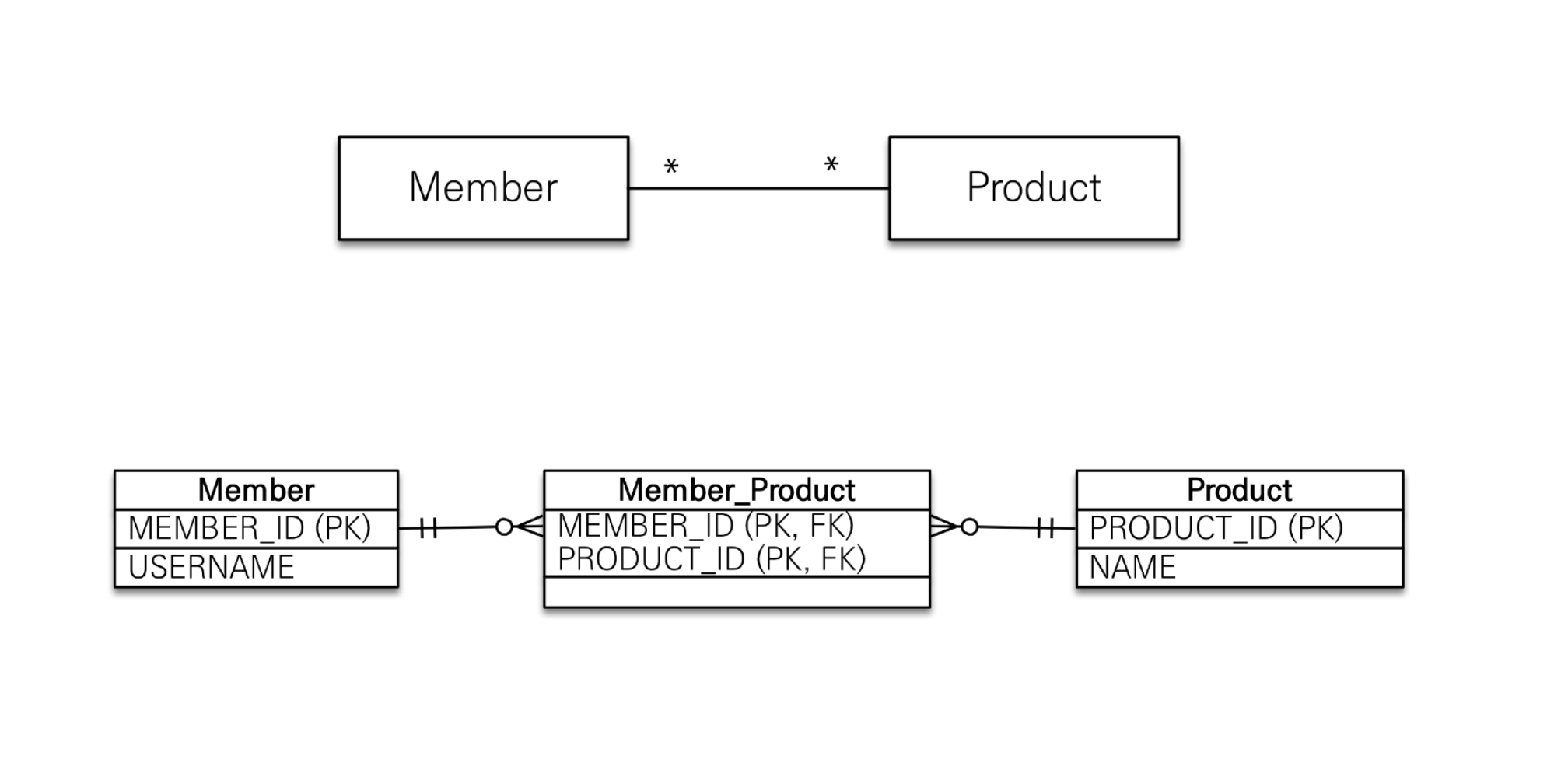
JPA에서는 이러한 객체의 특징을 살려 @ManyToMany 어노테이션을 지원하지만, 실무에서 이 방식을 사용하는 것은 권장하지 않는다.
실무에서 연결 테이블이 정말 연결만 하고 끝나는 경우가 거의 없기 때문이다. 위 예제만 보더라도 연결 테이블에 주문 시간, 수량, 수정 시각 등의 컬럼이 추가될 수 있다.
따라서 @ManyToMany를 사용하기보다 연결 테이블을 사용해 아래와 같이 매핑해 사용하자.
