
나의 코딩테스트 준비 상황
개발자로 취업을 준비하는 사람들에게 알고리즘은 필수 요소이다. 일단 코딩테스트를 통과해야 다음 단계로 넘어갈 자격을 가질 수 있기 때문에 아무리 다른 능력이 뛰어나다해도 알고리즘 문제 해결 능력은 절대 무시할 수 없는 역량이다.
나는 대학생 시절부터 꾸준히 코딩테스트를 준비하여 온 결과 현재 아래의 수준에 도달했다. (티어는 플래티넘 2지만 날먹으로 올린 거라 사실상 물플레 수준이다...)
 괴수들이 즐비한 알고리즘 세계에서 결코 잘한다고는 할 수 없지만 그래도 못하는 편은 아니라고 생각하기 때문에 내가 그동안 배워온 것들 중 몇 가지를 공유하려 한다.
참고로 나의 주 언어는 파이썬이기 때문에 파이썬으로 설명을 할 것이다. 하지만 어차피 언어가 달라도 같은 알고리즘이기 때문에 디테일한 부분을 제외하면 다른 언어를 사용하는 사람이라도 보는 데 큰 무리가 없을 것 같다.
괴수들이 즐비한 알고리즘 세계에서 결코 잘한다고는 할 수 없지만 그래도 못하는 편은 아니라고 생각하기 때문에 내가 그동안 배워온 것들 중 몇 가지를 공유하려 한다.
참고로 나의 주 언어는 파이썬이기 때문에 파이썬으로 설명을 할 것이다. 하지만 어차피 언어가 달라도 같은 알고리즘이기 때문에 디테일한 부분을 제외하면 다른 언어를 사용하는 사람이라도 보는 데 큰 무리가 없을 것 같다.
코딩테스트를 위한 틈새 지식
알고리즘에 대해 이야기전에 나는 알고리즘 문제를 풀 때 알고 있으면 좋은 몇 가지 팁을 먼저 이야기 할 것이다. 나도 많이 아는 것은 아니지만 조금이라도 도움이 되길 바라는 마음에 적어보겠다.
알고리즘 선정의 힌트
알고리즘 문제를 풀 때 첫 관문은 어떤 알고리즘을 사용할지 선정하는 것이다. 비교적 명확하게 사용해야 할 알고리즘이 보이는 경우도 있는 반면 그렇지 않은 문제도 있다. 이럴 때는 문제의 조건에 주어진 힌트를 활용해야 한다.
문제의 힌트를 통해 해당 문제에 사용해야 할 알고리즘의 목록을 순식간에 줄여줄 수 있다. 그렇다면 여기서 어떤 힌트를 얻기 위해 어디를 봐야 할까? 바로 제한 시간과 입력의 크기 N이다.(공간 복잡도도 힌트가 될 수는 있으나 대회 수준의 문제가 아니고서는 공간 복잡도까지 신경 쓰는 경우를 잘 못 봤기 때문에 넘어간다.)
시간 복잡도의 활용과 계산 방법
제한 시간과 N을 통해서 어떻게 알고리즘 목록을 줄일 수 있을까? 바로 시간 복잡도를 계산하는 것이다. 시간 복잡도란 간단히 말해 해당 알고리즘의 연산 횟수로 Big-O 표기법을 사용한다.
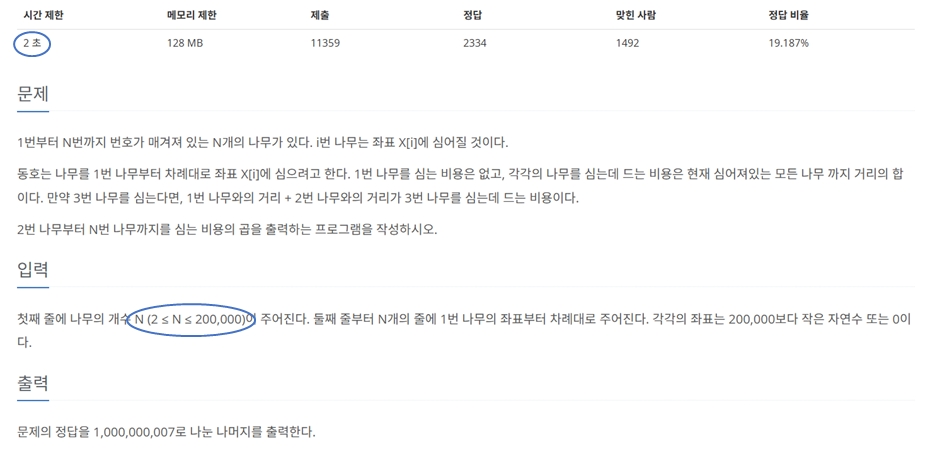
이제 위의 문제의 조건을 다시 한번 살펴보겠다. 일단 시간제한이 2초이다. 언어마다 다르지만 C++는 1초에 약 1억 번의 연산을 수행할 수 있고 파이썬은 약 3천만 번의 연산을 수행할 수 있다고 한다. 하지만 나는 파이썬으로 문제를 풀 때도 1초에 1억 번을 기준으로 계산을 하는데 언어에 따라 시간제한을 다르게 두는 경우가 있기 때문에 괜찮다고 생각을 한다. 그렇기 때문에 이번 문제에서의 연산 횟수를 2억 번으로 제한하겠다.
이렇게 되면 이상의 알고리즘은 사용할 수 없을 것이라는 것을 알 수 있을 것이다. 는 40억으로 2억을 훨씬 넘어버리니 사용이 불가능 할 것이다.
그렇다면 정도의 알고리즘을 사용해야 하는 것을 알 수 있다. 실제로 해당 문제는 세그먼트 트리를 활용하는 문제로 세그먼트 트리는 정도의 시간 복잡도를 가진다.
시간제한과 입력의 크기 별 시간 복잡도 제한
사실 시간제한과 입력의 크기의 의미를 알았다면 쉽게 계산할 수 있겠지만 내가 가진 대략적인 기준을 제시하겠다. 아래의 기준은 시간제한 1초 기준으로 계산한 것이지만 사실 이나 은 2초나 3초가 있더라도 저 정도가 한계이다.
N<12:
N<500:
N<10,000:
N<4,500,000:
<N:
input보다는 sys.stdin.readline을
파이썬으로 값을 입력받을 때 input보다는 sys.stdin.readline이 연산 속도 측면에서 좀 더 유리하다.
input에서는 데이터를 입력받을 때 개행문자 삭제와 문자열 변환 과정을 거치는 데다 버퍼에 데이터를 하나씩 입력하기 때문에 속도가 매우 느리다.
하지만 sys.stdin.readline은 input에서 수행하는 문자열 처리 과정을 거치지 않는 데다 모든 데이터를 한 번에 버퍼에 입력하기 때문에 input보다 훨씬 빠르게 데이터를 입력받을 수 있다.
