D+16 😉데이터를 시각화하여 인사이트로 전환하는 과정😉
오늘 한 것:
- SQL 코드 카타 16문제 풀기
- 통계학 기초 완강
- 시각화 이론 & 실습
- TIL 작성

목표:
- 고객의 데이터 시각화 (
연령,성별,지역,구매금액,만족도분석) - 모집단과 표본 이해
- 시각화 유형 선택 이유
- 시각화로 데이터 기반 인사이트 추출
1. 데이터 설명
데이터셋: 8명의 고객 구매 데이터
컬럼
customer_id: 고객 ID
gender: 성별
age: 나이
region: 거주 지역
satisfaction: 만족도 (1~5)
total_spent: 총 구매금액
모집단 vs 표본
- 모집단: 전체 고객
- 표본: 현재 데이터프레임의 8명
# 필요한 데이터
df = pd.DataFrame({
'customer_id': [1, 2, 3, 4, 5, 6, 7, 8],
'gender': ['여성', '남성', '여성', '여성', '남성', '남성', '여성', '남성'],
'age': [22, 35, 29, 41, 30, 48, 27, 33],
'region': ['서울', '부산', '서울', '대구', '부산', '서울', '인천', '서울'],
'satisfaction': [4.5, 3.8, 4.2, 3.9, 4.1, 3.5, 4.7, 3.9],
'total_spent': [250000, 420000, 310000, 290000, 500000, 270000, 320000, 450000]
})!!분석 과정 & 시각화!!
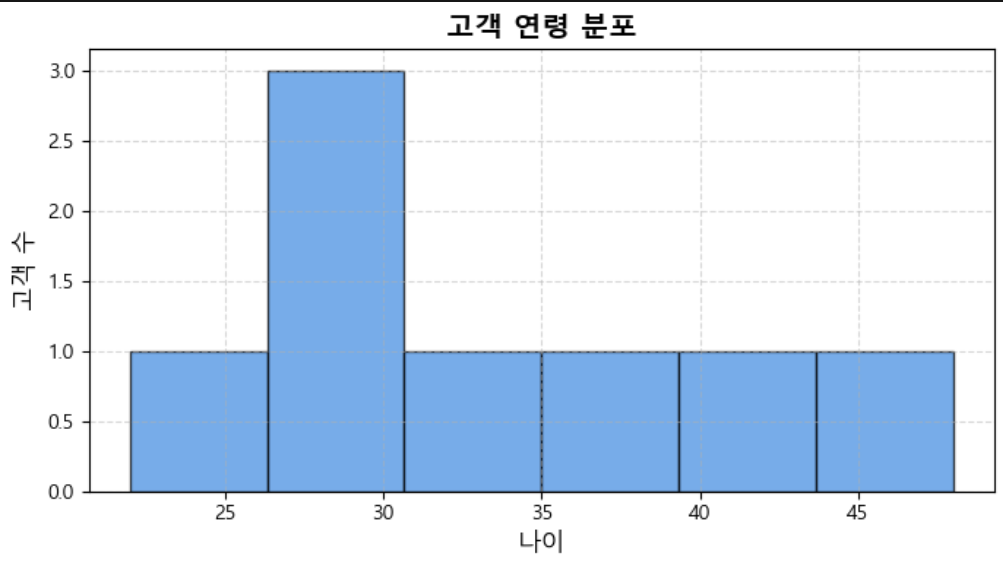
