
출처: DSBA 연구실 유튜브 와 DSBA 연구실 강의자료 를 참고하면서 스터디를 진행하였습니다.
주제: Anomaly Detection: Overview
1. Machine Learning
- 명확한 Task
T와 그 Task에 대해서 측정할 수 있는P가 있을 때, 충분한 데이터E를 제공해주면 특정 Task에 대해서 성능이 점점 향상되는 프로그램을 의미함. (Mitchell, 1997)
- 지도학습과 비지도학습으로 나누어지고, 종속변수의 유무에 따라 나뉨.
1.1. Unsupervised Learning
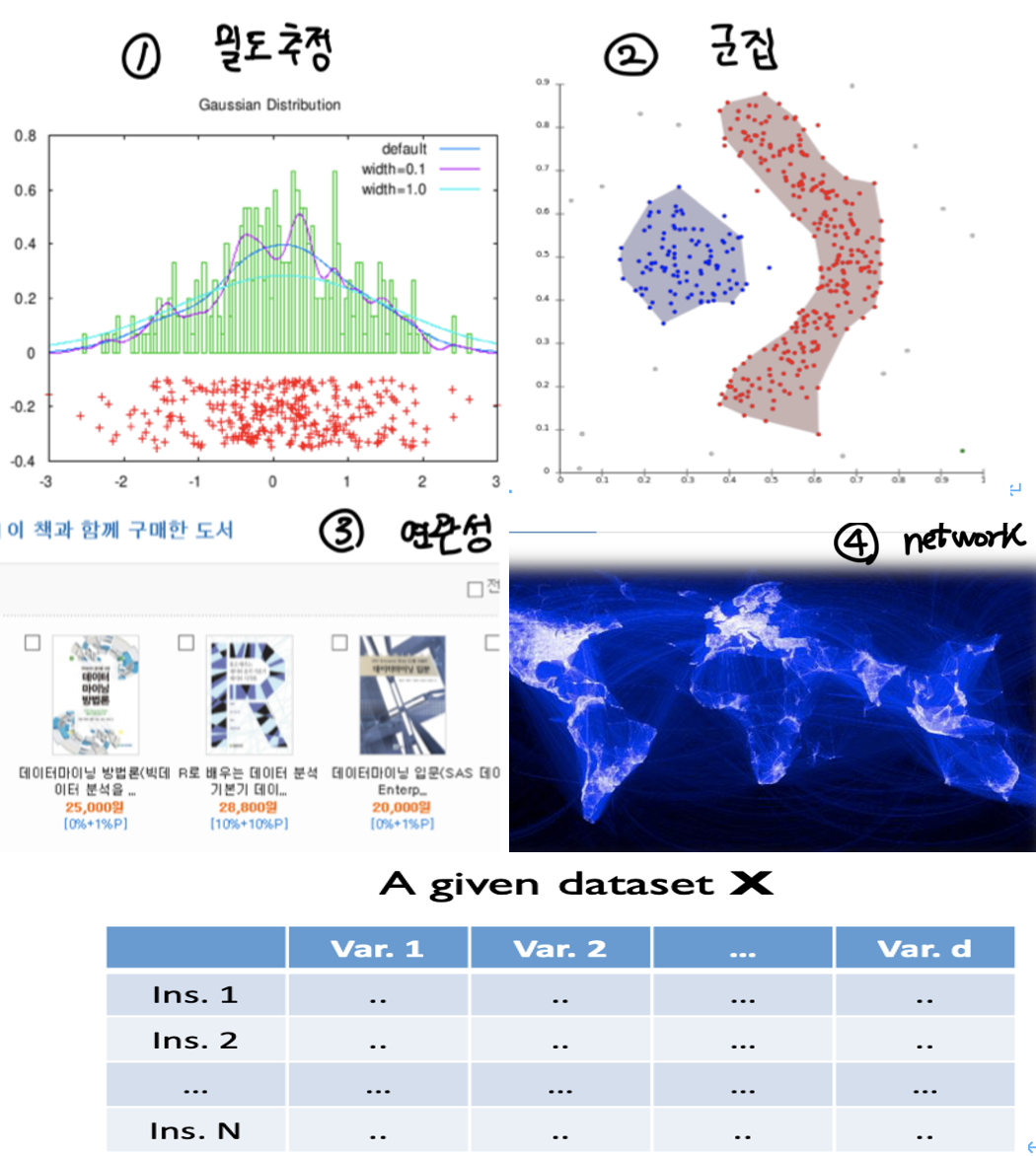
