
📍Process
: 실행 상태에 있는 program
- job이란 용어와 혼용 (사용자 입장의 용어로 느껴지는)
- program ➜ 실행 ➜ process
- 사용자가 program을 실행시켜라 하고 명령을 주면 process가 됨 (= 수행상태가 됨)
- program 내용이 memory에 올라와서 명령어가 수행되기 시작하는 상태
- program
- 수동적 객체
- 하나의 file을 생각하면 됨
- process
- OS의 관심대상
1. program 실행 중 필요한 내용
- memory에 해당 program이 load되어야 함.
- 실행중에 운영되어야 할 memory에 있는 공간은 H/W 적으로 기억장치가 있음
- 프로그램 명령어들이 나열된 게 메모리에 올라옴. ➜ 하나씩 가져다가 해석해서 CPU가 수행하고 다음 것을 가져옴. ➜ 수행된 위치를 기억하는 Register(PC)가 있음.
- PC (Program Counter): 현재 수행되는 명령어의 주소를 가리킴.
- 수행 중에 CPU가 빈번하게 사용되는 가장 빠른 기억소자 = Register
- PC, Register = CPU가 계속 읽음
1-2. memory
- memory = text section + 다른 memory
- data를 memory에 표현하는 data section 특징 1) static 영역 (정적 memory): 프로그램 시작될 때 잡히고 끝날 때 종료 (끝날때까지 변하지 않는 상태) ex. C에서의 global 변수 (해당파일 전 영역에서 접근가능한 file), static local 2) dynamic 영역 (동적 memory): 실행 시간 중에 공간이 잡혔다가 실행 시간 중에 필요에 의해서 사라질 수 있는 ① stack dynamic : local 변수, return address ② heap dynamic : 나타나고 사라지는 ex. malloc(C), new(C++) ➠ 영역이 static, heap영역이 있다는 말. cf. static은 Lifetime(memory 공간에 잡혀있는 기간)을 의미 static: 실행시간 이전에 결정되어서 실행 중 변하지 않는 속성 dynamic: 실행시간에 결정되는 속성
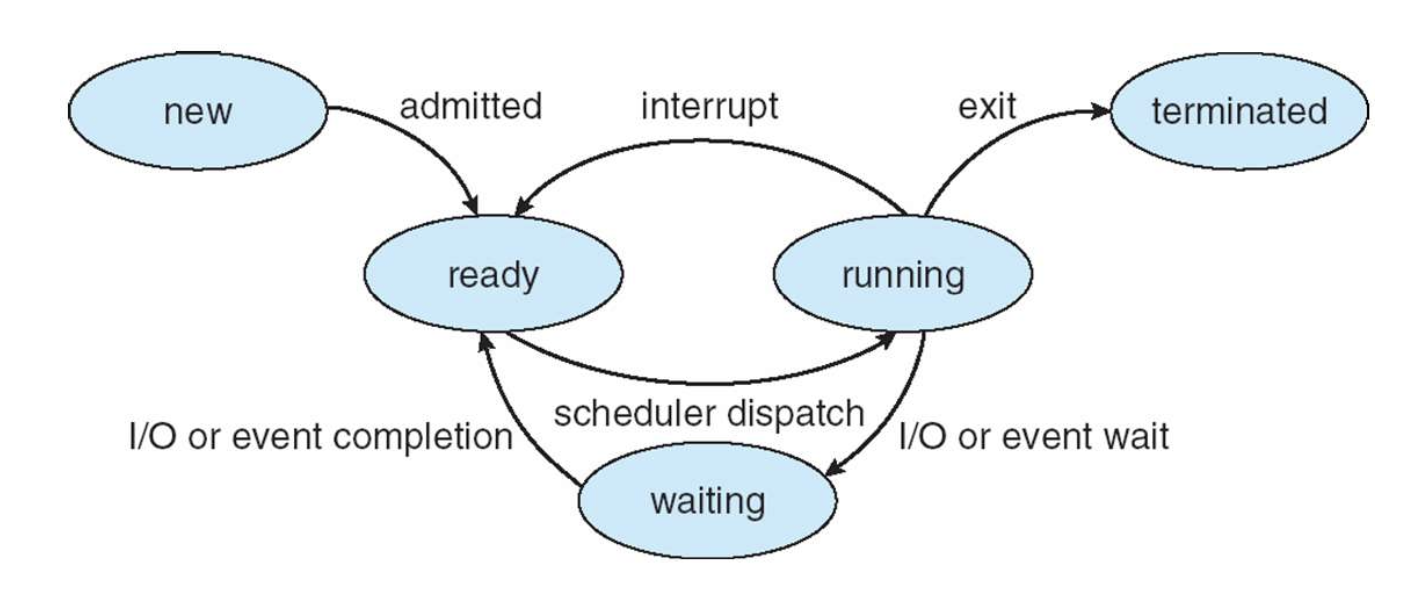
📍 Process State
1. Process State
- new: 아직 프로그램이 실행되지 않는 대기상태 (process가 생성되는 중)
- ready: 프로그램을 실행시켜도 될 상황 (CPU만 주면 즉각 실행할 수 있는 상태, 아직은 실행이 되지 X) (CPU 리소스 할당 받는 것을 기다리고 있는 상황)
- running: CPU가 실행하고 있는 상태 (running 상태에 있는 program은 한 개)
- waiting: process가 일부 이벤트 발생을 기다리는 중입니다 (I/O를 기다리는 것일수도)
- running에 있다가 I/O를 만남
- I/O를 만나면 그 process는 I/O가 끝날 때까지 기다리는 상태, I/O는 I/O process가 열심히 수행.