3-1. 연령 분포 (히스토그램)
목적: 고객 나이대 분포 확인
그래프 유형: 히스토그램
→ 연속형 데이터 분포 확인에 적합
x축: 나이
y축: 고객 수
인사이트: 27~30세 구간에 고객이 집중되어 있음
→ 주력 타겟 연령층 추정
코드:
import matplotlib.pyplot as plt
plt.figure(figsize=(6,4))
plt.hist(
df['age'],
bins=5,
edgecolor='black',
color='#84a59d',
alpha=0.8
)
plt.title('고객 연령 분포', fontsize=14, weight='bold')
plt.xlabel('나이', fontsize=12)
plt.ylabel('고객 수', fontsize=12)
plt.grid(alpha=0.3, linestyle='--')
plt.show()결과:
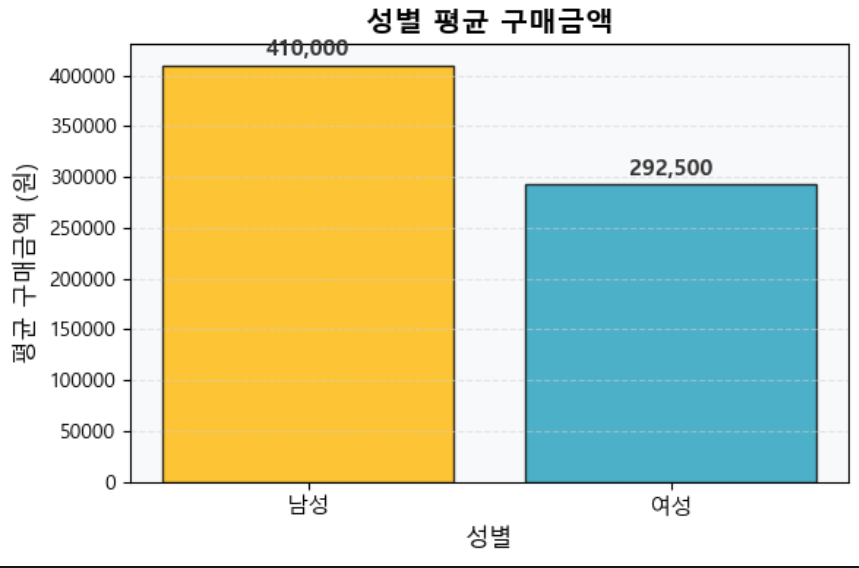
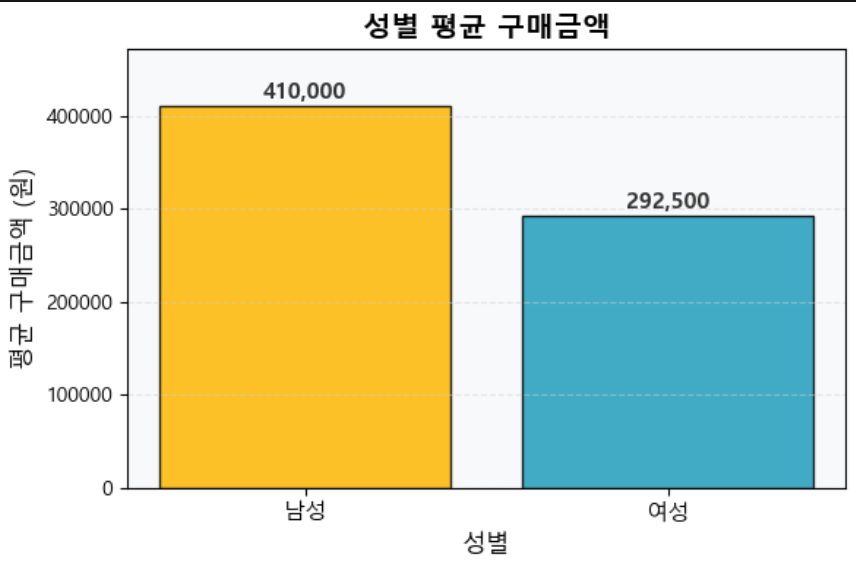
3-2. 성별 평균 구매금액 (막대그래프)
목적: 성별별 평균 구매금액 비교
그래프 유형:
막대그래프 → 범주형 x축, 연속형 y축 비교에 적합
시각적 강조
- 막대 색상 대비
- 막대 위 숫자 라벨 표시
- 그리드 → 값 비교 용이
인사이트
- 남성 평균 구매금액: 410,000원
- 여성 평균 구매금액: 292,500원
- 표본 기준 남성 고객의 구매금액이 더 높음
코드:
plt.figure(figsize=(6,4))