나는 아래처럼 input에 sys.stdin.readline을 매핑해서 사용한다.
import sys
input = sys.stdin.readline 데이터를 입력받을 때 사용한 함수에 따른 수행 시간 차이로 위의 코드는 sys.stdin.readline을 아래의 코드는 input을 사용했다. 만약 입력받을 데이터가 많아진다면 차이는 더 커질 것이다.
데이터를 입력받을 때 사용한 함수에 따른 수행 시간 차이로 위의 코드는 sys.stdin.readline을 아래의 코드는 input을 사용했다. 만약 입력받을 데이터가 많아진다면 차이는 더 커질 것이다.
값이 변하지 않는다면 리스트보다는 튜플을
파이썬으로 알고리즘 문제를 해결할 때, 리스트에 저장한 값을 변경할 일이 없다면 튜플을 사용하는 것을 추천한다. 튜플은 값을 변경할 수 없는 대신 리스트에 비해 더 적은 메모리를 소모하고 연산 시간이 빠르기 때문에 잘만 사용하면 수행 시간을 꽤나 줄여줄 수 있다.
 두 수행 결과를 낸 코드의 차이는 변수를 저장하는데 사용한 자료구조로 위는 리스트, 아래는 튜플을 사용하였다. 단순히 사용한 자료구조의 차이로 메모리와 연산 시간을 모두 줄일 수 있다.
두 수행 결과를 낸 코드의 차이는 변수를 저장하는데 사용한 자료구조로 위는 리스트, 아래는 튜플을 사용하였다. 단순히 사용한 자료구조의 차이로 메모리와 연산 시간을 모두 줄일 수 있다.
코테 준비를 위한 중급 알고리즘
이제 오늘의 본 주제인 중급 알고리즘에 대해 설명한 것인데, 해당 알고리즘은 말 그대로 중급 알고리즘으로 초보자가 단박에 이해하기는 어려울 수도 있다. 나는 기준을 백준 골드 문제 정도로 잡고 설명을 할 것이고 문제 선정도 그런 기준으로 했으므로 본인이 백준 기준 실버 상위에서 골드 하위라면 조금 힘겨울 수도 있지만 코테를 준비하면서 이 알고리즘들은 짚고 넘어가기 바란다.
최단 거리 알고리즘
최단 거리 알고리즘은 말 그대로 어떤 지점에서 다른 지점으로 가는 최단 거리를 구하는 알고리즘으로 대표적인 알고리즘에는 다익스트라 알고리즘, 플로이드워셜 알고리즘, 벨만포드 알고리즘이 있고 나는 이중 다익스트라와 플로이드 워셜에 대해 설명할 것이다.
다익스트라 알고리즘
다익스트라 알고리즘은 어느 한 지점에서 다른 모든 지점으로 가는 최단 거리를 구하는 알고리즘이다. 다익스트라 알고리즘에서는 지점의 개수가 E고 간선의 개수가 V라고 할 때 의 시간 복잡도를 가진다.
조금 더 자세히 설명하면 모든 지점에 대해 한 번씩만 방문을 할 것이기 때문에 의 시간 복잡도가 필요하고 각 지점에 방문할 때마다 해당 지점에서의 목적지를 힙에 넣는데는 의 시간 복잡도가 필요하다. 따라서 다익스트라 알고리즘의 시간 복잡도는 로 가 된다.
다익스트라 알고리즘의 실행 과정
- 출발지에서 갈 수 있는 지점들과 해당 지점들과의 이동 거리를 힙에 삽입한다. 이때 힙의 정렬 기준은 이동 거리이다.
- 힙에서 이동 거리가 짧은 순으로 꺼내가며 해당 지점과의 최단 거리를 확정하고 방문 처리를 한다.
- 힙에서 꺼낸 지점에서 이동할 수 있는 지점 중 아직 방문하지 않은 지점의 지점 번호와 거리를 힙에 삽입한다.
- 위의 과정을 모든 지점을 방문할 때까지 반복한다.
위의 과정에서 핵심은 이동 거리가 짧은 순으로 힙에서 꺼내가며 방문 처리를 한다는 것이다. 이동 거리가 짧은 순으로 꺼낸다는 먼저 나온 이동 거리보다 이후에 나온 이동 거리가 더 짧은 것이 불가능하다는 것이다.
현재 힙에 들어있는 이동 거리 중 그 차례에 꺼낸 이동 거리보다 짧은 거리가 없기 때문에 음의 간선이 존재하지 않는 한(따라서 다익스트라는 가중치에 음수가 존재할 경우 사용할 수 없다) 더 짧은 거리가 나오는 것이 불가능하다.
 예시를 들어보자면 위와 같은 힙이 있을 때 5번까지의 거리가 2일 때 이후 3번과 2번에서 5번으로 이어지는 경로가 존재한다 하더라도 절대 2보다 작아질 수는 없다. 각각 3번, 2번까지의 거리가 3, 5이므로 3번, 2번에서 5번으로 가는 경로가 0 이상인 이상 절대 2보다 작아지지 않는다. 따라서 음수의 간선이 없다면 다익스트라 연산 결과는 최단 경로임이 보장된다.
예시를 들어보자면 위와 같은 힙이 있을 때 5번까지의 거리가 2일 때 이후 3번과 2번에서 5번으로 이어지는 경로가 존재한다 하더라도 절대 2보다 작아질 수는 없다. 각각 3번, 2번까지의 거리가 3, 5이므로 3번, 2번에서 5번으로 가는 경로가 0 이상인 이상 절대 2보다 작아지지 않는다. 따라서 음수의 간선이 없다면 다익스트라 연산 결과는 최단 경로임이 보장된다.
그림으로 보는 다익스트라 실행 과정
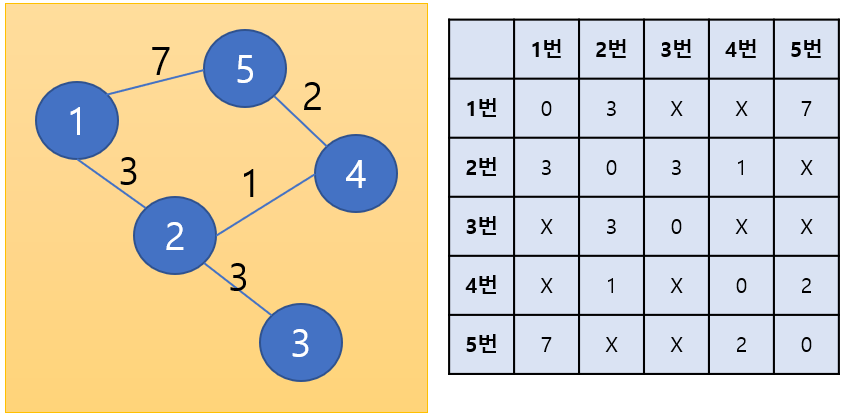 말로만 보면 이해가 가지 않을 수 있으니 위의 그래프를 예로 들어 설명을 해보겠다. 위의 그래프에서 출발점은 1번으로 1번에서 다른 지점으로 갈 수 있는 최단거리를 구할 것이다.
