
Attention Is All You Need
Attention Is All You Need는 많은 자연어처리 모델에서 사용하는 Transformer를 세상에 알린 논문입니다.
요약
Transformer는 Attention 체제를 바탕으로 하였고 Recurrence와 Convolution 단계를 생략한 간단한 네트워크 아키텍쳐입니다. 이 모델은 2개의 기계번역 작업을 통해서 품질이 우수하며 좀 더 병렬화되어있고 학습 시간이 상당히 줄어든다는 것을 보여줬습니다. Transformer는 English Constituency Parsing을 큰 데이터와 작은 데이터 모두에서 성공적으로 적용하며 여러 작업에 쉽게 일반화시킬 수 있다는 것을 보여줬습니다.
기존의 문제점
Recurrent model은 지금까지 많은 발전을 해왔고 최근의 성과를 통해 성능이 눈에 띄게 향상되었지만 여전히 긴 Sequence를 활용한 학습에서는 문제점을 가지고 있습니다.
Attention mechanism은 distance에 상관없이 dependency를 모델링하는게 가능하지만 긴 sequence를 통한 학습에 문제를 가진 Recurrent Network와 함께 사용되었는데 만약 Attention만을 사용한 Transformer를 사용한다면 더 좋은 성능을 보여줄 수 있을것입니다.
Transformer가 기존의 모델들과 다른 점
기존의 모델들은 연산 횟수가 position들간의 distance에 비례하여 늘어나지만 Transformer에서는 고정된 횟수로 줄어들었습니다. 이 과정에서 effective resolution의 비용이 줄어들었지만 이를 Multi-Head Attention을 통해 완화하였습니다.
또한 Transformer는 RNN이나 convolution없이 Self-attention만을 사용한 최초의 transduction모델입니다.
모델의 구조
Architecture: Transformer는 self-attention을 층으로 쌓고 point-wise 방식을 이용하며 encoder와 decoder가 서로 fully-connected-layers를 이룹니다.
Encoder: Transformer는 Encoder를 N개의 층으로 쌓아 이용하고 Encoder는 layer 하나당 2개의 sub-layer를 갖습니다. 첫 번째 sub-layer는 multi-head attention layer이고 두 번째는 position-wise fully connected feed-forward layer입니다. 첫 번째 sub-layer와 두 번째 sub-layer는 residual connection을 통해 연결돼 있고 각 sub-layer의 출력값은 LayerNorm(x+Sublayer(x))입니다.
Decoder: Decoder도 Encoder와 같이 N개의 층으로 쌓아서 이용하지만 Decoder에서는 layer 하나당 sub-layer가 3개로 Encoder의 output을 처리하기 위한 multi-head attention layer가 추가되었습니다. 이 layer는 뒷부분의 position에 attending 하는 것을 막기 위해 masking 기법을 사용합니다.
