레코드
- 데이터베이스에서 레코드란 일련의 필드로 이루어진 데이터 조각이다
- 레코드가 모여 파일을 구성하게 되고
- 파일이 모여 데이터베이스가 된다
- 데이터베이슨는 데이터를 읽을 때 물리적인 최소 단위인 Disk Block 단위로 읽기 때문에 Block과 레코드의 관계를 정의하기 위해 하나의 Block에 들어 갈 수 있는 레코드의 수를 Blocking Factor 라고 정의한다
고정 길이 레코드
- 각 파일에 저장되는 레코드의 길이가 동일한 경우 단순히 순서대로 저장 할 수 있다
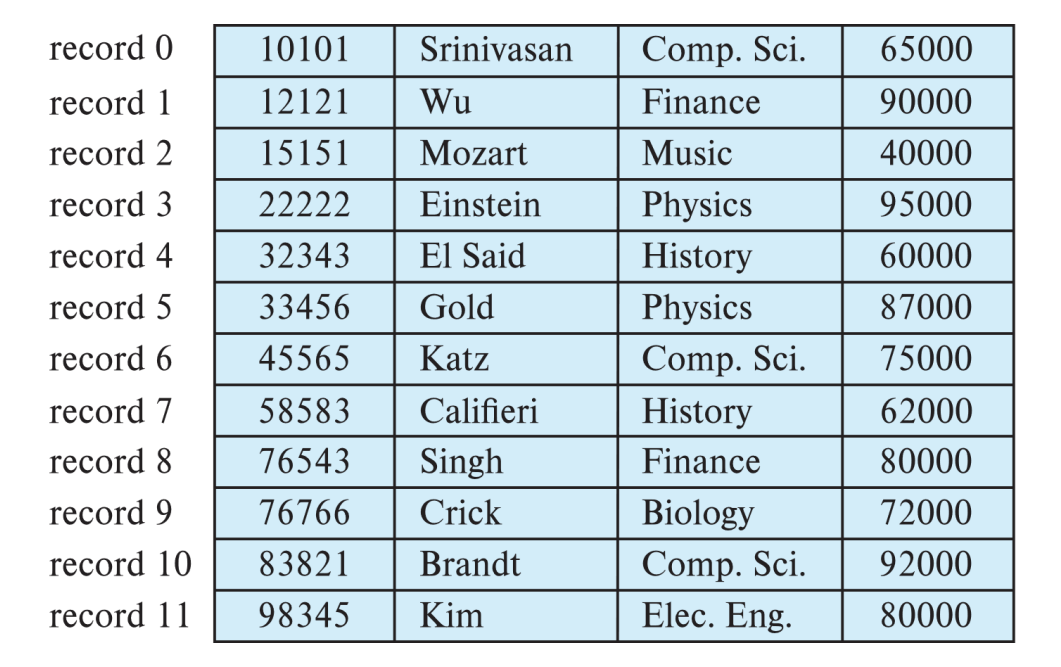
- 이런 경우 단순히 위의 그림과 같이 파일에 레코드들을 저장할 수 있다
- 데이터베이스 입장에서 몇번째 레코드인지 만 알면 주소값을 쉽게 알아낼 수 있을 것이다
- 이 때 데이터가 삭제 된다면 해당 칸을 비우고 아래의 데이터를 모두 한 칸 씩 땡길 수 있다
- 이게 너무 비효율적이라 면 마지막의 데이터만 빈칸으로 옮길 수 있다
- 혹은 데이터를 이동하지 않도 링크드 리스트를 통해 빈칸을 가르키도록 하여 빈 곳을 파악하도록 하게 할 수 있다
가변 길이 레코드
- 하지만, 데이터베이스에서 우리는 VARCHAR와 같은 길이가 변할 수 있는 값들을 사용한다.
- 또한 한 파일에 여러 종류의 레코드가 저장되는 경우도 있다

- 따라서 위의 그림과 같이 데이터를 저장한다
- 데이터의 가장 앞 부분에는 필드 값들이 온다
- 가변 길이 데이터인 경우에는 offset, length 값이 필드 값 대신 저장된다
- 21번지부터 길이가 5인 데이터, 26번지 부터 길이가 10인 데이터 36번지 부터 길이가 10인데이터가 있다
- Null bitmap은 Null을 가지는 레코드의 위치를 알려준다
- 그 뒤로는 가변 길이 필드의 실제 값들이 위치하게 된다
Slotted Page Structure
- 가변 길이 레코드를 사용하는 경우 데이터베이스의 입장에서 데이터를 찾는 것이 어렵다.
- 단순히 몇번째 데이터인지 안다고 해도 주소를 알 수 없다
- 그렇다면 가변 길이 레코드인 경우 어떻게 레코드를 조회할 까?
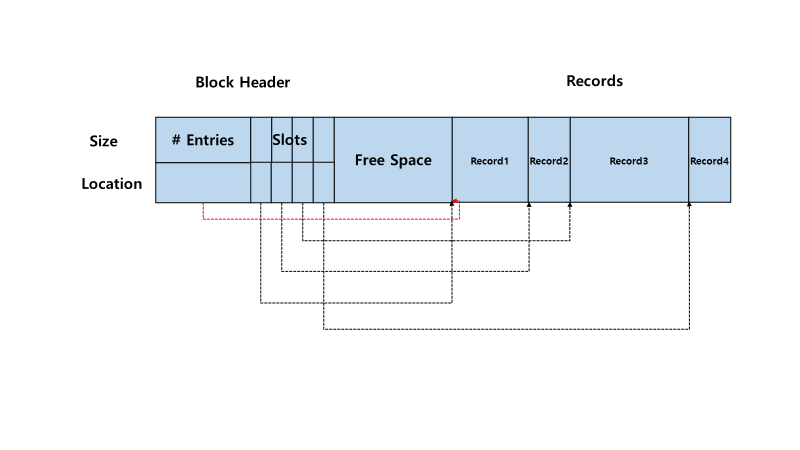
- 위의 그림 처럼 저장된다.
- 가장 먼저 Block Header에 다음과 같은 정보가 저장된다
- 총 레코드 수
- free space가 끝나는 지점
- 각 레코드의 시작 위치, 크기 (slot)
- 이를 통해서 새로운 데이터가 들어오면 Free Space에 할당한다
- 또 데이터가 삭제되면 빈 공간을 나머지 데이터들이 채우도록 이동한다
- 이 때 slot의 값은 삭제하지 않고 유지해야 한다
- 외부의 포인터 (인덱스)에 의해 해당 값이 사용 될 수 있기 때문이다
- 또한 외부의 포인터 (인덱스)는 직접 데이터를 가르키는 것이 아닌 Slot을 통해 가르킨다고 한다
- Blocking factor는 (블록 크기 - 블록 헤더 크기) / (레코드 크기 + slot 크기) 로 결정된다고 볼 수 있다
크기가 큰 데이터
- Block Size 보다 크기가 큰 데이터의 경우에는 파일 시스템에 저장 할 수 있다
- 또는 Block 단위로 나누어서 저장하는 방식도 있다