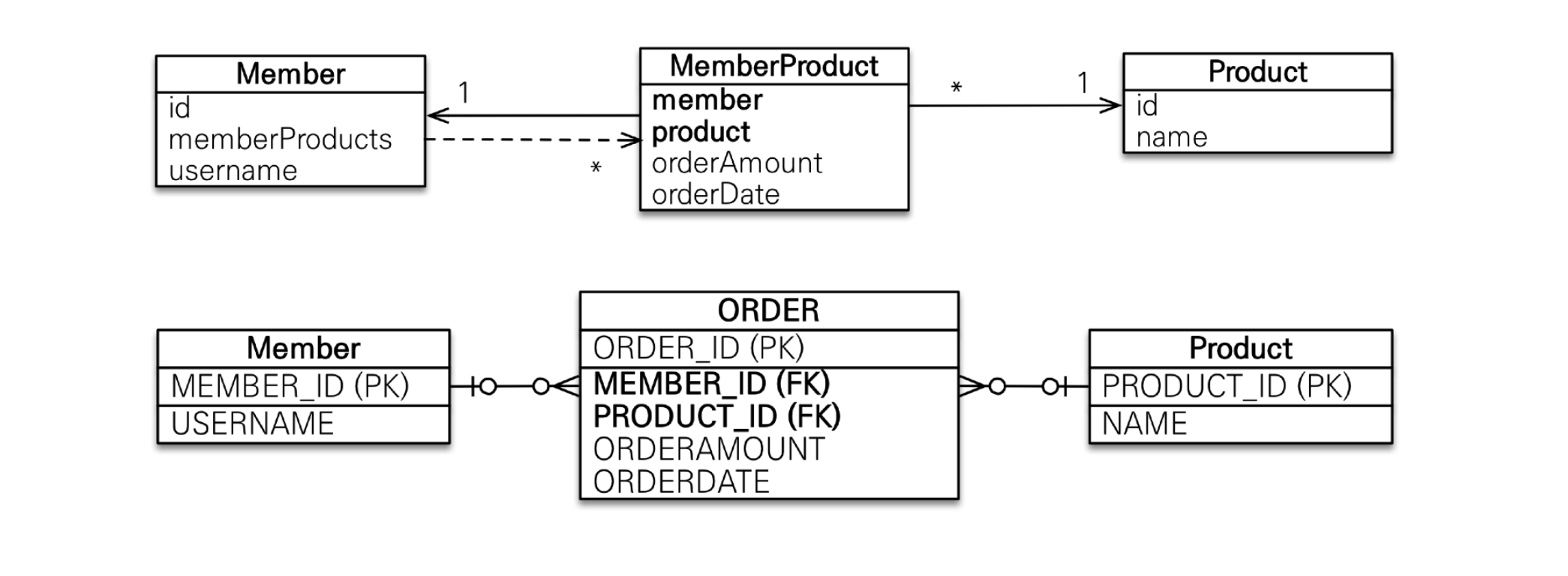
그리고 강의에서는 이런 연결 테이블의 PK도 위 그림처럼 별도의 값을 사용하는 것을 권장한다고 한다. 실제 운영을 오랜 시간 하다보면 비즈니스적으로 의미가 없는 값을 사용하는 것이 더 큰 유연성을 보장해준다고 한다.
고급 매핑
상속관계 매핑
객체와 달리 RDB는 상속관계가 없다. 다만 슈퍼타입-서브타입 관계라는 모델링 기법을 사용해 객체 상속과 유사한 논리 모델을 만들 수 있다.
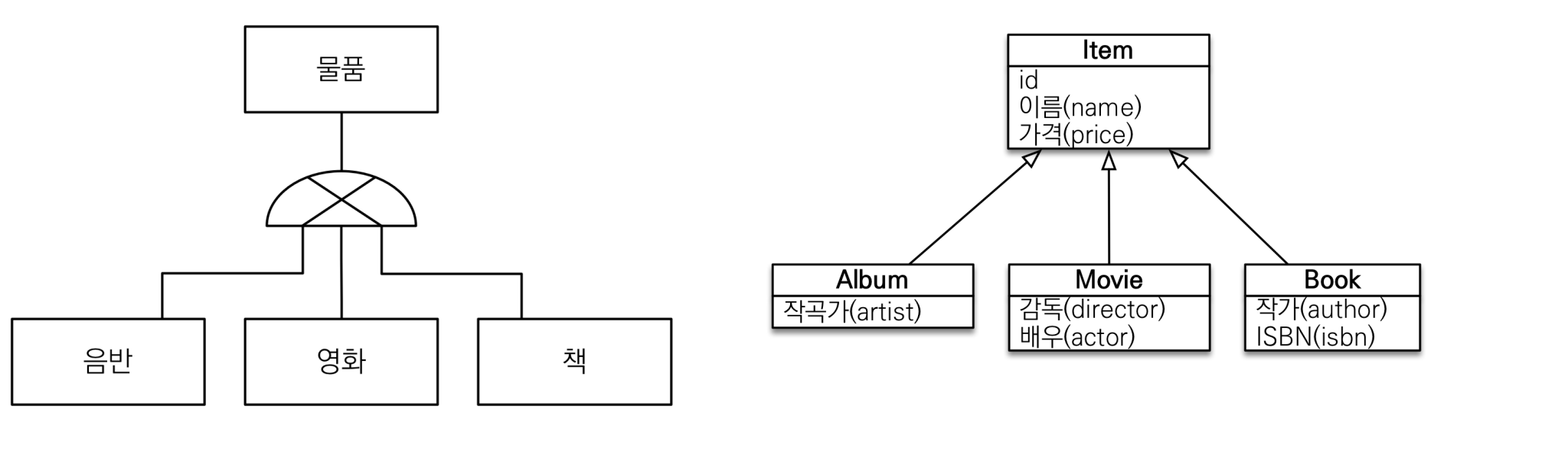
상속관계 매핑이란 객체의 상속 구조를 DB의 슈퍼타입-서브타입 관계에 매핑하는 것이다.
상속관계 매핑은 3가지 전략이 있다.
