
코드 유사성 판단 시즌2 AI 경진대회
코드 유사성 판단 경진대회는 두 개의 코드를 입력받고 그 두 코드가 같은 문제를 해결하는 코드인지를 추측하는 모델을 제작하는 대회이다.
모델 선정
일반적인 언어가 아닌 코드였기 때문에 어떤 모델을 사용할지 탐색을 해보았고 codebert와 graphcodebert라는 모델이 있다는 것을 알게 되었다.
codebert와 graphcodebert는 모두 대량의 코드를 학습한 언어 모델로 코드를 학습한 bert 같은 느낌으로 생각하면 될 것 같다.
둘 간의 차이에 대해 알아보면 graphcodebert는 codebert의 개선판 같은 느낌으로 변수들의 관계를 인코딩하여 성능을 개선했다고 한다.
나는 기학습 모델을 탐색하는 과정에서 neulab/codebert-cpp, microsoft/graphcodebert-base를 사용하기로 하였는데 앙상블을 고려하여 codebert와 graphcodebert 모델을 각각 하나씩 선정하였다.
데이터 처리
토큰 길이 제한으로 인한 토큰 제거 시 앞부분부터 제거
코드에서 중요한 부분은 앞부분보다 뒷부분에 많이 등장한다고 하므로 토큰이 개수 제한을 넘어가면 앞부분부터 제거하도록 수정하였다.
(ex. 대부분의 코드에서 앞부분은 라이브러리 출력이나 변수 선언 등이 나오고 뒷부분에 기능 구현이 나옴)C++ 코드의 주석 제거
코드 파일을 몇 개 열어서 확인해 본 결과, 파일마다 주석의 언어가 달랐기 때문에 모두 제거해 주기로 결정하였다.
C++ 코드 주석 종류
// 주석
/*
주석
*/
//주석 \
주석 \
주석
#if 0
주석
#endif
모두 제거코드 내의 수식이나 논리 연산자 띄어쓰기 통합
같은 코드가 띄어쓰기로 인해 다르게 인식되는 것을 방지하였다.
ex1. 1 + 1, 1+1, 1+ 1 => 1+1로 통합
ex2. A && B, A&&B =>A&&B로 통합#include 제거
라이브러리 선언문을 제거하여도 코드에 선언되어 있는 함수명을 보면 코드의 내용을 파악하는데
문제가 없을 것이라 생각하여 제거std 선언 부분 제거
using namespace std와 std:: 문을 모두 제거하여 두 포맷을 하나로 통합시키는 효과를 가져올 수 있을 것으로
보이고 cin, cout 등의 함수명을 통해 코드 내용을 파악할 수 있으므로 std 관련 내용을 삭제해도 문제가 되지
않을 것으로 보임 앙상블
서로 다른 모델들을 학습하고 앙상블 → codebert와 graphcodebert 두 개의 모델을 각각 학습하여 앙상블을 진행하였다.
학습데이터를 여러 개 생성하여 각각 학습하고 앙상블 → 해당 대회에서는 주어진 학습 데이터가 없고 코드 파일들이 주어지고 이를 직접 짝을 지어주며 학습 데이터를 생성해야 했다. 나는 랜덤하게 두 개의 코드를 짝지어주는 방식으로 학습데이터를 생성했는데(같은 문제를 해결하는 짝과 서로 다른 문제를 해결하는 짝의 비율은 서로 맞춰줄 수 있도록 코드를 짰다.) 이때 KFold를 응용하여 서로 다른 데이터들로 학습된 모델들을 앙상블 하면 더 좋은 성능이 나오지 않을까 생각하여 랜덤 시드 값을 바꿔가며 여러 개의 학습데이터를 생성하였다.