- , X라는 설명변수만을 가지고 데이터의 내재적 특징과 분포 츠정, 비슷한 집단의 객체를 찾는 것이 목표
- no target
- example: 밀도추정, 군집, 연관성, network 등
1.2. Supervised Learning
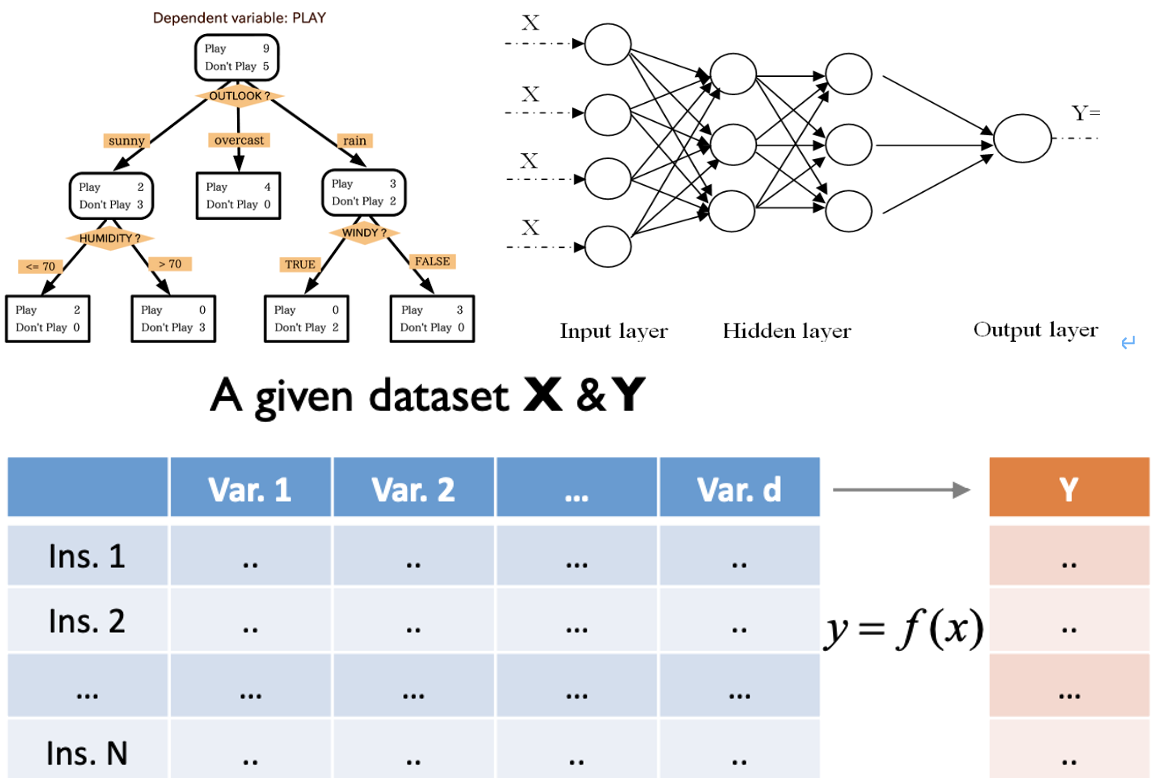
- , 설명변수와 반응변수를 찾아내는 것이 목표
- target 있음
- example: 의사결정나무, Neural Network 구조 등
2. Anomaly Detection
1. generated by a different mechanism (Hawhins, 1980)
- 데이터 생성 mechanism 관점
- 발생 메커니즘이 다름.