조인 전략
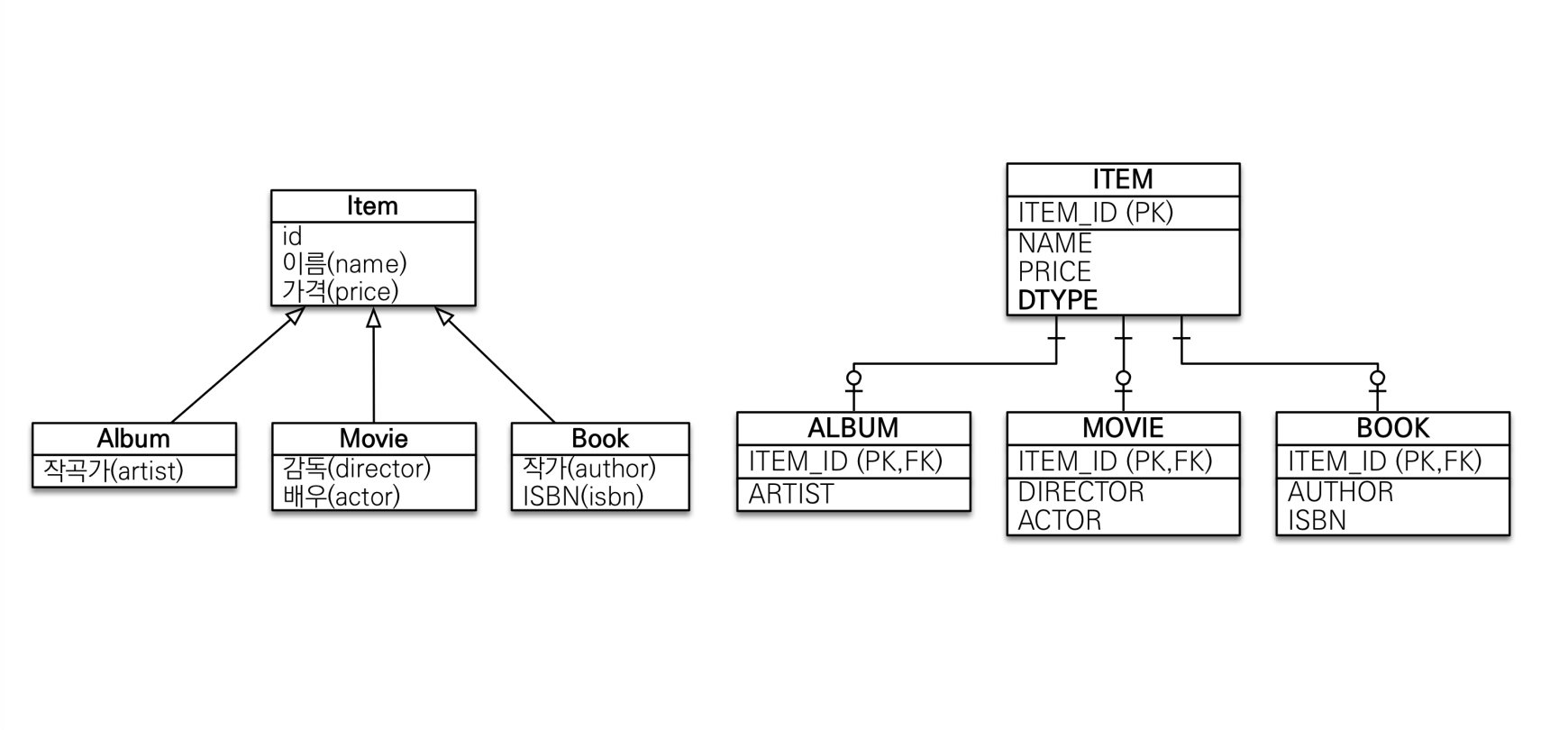
테이블 조인을 활용하는 매핑 전략이다.
사용법은 다음과 같다.
- 부모 클래스
@Inheritance(strategy = InheritanceType.JOINED): 조인 전략 지정 어노테이션@DiscriminatorColumn(name = "DTYPE"): 구분자 컬럼명 지정 어노테이션(기본값 DTYPE)
- 자식 클래스
@DiscriminatorValue("XXX"): 구분자 컬럼에 해당 클래스를 어떻게 표시할지 지정. 기본값은 클래스명
이 방법의 장단점은 다음과 같다.
- 장점
- 정규화된 테이블 사용 => 저장공간 효율화
- 외부에서 부모 테이블만 참조하면 되기 때문에 활용성이 높음
- 단점
- 조회 시 조인을 많이 사용해 쿼리가 복잡해지고 성능 저하 우려
- 데이터 저장 시 INSERT 쿼리 2번 호출
강의에서는 가장 기본으로 고려할 전략으로 소개한다. INSERT를 2번 수행하거나 JOIN이 많아지는 것을 우려하는 사람들이 많지만 잘 설계하면 이런 부분에서의 성능 저하도 그리 크지 않다고 한다.