말로만 보면 이해가 가지 않을 수 있으니 위의 그래프를 예로 들어 설명을 해보겠다. 위의 그래프에서 출발점은 1번으로 1번에서 다른 지점으로 갈 수 있는 최단거리를 구할 것이다.
일단 1번에서 갈 수 있는 노드들을 거리순으로 힙에 삽입하면 아래와 같은 형태가 될 것이다.
 일단 첫 번째로 가장 앞에 있는 2번이 나올 것이므로 2번을 꺼내 2번까지의 최단 거리는 3으로 확정짓고 2번에 방문 표시를 한다.
일단 첫 번째로 가장 앞에 있는 2번이 나올 것이므로 2번을 꺼내 2번까지의 최단 거리는 3으로 확정짓고 2번에 방문 표시를 한다.
 그다음 2번에서 갈 수 있는 곳들과 해당 위치와의 거리를 힙에 삽입한다.
그다음 2번에서 갈 수 있는 곳들과 해당 위치와의 거리를 힙에 삽입한다.

그렇다면 힙에 담겨있는 데이터는 이렇게 될 것이다.(실제로는 힙은 첫 번째 원소를 제외한 나머지 원소들의 순서를 보장하지 않지만, 이해를 위해 이런 식으로 표현을 하였다.)
여기서 목적지 4번과 3번의 거리에 각각 3이 더해져 있는 것을 볼 수 있는데 이는 1번을 기준으로 거리를 측정하는 것이기 때문에 1번에서 2번으로의 거리+2번에서 해당 원소로의 거리로 거리를 나타낸 것이다.
이제 다시 힙에서 4번을 꺼내 4번까지의 최단 거리를 4로 확정 짓고 4번에 방문 표시를 해준다.
그 후 4번에서 방문 가능한 지점의 번호와 거리를 힙에 삽입한다.
위의 모든 과정이 끝나면 방문 여부와 힙은 이렇게 될 것이다.


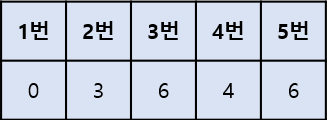
이후 똑같은 과정을 반복하여 3번을 힙에서 꺼내 최단 거리 확정 및 방문 처리, 5번을 힙에서 꺼내 최단 거리 확정 및 방문 처리를 하면 모든 과정이 끝이 난다. 이때 힙에 5번은 2개가 들어있지만 1번에서 5번으로 바로 가는 거리 7보다 2번과 4번을 거쳐 5번으로 가는 6이 더 짧기 때문에 6을 최단 거리로 저장한다.
모든 과정을 마치면 아래와 같이 1번에서 다른 지점으로 가는 최단 거리를 모두 구할 수 있게 된다.
코드로 보는 다익스트라
import heapq
import sys
input = sys.stdin.readline
V, E = map(int, input().split())
K = int(input())
heap = []
distances = [-1] * (V+1)
graph = [[] for _ in range(V+1)]
for _ in range(E): # 간선 입력
u, v, w = map(int, input().split())
graph[u].append([v, w])
distances[K] = 0 # 출발점 처리
for i in range(len(graph[K])): # 출발점에서 이동 가능한 지점들과 해당 지점과의 거리를 힙에 삽입
heapq.heappush(heap, [graph[K][i][1], graph[K][i][0]])
while heap:
dist, node = heapq.heappop(heap) # 힙에서 가장 짧은 거리의 지점을 꺼내옴
if distances[node] != -1: # 만약 현재 지점이 이전에 방문한 적이 있는 경우 무시
continue
distances[node] = dist # 현재 지점의 최단 거리를 확정 짓고 방문 여부로 활용
for i in range(len(graph[node])): # 현재 지점에서 이동 가능한 지점 탐색
if distances[graph[node][i][0]] != -1: # 해당 지점에 방문한 적 있을 경우 무시
continue
heapq.heappush(heap,[dist+graph[node][i][1], graph[node][i][0]]) # [현재 지점까지의 거리+그 지점까지의 거리, 해당 지점 번호]를 힙에 삽입
for i in range(1, V+1):
if distances[i] == -1: ## 도달 불가능한 경우
print("INF")
else: ## 도달 가능한 경우
print(distances[i])해당 코드는 백준 1753번 최단경로의 정답 코드로 다익스트라 알고리즘의 원형을 볼 수 있는 코드라 가져왔습니다.
플로이드 워셜 알고리즘
플로이드 워셜 알고리즘은 다익스트라와 다르게 모든 지점 간의 최단 거리를 구하는 알고리즘이다. 플로이드 워셜 알고리즘에서는 지점의 개수가 N이라고 할 때 모든 지점들이 출발지, 목적지, 경유지가 되기 때문에 이 되어 의 시간 복잡도를 가진다.
플로이드 워셜 알고리즘의 실행 과정
- 두 지점 i와 j의 최단 거리를 구하기 위해서는 두 지점 사이 가능한 모든 노선을 체크한다.
- 두 지점 i와 j 사이에서 k라는 지점을 거쳐서 가는 경우들 중 최단 거리를 저장한다.(여기서 k=i 또는 k=j일 수도 있다. 이 경우 i와 j가 다른 지점을 거치지 않고 바로 이어지는 경우이다.)
- 1번, 2번 과정을 모든 지점에 대해 반복한다.
이 과정에서 i와 j의 거리가 k라는 지점을 거치는 경로들 중 최단 거리를 저장하는 행위를 반복하게 되는데 여기서 i부터 k지점 사이의 거리는 i부터 k로 향하는 모든 경로들 중 최단 경로이고 k지점에서 j지점으로 가는 사이의 거리는 k에서 j로 가는 모든 경로들 중 최단 경로이기 때문에 i에서 j로 가는 경로가 최단 경로인 것이 보장된다. 왜 i에서 k, k에서 j까지 가는 거리가 최단 경로인지는 아래에서 설명하겠다.
점화식으로 설명한 플로이드 워셜
플로이드 워셜은 기본적으로 DP처럼 값을 저장해 조건에 따라 갱신해가며 사용하기 때문에 점화식으로 나타내는 것이 가능하고 점화식은 아래와 같다.
여기서 현재 값과 비교에 사용되는 는 어떻게 구해질까?
정말 간단하게도 위의 점화식과 동일한 방식으로 구해진다.
점화식이 좀 더 복잡해지지만 이를 수식으로 나타내보았다.
와 의 점화식을 이용하면
위의 점화식을 얻을 수 있다. 여기서 더 파고들어 갈 수도 있지만 어차피 반복일 테니 그만하겠다.
