
오늘은 주일이어서 쉬는 날이지만,
항해를 월요일에 시작했기에 딱 한 달, 28일째 되는 날이다.
항해는 말 그대로 바다를 건너는 일처럼 비유가 잘 되는 것 같다.
파도는 언제 어디서 불어올 지 모른다. 그렇다고 늘 긴장해있으면? 당연히 빨리 지친다.
그래서 배에 내 몸을 맡기고 파도를 탈 수 있다면 그게 최고다.
지난 주에는 멘탈이 나갔다가 들어오기까지 힘들었다면,
이번주는 좋은 사람들을 만나면서 순풍이 불어온 듯한 한 주였다.
그렇다고 파도가 그쳤다고 생각이 들지는 않는다.
다만, 잘- 헤쳐나가는 방법을 점차 배워나가는 것이라고 생각한다.
자연은 이길 수 없다. 그 앞에 겸손을 배워나갈 뿐.
Algorithm(1/31 ~ 2/5)
알고리즘이 잘 풀리면 잘 풀리는 대로, 회고를 남기기가 어렵다. 하루의 시작부터 끝까지 알고리즘에 집중이 '되어지기' 때문이다. 참 감사한 일인데 회고를 남길 시간이 없더라는 것이다. 지금은 문제 풀이를 '알고리즘 풀이 노션 페이지'에 쌓고 있는 중이어서 그것으로 만족하며 배운 것에 대한 핵심적인 한 주의 회고만 남기려 한다.
한 주 회고
'나 자신을 완전히 바닥부터 놓고 시작하면 가능하지 않을까?'라고 지난 주 회고에 적었는데 -
월요일부터 도토리 반 사람들을 만나며 순풍이 시작되었다.
한 주의 끝에 우리 조원들과 이런 저런 이야기를 나눌 때에는 '코드업 100제'를 푼 것 자체가 멘탈을 잡는데 큰 영향을 끼친 것 같다는 결론이 났다.
코드업 100제는 아주 기초와도 같다고 볼 수 있는데. 그것이 단순히 도토리 과제인 것을 보고, 하루동안 처음부터 끝까지 도전한 것이었다. 어렵거나 쉽거나, 시간이 얼마나 걸린 것이 중요하지 않았다. 그 날 기쁨으로 gif로 캡쳐까지하며 기록을 남길 정도로 뿌듯했던 그 마음이 너무 중요했다. (그것이 나에게 필요했다)
그리고 그 다음날부터 문제를 쑥쑥 풀어나간 것은 아니다. 그런데 다시, 문제에 접근하겠다는 마음을 먹을 수 있었다. 물론 안 풀리고 삐걱거리고, 다른 사람들은 잘만 풀이하는 것 같을 때에는 짜증이 당연히 올라오긴 했다.
그래도, 하루하루 해나가다 보니 한 주의 마지막 즘엔 알고리즘 공부를 기분 좋은 마음으로 대할 수 있었고 이는 이전의 시간들을 '아는 것 같다'는 생각과 그러다가 '모르는 상태라는 것을 깨달은' 생각의 연속으로 방향을 잡지 못하던 나에게는 너무나 큰 성장이었고 감사한 순간이었다.
코드업 100제 이후로 풀이에 점점 속도가 붙으면서 진정 '피지컬 키우기'에 돌입했다. 그래서 이코테 책에 있는 그리디, 구현, DFS/BFS, 정렬, 이진탐색까지 가리지 않고 계-속 풀었다. 아직도 내 몸은 왜소할 다름이지만, 계속 피지컬을 키워나갈 예정이다.
merge sort
이번 주 배운 것 중에 개인적으로 가장 중요하다고 생각한 것은 merge sort이다.
quick sort는 최악의 경우가 있기에, merge를 확실히 익혀놓는 것이 좋다는 생각이 들었다.
개념은 어렵지 않다. 경우를 다 나누고, 다시 다 모은다(정복한다).