- running 상태에서 process가 빠져나가고 CPU는 ready상태에 있는 다른 process를 불러서 running 상태로 만듦.
- terminated: Lifetime 끝
+) interrupt: 정책적인 문제, 상황 등으로 인해 내가 CPU를 놓게 되는 상황
➠ 급한 일, 공평한 수행을 위해 (ex. time sharing)
2. Diagram
3. scheduling
: 어떤 resource를 운영하는 대상이 여러 개 일때, 어느 대상에게 순서를 줄 것인가를 결정하는 것. (경쟁이 있을 때)
- 대상의 waiting 장소 : queue
- job queue = job scheduling
- ready queue = CPU scheduling
- device queue : I/O를 만나서 어떤 device를 이용하러 갔는데, 바쁜 상태면 queue에 들어가서 기다림.
📍 PCB (Process Control Block)
: process로 존재할 때 OS가 관리하는 process에 관한 정보 (ex. 주민번호)
- process가 되면 (program 실행이 되면) PCB가 만들어지고 종료되면 사라짐
- process에 관한 일체의 정보가 담겨져 있는 control block
- 들어있는 내용 1) process 상태 (ready, waiting …) 2) Program Counter (현재 실행중인 명령어의 위치를 기억하는 register) 3) CPU register : 현재 순간적 상태의 register 각각의 내용이 있어야 함. 4) CPU scheduling information 5) Memory-management 6) Accounting information: 계정정보에 따라 종속적인 것 (얼마나 사용하였는지 등) 7) I/O 상태: I/O 중일수도 있고, open된 파일이 무엇이 있는지, list는 무엇인지 등 +) thread에 대한 정보도 저장이 됨.
📍 CPU Switch From Process to Process
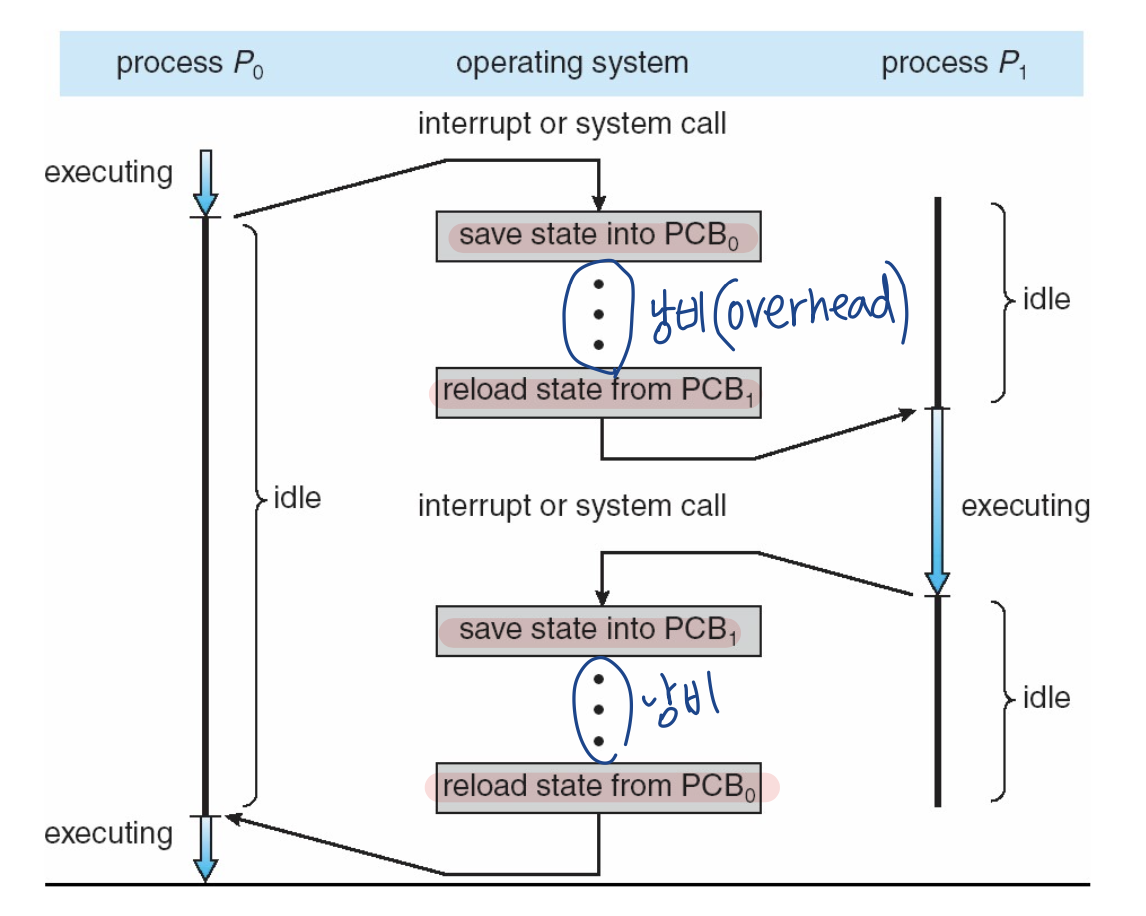
- 개념적인 그림!
- process0, process1 실행 중에 interrupt를 만남.
- 0번 저장, 1번 회복 ➜ 1번 저장, 0번 회복
- 공평하게 수행하기 위해서, 혹은 급해서 왔다갔다 = CPU switching = context switching (수행하는 것을 process 간에 이동하는 것)
- overhead: 추가부담
- context switching이 자주 일어나면, CPU가 필요한 것을 수행하지 않고 절차적 수행을 하게 됨
❗️ Context switching vs Time sharing
-
context switching
- CPU를 한 process에서 다른 process로 넘겨주기 위해서 PCB를 저장하고, 다시 load를 해주는 과정. (CPU가 사용자 process에서 다른 process로 넘어가는 과정)