위의 점화식을 통해 보았듯이 계속해서 점화식이 반복되며 각 경로를 이루는 하위 경로가 그 경로의 최단 경로가 되는 것이다. (사실 엄밀히 말하자면 과 가 고정된 값이 아니라 맞는 점화식이라고 보기는 힘들지만, 그냥 이런 식으로 두 구간의 최단 거리를 구하는 경로는 두 구간 사이의 경로들의 최단 경로라는 것을 보여주려 하였다.)
정확한 점화식은 아니지만 위의 식을 통해서 각 두 지점 사이의 거리는 해당 지점들간의 경로들 중 최단 거리가 된다는 것을 보았다.
코드로 보는 플로이드 워셜
import sys
n = int(sys.stdin.readline())
m = int(sys.stdin.readline())
road = [[1e9 for _ in range(n+1)] for _ in range(n+1)]
for i in range(m):
s, d, c = map(int, sys.stdin.readline().split())
if road[s][d] > c: # 한 간선에 대해 여러 거리를 입력받을 경우 최소 거리를 저장
road[s][d] = c
for i in range(n+1): # 출발지와 목적지가 같은 경우 거리를 0으로 저장
road[i][i]=0
for k in range(n+1): # 가능한 모든 경로에 대해 경로 조회
for i in range(n+1):
for j in range(n+1):
if road[i][j] > road[i][k]+road[k][j]: # k를 거쳐 i에서 j로 가는 경로 중 최단 경로 저장
road[i][j] = road[i][k]+road[k][j] # DP(i,j) = min(DP(i,j),DP(i,k)+DP(k,j))
for i in range(1, n+1):
for j in range(1, n+1):
if road[i][j] != 1e9: # 두 지점 사이에 이동 가능한 경로가 존재하는 경우
print(road[i][j], end=' ')
else: # 두 지점 사이 이동 가능한 경로가 없는 경우
print(0, end=' ')
print()해당 코드는 백준 11404번 플로이드의 정답 코드로 위의 문제처럼 플로이드 워셜 알고리즘의 원형을 볼 수 있는 코드라 가져왔습니다.
최소 신장 트리
최소 신장 트리는 어떤 트리에서 모든 노드를 연결할 때 필요한 최소한의 비용을 구하는 알고리즘이다. 대표적인 알고리즘으로 크루스칼 알고리즘과 프림 알고리즘이 있는데, 나는 오늘 크루스칼 알고리즘에 대해 설명할 것이다.
크루스칼 알고리즘
크루스칼 알고리즘은 최소 신장 트리의 한 종류로 사이클이 발생하지 않으면서 모든 노드가 연결되는 최소한의 비용을 구한다. 크루스칼 알고리즘의 시간 복잡도는 간선의 개수가 E라고 할 때 이다.
좀 더 세부적으로 파고들면 간선을 가중치 순으로 정렬하는데 의 시간복잡도가 소요되고 이후 간선의 가중치 순으로 해당 간선을 사용할지말지 판정한 후 사용하는데 이 과정의 시간 복잡도는 (사실 엄밀히 말하면 가 아니지만 으로 표현한 이유는 아래의 유니온 파인드 부분에서 설명하겠다.)이기 때문에 총시간 복잡도가 가 되고 이 중 더 큰 를 시간 복잡도로 본다.(시간 복잡도 계산에서는 보통 가장 큰 요소만을 제외하고는 생략하는 경우가 많다.)
사이클 판정
위에서 사이클이 발생하지 않게한다는 말을 했는데 여기서 사이클이란 한 노드에서 시작하여 다시 그 노드로 돌아올 수 있는 경로가 존재한다는 것이다.
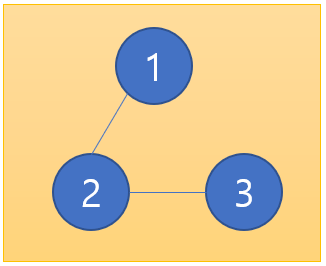 예를 들어 이런 식으로 1번, 2번, 3번 노드가 연결되어 있는 상태의 트리가 있다. 이 상태에서는 각 노드가 갔던 길을 되돌아오지 않는 한 본인에게 돌아올 수 있는 루트가 존재하지 않는다.
예를 들어 이런 식으로 1번, 2번, 3번 노드가 연결되어 있는 상태의 트리가 있다. 이 상태에서는 각 노드가 갔던 길을 되돌아오지 않는 한 본인에게 돌아올 수 있는 루트가 존재하지 않는다.
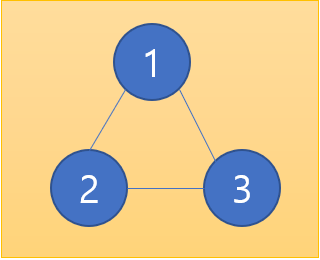 하지만 1번-3번이 다시 연결되어 사이클이 발생할 경우 3번-1번-2번-3번의 경로로 본인에게 돌아올 수 있게 된다. 이것을 사이클이라고 한다.
하지만 1번-3번이 다시 연결되어 사이클이 발생할 경우 3번-1번-2번-3번의 경로로 본인에게 돌아올 수 있게 된다. 이것을 사이클이라고 한다.
유니온 파인드
크루스칼 알고리즘에서는 사이클이 발생하지 않으면서 모든 노드를 연결한다고 하였는데 그렇다면 사이클이 발생하는지는 어떻게 판단할까.
바로 유니온 파인드를 사용해 판단한다. 유니온 파인드는 두 노드가 서로 같은 부모의 자식 노드인지를(=같은 그룹에 속한 노드인지) 판단하는 알고리즘으로 경로 압축을 사용할 경우(사용하지 않으면 최악의 경우 의 시간 복잡도를 가지므로 반드시 사용해야 한다.) 한 번의 연산은 이라는 시간 복잡도를 가지는데 여기서 은 사실상 상수(라고 한다)이기 때문에 상수 시간 복잡도를 가진다고 봐도 무방하다.
그림으로 보는 유니온 파인드
유니온 파인드는 오늘의 주제가 아니기 때문에 간략히 어떤 느낌인지만 보고 넘어갈 것이라 그림으로만 대충 설명하겠다.
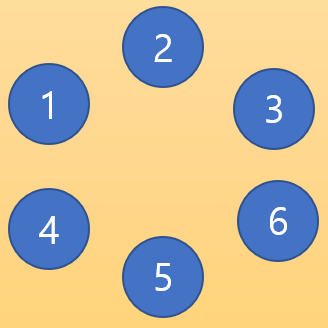

일단 1번부터 6번까지의 노드가 있고 서로 모두 연결되어 있지 않은 경우 이렇게 각자가 본인의 부모가 된다.
