정규화
정규화란, 관계형 데이터베이스에서 데이터 중복을 최소화하고 데이터 이상 현상을 제거하기 위해 테이블을 나누어 관계를 재구성하는 것을 의미한다
제1 정규화
하나의 컬럼에는 하나의 데이터만
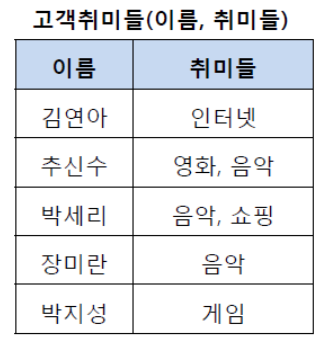
위와 같은 테이블이 있을 때 취미 컬럼에 두 가지 이상의 데이터가 들어간다
- 이런 경우에 데이터 조회 시에 성능 문제가 발생 할 수 있다
- 또한 데이터 수정 시 구현이 더 힘들 수 있다
제2 정규화
테이블과 관련 없는 내용은 분리하자
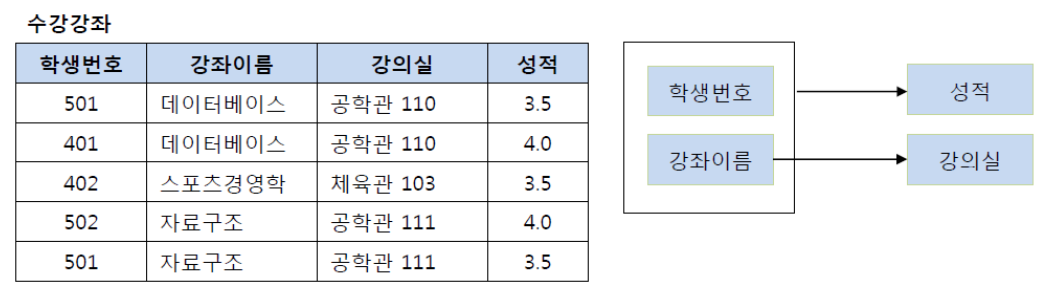
제 2 정규화는 하나의 테이블에는 관련된 정보만 저장하는 것을 의미한다
- 더 엄밀하게는 완전 함수 종속을 만족하는 것을 의미한다
- 완전 함수 종속이란 기본키의 부분집합이 결정자가 되지 않도록 하는 것이다
- 위의 테이블에서 기본키는 학생 번호와 강좌 이름이다
- 그런데 강좌이름에 의해 강의실이 결정되고 있다 즉, 강좌이름은 결정자이다
- 이런 경우에 데이터베이스에 해당하는 강의실이 변경되는 경우 모든 데이터베이스를 수강하는 row를 찾아 수정해주어야 한다
- 따라서 강좌이름 -> 강의실 테이블을 분리하는 것이 제2 정규화를 만족하는 것이다
제3 정규화
잔바리를 나누자
제 3 정규화는 이행적 종속을 없애도록 테이블을 분리하는 것이다
- 앞서 제2 정규형을 만족하는 상태라면 완전 함수 종속을 만족하는 상태이다
- 이때 기본키가 아닌 다른 컬럼에 의해 결정되는 컬럼이 존재 할 수 있다
- 이는 기본키가 아닌 컬럼에 의해 결정되기 때문에 완전 함수 종속은 맞다 하지만 앞선 예제와 비슷하게 데이터를 수정하려면 종속되는 컬럼에 해당되는 모든 값을 수정해주어야 한다
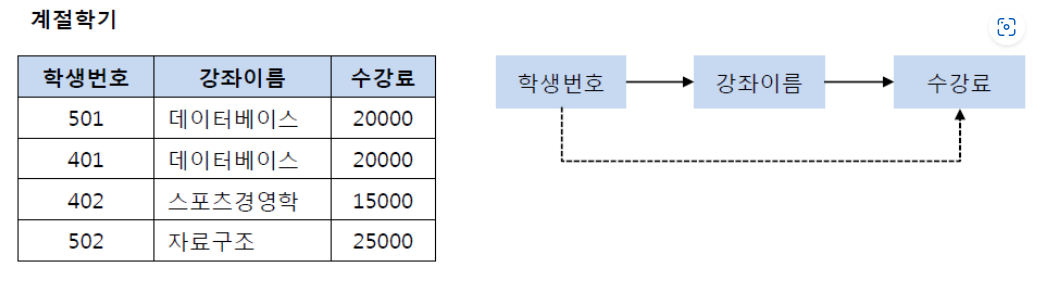
- 위의 테이블에서 학생번호가 기본키이며 강좌이름과 수강료를 결정한다
- 그런데 강좌이름은 기본키가 아닌데 수강료를 결정한다
- 그렇기 때문에 데이터베이스 강좌의 비용이 변경되면 수정을 많이 해야되는 문제가 생길 수 있다
- 따라서 강좌이름 -> 수강료 테이블을 분리한다
정규화 결론
- 무조건 정규화를 만족하도록 하는 것이 무조건 좋은 것은 아니다
- 데이터를 조회 할 때 추가적인 조인 연산이 필요해지기 때문이다
- 그러나 보통 제3 정규화 까지는 만족하도록 하는 것이 좋다