단일 테이블 전략
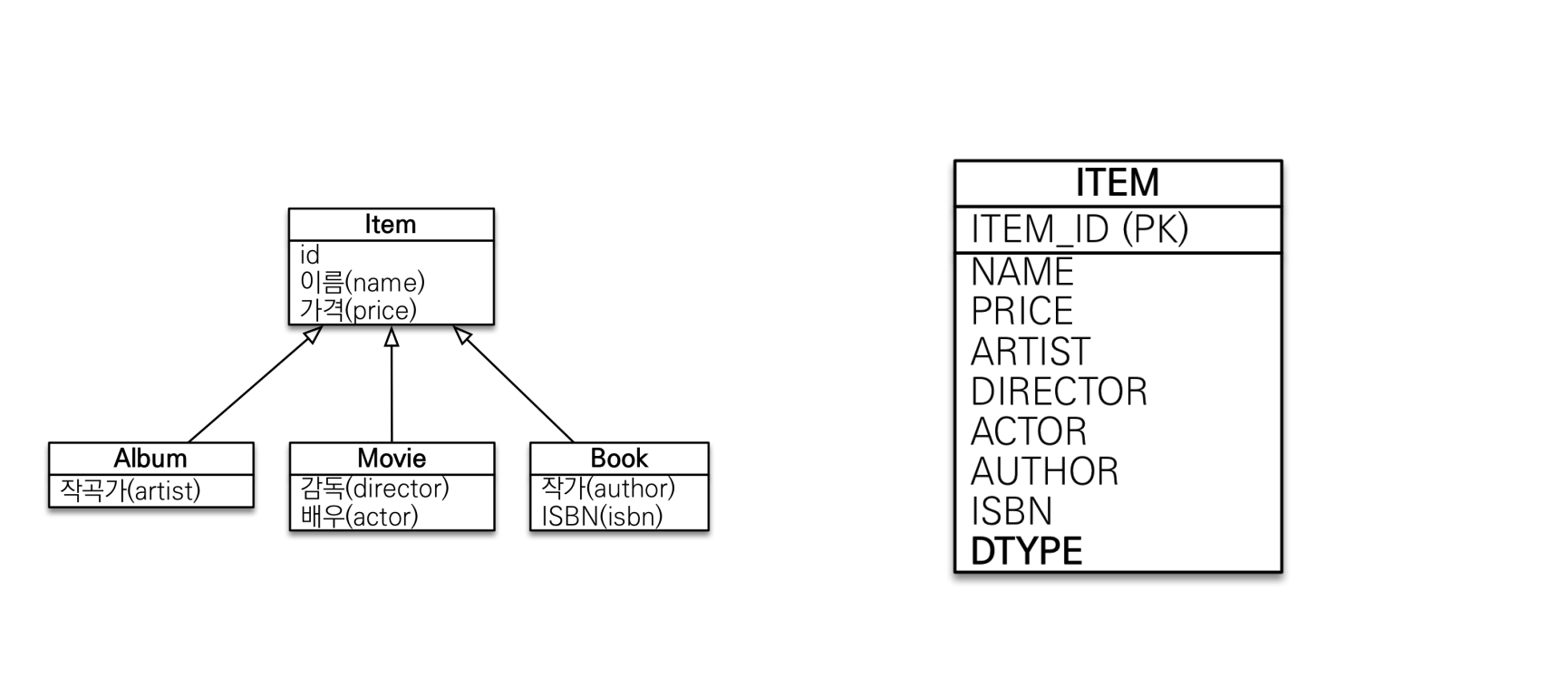
단일 테이블에 모든 컬럼을 때려박는 전략이다.
사용법은 다음과 같다.
- 부모 클래스
@Inheritance(strategy = InheritanceType.SINGLE_TABLE): 단일 테이블 전략 지정 어노테이션@DiscriminatorColumn(name = "DTYPE"): 구분자 컬럼명 지정 어노테이션(기본값 DTYPE)- 해당 어노테이션을 사용하지 않아도 DTYPE 컬럼이 반드시 추가된다. 조인 전략과 다르게 해당 컬럼이 없으면 어떤 클래스에 매핑되는지 구분할 수 없기 때문.
- 자식 클래스
@DiscriminatorValue("XXX"): 구분자 컬럼에 해당 클래스를 어떻게 표시할지 지정. 기본값은 클래스명
이 방법의 장단점은 다음과 같다.
- 장점
- 조인이 필요 없으므로 조회 쿼리가 단순하고 성능이 빠르다.
- 단점
- 자식 엔티티가 매핑한 컬럼은 모두 NULL 허용
- 단일 테이블에 모든 것을 저장하므로 테이블이 커질 수 있다.
강의에서는 먼 미래를 고려하더라도 확장할 일이 거의 없으며, 조인 전략을 적용할 필요조차 없을 만큼 단순한 구조인 경우에는 해당 전략을 택하는 경우도 꽤 있다고 한다.
구현 클래스마다 테이블 전략
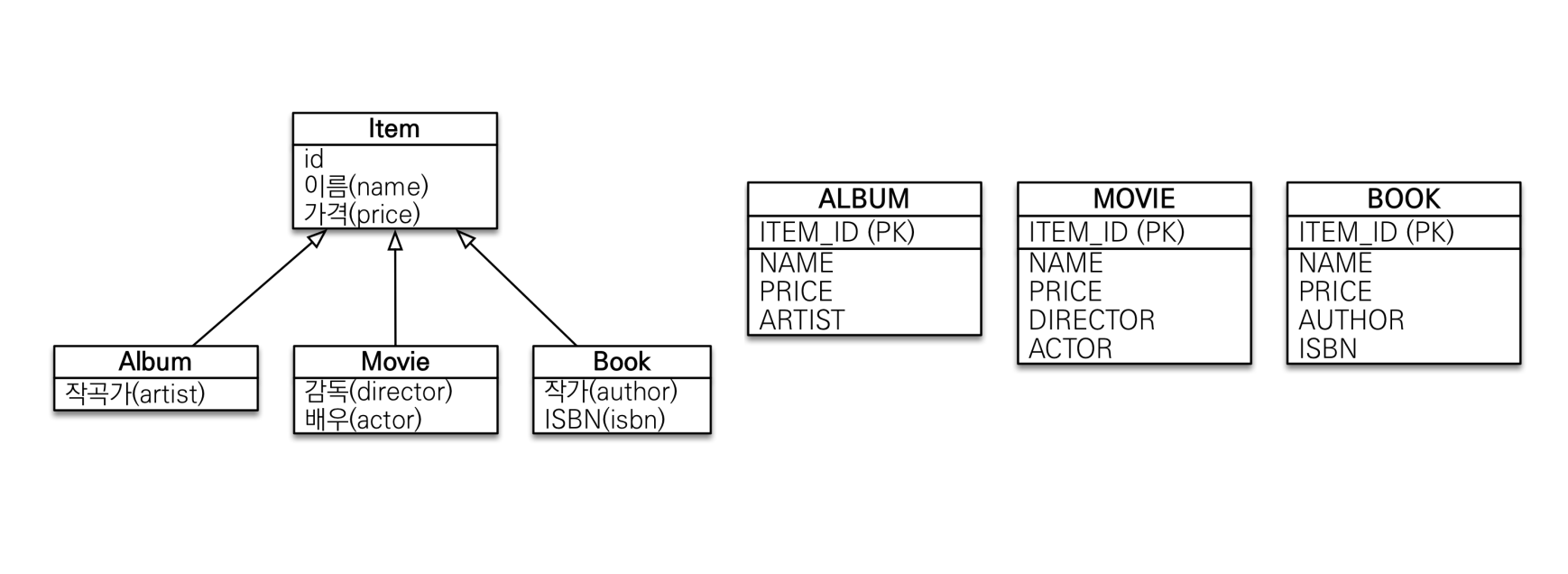
구현 클래스마다 테이블을 생성하는 전략이다.