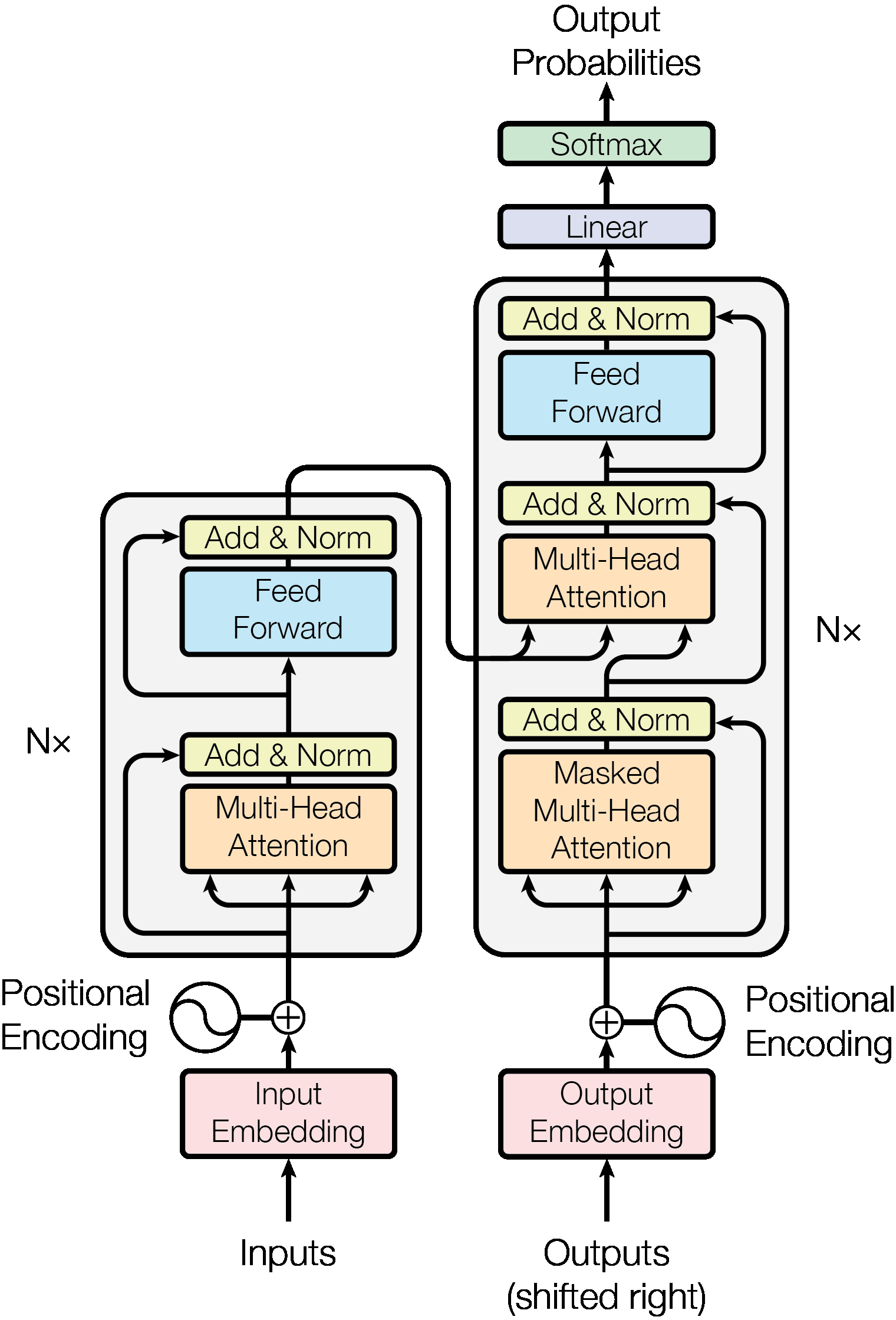
Attention: attention은 쿼리와 키-값 쌍을 output으로 mapping하는 것으로 output은 query와 key의 compatibility function을 통해 계산한 가중치를 적용한 가중합으로 계산됩니다.
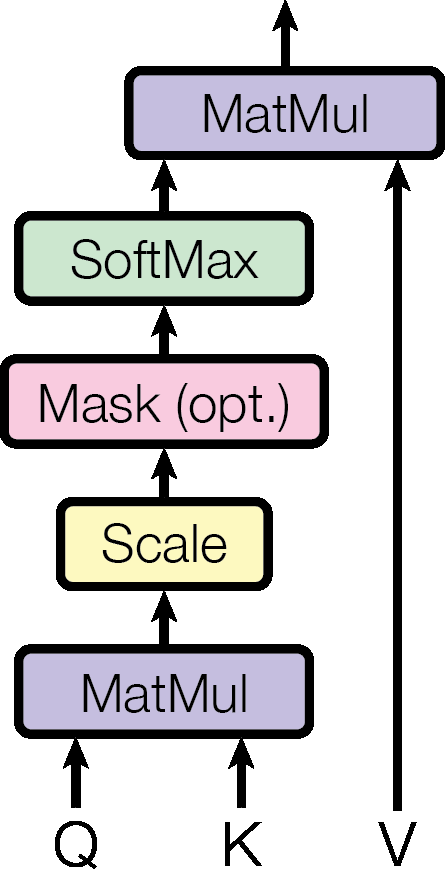
Scaled Dot-Product Attention: Scaled Dot-Product Attention은 기존의 Dot-Product Attention에서 dot product를 로 나누는 연산을 추가한 것입니다. Transformer에서는 내의 큰 값이 softmax 연산에서 문제가 될 수 있다고 생각되어서 dot product를 로 스케일링했습니다.