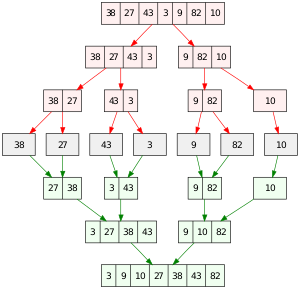
그래서 이런 정렬 방식을 'divide and conquer' 이라고 부른다.(merge sort는 분할 정복 알고리즘 중 하나이다)
이것을 알면 구현에 대한 아이디어를 얻을 수 있다. merge sort를 하기 위해서는 두 가지의 함수가 필요한 것이다.
def merge(arr1, arr2):
result = []
i = j = 0
while i < len(arr1) and j < len(arr2):
if arr1[i] < arr2[j]:
result.append(arr1[i])
i += 1
else:
result.append(arr2[j])
j += 1
while i < len(arr1):
result.append(arr1[i])
i += 1
while j < len(arr2):
result.append(arr2[j])
j += 1
return resultmerge 함수는 따로 생각해보자면 conquer 부분에 해당한다고 볼 수 있다. array 두 개를 합치는 함수이다. 두 배열 안의 원소를 비교해서 작은 것을 반복해서 넣어준다. 하나의 array에서 먼저 다 담은 뒤 남은 array의 원소들도 다 넣어주면 끝.
def mergesort(lst):
if len(lst) <= 1:
return lst
mid = len(lst) // 2
L = lst[:mid]
R = lst[mid:]
return merge(mergesort(L), mergesort(R))이 부분이 나누는 것인데 나눈 뒤에 return에서 merge에 넣어주기 때문에 divide and conquer가 전부 여기서 일어난다고 해도 맞는 말이다.
이 함수는 DFS로 mergesort 함수 안에 하나의 list를 넣어주면 중간 점을 기준으로 나누어서 두 개의 list를 만들어 merge 함수에 넣어준다. 그런데 들어갈 때, mergesort라는 함수의 이름으로 들어가기 때문에 들어가서 다시 가운데를 기준으로 나누어 merge 함수 안에 mergesort 함수의 이름으로 array가 들어간다. 함수가 동작하는 것을 머리로 그리면서 따라가보면,
mergesort 안에서 array가 merge(mergesort(arr1), mergesort(arr2)로 들어가서
mergesort 안에서 arr1가 merge(mergesort(arr1-1), mergesort(1-2)로 들어가서
mergesort 안에서 arr1-1가 merge(mergesort(arr1-1-1), mergesort(1-1-2)로 들어가서
.
.
.
각 배열이 len(lst) <= 1 곧 하나의 원소만 남으면 그 때부터 그 원소를 lst로 반환해준다.
그럼 다시 올라오면서, merge(하나 원소 arr, 하나 원소 arr)로 작은 것부터 넣어서 합쳐주고
merge(합친 arr, 합친 원소 arr)로 작은 것부터 넣어서 합쳐주고
.
.
이런 식으로 올라오면 전체 array가 정렬되는 것이다.
merge sort는 시간 복잡도가 nlogn이기에 꼭꼭 구현할 수 있고, 기억해두기.
heap sort
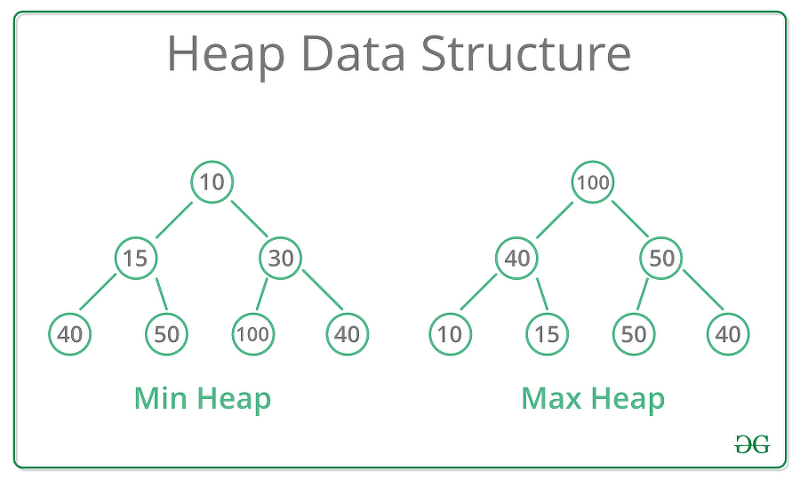
힙은 데이터에서 최대값과 최소값을 빠르게 찾기 위해 고안된 완전 이진 트리라고 한다.