이 전략은 어떠한 경우에도 추천하지 않는 방식이다.
부모 타입으로 조회 시 모든 테이블을 조회해 UNION ALL을 수행한다.
또한 자식 테이블을 통합해서 쿼리하기도 어렵다.
매핑 정보 상속
서비스를 만들다보면 여러 테이블에 공통으로 들어가야 하는 속성들이 있다. (createdAt, updatedAt 등)
이런 경우 DB 상에서는 완전 별도의 테이블이지만, 객체들을 관리할 때는 부모 클래스를 상속받아 구현하는 것이 편리하다.
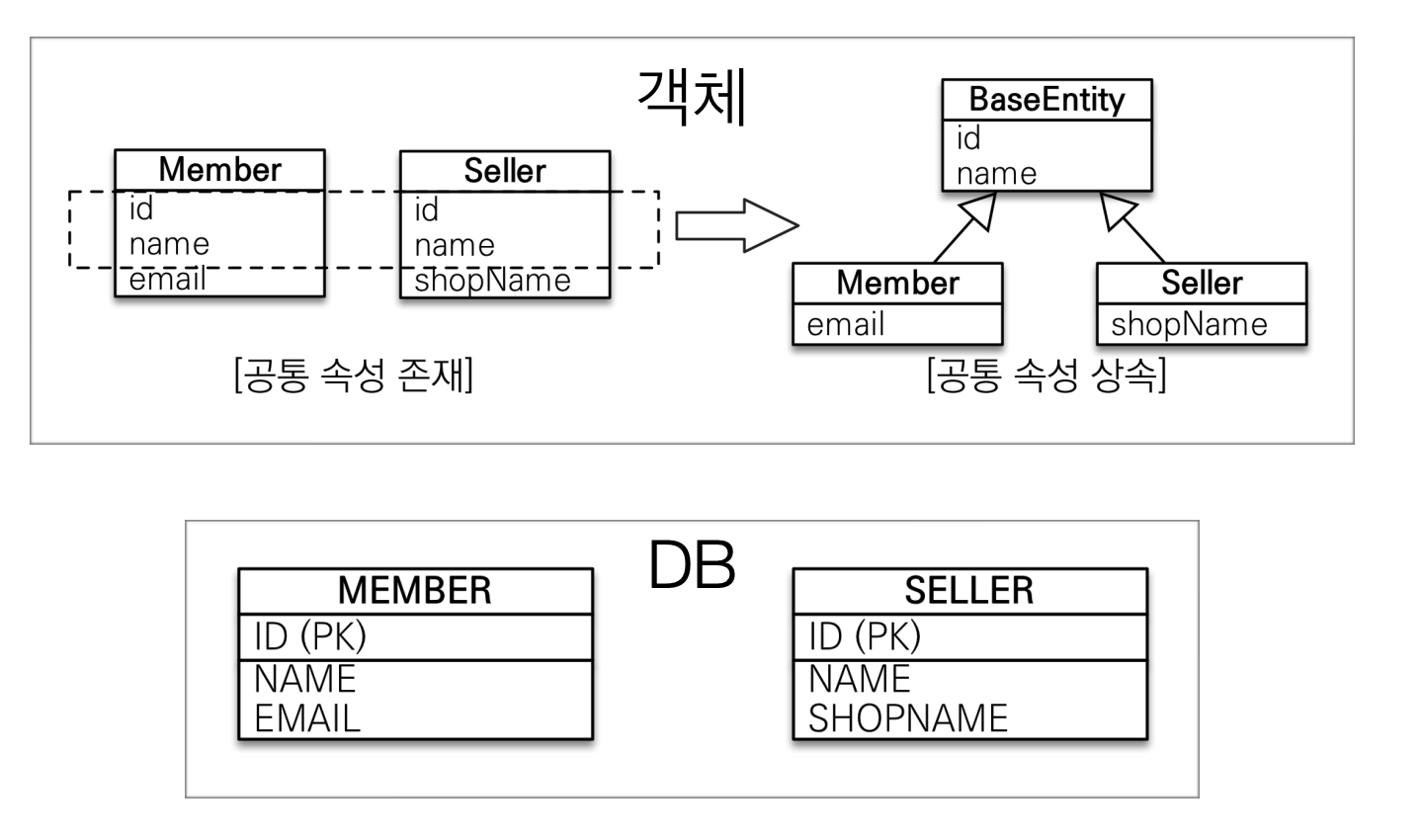
이러한 편의성을 제공하는 것이 @MappedSuperclass 어노테이션이다.
사용법은 다음과 같다.
- 추상 클래스에
@MappedSuperclass어노테이션을 붙인다.- 이 클래스는 엔티티로 등록하는 것이 아니라 공통 속성을 매핑하는 역할만 하기 때문에 추상 클래스 사용을 권장한다.