2. true probability density is very low (Harmeling et al., 2006)
- 데이터 밀도에 관한 관점
- 객체들 자체에 발생빈도 관점에서 봤을 때 매우 낮은 발생 빈도를 가지고 있으면, 그 데이터는 이상치임.
- Novelty: 다변량 데이터에 대해 사용되고 긍정적인 뉘앙스임.
-> Anomaly는 부정적인 뉘앙스임.
- Outlier: 단변량 데이터에 대해 사용되고 실제 변수들의 값을 벗어남.
- Outliers와 noise data는 다르다.
(noise를 반드시 제거해야 되는 것은 아니다.)
2.1. Applications
- Industrial Monitoring

- System Security
- 시스템 보완 (비정상적인 로그 데이터 감지)

2.2. Classification vs Anomaly Detection
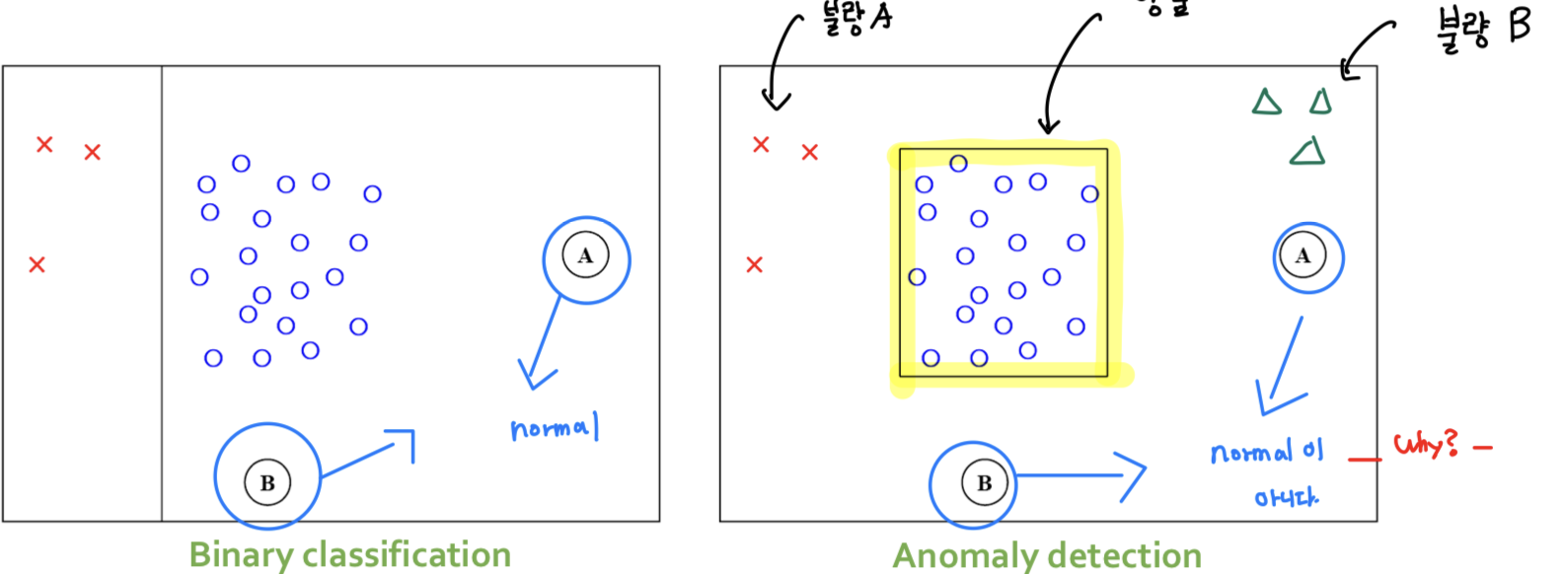
- Anomaly Detection의 목적 자체는 Supervised Learning임. (왜냐면 이상치인지 아닌지를 판별해야 하기 때문)
- 하지만 실질적으로 사용하는 방식은 Unsupervised Learning임.