- overhead가 많이 발생한다.
- overhead: program을 수행할 때 전혀 상관없는 system → overhead를 줄이면 성능이 좋아짐.
-
time sharing: time sharing을 하기 위해서 context switching이 필요하게 되는 것
✏️ 용어정리
1. Thread
: 수행의 줄기 (흐름)
- single thread : 한 줄기 수행
- multi thread : 여러 줄기, 동시에 수행 (CPU하나가 바삐 움직여서 동시에 수행되는 것처럼 보이게 하는 것)
- 하나의 process에서 PC가 여러 개 생기는 것
❗️process와 thread의 차이
: process는 program을 메모리 적재시키는 것
thread는 한 process에서 나뉘는 수행 흐름
❗️ multi-process, multi-thread 차이
: multi-process: process여러개를 만들어 낼 수 있는 것
multi-thread는 하나의 process에서 수행 줄기가 여러 개로 나뉘는 것
2. Process Scheduling
: 어떤 서비스 할 대상을 고르는데, 어느 process를 골라서 어떤 서비스를 지원해줄지 고민하는 것
- 배경: multi programming의 목적
- multi programming이 됐을 때 scheduling 할 필요가 있는 것은 동시로 job이 많이 들어오게 만드는 이유 = 하나의 작업을 수행하다가 I/O를 만났을 때 CPU가 할 일이 없으니 다른 process 작업을 실행하게 됨.
- CPU utilization (활용도) 증가
- b/c. scheduling이 없으면 종료될때까지 얘만 붙잡고 있어야 하는데, scheduling을 하면 CPU가 놀 시간이 없음.
- queue
- ready queue
- job queue
- device queue :waitng상태로 가면 있어야 하는
3. Time Sharing
: 짧은 주기로 번갈아 수행
- 목적: 여러 user에게 공평한 서비스를 주기 위해
- 공평함 유지하기 좋음.
❗️ time sharing을 하면 turn around time이 늘어남.
b/c. context switching으로 인한 overhead가 발생하기 때문
❗️그럼에도 불구하도 time sharing을 쓰는 이유: 여러 user에게 공평하게 해 줄 수 있기 때문
4. Context switching
- CPU가 다른 프로세스로 전환 ➜ 시스템이 이전 프로세스의 상태를 저장, Context switching을 통해 새 process에 대해 저장된 상태를 load해야함.
- state save: 현재 상태 저장
- state restore : 다른 거 불러오기
- pure overhead: user에게 의미있는 실행시간이 아님.