- 공통 속성을 사용하는 다른 엔티티에서 해당 추상 클래스를 상속한다.
@MappedSuperclass가 붙은 클래스는 엔티티가 아니기 때문에 영속성 컨텍스트에서 조회 또한 불가능하다.
✅ 참고
@Entity클래스는@Entity나@MappedSuperclass로 지정한 클래스만 상속 가능하다
프록시와 연관관계 관리
프록시
Member를 조회할 때, 연관관계가 맺어진 Team도 조회해야 할까? 이는 상황마다 달라진다. 두 테이블의 정보를 모두 사용한다면 JOIN을 사용해 한 번에 조회하는 것이 나을 것이고, Member의 정보만 사용한다면 JOIN 없이 Member만 조회하는 것이 더 효율적이다.
이러한 유연함을 제공하기 위해 JPA는 프록시 객체를 사용한다. 프록시 객체란 무엇일까?
프록시 객체는 실제 엔티티를 상속받아 만들어진 클래스이다. 엔티티를 사용하는 입장에서는 이 객체가 실제 엔티티 객체인지, 프록시 객체인지 구분하지 않고 사용하면 된다.
프록시 객체는 실제 엔티티의 참조(target)을 속성으로 갖고 있으며, 프록시 객체의 메서드를 호출하면 프록시 객체는 실제 객체(target)의 메서드를 호출한다.
프록시 객체는 EntityManager::getReference 메서드를 사용해 반환받을 수 있다.
Member member = em.getReference(Member.class, 1L); // a. 프록시 객체 생성 후 영속성 컨텍스트에 저장
member.getname(); // b. 영속성 컨텍스트에 프록시 초기화 요청a 단계에서는 빈 프록시 객체에 id값만 할당해 영속성 컨텍스트에 저장한다.
그리고 메서드를 호출하는 b 시점에 영속성 컨텍스트에 초기화를 요청하게 된다.
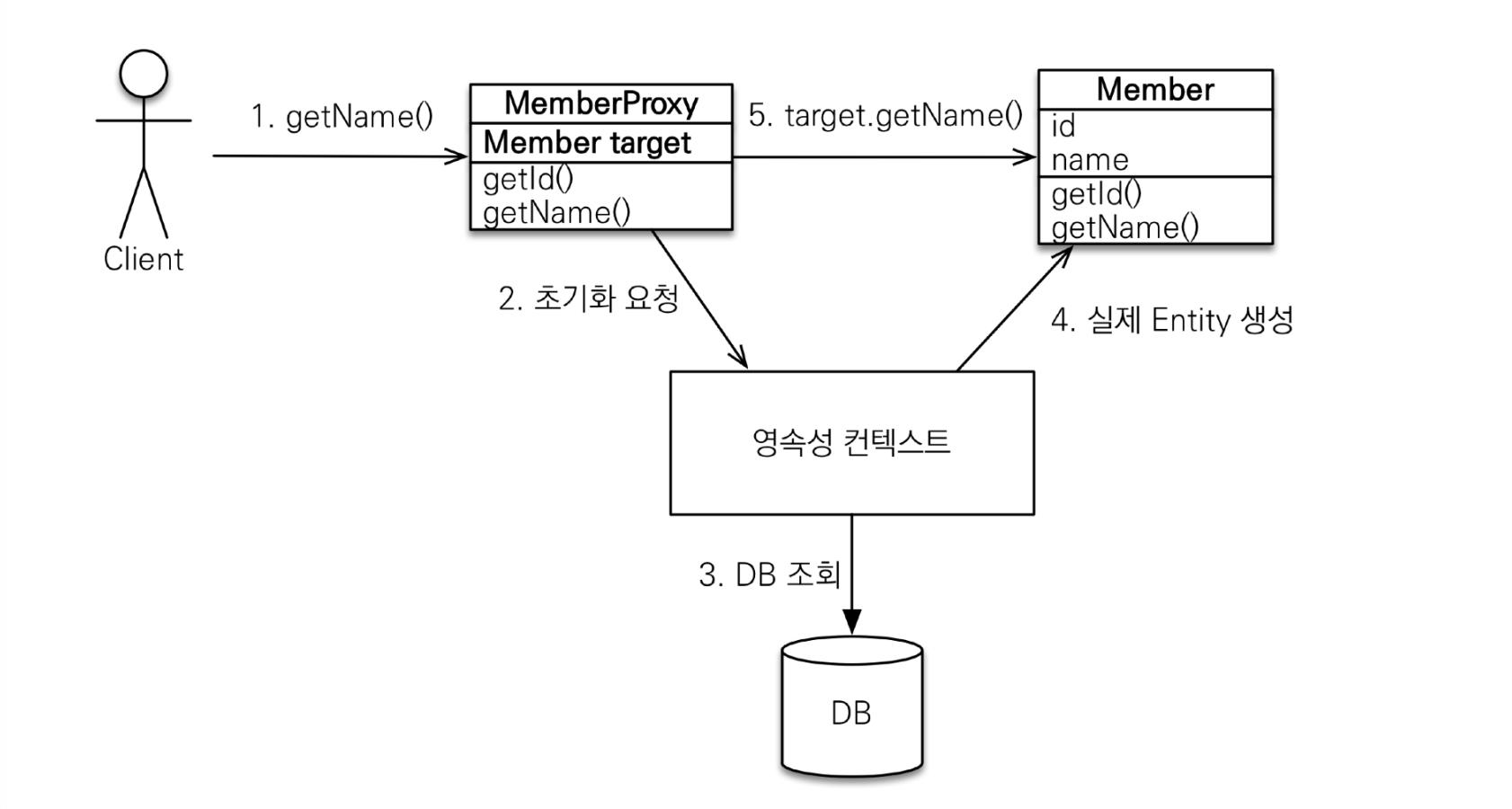
find 메서드와 비교하면 다음과 같이 정리할 수 있다.
