
회사에서 사용하고 있는 기술 스택 중 하나인 redis에 대해 알아보자
딱 현업 1개월차 눈높이기 때문에 고수들은 패스해도 좋다.
Redis 왜 쓰는건데?
Redis는 굵직 굵직한 기업들은 모두 사용중이거나 한번쯤은 도입을 생각해 봤을 정도로 너무나도 유명한 인메모리 데이터베이스다.
쿠팡은 레디스의 메모리 관리를 안해서 이슈가 났었다
대용량 트래픽을 관리해야 하는 서비스들의 시점으로 넘어가면서 클라이언트 로직, 백엔드 로직의 성능 최적화로는 성능 향상에 한계가 있다. 자연스럽게 트래픽을 분산 시켜야 된다는 이슈가 생기고(만약 사용자가 사이트에 접속하여 데이터 요청을 하면 서버로부터 응답을 받고 거기에 간단한 인터렉션을 하게 된다면 요청 응답에 의해 4번의 트렌잭션이 일어난다. 만약 사용자가 10만명이라면? 10만 x 4 = 데이터베이스에서 40만번의 트랜잭션이 일어난다) => 간단한 잡큐나 키벨류 형태의 트랜잭션을 인메모리 할당으로 부하를 분산시키자! => CPU 인메모리 데이터를 부분적으로 활용해보자~ 해서 나온것이 레디스! 외에도 여러 이유가 있겠지만 내가 느끼는 가장 큰 존재 이유라고 생각된다.
Redis 특징
레디스는 자바스크립트와 동일하게 싱글 스레드의 형태로 작동한다. 즉 한번에 하나의 테스크씩 수행하는데 레디스에서는 단순한 get/set일 경우 초당 10만 TPS이상 처리가 가능하다고 설명한다. 인메모리에 할당된 저장소에 직접 저장을 하는것이기 때문에 정말 빠른 퍼포먼스 성능을 가진다.
하지만 싱글 스레드 특성상 테스크를 처리하는 과정에서 맨 첫 큐의 테스크를 처리하는 시간이 1초가 걸린다면 첫 큐를 처리하는 동안 나머지 큐들은 대기를 하기 때문에 타임아웃이 걸려있을 경우 오류가 나기 때문에 주의하여 사용해야 한다.
레디스와 가장 많이 비교되는 오픈소스 데이터 저장소는 Memcached(맴캐시드)인데 둘 다 비슷한 기능을 하고 사용성이 쉽지만 맴캐시드는 멀티스레드를 지원하기 때문에 더욱 스케일업을 할 수 있는 장점이 있지만 한정된 데이터타입 구조를 지원하기 때문에 확장성 측면에서 불리하다. 하지만 멀티스레드의 장점을 이용하는 목적에는 유리한 것이 사실이다.(요즘 내가 느끼는 부분은 인프라와 아키텍쳐를 구성할때 확장성은 정말 중요하기 때문에 맴캐시드 도입은 선택적으로 하거나, redis config관리를 통해 맴캐시드를 대체 할 수 있다고 생각함)
Redis 작동방식
레디스는 키-벨류 형태로 저장하고 GET/SET 명령을 통해 데이터를 가져올 수 있다. 데이터가 인메모리에 존재하기 때문에 read와 write가 정말 빠르다. 그리고 레디는 다양한 형태의 데이터 타입을 지원하다고 했는데 string, set, sorted set, hashes, list 형식의 구조도 지원하기 때문에 목적에 맞게 사용하면 된다. 저장된 데이터의 대한 연산이나 추가 작업도 가능하기 때문에 가공하기 정말 쉽다.
Redis 메모리
인메모리 데이터베이스이기 때문에 데이터 용량은 물리적인 메모리 크기를 넘어 갈 수 없다. 레디스를 운용시 메모리 관리가 정말 중요한데 레디스 메모리는 최소 크기를 선정하고 작게 나누어 여러 redis를 운용하는 방법이 효율적이다. 메모리 max 설정을 해놔도 실제로는 오버하여 사용하고 있는 경우의 사례를 소개 해 주었는데, 레디스 메모리를 2GB를 사용중이라고 나오지만 실제론 11GB를 사용하고 있었다는 내용이였다. 이 현상은 메모리파편화 현상 때문에 일어난다.
메모리 파편화
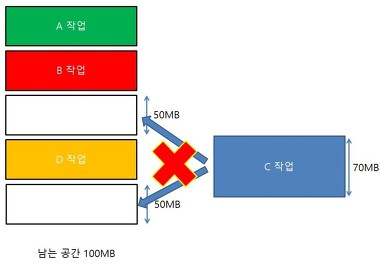
실제로 메모리에 남은 공간이 있지만 데이터를 저장하는 구조 특성상 70mb의 메모리를 할당 할 수 없게 되는 특성이다. 그렇기에 큰 메모리를 사용하는 하나보다는 적은 메모리를 사용하는 여러개가 안전하다.
메모리가 부족할 때?
기본적으로 메모리는 돈이다. 좀 더 많은 메모리 장비로 업그레이드를 해야하는데 메모리를 업그레이드 하는 시점은 75%정도 가용중일 시점. 메모리를 빡빡하게 쓰고 있는 중 업그레이드를 하면 문제가 생길 수도 있음. 아니면 데이터를 줄이는 방법인데 전자의 자료구조들은 메모리를 많이 사용하기 때문에 Hash -> HashTable 식의 구조나 Sorted Set -> Skiplist, Set -> HashTable 을 사용하여 줄일 수 있다.
Ziplist 사용 인메모리 특성상 일정량 이하의 데이터는 알고리즘 선형 탐색보다 그냥 전체적으로 탐색하는 경우가 더 빠르다. 일정량 이하 데이터 탐색에 관한 설정이 있음.