그럼 언제 classification과 anomaly detection을 써야될까?

(1) data에 대한 불균형(imbalance)이 존재하는가?
- class imbalance가 심하지 않으면, classificaction으로!
(7:3, 8:2 이런건 X -> 9:1 이런게 불균형임)
- yes면, Anomaly Detection으로!
(2) 소수 범주에 대한 데이터가 충분하는가?
- yes면, classification으로 푸는 것이 더 효율적!
- no면, Anomaly Detection으로 푸는 것이 더 효율적!
- (1) 범주간의 불균형도 심각하면서 (2) 소수 범주에 대한 데이터가 불충분할 때, Anomaly Detection을 사용함
2.3. Generalization vs Specialization
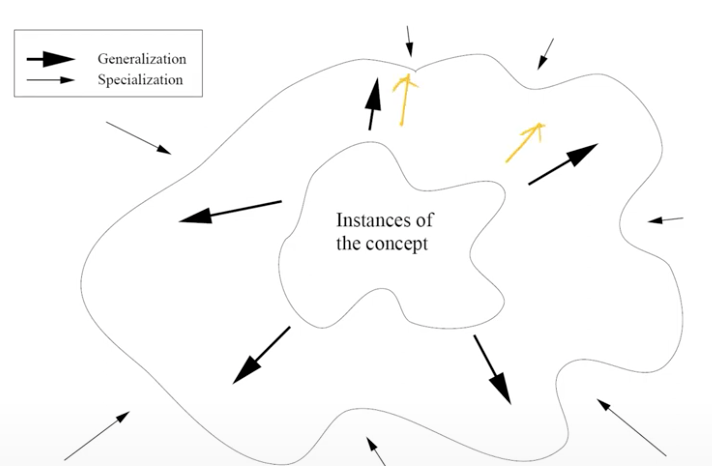
- 일반화와 구체화 사이에는 반드시 trade-off 관계가 있음.
- Generalization 확장 ⬆️ ➡️ normal이 아닌데도 normal로 잘못 분류 (2종 오류)
-> 귀무가설이 거짓인데 채택
- Specialization 확장 ⬆️ ➡️ 실제로 normal class인데도 불구하고 normal이 아닌것처럼 판단 (1종 오류)
->귀무가설이 참인데 기각
- 이 둘 사이의 trade-off가 발생하기 때문에 적절히 잘 조정해야 함.
2.4. Assumption
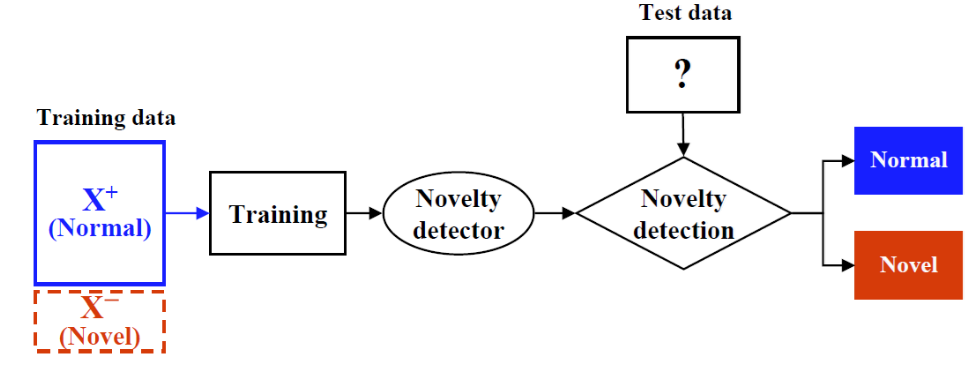
-
normal data가 abnormal data보다 많아야 한다.