- overhead: context 전환 시간
- 개선하면 전체적 성능이 개선됨.
📍 Scheduling queue
- job queue : 프로그램을 시작시키는 것
- ready queue :
- device queue : I/O queue, device 속성에 따라 달라짐.
1. 구현
: PCB의 Linked list로 구현
- 원소를 읽는 쪽: head → front
- 꼬리 : tail → rear (여기로 원소를 넣음)
- 원소를 삭제하더라도 노드끼리 서로 연결이 잘 되어 있어야 함.
📍Process scheduling
: ready queue에서 선택되어 CPU를 할당받고, 다음 상황에 의해 CPU를 놓는다
- 다음상황 1) I/O 요청 (CPU는 다른 것을 함) ➠waiting 상태 2) subprocess를 생성하고 그것이 종료될때까지 wait하는 상태
-
interrupt 방식으로 이루어짐
➠waiting 상태
3) time sharing (공평한 수행) 및 interrupt (나보다 먼저 해야 될 것이 있을 경우)
➠ ready로 전환
4) process 종료 (종료는 반드시 running 상태에서 종료하게 됨)
-
📍Scheduler
1. Long term scheduler (= job scheduler)
- ready queue로 전환할 process 선택
- OS가 job scheduler로부터 하는 일은?
- degree og multi programming을 적절히 조정(조절)
- 드물게 호출됨 → 느림
2. short term scheduler
- 다음에 실행할 process를 선택하고 CPU 할당
- 일부 작업을 잠시 memory에서 제거 → degree of milti programming을 완화m
- Sometimes the only scheduler in a system
- 자주 호출됨 → 빠름
3. midium term scheduler
- 요청하면 다 받고 ready queue(memory)에 넣음. → 많아지면 빼서 disk에 저장
- 다중 프로그래밍의 정도를 줄여야 할 경우 사용
- swapping
- 일부 작업을 잠시 memory에서 제거 → degree of multi programming을 완화
- memory → disk로 이동해버리는
4. 용어
✔︎ I/O-bound process & CPU-bound process
-
어떤 프로그램 성능이 CPU로 일어나느냐 I/O로 일어나느냐
-
I/O bound process: I/O가 매우 빈번히 발생하는 progrm (I/O 연산이 자주 일어나는)
- CPU burst가 자주 일어남.
- 순환이 빨리 돌아감
- process입장에서는 이 친구들이 많아야 함.
- CPU burst가 자주 일어남.
-
CPU bound process: CPU연산이 길게 이어지는 program
- CPU burst가 더 작게 일어남.
- 한 번 잡으면 끝날 때까지 잘 끝나지 않음.
- CPU burst가 더 작게 일어남.
-
둘 다 적절히 사용해야함
- CPU 사용 多: I/O 활용도 저하
- I/O 사용 多: CPU 활용도 저하
-
어떤 게 CPU bound인지 알기 어려움 (→ 실행전에 알기 어려움)
-
일부 system에서는 long term scheduler가 아예 없거나 최소한의 기능만 유지 (= 작업이 수행하라고 들어오면 바로 수행하게 됨)
- 이것을 할 수 있는 배경(근거)
- time sharing system으로 동작하기 때문에 모두 실행 ➠ 전체적으로 느려지지만 실행 가능
- degree of multi programming이 지나치게 높아지는 현상 발생
- ① physical limitation에 의존하자
- ② 사용자 스스로 조정하자 (ex. 한시간에 10명밖에 못하는 서비스가 있다면 가장 긴급한 사람에게 줌 → 이 사람은 느려도 버틴다)
- 이것을 할 수 있는 배경(근거)
📍 Process 관련 operation (OS에서 지원하는 연산)
1. process creation
: process 실행 명령
✅ 수행형태 (2가지 고려)
- parent, child 동시에 수행을 계속
- parent가 child를 생성함 (부모-자식 관계 설정됨)
- parent가 child 중 일부 || 전부가 수행을 종료하기를 기다림 =

✅ process 생성 시 address space
- 형식
- child가 parent의 data를 그대로 갖는 형식 → 두 갈래로 수행이 갈라지는 느낌
- child가 새로운 program으로 load되는 형식 → 다른 것을 실행시키는, 독립된
2. process termination
: program 종료 명령
-
exit() - system call
-
Terminate Process()
-
종료되면 OS는 process가 사용하던 resource (file, register 등)를 모두 반납. → PCB가 최종적으로 사라짐
-
상황
- parent가 child를 강제적으로 종료
- resource 사용초과
- 작업완료
- parent 종료 시 OS는 자동으로 child 종료
- parent가 child를 강제적으로 종료
unix
- ps -el : 현재 수행중인 process 목록 나열
- fork() 등