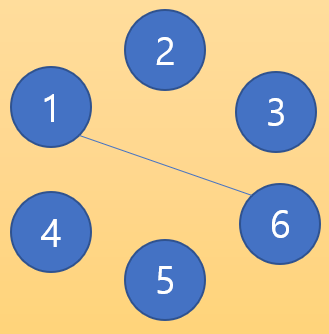
여기서 1번과 6번을 연결했다고 하자 그렇다면 아래처럼 될 것이다. 유니온 파인드에서는 보통 본인이 속한 그룹에서 숫자가 가장 낮은 노드가 부모가 되므로 1번 노드가 6번 노드의 부모가 된다.

이후 6번과 4번을 연결한다면 이번에는 이렇게 될 것이다. 6번 노드의 부모 노드 번호 1이 4보다 작은 숫자이기 때문에 4번 노드의 부모는 1번 노드가 된다.
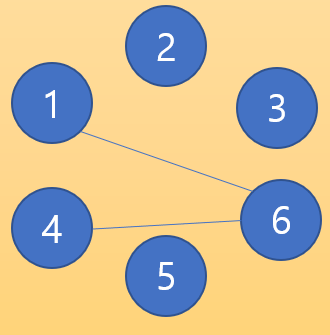

여기서 다시 1번과 4번을 연결한다고 해보자. 이때 각각의 부모 노드 번호는 1과 1로 서로 같은 부모를 가지는데 이 두 노드를 연결하면
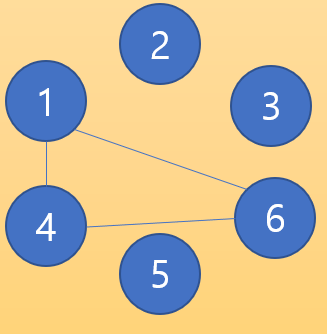 이런 식으로 사이클이 발생하게 된다. 같은 부모 아래에 있는(=같은 그룹의) 노드들끼리 연결을 했기 때문에 사이클이 발생하는 것이다.
이런 식으로 사이클이 발생하게 된다. 같은 부모 아래에 있는(=같은 그룹의) 노드들끼리 연결을 했기 때문에 사이클이 발생하는 것이다.
크루스칼 알고리즘의 실행 과정
- 주어진 간선들을 가중치가 적은 순으로 정렬을 한다.
- 가중치가 적은 간선들부터 활용하여 각 노드들을 연결한다.
- 이때 현재 순서의 간선이 연결하는 노드들이 이미 서로 연결되어 있는지를 확인하고 연결되어 있을 경우 해당 간선을 버린다.
- 현재 기준으로 서로 연결되지 않은 노드들만을 연결해 가며 모든 노드를 연결하는 데 필요한 최소한의 비용을 구한다.
크루스칼 알고리즘에서 구한 비용이 최소 비용이라는 것을 보장해 주는 것은 가중치가 작은 간선부터 사용을 한다는 점이다. 해당 알고리즘에서는 두 노드 간의 거리는 상관없이 그 두 노드가 연결되어 있는지 여부만 보기 때문에 한 번 최소 비용으로 연결된 것은 절대 최소 비용이 바뀌지 않는다. 설령 두 노드가 트리의 모든 노드를 거친 다음에야 만날 수 있더라도 두 노드가 만날 수 있다는 것은 사실이기에 상관이 없다.
그림으로 보는 크루스칼 알고리즘 실행 과정
이번에는 그림을 통해 크루스칼 알고리즘의 실행 과정을 살펴보겠다.
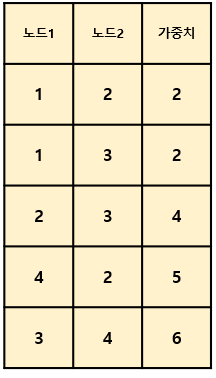
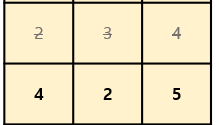
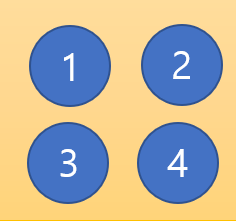 이렇게 4개의 노드가 있으며 각각의 노드를 연결할 수 있는 간선은 아래와 같고 가중치 순으로 정렬을 한 상태이다.
이렇게 4개의 노드가 있으며 각각의 노드를 연결할 수 있는 간선은 아래와 같고 가중치 순으로 정렬을 한 상태이다.
먼저 가중치가 가장 적은 1번과 2번을 2의 가중치로 연결하겠다.

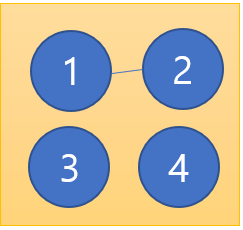 현재 가중치의 총합은 2로 1번과 2번이 서로 연결되어 있다.
현재 가중치의 총합은 2로 1번과 2번이 서로 연결되어 있다.
이제 가중치가 2번째로 적은 간선인 1번-3번을 2의 가중치로 연결하겠다.

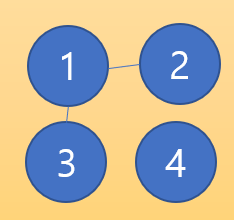 현재 가중치의 총합은 4로 1번, 2번, 3번이 서로 연결되어 있다.
현재 가중치의 총합은 4로 1번, 2번, 3번이 서로 연결되어 있다.
그리고 가중치가 3번째로 작은 간선은 2번과 3번을 연결하는 간선인데 2번과 3번은 이미 서로 연결되어 있기 때문에 무시하고 4번째로 가중치가 작은 간선을 이용해 2번과 4번 노드를 5의 가중치로 연결한다.
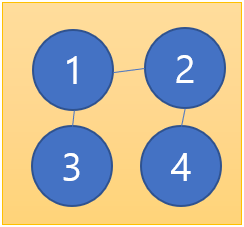 결과적으로 모든 노드가 연결되었고 가중치의 총합은 9가 되었다. 모든 노드가 연결되었기 때문에 이후의 간선은 무시한다.
결과적으로 모든 노드가 연결되었고 가중치의 총합은 9가 되었다. 모든 노드가 연결되었기 때문에 이후의 간선은 무시한다.
이렇게 크루스칼 알고리즘을 사용한 결과 트리의 모든 노드를 연결하는 데 필요한 최소 비용이 9인 것을 알게 되었다.
코드로 보는 크루스칼 알고리즘
import sys
input = sys.stdin.readline
def union(a, b): # 사이클 발생 여부 확인
A = find(a)
B = find(b)
if A>B: # 두 노드의 부모 노드 중 더 작은 숫자의 노드를 부모로 지정
parents[B] = A
else:
parents[A] = B
def find(a):
if parents[a] == a: # 본인이 본인의 부모일 경우 본인을 반환
return a
else:
parents[a] = find(parents[a]) # 경로 압축 사용
return parents[a] # 본인의 부모 노드 반환
V, E = map(int, input().split())
links = [tuple(map(int, input().split())) for _ in range(E)]
parents = [i for i in range(V+1)] # 각 노드의 부모 노드를 저장하는 배열 생성
links.sort(key = lambda x:x[2]) # 간선을 가중치 순으로 정렬
answer = 0
for link in links:
if find(link[0]) == find(link[1]): # 두 노드를 연결시 사이클이 발생할 경우 생략
continue
union(link[0], link[1]) # 두 노드를 연결
answer += link[2] # 두 노드를 연결하는데 사용된 가중치
print(answer) # 가중치의 총합해당 코드는 백준 1197번 최소 스패닝 트리의 정답 코드입니다.
