Ollama란?
ollama는 로컬 컴퓨터에서 대규모 언어 모델(LLM)을 실행할 수 있게 해주는 오픈 소스 소프트웨어입니다. 이 툴을 사용하면 인터넷 연결 없이도 자신의 기기에서 다양한 AI 모델(Llama, Mistral, Deepseek 등)을 다운로드하고 실행할 수 있습니다. ollama는 특히 개인 정보 보호가 중요하거나 로컬 환경에서 AI를 활용하고자 하는 사용자들에게 유용하고, Deepseek가 개인정보 이슈로 한국에서 사용이 중단되어 로컬 구현을 원하는 사용자들에게 쉽게 접근할 수 있는 수단으로 활용되고 있습니다.
Ollama 설치방법
Ollama의 공식 홈페이지(https://ollama.com/)에서 다운로드가 가능합니다. 현재 Window, Mac, Linux환경을 지원하고 있습니다. 기본적으로 소프트웨어를 다운로드해야 명령 프롬프트에서 활용할 수 있습니다.
Ollama 실행방법
저는 윈도우를 사용하고 있어, 윈도우에 맞는 실행방법으로 소개하고자 합니다.
Ollama 홈페이지의 Search Model에 원하는 모델명을 입력하거나, 첫화면에 추천하는 LLM모델을 클릭하면 다음과 같은 화면이 나타납니다.

Ollama run deepseek-r1:1.5b처럼 표기되어있는게 실제 Ollama에서 활용할 모델 명입니다(Deepseek-r1-distill-qwen-1.5B 가 아닙니다.).
저는 개인 PC의 특성상 파라미터 수가 많은 모델을 사용하지 않고, 경량화된 deepseek-r1:14b 모델을 활용했습니다.
다음의 커맨드라인(cmd 환경)을 활용하여 Ollama를 설치하고 실행할 수 있습니다.
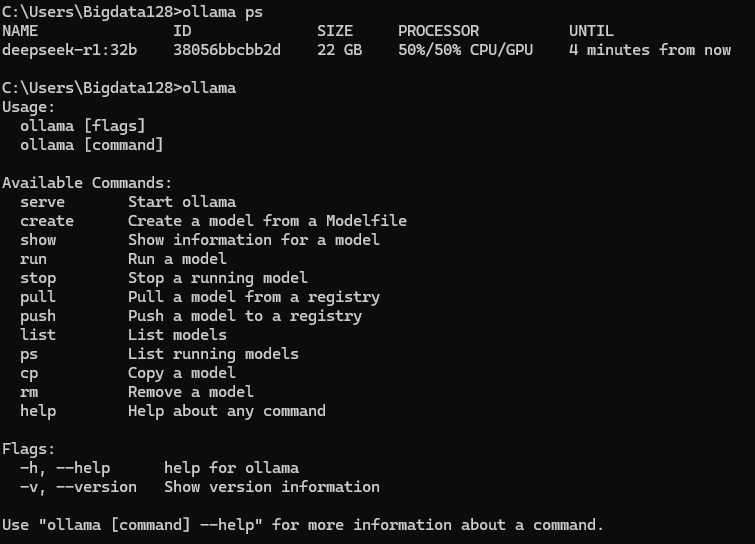
커맨드창에서 Ollama 명령어를 입력하면 다음과 같은 명령어 도움을 받을 수 있습니다.
Ollama 모델 설치
Ollama pull [model]
제가 실질적으로 활용한 코드는 Ollama pull deepseek-r1:14b 입니다.
Ollama 모델 실행
Ollama run [model]
제가 실질적으로 활용한 코드는 Ollama run deepseek-r1:14b 입니다.
Ollama 모델 삭제
Ollama rm [model]
Ollama 실행중인 모델 확인
Ollama ps
이 코드는 Ollama가 CPU/GPU를 사용중인 비율을 확인할 수 있습니다.

3080Ti 기준으로 32b의 로컬 모델도 답변 생성속도가 매우 느립니다(20~30초).
개인의 PC 성능에 맞춰 경량화 모델을 선택하면 좋을 것 같습니다.
다양한 모델을 사용해보고, 14b의 모델을 선택하였습니다.
아래는 32b의 모델로 실험한 결과로 첨부하였습니다.
모델을 실행하게 되면 다음과 같은 창을 확인할 수 있습니다.

원하시는 텍스트를 입력하고, 답변을 받으면 됩니다.
퇴장 명령어는 /bye 이지만, Ollama에서 계속 구동중이라 최종적으로 종료해주려면 다음 코드를 활용해야 합니다.
Ollama 종료
Ollama stop [model]
Ollama를 기초적으로 활용하는 방법을 알아보았습니다.
곧 API를 Python에서 구현하는 방법, Docker와 OpenwebUI를 활용하는 방법도 포스팅 하도록 하겠습니다. 읽어주셔서 감사합니다.