em.find()- 영속성 컨텍스트에서 엔티티 조회 후 반환
- 영속성 컨텍스트에 엔티티가 없다면 DB 조회 -> 엔티티 생성 및 등록 -> 엔티티 반환
em.getReference()- 영속성 컨텍스트에서 엔티티 조회 후 반환
- 영속성 컨텍스트에 엔티티가 없다면 프록시 객체 생성 & id만 할당 -> 영속성 컨텍스트에 등록 -> 반환
주의사항
JPA에서 엔티티의 타입 체크 시 instance of를 사용할 것
영속성 컨텍스트에서 반환하는 엔티티는 실제 엔티티일 수도 있지만 엔티티를 상속받은 프록시일 수도 있다. 따라서 타입 체크 시 ==이 아닌 instance of를 사용하자.
Member member = em.getReference(Member.class, 1L);
// member가 프록시 객체라면 타입 체크 결과는 false가 나온다!
System.out.println("type check by == : " + member.getClass() == Member.class);
// 항상 true
System.out.println("type check by instance of : " + member instance of Member); 영속성 컨텍스트에서 같은 id로 조회한 객체는 항상 동일하다
// 영속성 컨텍스트에 프록시 객체로 처음 등록되었다면, 쭉 프록시 객체를 반환받는다.
Member refMember = em.getReference(Member.class, member.getId());
Member findMember = em.find(Member.class, member.getId());
System.out.println("refMember = " + refMember.getClass());
System.out.println("findMember = " + findMember.getClass());
System.out.println("isSameObject = " + (refMember == findMember));
// result
// refMember = class hellojpa.Member$HibernateProxy$8moZxv7M
// findMember = class hellojpa.Member$HibernateProxy$8moZxv7M
// isSameObject = true// 영속성 컨텍스트에 엔티티 객체로 처음 등록되었다면, 프록시 객체는 생성되지 않는다.
// getReference 메서드로 조회해도 엔티티 객체를 반환받는다.
Member findMember = em.find(Member.class, member.getId());
Member refMember = em.getReference(Member.class, member.getId());
System.out.println("findMember = " + findMember.getClass());
System.out.println("refMember = " + refMember.getClass());
System.out.println("isSameObject = " + (refMember == findMember));
// result
// findMember = class hellojpa.Member
// refMember = class hellojpa.Member
// isSameObject = true준영속(detached) 상태의 프록시 객체를 초기화하면 에러가 발생한다.
프록시 객체는 영속성 컨텍스트를 통해 DB 정보를 조회하고 초기화를 수행한다.
따라서 준영속 상태에서는 초기화가 불가능하며, 초기화를 시도하면 LazyInitializationException이 발생한다.
Member refMember = em.getReference(Member.class, member.getId());
em.detach(refMember);
System.out.println("username = " + refMember.getUsername());
// org.hibernate.LazyInitializationException프록시 관련 유틸 함수들
Member refMember = em.getReference(Member.class, member.getId());
// 프록시 초기화 확인
// false
System.out.println("isLoaded = " + emf.getPersistenceUnitUtil().isLoaded(refMember));
// getter를 사용하지 않고 프록시 객체를 직접 초기화하는 메서드
// JPA 공식 스펙이 아닌, Hibernate 구현체의 기능
Hibernate.initialize(refMember);
// true
System.out.println("isLoaded = " + emf.getPersistenceUnitUtil().isLoaded(refMember));즉시 로딩과 지연 로딩
지연 로딩
아래처럼 Member와 Team이 연관관계를 맺고 있다면, Member 정보만을 조회할 때 Team도 함께 조회해야 할까?
Member 정보만을 조회한다면, 당연히 Member 정보만 조회하고 Team 정보 조회는 해당 정보를 사용하는 시점까지 지연시키는 것이 유리하다.
JPA는 이러한 목적을 달성하기 위해 프록시 객체를 통한 지연 로딩 기능을 제공한다. 연관관계 매핑 어노테이션에서 FetchType.LAZY를 설정하면 적용할 수 있다.