스위핑 알고리즘
스위핑 알고리즘은 한쪽에서 시작점에서부터 반대쪽으로 종료 지점까지 범위를 이동시켜 가며 조건을 조회하는 알고리즘이다.
스위핑 알고리즘의 실행 과정
- 시작점에서 해당 지점에서의 조건을 확인한다.
- 시작점에서 다음 점으로 넘어가서 해당 지점에서의 조건을 확인한다.
- 2번을 종료 지점까지 반복한다.
사실 스위핑 알고리즘은 다른 알고리즘들처럼 특정 문제를 해결한다기보다는 보조적인 느낌으로 사용한다는 느낌이라 다른 알고리즘들에 비해 설명할 것이 없다. 스위핑 알고리즘의 역할은 범위를 순서대로 조회하게 해준다 정도이고 결국 중요한 것은 각 구간에 적용하는 조건이다.
최소 회의실 개수
스위핑 알고리즘 단독으로는 이렇다 할 얘기가 없으므로 이번에는 백준 19598번 최소 회의실 개수를 풀어보며 스위핑 알고리즘을 설명해 보겠다.
해당 문제의 조건은 회의의 시작 시간과 종료 시간을 입력받고 모든 회의가 진행가능한 최소한의 회의실 개수를 구하는 것이다.
가장 먼저 회의 일정이 아래와 같다고 하자. 회의 일정은 시작 시간순으로 정렬한 것이다.
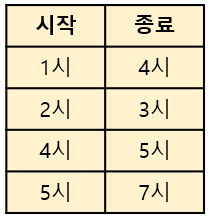
일단 첫 번째 회의인 1시~4시 회의를 시작하겠다. 이렇게 되면 회의실 하나가 4시까지 사용 중인 상태가 된다.

그다음으로 두 번째 회의인 2시~3시 회의를 시작하겠다. 회의실 하나가 4시까지 사용 중이므로 회의실 하나를 추가하여 그 곳에서 회의를 진행하고 해당 회의실은 3시까지 사용 중 상태가 된다.

이번에는 세 번째 회의를 진행하겠다. 4시에 시작하므로 두 곳 모두 비어있을 것이다. 아무 곳에나 들어가서 회의를 진행하겠다.

마지막으로 5시~7시 회의를 진행하려고 한다. 이전에 세 번째 회의도 5시에 끝이 났으므로 모든 회의실이 비어 있다. 이번에도 아무 곳에나 들어가서 회의를 진행하면 된다.

이렇게 회의가 모두 끝났고 모든 회의를 문제없이 진행하기 위해 필요한 회의실의 개수는 2개이다.
최소 회의실 개수 정답 코드
import sys
import heapq
input = sys.stdin.readline
N = int(input())
meeting = []
nowRoom = []
for i in range(N):
meeting.append(tuple(map(int, input().split())))
meeting.sort() # 회의를 시작 시간 순으로 정렬
maxMeetingRoomCount = 0 # 최대 회의실 개수
for s, e in meeting: # <- 이 부분이 스위핑 알고리즘
# 위에서 말했듯이 스위핑은 그냥 구간 탐색을 도와줄 뿐이고 중요한 것은 아래의 조건 처리 로직
while nowRoom and nowRoom[0] <= s: # 현재 시간 이전에 끝난 회의는 회의 종료 처리
heapq.heappop(nowRoom)
heapq.heappush(nowRoom, e) # 현재 회의를 시작하고 종료 시간을 진행중인 회의 목록에 추가
if maxMeetingRoomCount < len(nowRoom): # 만약 현재 사용중인 회의실 개수가 최대 회의실 개수보다 크면 최대 회의실 개수로 저장
maxMeetingRoomCount = len(nowRoom)
print(maxMeetingRoomCount)최소 회의실 개수 문제에서 스위핑의 활용
최소 회의실 개수는 스위핑을 활용한 간단한 문제로 스위핑을 어떻게 활용해야 하는지 보여주기 좋을 것 같아 가져왔다. 위의 코드를 보면 알겠지만 사실 스위핑 알고리즘은 별로 할 얘기가 없다. 그저 회의를 시작 시간순으로 정렬하여 순서대로 가져왔을 뿐이다.
결국 가장 중요한 것은 구간별로 조건을 처리하는 로직이다. 해당 문제에서는 회의 시작 시, 힙에 회의 종료 시간을 저장하였고, 각 시점마다 현재 시점 이전에 끝난 회의를 모두 회의 목록에서 삭제해 가며 그때그때 필요한 회의실의 개수를 조회하며 최대 회의실 개수를 탐색했다.
스위핑 알고리즘을 활용할 때의 시간 복잡도 계산
스위핑 알고리즘을 활용할 때 시간 복잡도를 계산하기 위해서는 본인의 조건 처리 로직이 어느 정도의 시간 복잡도를 갖는지 알아야 한다.
예시를 위해 위의 코드의 시간 복잡도를 계산해 보겠다. 일단 스위핑 알고리즘을 사용하기 위해서는 조건에 따라 정렬을 해야하므로 정렬에 필요한 시간 복잡도가 이고 각 구간을 한 번씩은 조회하기 때문에 조회에 필요한 시간복잡도는 이다.
가장 중요한 부분은 본인이 사용한 로직이므로 찬찬히 시간 복잡도를 계산해보자.
일단 힙에서 가장 작은 값을 가져오는 시간 복잡도는 이기 때문에 가장 빠른 회의 종료 시간을 가져와 현재 회의의 시작 시간과 비교하는 부분은 의 시간 복잡도를 가진다.
다음으로 현재 회의 시작 이전에 끝난 회의 하나를 힙에서 제거하는 데는 이 걸릴 것이다. 그런데 이러면 이 될 수도 있지 않냐고 생각할 수 있는데 한 번 회의 목록에서 삭제된 회의는 다시 힙에 들어오지 않기 때문에 개 이상의 원소를 조회할 일이 없다는 것이 보장된다. 따라서 이 부분은 하나의 회의를 삭제하는 데 필요한 연산 전체 회의의 개수로 이 될 것이다.
마지막으로 현재 회의의 종료 시간을 힙에 삽입하는 데는 시간이 걸린다.
이를 모두 합쳐보면 으로 이를 간소화시키면 이 된다.