-
모델링 할 때는 abnormal을 사용하지 않고 normal data만 사용해서 모델을 학습시킨다.
3. Type of Abnormal Data (Outliers)
3.1. Global Outlier
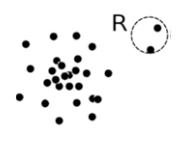
- 보통 이것을 많이 다룸
- example: Credit card fraud detection
3.2. Contextual Outlier
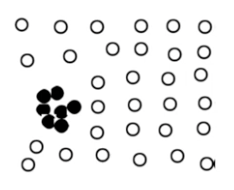
- 상황과 환경에 따라서 값이 outlier가 되기도 하고, 그렇지 않을수도 있음
- 상당히 까다로움
- 예를 들어, 알레스카에서 30도와 사하라사막에서 30도는 환경이 다르기 때문에 온도가 다르다. 알레스카 30도는 outlier로 판단됨.
3.3. Collective Outlier
- 집단적 outlier
- example: Denial-of-Servie(DoS) attack
3.4. Challenges
주의 사항은 다음과 같음.
1. abnormal data를 충분히 모은 상황이 아니고 normal data만 가지고 모델링을 진행하기 때문에 실질적으로 outlier와 normal objects를 적절히 모델링하기 어려움.
- gray area가 존재하기 때문에 영역 boundary가 정해지지 않아서 영역을 구분하기 쉽지 않음.
2. 우리가 풀어야 하는 도메인에 매우 종속적임.
- generalization과 specification 사이의 trade off를 어디서 끊어야 하는지는 'Domain'별로 달라짐.
3. 결과물에 대해서 이해가 가능해야 함.
- 이 상황에서 이 개체가 왜 Outlier인 것인가? 왜 abnormal인 것인가?
- 어떤 변수들이 그 abnormal data에 기여를 많이 했는가? 등에 대한 해석이 가능해야 함.
4. Performance Measures
- Train: Normal Data Only
- Test: Normla(더 많아야 함) + Abnormal Data
성능 평가 지표
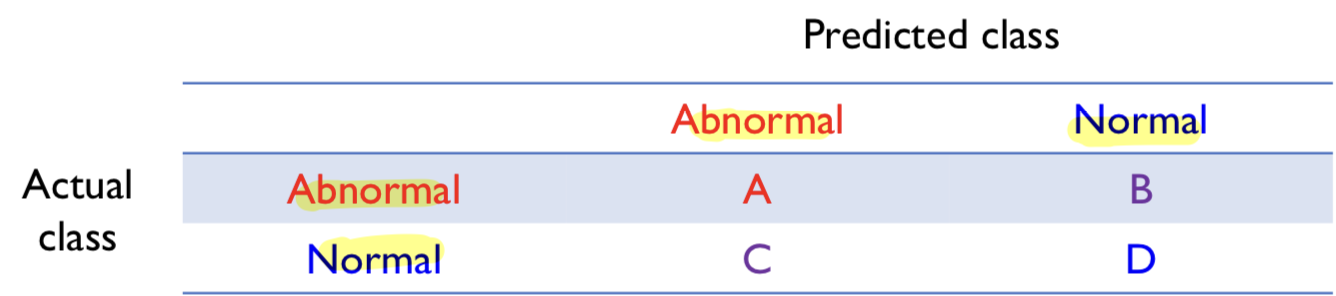
cut-off(threshold)가 존재

- Detection Rate:
= (Identified as abnormal) / (Actually abnormal)
- False Rejection Rate (FRR):
= (Rejected as abnormal) / (Actually normal)
-> 원래는 정상인데, 정상이 아닌 것으로 reject됨.
- False Acceptance Rate (FAR):
= (Accepted as normal) / (Actually abnormal)
-> 원래는 비정상인데, 정상으로 판단됨.