Scaled Dot-Product Attention의 수식은 입니다.
아래는 Scaled Dot-Product Attention 과정을 그림으로 표현한 것입니다.
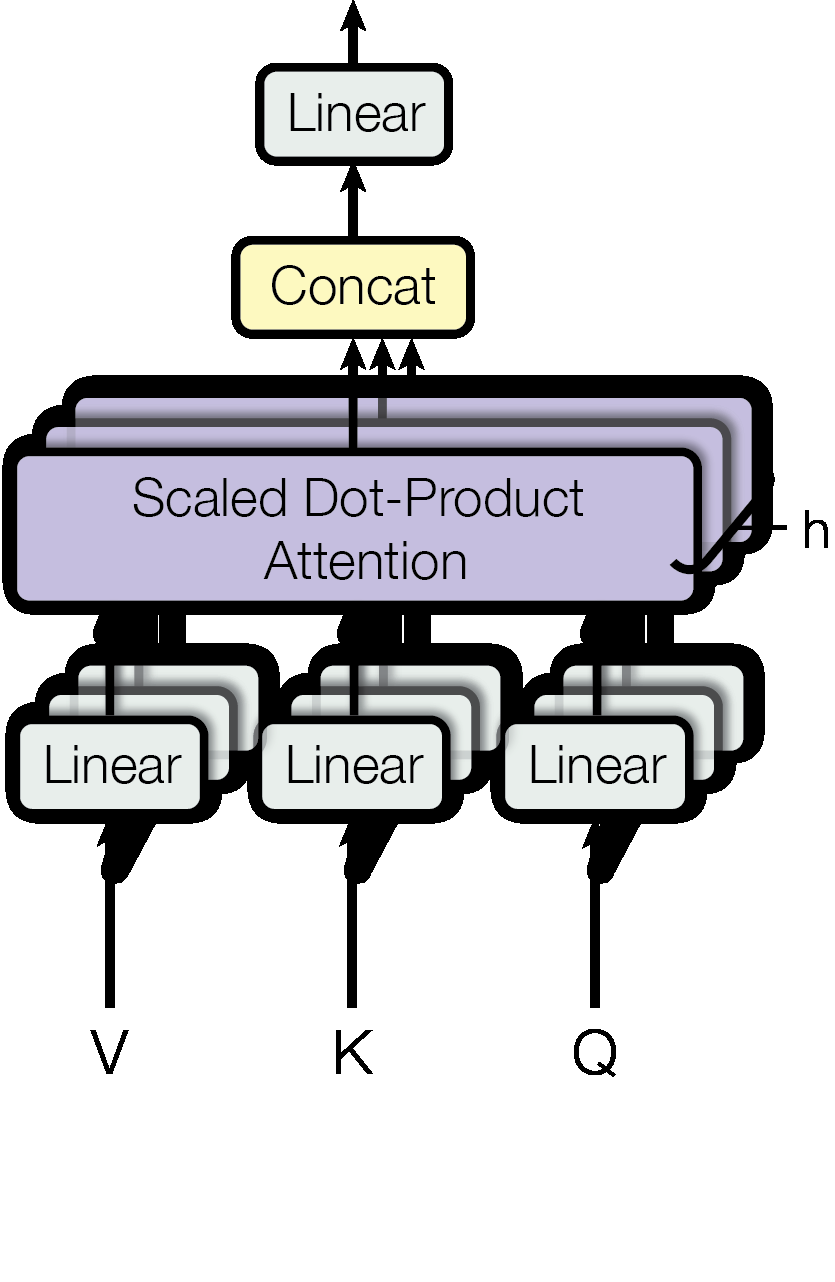
Multi-Head Attention: Multi-Head Attention은 single attention대신 여러 개의 head에서 병렬 attention 연산을 수행한 후 그 값들을 합쳐서 사용하는 방법입니다. Multi-Head Attention을 사용하면 한 쿼리에 대해 여러 attention head에서의 정보를 병렬적으로 사용할 수 있습니다. 또한 각 head의 dimension을 로 축소하였기 때문에 전체 계산량은 single-head attention과 큰 차이가 없습니다.