대회 결과
PUBLIC 9등
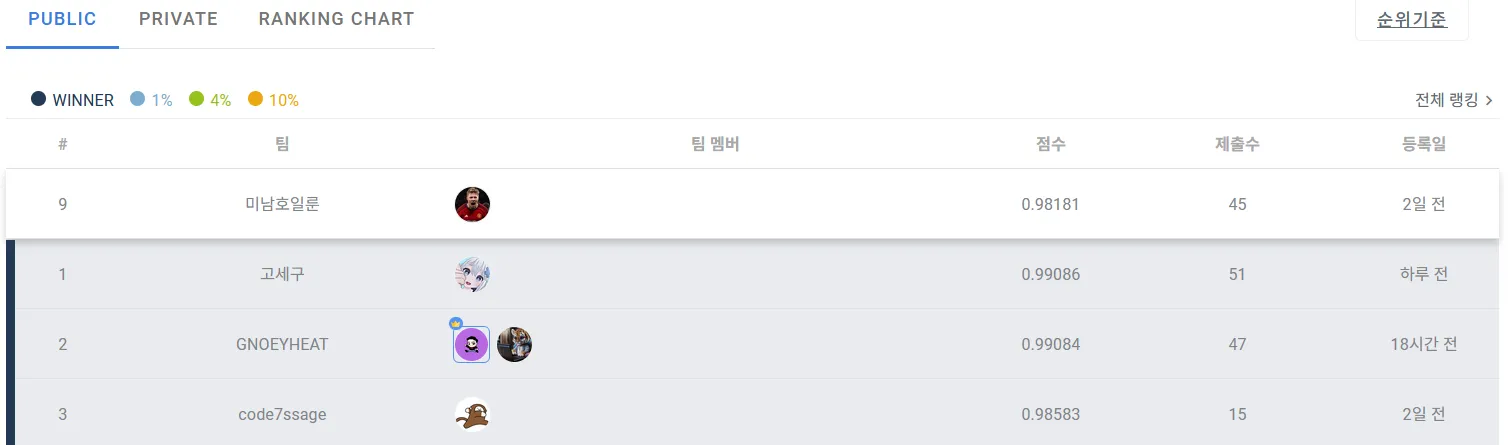
PRIVATE 10등
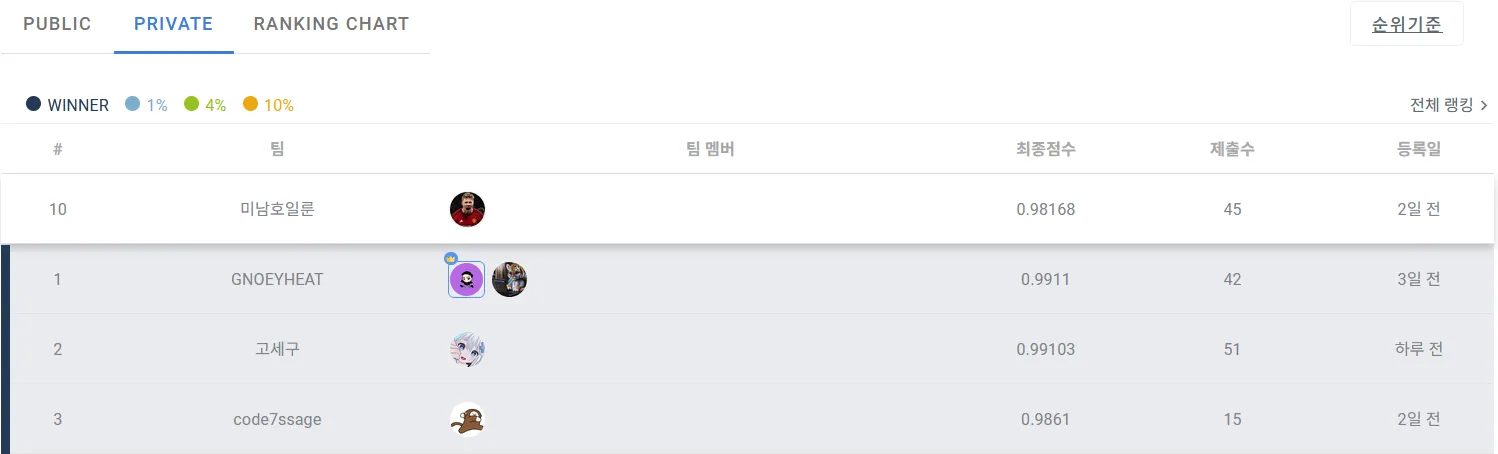
리더보드 기준 133명이 참가한 대회에서 최종 순위 10위로 대회를 마무리했다.
대회 후기
수상을 실패한 것은 아쉽지만 오랜만에 NLP 프로젝트를 간단하게나마 진행해 볼 수 있어서 좋았고 기존에 진행해 봤던 한국어나 영어 데이터가 아니라 코드로 NLP 프로젝트를 진행했던 것이 매우 신선했다.
다른 참가자들의 후기를 보니 나처럼 작은 데이터로 학습한 모델을 활용하지 않고(사실 1회 대회에서 대량의 데이터로 학습한 모델들이 좋은 순위를 거두었기 때문에 생각을 해보았지만, 개인 GPU가 없이 케글과 코랩의 GPU 서버를 사용하다 보니 사용량 제한으로 인해 대량의 데이터로 학습하는 것이 불가능했다…) 대량의 데이터로 학습한 모델을 활용하였던데 이런 식으로 데이터를 무제한으로 생성할 수 있는 대회의 특징인 것 같다.
대량의 데이터를 학습한 모델들과 경쟁하기 위한 나의 무기가 학습데이터를 여러 개 생성하여 각각 학습하고 앙상블을 하는 방식이었는데 결국 실패를 하였다. 하지만 내 나름 차이를 뒤집기 위한 파훼법을 연구해 보았고 그를 통해 대회 중에나마 수상권에 진입해 보았으니 만족이다.
p.s. 언젠가는 꼭 개인 GPU를 가지고 싶다!
p.s.2 원래 올해 초에 참가한 대회였는데 최근에 데이콘에 다시 관심이 생긴 김에 대회 당시에 작성해놓고 공개하지 않았던 회고록을 공개해 보았습니다.(사실 주제가 안 떠올라서 그렇습니다...)
p.s.3 참고로 이제 데이콘 닉네임을 바꿨기 때문에 미남호일룬은 더 이상 존재하지 않습니다.
이전에 쓴 대회 후기들
뒤늦게 써보는 데이콘 고객 대출등급 분류 해커톤 후기
초보 데이커의 첫 데이콘 수상 후기(웹 로그 기반 조회수 예측 대회 후기)