bars = plt.bar(avg_spent_by_gender.index, avg_spent_by_gender,
color=['#ffb703', '#219ebc'], alpha=0.8, edgecolor='black')
plt.title('성별 평균 구매금액', fontsize=14, weight='bold')
plt.xlabel('성별', fontsize=12)
plt.ylabel('평균 구매금액 (원)', fontsize=12)
plt.xticks(fontsize=11)
plt.grid(axis='y', linestyle='--', alpha=0.5)
# y축 범위를 약간 여유있게 설정
plt.ylim(0, avg_spent_by_gender.max() * 1.1)
# 라벨 위치를 막대 위에 적절히 조정
for bar in bars:
height = bar.get_height()
plt.text(bar.get_x() + bar.get_width()/2, height * 1.01, f'{height:,.0f}',
ha='center', va='bottom', fontsize=11, weight='bold', color='#333333')
plt.tight_layout()
plt.show()결과:
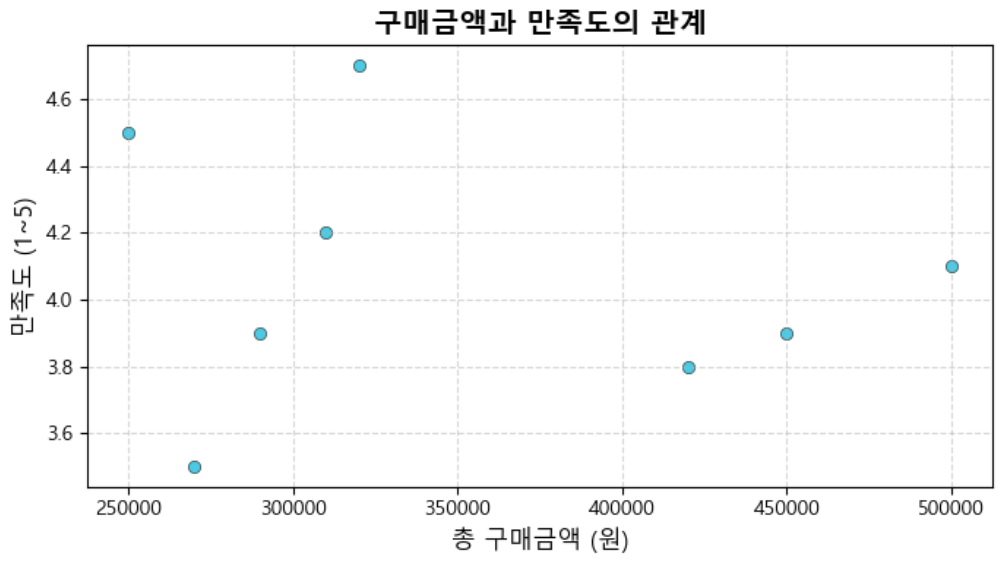
3-3. 구매금액과 만족도 관계 (산점도)
-
목적: 구매금액과 만족도 간 상관관계 확인
-
그래프 유형: 산점도 → 두 연속형 변수 간 관계 시각화
인사이트:
구매금액과 만족도 사이 명확한 상관관계는 보이지 않음.