Multi-Head Attention을 수식으로 표현하면 아래와 같습니다.
MultiHead() = Concat()
where = Attention(, , )
아래는 Multi-Head Attention 과정을 그림으로 표현한 것입니다.
Embedding and Softmax: Transformer는 input token과 output token을 vector로 변환하기 위해 embedding을 사용하고 decoder에서의 output을 확률값으로 변환하는데, softmax를 사용합니다. Embedding과 softmax 전 단계의 linear transformation에서는 같은 값의 weight matrix를 공유하고 weight는 embedding layer에서 로 곱해준 뒤 사용합니다.
Positional Encoding: Transformer는 sequential한 속성을 버렸기 때문에 sequence의 순서를 구분하기 위해서는 token들의 position에 대한 정보를 가지고 있어야 하고 이를 위해 encoder와 decoder의 embedding에 Positional Encoding을 적용합니다. Positional Encoding은 sin 함수와 cos 함수를 이용하고 embedding과 동일한 dimension이기 때문에 둘의 합을 구할 수도 있습니다.
Self Attention을 사용하는 이유
Self attention은 recurrent layer의 계산 복잡도가 sequence의 길이 n에 비례해서 늘어나는 데 반해 n과 상관없이 고정된 숫자의 연산이 필요하므로 계산복잡도 측면에서 유리하고 convolution을 개량한 separable convolution과 비교해도 큰 차이가 없습니다.
Training Setting
이 논문에서는 훈련에 NVIDIA P100 GPU 8개를 사용해서 base model은 약 12시간, big model은 약 3.5일 동안 학습을 진행했습니다. Optimizer로는 Adam을 로 설정하여 사용하였고 학습률은 로(논문에서 step_num=4000) 설정하여 사용하였습니다. Regularization을 위해서는 Residual Dropout과 Label Smoothing을 사용했고 학습 데이터는 WMT 2014 English-German 데이터셋을 이용했습니다.
학습 결과
실험에서 사용한 Base model은 학습 과정에서 10분 간격으로 저장한 checkpoint들 중 마지막 5개를 평균화해서 얻은 model을 사용했고 Big model은 마지막 20개를 평균화해서 사용했습니다. 또한 Transformer의 여러 component들의 중요도를 알아보기 위해 model에 수정을 가하며 테스트도 수행하였습니다.
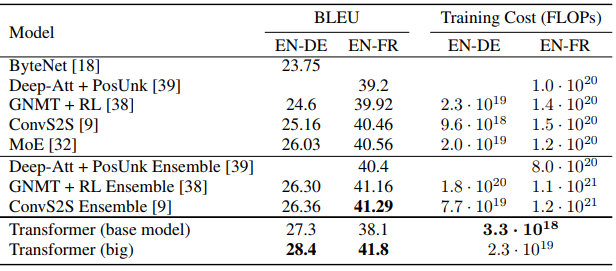
WMT 2014 English-to-German Translation: Transformer의 bigmodel에 WMT 2014 EtG 데이터셋을 활용하여 번역 작업을 한 결과 다른 모델들에 비해서 훨씬 적은 양의 자원을 사용하고도 BLEU에서 28.4점을 받았고 이 점수는 Transformer 이전의 모델들에 비해 2점 이상 높은 점수였습니다.