그래서 merge sort 다음으로 정리하고 싶었던 것이 바로 heap sort이다.
문제에서 최대, 최소를 이용해서 풀이하는 것은 참 많이 나오는데 heap은 익숙해지지 않으면 아이디어가 떠오르지 않기 때문이다.
heap 자료구조는 분명한 조건이 있다. 위 그림처럼 이진 트리 중, 부모 노드가 자식 노드보다 큰 것을 max heap. 반대로 부모 노드가 자식 노드보다 작은 것을 min heap이라고 부른다.
BST(이진 탐색 트리)와는 다르다. 좌, 우 자식의 위치가 대소 관계를 반영하지 않기 때문이다.
heap에서는 계산 편의를 위해 인덱스는 1부터 사용한다.
(parent: x, left: 2x, right: 2x+1 - 이렇게 인덱스 값을 설정할 수 있도록)
-> 다음으로는 heap의 구현이 아닌, 파이썬 내장 함수의 내용을 정리하려 한다. 구현은 연습하고 자료구조는 익히되 실전에서는 라이브러리를 잘 사용해야 하기 때문이다.
파이썬 내장함수 heapq에 대한 설명이다.
이 API는 두 가지 측면에서 교과서 힙 알고리즘과 다릅니다:
- (a) 우리는 0부터 시작하는 인덱싱을 사용합니다. 이것은 노드의 인덱스와 자식의 인덱스 사이의 관계를 약간 덜 분명하게 만들지만, 파이썬이 0부터 시작하는 인덱스를 사용하기 때문에 더 적합합니다.
- (b) pop 메서드는 가장 큰 항목이 아닌 가장 작은 항목을 반환합니다 (교과서에서는 《최소 힙(min heap)》이라고 합니다; 《최대 힙(max heap)》은 제자리 정렬에 적합하기 때문에 텍스트에서 더 흔합니다).
파이썬이 제공하는 heapq 함수
- heapq.heappush(heap, item)
힙 불변성을 유지하면서, item 값을 heap으로 푸시합니다.- heapq.heappop(heap)
힙 불변성을 유지하면서, heap에서 가장 작은 항목을 팝하고 반환합니다. 힙이 비어 있으면, IndexError가 발생합니다. 팝 하지 않고 가장 작은 항목에 액세스하려면, heap[0]을 사용하십시오.- heapq.heappushpop(heap, item)
힙에 item을 푸시한 다음, heap에서 가장 작은 항목을 팝하고 반환합니다. 결합한 액션은 heappush()한 다음 heappop()을 별도로 호출하는 것보다 더 효율적으로 실행합니다.- heapq.heapify(x)
리스트 x를 선형 시간으로 제자리에서 힙으로 변환합니다.- heapq.heapreplace(heap, item)
heap에서 가장 작은 항목을 팝하고 반환하며, 새로운 item도 푸시합니다. 힙 크기는 변경되지 않습니다. 힙이 비어 있으면, IndexError가 발생합니다.
이 한 단계 연산은 heappop()한 다음 heappush()하는 것보다 더 효율적이며 고정 크기 힙을 사용할 때 더 적합 할 수 있습니다. 팝/푸시 조합은 항상 힙에서 요소를 반환하고 그것을 item으로 대체합니다.