위상 정렬
위상 정렬 알고리즘은 대상들 간의 우선순위가 정해져 있는 대상들을 정렬하는 알고리즘이다. 여기서 우선순위가 정해져 있다는 것은 특정 대상이 다른 특정 대상보다 앞에 오는 것이 불가능하다는 뜻이다.
예를 들어 게임에서 스킬을 습득하려 할 때 선행 스킬을 습득한 상태여야 습득이 가능한 경우가 있다. 이런 경우 스킬들 간의 우선순위가 정해져 있어 선행 스킬을 습득하고 해당 스킬을 습득할 수 있지, 해당 스킬을 습득한 후 선행 스킬을 습득할 수 없다. 이런 경우가 위상 정렬을 쉽게 설명할 수 있는 예시가 되는 경우이다.
참고로 위상 정렬의 시간 복잡도는 대상의 개수가 V, 우선순위의 개수가 E라고 할 때 가 된다.
일단 모든 대상을 정렬하려면 각 대상을 모두 한 번씩 조회하여야 하기 때문에 가 된다. 그다음 각 대상의 하위 대상을 조회하여야 하는데 모든 대상의 하위 대상의 개수의 합은 우선순위의 개수와 같다. 따라서 가 된다. 그렇기 때문에 둘을 합쳐 의 시간 복잡도가 된다.
위상 정렬의 수행 과정
- 입력받은 대상들 간의 우선순위를 저장하고 하위 대상이 가진 상위 대상 개수를 +1 해준다.
- 상위 대상이 없는 대상들은 꺼내온다.
- 꺼내온 대상들의 하위 대상들의 상위 대상 개수를 -1 해준다.
- 1번부터 3번을 반복하며 모든 대상을 꺼낸다.
위의 과정은 상위 대상이 없는 대상을 꺼내 해당 대상들의 하위 대상의 상위 대상 개수를 하나씩 줄여간다. 따라서 상위 대상이 있는 대상은 자신의 상위 대상을 모두 꺼내기 전까지는 꺼낼 수 없다. 따라서 대상들 간의 우선순위에 따라서 대상을 정렬하는 것이 가능해진다. 이 부분은 코드를 보면 좀 더 이해가 쉽게 갈 것이다.
그림으로 보는 위상 정렬
설명만으로는 충분히 이해가 가지 않을 것 같아 아래의 예시로 좀 더 쉽게 알아보겠다.
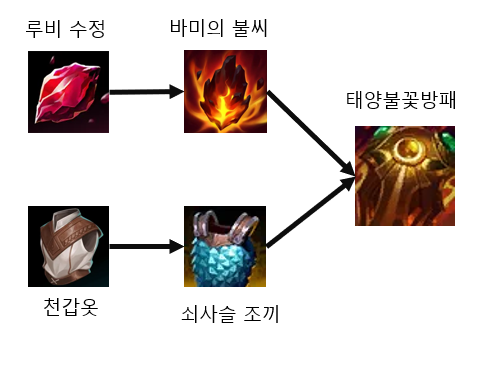
위는 리그오브레전드라는 게임의 아이템인 태양불꽃방패로 앞의 아이템들(바미의 불씨, 쇠사슬 조끼)이 모두 구비되어 있어야 구매가 가능하다. 그런데 바미의 불씨와 쇠사슬 조끼는 각각 루비 수정과 천갑옷이 구비되어 있어야 구매가 가능하다.
이에 따라 각각의 우선순위를 아래와 같이 정의하겠다. 여기서 우선순위는 필요한 하위 아이템의 개수이다.
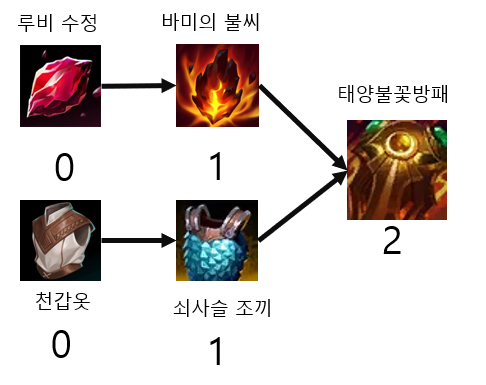
이제 루비 수정을 구매해 보겠다.
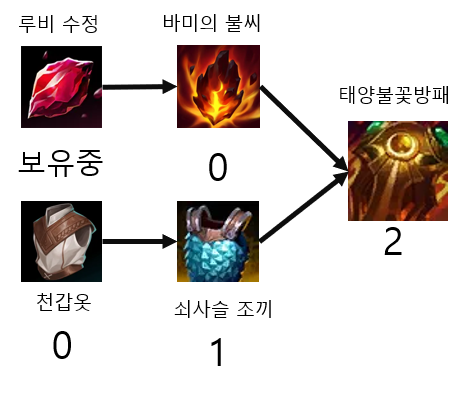 루비 수정을 구매하였으니 바미의 불씨의 필요 하위 아이템 개수에서 1을 빼주었고 그 결과 바미의 불씨는 구매 가능 상태가 되었다.
루비 수정을 구매하였으니 바미의 불씨의 필요 하위 아이템 개수에서 1을 빼주었고 그 결과 바미의 불씨는 구매 가능 상태가 되었다.
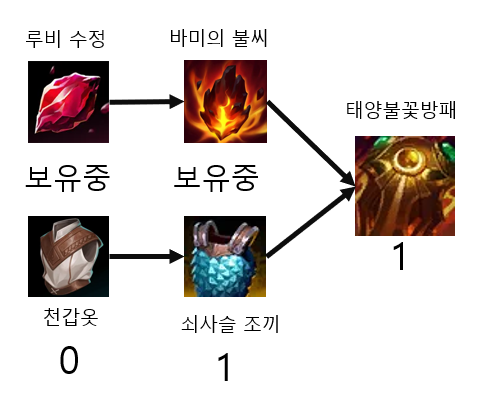 바미의 불씨까지 구매를 하였고 그에 따라 태양불꽃방패의 필요 아이템 개수는 1개가 되었다.
바미의 불씨까지 구매를 하였고 그에 따라 태양불꽃방패의 필요 아이템 개수는 1개가 되었다.
이제 천갑옷을 구매하겠다.
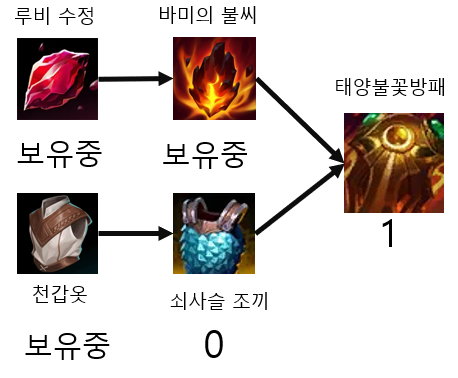 이제 쇠사슬 조끼가 구매 가능하게 되었으니 쇠사슬 조끼까지 구매하겠다.