일부 저금액 고객의 만족도가 낮음
→ 가격 외 요인 만족도에 영향
코드:
plt.figure(figsize=(7,4))
plt.scatter(df['total_spent'], df['satisfaction'],
color='#00b4d8', alpha=0.7, edgecolor='black', linewidth=0.5)
plt.title('구매금액과 만족도의 관계', fontsize=14, weight='bold')
plt.xlabel('총 구매금액 (원)', fontsize=12)
plt.ylabel('만족도 (1~5)', fontsize=12)
plt.grid(True, linestyle='--', alpha=0.5)
plt.tight_layout()
plt.show()결과:
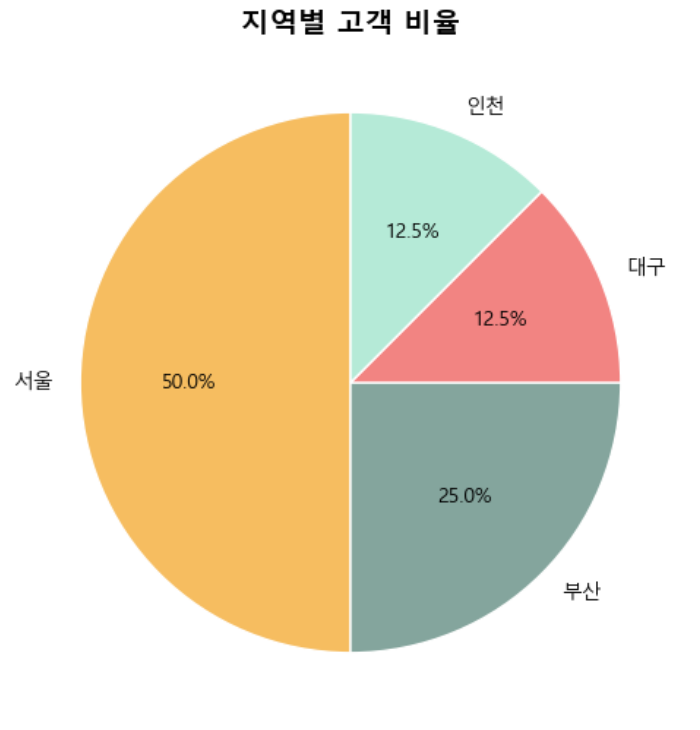
3-4. 지역별 고객 비율 (파이차트)
목적: 고객 지역 분포 확인
그래프 유형: 파이차트 → 전체 대비 비율 직관적 표현
인사이트:
- 서울: 50%, 부산: 25%, 대구/인천: 12.5%
- 서울 중심 고객 다수 → 마케팅 지역 우선 순위 파악 가능
코드:
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame({
'region': ['서울', '부산', '서울', '대구', '부산', '서울', '인천', '서울']
})
region_counts = df['region'].value_counts()
plt.figure(figsize=(6,6))
plt.pie(
region_counts,
labels=region_counts.index,
autopct='%1.1f%%',
startangle=90,
colors=['#f6bd60', '#84a59d', '#f28482', '#b5ead7'],
wedgeprops={'edgecolor': 'white', 'linewidth': 1}
)
plt.title('지역별 고객 비율', fontsize=14, weight='bold')
plt.show()결과:
4. 종합 인사이트
- 주력 고객 연령층: 27~30세
- 성별 구매 차이: 남성 평균 구매금액 높음
- 만족도 요인: 구매금액 외 다른 요인 영향 추정
- 지역별 전략: 서울 고객 비중 높음 → 프로모션 우선 고려
5. 추가 학습 아이디어
- 성별 + 연령대 + 지역 교차 분석
- 이상치(outlier) 분석 후 평균 비교
- 시간별 구매 패턴 분석 → 마케팅 전략 반영
1차 데이터 시각화 & 인사이트 마무리
-
표본 크기
데이터 만드는 게 힘들어서 표본 8명으로 정의하니,
구체적 인사이트 추출이 어려움. -
수치 기반 상관 분석
구매금액 vs 만족도, 수면 vs 집중도처럼 상관 계수(예: Pearson)나 회귀선을 추가하면 인사이트 근거가 강화됨.