반환된 값은 추가된 item보다 클 수 있습니다. 그것이 바람직하지 않다면, 대신 heappushpop() 사용을 고려하십시오. 푸시/팝 조합은 두 값 중 작은 값을 반환하여, 힙에 큰 값을 남겨 둡니다.- heapq.nlargest(n, iterable, key=None)
iterable에 의해 정의된 데이터 집합에서 n 개의 가장 큰 요소로 구성된 리스트를 반환합니다. key가 제공되면 iterable의 각 요소에서 비교 키를 추출하는 데 사용되는 단일 인자 함수를 지정합니다 (예를 들어, key=str.lower). 다음과 동등합니다: sorted(iterable, key=key, reverse=True)[:n].- heapq.nsmallest(n, iterable, key=None)
iterable에 의해 정의된 데이터 집합에서 n 개의 가장 작은 요소로 구성된 리스트를 반환합니다. key가 제공되면 iterable의 각 요소에서 비교 키를 추출하는 데 사용되는 단일 인자 함수를 지정합니다 (예를 들어, key=str.lower). 다음과 동등합니다: sorted(iterable, key=key)[:n].
heapq.merge 라는 함수를 제외하고 파이썬 docs에서 다 가져왔다. 하나 하나 세세하게 읽어본 함수들이다.
실제로 사용이 아주 용이할 것 같아서 꼼꼼하게 읽어보고 문제를 풀이할 때도 직접 사용해보았다.
insertion sort
삽입 정렬은 버블, 선택, 삽입 이라는 정렬의 기초(?)를 배울 때 가장 쓸만한 정렬이라고 할 수 있을 것 같다.
버블과 선택은 결국 하나 하나 완전 탐색을 하게 되는 반면, 삽입 정렬은 탐색을 하다가 필요할 때만 위치를 변경하기 때문이다.
그리고 정렬 문제를 풀이하면서 파이썬 내장 sort에 대해 궁금하여 tim sort에 대해 찾아보았는데,
2002년 소프트웨어 엔지니어 Tim Peters에 의하여 Tim sort가 등장했다. 이 정렬 알고리즘은 Insertion sort와 Merge sort를 결합하여 만든 정렬이다.출처 : Naver D2
라고 나와있어서 insertion sort에 대해서도 구현을 반복해보면서 관심을 가지고 체득하려고 하였다.
물론 tim sort는 간단하게 생각해낸 함수가 아니었기에, 완전 이해는 어려웠고 두어번 반복해서 읽어보았다.
튜터님이 insertion sort를 두 가지 방법으로 구현해서 보여주셨는데 개인적으로 첫 번째 방법은 어려웠다.
물론, 그 당시 멘탈이 정상이 아니어서 이해가 잘 되는 쪽만 택했던 것도 있기에, 나중에 다시 강의를 보며 구현에 대해서는 반복해서 연습하려 한다.
def insertionsort_2(lst):
for idx in range(1, len(lst)):
val = lst[idx]
cmp = idx - 1
while lst[cmp] > val and cmp >= 0:
lst[cmp + 1] = lst[cmp]
cmp -= 1
lst[cmp + 1] = val
return lst이해가 잘 되었던 insertion sort 구현
def insertionsort(lst):
# 0번째 요소는 이미 정렬되어있으니, 1번째 ~ lst(len)-1 번째를 정렬하면 된다.
for cur in range(1, len(lst)):
# 비교지점이 cur-1 ~ 0(=cur-cur)까지 내려간다.
for delta in range(1, cur + 1):
cmp = cur - delta
if lst[cmp] > lst[cmp + 1]:
lst[cmp], lst[cmp + 1] = lst[cmp + 1], lst[cmp]
else:
break
return lst이해가 어려웠던 insertion sort 구현
merge에 대해서는 함수를 설명하면서
heap에 대해서는 나중에 실전에 용이하도록 python docs의 내용으로
insertion에 대해서는 python 내장 sort인 tim sort에 대해 짧게 다루면서
기록해두었다.
이번 한 주 참 다사다난, 상쾌했다.
오는 내일부터도 빡공이다 !