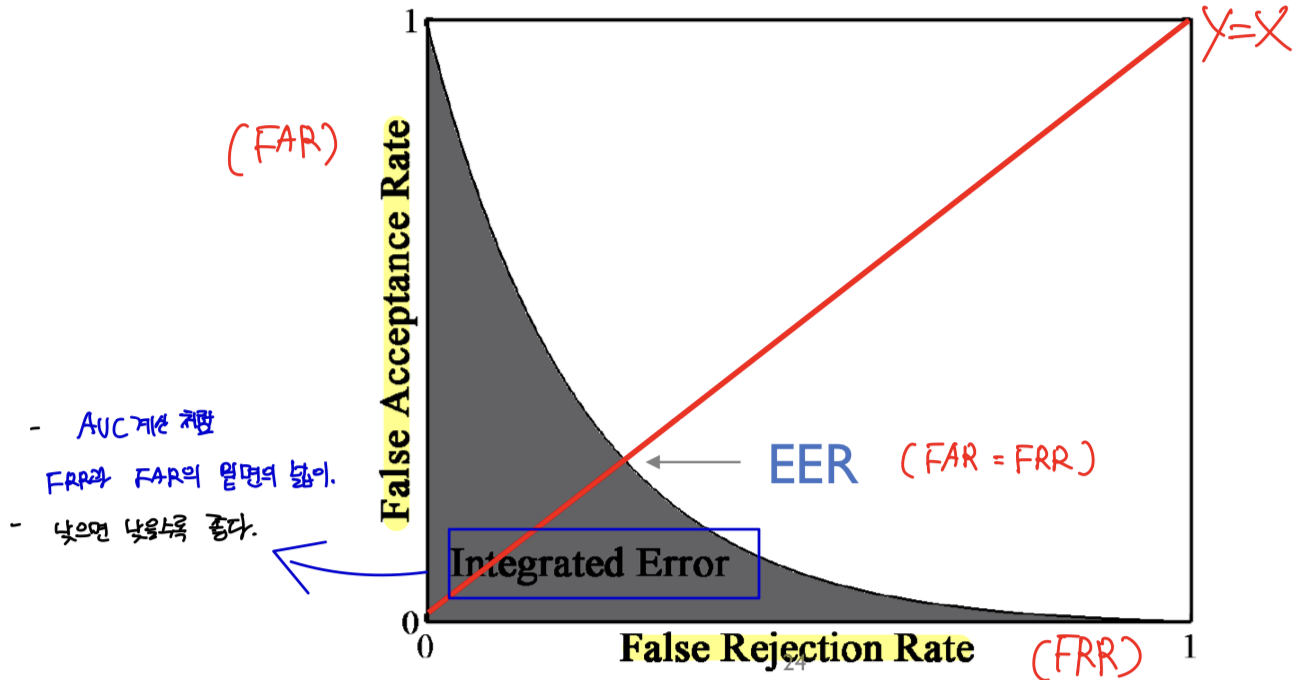
- x축: False Rejection Rate (FRR)
- y축: False Acceptance Rate (FAR)
- EER(Equal error rate)
: (FAR = FRR) / 낮으면 낮을수록 좋음
- IE (Integrated Error)
: 낮으면 낮을수록 좋음 / FRR과 FAR의 밑면의 넓이
🎯 Summary
- Anomaly Detection과 Classification의 차이는 다음과 같음. (1) 범주간의 불균형의 차이 (2) 소수 범주에 대한 데이터 불균형의 차이
- 이상치 탐지 분야를 Computer vision 분야에 접목해서 의류 위조상품 모니터링 프로젝트를 하고 싶은 소망
- 강의자료와 유튜브를 무료로 볼 수 있게 한 DSBA 연구실에 감사의 인사를 전합니다.
📚 References
- Youtube
- https://www.youtube.com/watch?v=ECgI1YVQpY8&list=PLetSlH8YjIfWMdw9AuLR5ybkVvGcoG2EW&index=16, DSBA 연구실 유튜브
- 강의 자료

AI 전문가가 되기 위해 [a-zA-Z]까지 정리하는 거나입니다 😊