@Entity
public class Member {
@Id
@GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
@Column(name = "USERNAME")
private String username;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "TEAM_ID")
private Team team;
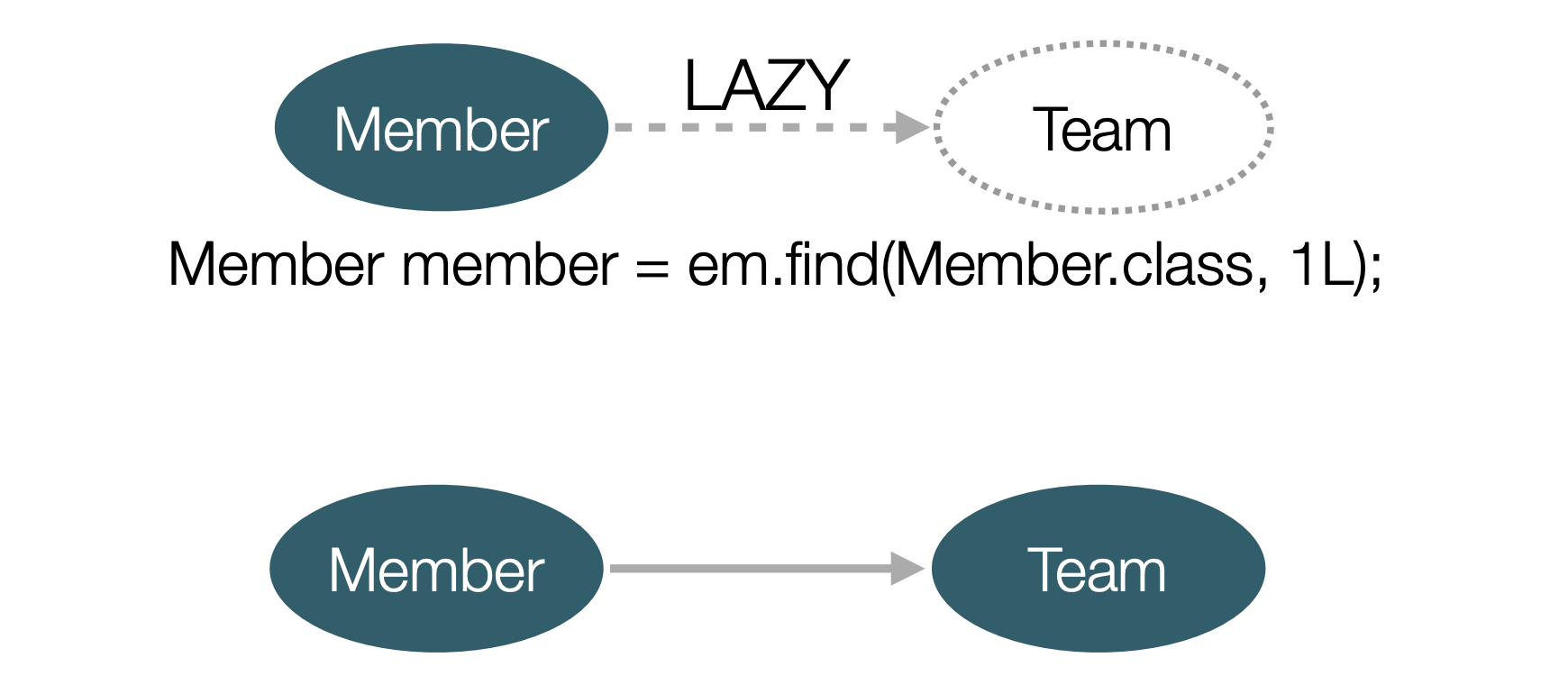
...지연 로딩을 적용하면 연관관계로 매핑된 속성(이 예시에서는 Team)은 빈 프록시 객체를 참조하고, 해당 객체의 정보에 접근하는 메서드를 호출하는 시점에 DB를 조회하며 프록시를 초기화하게 된다.
즉시 로딩
만약 Member와 Team을 항상 같이 사용한다면 즉시 로딩을 사용할 수도 있다.
@Entity
public class Member {
@Id
@GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
@Column(name = "USERNAME")
private String username;
@ManyToOne(fetch = FetchType.EAGER)
@JoinColumn(name = "TEAM_ID")
private Team team;
...즉시 로딩을 사용할 경우 JPA 구현체는 가능한 조인을 사용해 한 번에 정보를 가져온다.
즉시 로딩과 N + 1 문제
강의에서는 가급적 지연 로딩만 사용하는 것을 권장한다.
즉시 로딩은 JPQL에서 N + 1 문제를 일으키기 때문이다.
만약 Member와 Team이 즉시 로딩으로 연관관계 매핑이 되어있다면 아래 코드의 실행 결과는 다음과 같다.
Team teamA = new Team();
teamA.setName("teamA");
em.persist(teamA);
Team teamB = new Team();
teamB.setName("teamB");
em.persist(teamB);
Team teamC = new Team();
teamC.setName("teamC");
em.persist(teamC);
Member memberA = new Member();
memberA.setUsername("memberA");
memberA.setTeam(teamA);
em.persist(memberA);
Member memberB = new Member();
memberB.setUsername("memberB");
memberB.setTeam(teamB);
em.persist(memberB);
Member memberC = new Member();
memberC.setUsername("memberC");
memberC.setTeam(teamC);
em.persist(memberC);
em.flush();
em.clear();
List<Member> members = em.createQuery("select m from Member m", Member.class).getResultList();
tx.commit();// 실제 호출된 쿼리
// Member 전체 조회
Hibernate:
/* select
m
from
Member m */ select
m1_0.MEMBER_ID,
m1_0.TEAM_ID,
m1_0.USERNAME
from
Member m1_0
// 위 select 쿼리 실행 결과의 row마다 Team 조회 쿼리 실행
Hibernate:
select
t1_0.TEAM_ID,
t1_0.name
from
Team t1_0
where
t1_0.TEAM_ID=?
Hibernate:
select
t1_0.TEAM_ID,
t1_0.name
from
Team t1_0
where
t1_0.TEAM_ID=?
Hibernate:
select
t1_0.TEAM_ID,
t1_0.name
from
Team t1_0
where
t1_0.TEAM_ID=?1개의 JPQL 쿼리를 실행했는데, N번의 조회 쿼리가 추가로 실행되는 것이다.
이는 JPQL이 SQL로 변환되어 그대로 실행되기 때문이다. Member를 조회하는 SQL 쿼리가 그대로 실행되었지만, 즉시 로딩으로 설정되어 있기 때문에 Team 객체를 바로 할당하기 위해 각 row마다 Team을 조회하는 쿼리를 호출하게 되는 것.
이러한 이유로 실무에서는 즉시 로딩을 사용하지 않는 것을 권장한다.
이런 N + 1 문제의 해결 방법인 fetch join이나 엔티티 그래프 기능은 이후 JPQL 파트에서 알아보자.
영속성 전이(CASCADE)와 고아 객체
값 타입
기본값 타입
임베디드 타입
값 타입과 불변 객체
값 타입의 비교
값 타입 컬렉션