번외
최다빈의 수면 패턴 분석하기
import matplotlib.pyplot as plt
from matplotlib import font_manager
plt.rcParams['font.family'] = 'Malgun Gothic'
요일 = ['월', '화', '수', '목', '금', '토', '일']
수면시간 = [2, 4, 4, 7, 3, 10, 8]
집중도 = [3, 7, 5, 9, 4, 6, 8]
막대색 = ['skyblue'] * 7
fig, ax1 = plt.subplots(figsize=(10,6))
ax1.bar(요일, 수면시간, color=막대색, alpha=0.7, label='수면 시간(시간)', edgecolor='gray')
ax1.set_ylabel('수면 시간(시간)', fontsize=12, color='black')
ax1.set_ylim(0, max(수면시간)+2)
ax1.set_xlabel('요일', fontsize=12, color='black')
ax1.tick_params(axis='y', colors='black')
for tick_label, day in zip(ax1.get_xticklabels(), 요일):
if day == '토':
tick_label.set_color('blue')
elif day == '일':
tick_label.set_color('red')
else:
tick_label.set_color('black')
ax2 = ax1.twinx()
ax2.plot(요일, 집중도, color='orange', marker='o', linewidth=2, markersize=8, label='집중도')
ax2.set_ylabel('집중도(1~10)', fontsize=12, color='black')
ax2.set_ylim(0, 10)
ax2.tick_params(axis='y', colors='black')
plt.title('요일별 수면 시간과 집중도', fontsize=16, fontweight='bold', color='black')
ax1.legend(loc='upper left', fontsize=10)
ax2.legend(loc='upper right', fontsize=10)
for i, val in enumerate(수면시간):
ax1.text(i, val + 0.2, str(val), ha='center', fontsize=10, fontweight='bold', color='black')
for i, val in enumerate(집중도):
ax2.text(i, val + 0.2, str(val), ha='center', fontsize=10, fontweight='bold', color='orange')
ax1.grid(axis='y', linestyle='--', alpha=0.5)
plt.show()
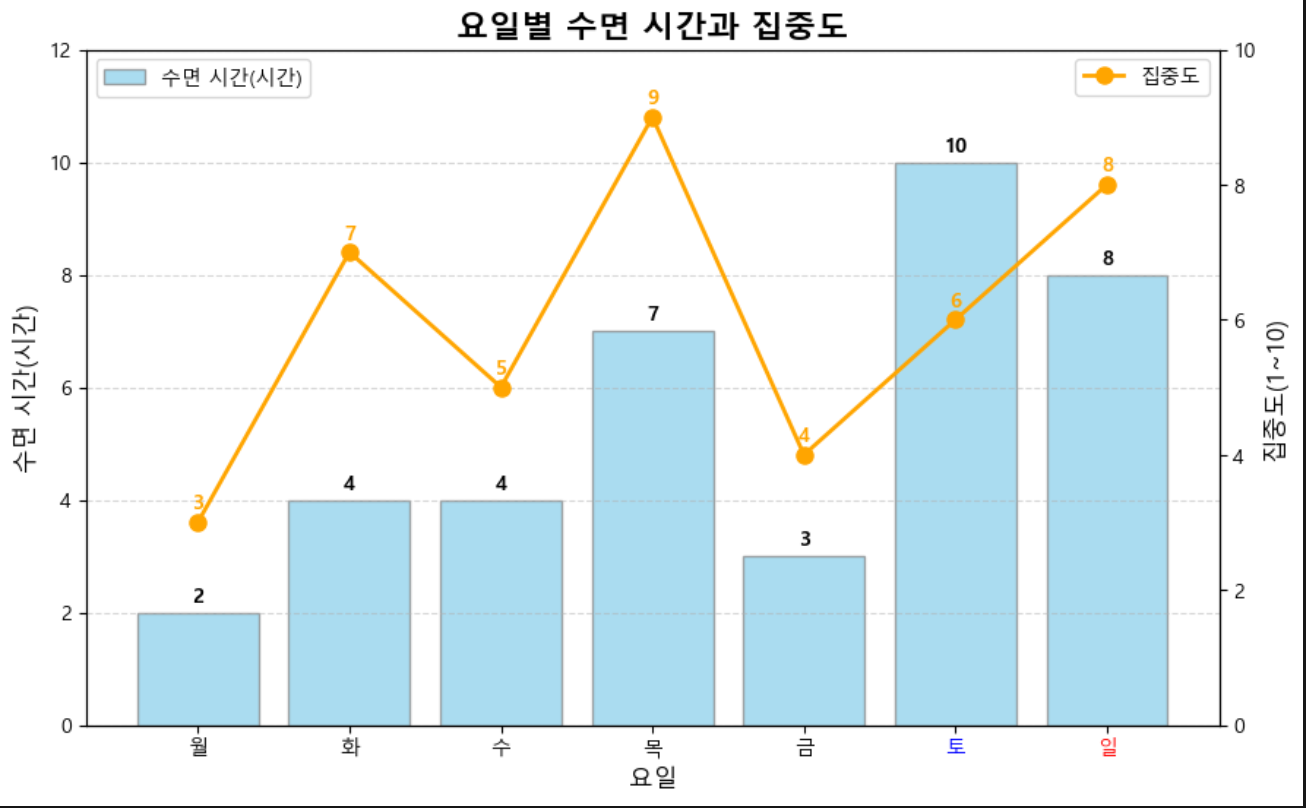
주간 수면 패턴
- 월요일 2시간 수면 → 최저 수면
- 화~수요일: 4시간 수면 → 부족한 수면
- 목요일: 7시간 수면 → 평일 중 가장 긴 수면
- 금요일: 3시간 수면 → 다시 수면 부족
- 토요일: 10시간 수면 → 주말 회복형 수면
- 일요일: 8시간 수면 → 주말 회복 지속
인사이트
- 주중 수면 부족
- 주말 회복 패턴
- 주중 누적 피로 존재 가능성 높음.
