파일 구조
- 레코드가 파일에 저장될 때 파일 구조에 따라 다양한 방식으로 저장된다
Heap
- 레코드를 아무 빈 공간에 채워 넣는 방식이다
- 한 번 저장된 레코드는 이동 시키지 않는다
- 빈 메모리 공간을 찾기 위해 Free-space map을 사용한다
- Free-space map은 block 마다 하나의 엔트리를 사용하여 block의 빈 공간의 비율을 나타낸다
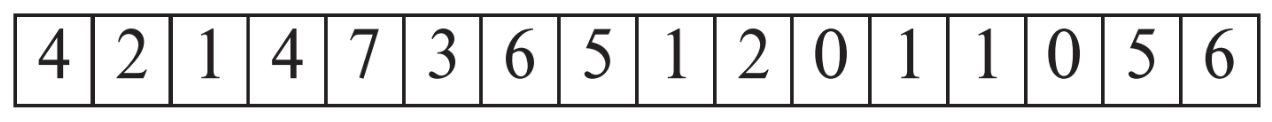
- 위의 배열은 하나의 block 마다 3비트를 사용하여 표현한 것으로 첫 번째 block은 4/8의 공간이 비어있음을 알 수 있다
- 이를 메모리 공간을 더 효율적으로 사용하기 위해 n개의 block 마다 빈 공간의 비율을 나타내도록 할 수 도 있다
- 매번 데이터의 삽입/삭제 마다 free-space map을 수정하는 것은 비효율적이고 free-space map에 약간의 오차는 허용되기 때문에 주기적으로 update를 하는 방식을 사용한다
Sequential
- Sequential 파일 구조는 레코드 순서가 필요한 경우 사용한다
- search-key에 의해 레코드를 순서대로 저장한다
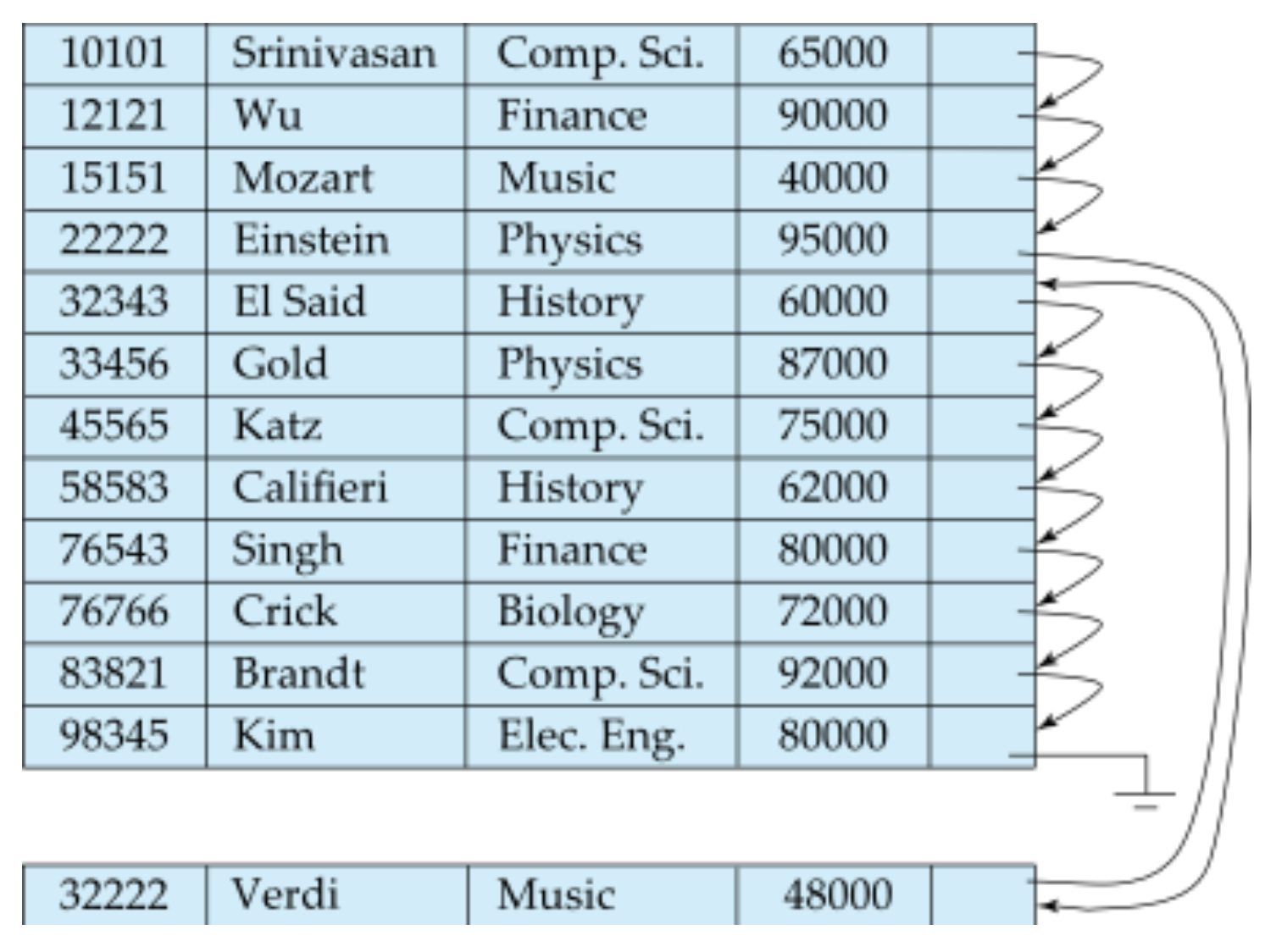
- 그림과 같이 새로운 데이터가 들어오면 search-key를 통해 들어갈 자리를 탐색한다
- 해당 block에 자리가 있으면 저장을 하고 pointer를 수정하면 된다
- 자리가 없으면 다른 overflow block에 저장하고 pointer를 수정해야 하기 때문에 추가적인 I/O를 사용하게 된다
- 시간이 지날 수 록 overflow block이 많아지기 때문에 주기적으로 파일을 재구성하여 순서를 정리한다
Multitable Clustering
- 이 방식은 서로 다른 테이블에 있는 레코드 여도 서로 연관된 레코드라면 하나의 블록에 저장하도록 하여 I/O를 줄이는 방식이다
- JOIN과 같은 연산에 유리하다는 장점이 있다
- 하지만 단일 테이블에 대해서 조회하는 경우에 비효율적일 수 있다
- 레코드의 종류를 구분하기 위해 같은 레코드인 경우 pointer로 연결하여 구분 할 수 있다
Data Dictionary Storage
- 이는 Meta Data를 저장하는 공간이다
- relation 이름
- attribute의 이름, 길이 , type
- view 이름, definition 정보
- 통계 데이터
- 유저 정보
- 물리 저장 정보 (파일 구조 등등)
- 인덱스 정보
- 메타 데이터는 DBMS에 의해 매우 자주 사용되는 데이터이다
- 따라서 메타데이터 자체를 RDB에 저장해두고 SQL을 이용하여 조회하여 사용한다
- 이 때 성능을 위해 아예 메모리에 올려두고 사용하는 방법도 있다