WMT 2014 English-to-French Translation: Transformer의 bigmodel을 활용하여 EtF 번역 작업도 수행해본 결과 다른 모델들의 1/4 정도의 자원으로 BLEU에서 41.0점을 받았고 이전의 모든 단일 모델들을 능가했습니다.
아래 표는 BLEU점수, 사용된 자원량을 모델 별로 비교한 것입니다.
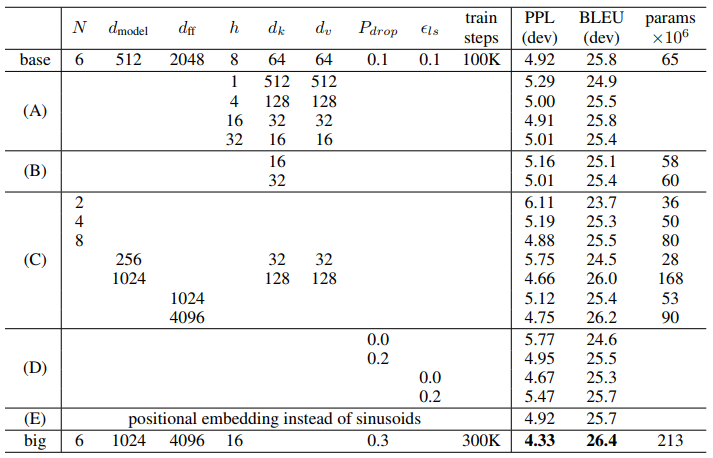
아래는 Transformer의 hyperparameter들을 변경해가며 성능을 비교한 결과입니다.
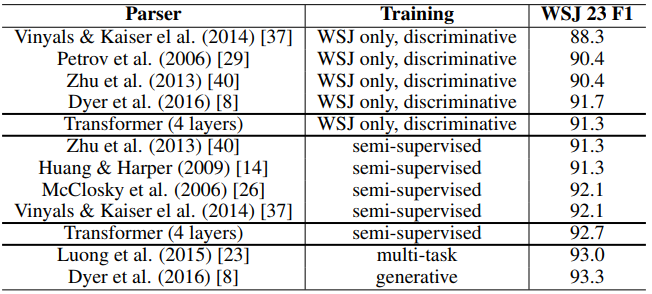
영어 구문 분석 작업: Transformer가 번역 작업 외의 다른 작업에서도 좋은 성능을 보이는지 알아보기 위해서 약 4만 개의 sentence를 가진 Wall Street Journal와 약 1700만 개의 sentence를 가진 BerkleyParser corpora를 사용하여 학습을 진행했고 이 과정에서는 semi-supervised learning을 했습니다. 아래는 영어 구문 분석 작업의 성능을 비교한 표인데 Transformer가 상당히 좋은 성능을 보이는 것을 알 수 있습니다.
결론
이 연구에서는 최초로 recurrence layer없이 attention만을 사용한 sequence transduction 모델인 Transformer를 소개했고 이 모델은 지금까지 나온 모델들을 능가하는 성능을 보여주었습니다. 또한 연구진들은 이 모델을 단순히 text 처리에만 사용하는 것이 아니라 이미지, 오디오, 비디오 등의 데이터도 처리할 수 있도록 연구할 계획이라고 합니다.
후기
논문을 읽어보고 정리하는 것이 처음이라서 논문 이해 자체를 잘 못한 것 같다. 언젠가는 나도 논문을 보고 이해할 수 있는 날이 오면 좋겠다.