집중도 패턴
월요일 집중도 3 → 수면 & 집중도 최저
화요일 집중도 7 → 수면은 적지만 집중도 상대적으로 회복
수요일 집중도 5 → 수면 부족 영향 여전히 존재
목요일 집중도 9 → 수면 7시간으로 집중도 최고
금요일 집중도 4 → 수면 부족 영향 다시 나타남
토요일 집중도 6 → 수면 10시간으로 회복하지만 집중도 낮음.
일요일 집중도 8 → 수면 8시간, 집중도 양호
인사이트
- 수면 시간과 집중도 상관 관계가 나타남.
- 평일 수면 부족, 집중도 낮음
- 충분한 수면, 집중도 상승
요일별 특징
1. 월·금요일: 극단적인 수면 부족 → 집중도 최저
2. 목요일: 수면 충분 → 집중도 최고
3. 주말:
- 수면 시간 최장
- 집중도는 금요일 대비 회복했지만,
목요일만큼 최고치는 아님 → 주중 누적 피로 영향 존재 가능
- 주중 불규칙 수면 → 집중도 변동폭 큼
전략적 인사이트
- 수면 조정 필요: 월~금 수면 2~4시간 → 집중도에 직접적 부정적 영향
- 주말 수면으로만 회복은 부족
- 주말 과다 수면 → 일부 회복 가능하지만
- 평일 집중도 최적화는 힘듦
- 목요일 수면 패턴 주목: 집중도 최고 → 하루 7시간 수면이 최적 수준
수치 기반 상관 분석 가능성
- 수면 시간 vs 집중도: 양의 상관관계
- 주말 vs 평일 패턴: 회복형 수면 → 집중도 완전 회복은 아님
- 월요일 수면 부족 후 집중도 저하 → “주말에 몰아서 수면”보다 평일 일정한 수면 필요성 강조
종합 인사이트
- 주중 수면 부족 → 집중도 급격히 하락 (특히 월·금)
- 평일 7시간 수면 → 집중도 최적화 (목요일 사례)
- 주말 몰아서 수면 → 피로 일부 회복 가능, 집중도 최대치 회복은 어렵다
패턴 개선 제안:
- 평일 최소 6~7시간 수면 유지
- 주말 과다 수면 대신 일정한 수면 패턴 유지
!! 진짜 마무리 !!
1차 데이터 시각화 (구매 고객 데이터)는
사실 sql로 데이터를 만드려다가 포기했다.
그래프 총 4개 (히스토그램, 막대, 산점도, 파이차트) 를 통해
데이터 유형별 적합한 시각화 방법을 직접 적용하며 이해했다.
2차 데이터 시각화 (최다빈의 수면 패턴 분석)은
실제 나의 저번 주 수면 패턴이다.
데이터 분석을 공적으로만 사용하지 않고,
나의 불면은 어떤 이유 때문일까?이라는 사적인 주제로
복합 그래프를 만들어 수면 시간과 집중도를 연관지어 봤다.
나름 인사이트가 나온 것 같아 만족스럽다.
이것도 사실 장기적으로 보는 게 좋을 것 같다는 생각이 들었다.
끝!@#!@#!~@~!@~

