논문? 리뷰?
1.Attention Is All You Need[Transformer]

Attention Is All You Need[Transformer]
2.BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding

BERT 논문 리뷰
3.BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension

BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
4.Improving Language Understanding by Generative Pre-Training

GPT 논문 리뷰
5.NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE

NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE
6.RoBERTa: A Robustly Optimized BERT Pretraining Approach

RoBERTa: A Robustly Optimized BERT Pretraining Approach
7.Efficient Estimation of Word Representations in Vector Space
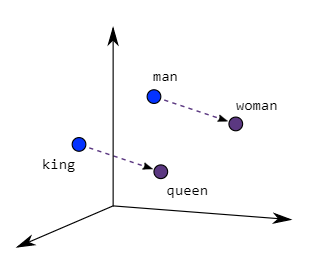
Efficient Estimation of Word Representations in Vector Space
8.Sequence to Sequence Learning with Neural Networks
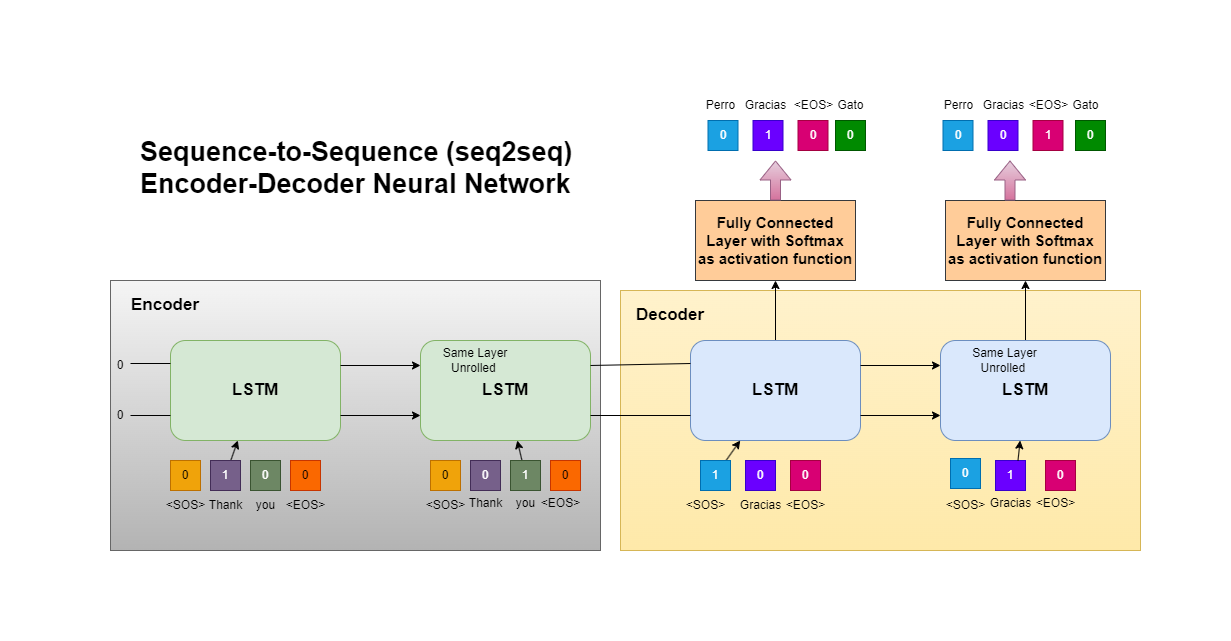
Sequence to Sequence Learning with Neural Networks
9.LLaMA: Open and Efficient Foundation Language Models

LLaMA: Open and Efficient Foundation Language Models
10.EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
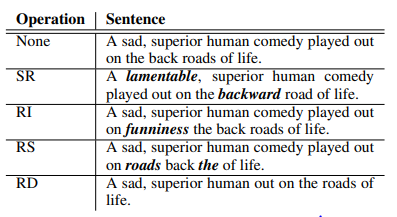
EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks
11.GloVe: Global Vectors for Word Representation

GloVe: Global Vectors for Word Representation GloVe: Global Vectors for Word Representation는 2014년에 스탠포드 대학 연구진들이 발표한 논문입니다. 요약 Glove는 co-occurrence(단어 - 단어 공동 등장 빈도)를 활용하여 단어의 의미를 다차원 벡터에 대입을 시키는 방식...
12.ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS
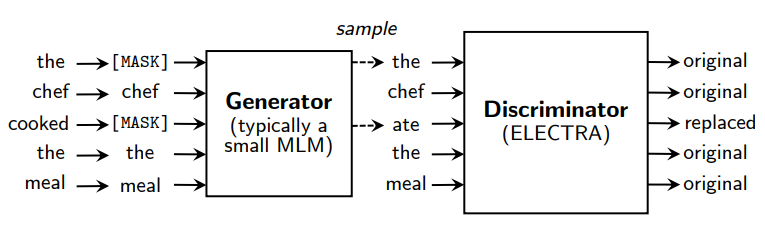
ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS