선형 회귀(Linear Regression)란?
선형회귀는 머신러닝의 가장 기본적이면서도 강력한 알고리즘 중 하나입니다. 종속변수라 불리는 예측하고자 하는 값 y, 독립변수라 불리는 입력 특성인 x, 가중치(기울기) w, 편향(bias) b로 수학적 표현을 나타냅니다.
선형 회귀의 작동 원리
작동 원리는 데이터 포인트들을 가장 잘 표현하는 직선을 찾는 것이 목표이고, 실제 값과 예측 값의 차이(오차)를 최소화하는 방향으로 학습합니다.
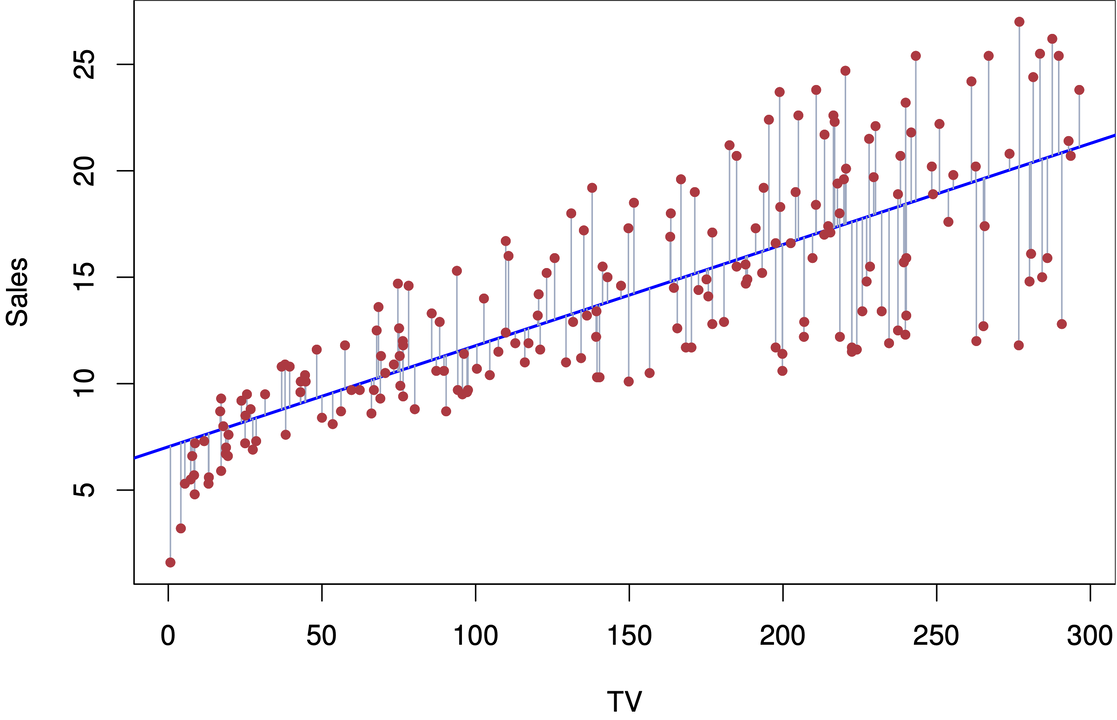
[Fig 1] 선형 회귀 예시
그림과 같이 데이터 포인트들을 가장 잘 표현하는 최적의 직선을 찾아 오차를 줄여가는 방법으로 학습합니다. 경사 하강법(Gradient Descent)를 통해 최적의 파라미터(가중치, 편향)을 찾고 학습률을 설정하여 파라미터 업데이트 속도를 조절합니다. 후에, 반복적으로 활용된 비용 함수를 최소화하는 방향으로 파라미터를 조정합니다.
from sklearn.linear_model import LinearRegression
import numpy as np
# 데이터 준비
X = np.array([[1], [2], [3], [4], [5]])
y = np.array([2, 4, 6, 8, 10])
# 모델 생성
model = LinearRegression()
# 모델 학습
model.fit(X, y)
# 예측
predictions = model.predict([[6]])
print(f"가중치(w): {model.coef_[0]}")
print(f"편향(b): {model.intercept_}")
print(f"예측값: {predictions[0]}")단순한 코드로 구현하는 방식은 이렇습니다. 추후 실제 데이터세트를 가지고 활용하는 코드를 게시하겠습니다.
해석은 다음 예시와 같이 할 수 있습니다.
(예시) 공부시간과 시험점수 관계
가중치(w,coef): 5
편향(b,y) : 40
예측값: 90
공부시간이 1시간 증가할때마다 점수가 5점씩 증가합니다. "공부를 1시간 더 하면 평균 5점이 상승합니다."
공부를 전혀 하지 않았을때의 기본 점수가 40점입니다. "아무리 공부를 안해도 기본 점수는 40점"
10시간 공부하게 되면 예상 점수는 90점입니다. "(5*10)+40=90"
이와 같이 해석이 가능합니다.
경사 하강법(Gradient Descent)이란?
- θ: 모델의 파라미터
- α: 학습률(learning rate)
- ∇J(θ): 비용 함수의 기울기(gradient)
3가지의 변수로 다음과 같은 수식으로 활용합니다.
기본 개념은 비용 함수의 최솟값을 찾는 것이 목표입니다. 함수의 기울기를 계산하고 기울기가 가리키는 반대 방향으로 이동합니다. 이 과정을 지속적으로 반복하여 비용 함수의 최솟값에 도달할 수 있도록 합니다.
학습률(α)가 너무 크게 되면 최솟값을 지나쳐버리게 되는 오버슈팅 문제가 생깁니다. 반대로, 학습률이 너무 낮게 되면 학습이 매우 느려저 적절한 학습률 설정이 매우 중요합니다.
경사 하강법의 종류
-
배치 경사 하강법(Batch Gradient Descent)
전체 데이터세트를 활용하여 기울기를 계산하는 방법입니다. 정확하지만 계산 비용이 크다는 단점이 있습니다. -
확률적 경사 하강법(Stochastic Gradient Descent, SGD)
데이터 포인트를 하나씩 사용합니다. 전체 데이터세트를 활용하는 배치 경사하강법보다는 빠르지만, 노이즈가 많이 생긴다는 단점이 있습니다. -
미니 배치 경사 하강법(Mini-batch Gradient Desent)
데이터의 일부분을 사용합니다. 위의 2가지 방식의 장점을 결합한 방법입니다.
활용할 수 있는 코드의 예시는 다음과 같습니다.
def gradient_descent(x, y, learning_rate=0.01, n_iterations=1000):
# 초기 파라미터
w = 0
b = 0
for i in range(n_iterations):
# 예측값
y_pred = w * x + b
# 기울기 계산
dw = -(2/len(x)) * sum(x * (y - y_pred))
db = -(2/len(x)) * sum(y - y_pred)
# 파라미터 업데이트
w = w - learning_rate * dw
b = b - learning_rate * db
return w, b경사하강법은 딥러닝을 포함한 대부분의 머신러닝 알고리즘의 학습 과정에서 핵심적인 역할을 하는 중요한 요소이기에, 추후에 다른 챕터로 자세히 다루겠습니다.
다중 선형 회귀 분석
위에 나타나는 선형 회귀 분석은 단일(단순) 회귀 분석이라 표현합니다.
다중 선형 회귀 분석은 여러개의 독립변수를 활용합니다. 아래의 수식과 같이 표현하고, 더 복잡한 관계도 모델링이 가능합니다.
선형 회귀분석의 장단점
- 선형 회귀분석의 장점
- 변수 간의 관계를 직관적으로 이해할 수 있고, 각 독립변수의 영향력을 계수(coefficient)를 통해 해석이 용이합니다.
- 또한, 수학적으로 잘 정립된 알고리즘으로 계산 속도가 빠른 분석기법이며 적은 컴퓨팅 리소스로도 실행 가능하고 구현과 계산의 효율성이 강합니다.
- 대부분의 머신러닝 기법에서 모델의 고질적인 문제인 과적합(overfitting)위험이 상대적으로 낮은 모델입니다. 새로운 데이터에 대한 일반화 성능이 좋고, 적은 양의 데이터로도 어느정도 일반적인 학습이 가능해 나쁘지 않는 성능을 보입니다.
- 선형 회귀분석의 단점
- 가장 중요한 문제인 비선형 관계를 모델링하지 못한다는 단점이 있습니다. 어느정도 데이터를 다루신 분들이라면 알고 계시겠지만, 현실세계에 선형 모델로 설명할 수 있는 모델이 많지 않습니다.
- 극단값에 크게 영향을 받는 모델입니다. 극단값이라고 한다면, 1~100사이의 데이터에 음수값이나 100을 훌쩍 뛰어넘는 값들을 의미합니다. 다른 모델도 마찬가지지만, 이상치 처리가 매우 필수적이고 강건성(Robustness)를 보완할 수 있는 다른 방법과 같이 활용해야 합니다.
- 다중공선성 문제가 있습니다. 다중 공선성문제는 회귀분석에서 나타나는 문제인데, 독립변수들 간 강한 상관관계가 존재하는 문제를 말합니다. 예를들어, 부동산 가격 예측 모델을 생성하는 과정에서 주택면적이 클수록 방 개수와 화장실 개수도 비례하여 증가하는 모습이 일반적입니다. 이에 따라, 변수가 모두 서로서로에게 영향을 받는 모양새라 각 변수의 실제 영향력을 구분하기 어려운 상태가 될 수 있습니다.
여기까지 기초 머신러닝인 선형 회귀분석에 대하여 알아봤습니다.
지속적으로 머신러닝 기법들을 포스팅하겠습니다. 읽어주셔서 감사합니다.