이제 쇠사슬 조끼가 구매 가능하게 되었으니 쇠사슬 조끼까지 구매하겠다.
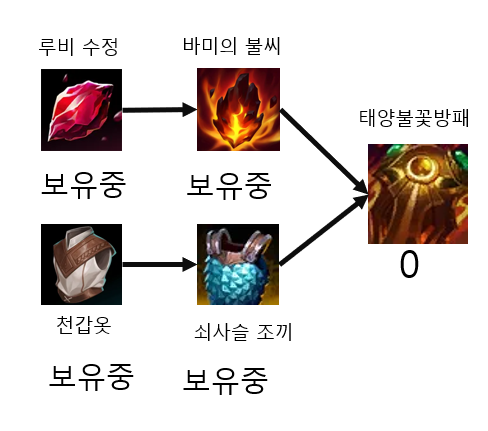 쇠사슬 조끼까지 구매한 결과 마침내 태양불꽃방패를 구매할 수 있게 되었다.
아이템을 구매하는 순서는 다양할 수 있다. 루비 수정을 구매한 후 천갑옷을 구매해도 되고 쇠사슬 조끼를 먼저 구매한 후 바미의 불씨를 구매해도 상관이 없다. 하지만 아이템을 구매하는 순서가 바뀌었더라도 쇠사슬 조끼를 구매하기 전에 태양불꽃방패를 구매하거나 루비 수정을 구매하기 전에 바미의 불씨를 구매하는 경우는 불가능하다.
쇠사슬 조끼까지 구매한 결과 마침내 태양불꽃방패를 구매할 수 있게 되었다.
아이템을 구매하는 순서는 다양할 수 있다. 루비 수정을 구매한 후 천갑옷을 구매해도 되고 쇠사슬 조끼를 먼저 구매한 후 바미의 불씨를 구매해도 상관이 없다. 하지만 아이템을 구매하는 순서가 바뀌었더라도 쇠사슬 조끼를 구매하기 전에 태양불꽃방패를 구매하거나 루비 수정을 구매하기 전에 바미의 불씨를 구매하는 경우는 불가능하다. 또한 루비 수정과 천갑옷이 1단계 아이템이고 바미의 불씨와 쇠사슬 조끼는 2단계 아이템이지만 루비 수정과 쇠사슬 조끼, 천갑옷과 바미의 불씨 사이에는 우선순위가 없기 때문에 바미의 불씨를 천갑옷보다 먼저 구매하는 것도 가능하다.
중요한 것은 서로 간의 우선순위가 있는 대상들의 순서지 모든 대상들 간의 순서가 아니다. 이런 식으로 특정 대상들 간의 우선순위가 정해져 있고 해당 순위에 맞게 대상들을 정렬을 하는 것이 위상 정렬이다.
코드로 보는 위상 정렬
from collections import deque
import sys
input = sys.stdin.readline
N, M = map(int, input().split())
topology = [0] * (N+1)
graph = [[] for _ in range(N+1)]
for _ in range(M):
A, B = map(int, input().split())
graph[A].append(B) # 대상들간의 우선 순위를 저장
topology[B] += 1 # 하위 대상이 가진 상위 대상 개수+1
q = deque()
for i in range(1, N+1):
if topology[i] == 0: # 현재 상위 대상이 없는 대상들부터 꺼내옴
q.append(i)
while q:
num = q.popleft()
print(num, end=' ')
for next_num in graph[num]:
topology[next_num] -= 1 # 본인의 하위 대상의 상위 대상 개수-1
if topology[next_num] == 0: # 만약 해당 하위 대상이 더 이상 상위 대상이 없을 경우 꺼내오기
q.append(next_num)해당 코드는 백준 2252번 줄 세우기의 정답 코드로 매우 간단한 위상 정렬 코드입니다.
후기
이 글의 대상과 읽으며 유의할 점
최근에 알고리즘 공부를 다시 시작한 김에 내가 아는 것들을 되새겨 볼 겸 이 글을 작성하였다. 이 글의 대상은 백준 기준 골드 중~하위권 정도의 실력을 가진 사람들인데 과연 이 글이 도움이 될지 모르겠다. 만약 이 글을 읽고 제대로 이해가 가지 않더라도 본인의 부족이 아닌 글쓴이의 부족으로 생각해 주길 바란다.
또한 나의 부족한 실력으로 인해 틀린 내용이 있을지도 모르니 너무 맹신은 하지 말아주길 바라고 그냥 시간 날 때 가볍게 읽어 볼 정도의 글로 생각해 줬으면 한다.
수많은 좌절을 마주하고 있을 코테 준비자들에게
코딩 테스트를 대비해서 알고리즘을 준비하는 사람들은 아마 좌절을 마주한 적이 있을 것이다. 남들은 쉽게 실력이 느는 것 같은데 본인은 늘지 않는 것 같고 뒤쳐지는 느낌을 받을 수도 있다. 나 역시 그렇다.
나도 현재까지 수많은 좌절을 경험했고 지금도 계속해서 좌절을 하는 중이다. 사실 애초에 이 글을 쓴 이유도 최근 알고리즘을 다시 시작하고 나서 높은 난이도의 문제들에 벽을 느끼고 나의 알고리즘 지식에 대한 검증이었다.
그리고 이 글을 쓰며 내가 예전에 비해 많이 성장했다는 것을 발견했다. DFS, BFS도 어려워하던 내가 이제 그것보다 훨씬 어려운 알고리즘에 대해 설명하는 글을 쓰고 있다니 웃긴 일이다. 아마 이 글을 읽는 사람들도 예전에 비해 성장했을 것이다. IF 문과 FOR 문에 쩔쩔매던 차마 개발자라고 부르기도 힘든 시절과 비교해 보면 말도 안 되는 성장일 것이다.
사실 이 얘기는 알고리즘에만 국한된 이야기가 아니라 내 커리어 전체를 돌아봐도 똑같은 얘기인 것 같다.
나는 제자리걸음이라고 느꼈지만 결국은 조금씩 전진했고 현재의 위치까지 왔다. 그러니 이 글을 읽는 사람들만이라도 본인을 믿어주길 바란다. 본인을 아끼고 사랑해 주라는 말은 못 하겠다. 나조차 그렇지 못하니까. 그 대신 그냥 믿어만 줘라. 지금은 본인이 무능력해 보이고 늘 실패와 좌절만 반복하는 것처럼 보일지라도 언젠가는 해낼 수 있는 사람이라고 믿어줘라.
글이 길었지만 사실 그냥 마지막 문장을 바치고 싶었다.
수많은 좌절을 마주하고 있을 사람들에게
그리고 수많은 좌절을 마주했고 앞으로도 마주할 나에게

잘 읽었습니다!! 틈새지식만으로도 너무 좋은 인사이트인 것 같아요~