- 해당 논문 리뷰에는 Transformer을 구체적으로 알기 위해서 다양한 정보를 추가하였습니다.
편하게 봐주시면 감사하겠습니다!
Title
- Attention Is All You Need

Abstract
- Encoder와 Decoder를 연결하는 Attention mechanism만을 기반으로 하는 Transformer를 제안
- 두 가지 기계 번역 작업 실험 결과, 이 모델은 품질이 우수하면서도 병렬화가 가능하고, 적은 시간이 소요되었다.
- WMT 2014 영어-독일어 번역 작업에서 28.4 BLUE를 달성하여 기존보다 성능이 우수하였다
- 8개의 GPU에서 3.5일 간 훈련한 후 41.8의 새로운 단일 모델 최첨단 BLUE 점수를 기록했다.
1. Introduction
- 최근 연구에서는 인수분해 기법과 조건부 계산을 통해 계산 효율을 크게 개선했으며, 후자의 경우 모델 성능도 개선하였다.
- Attention mechanism만을 사용하여 입력과 출력 간의 글로벌 종속성을 도출하는 모델 아키텍처인 Transformer을 제안하였다.
- Transformer는 더 많은 병렬화를 가능하게 하며, P100 8개의 GPU에서 단 12시간의 훈련만으로 새로운 수준의 번역 품질에 도달할 수 있다.
2. Background
- Sequential computation 감소의 목표는 Extended Neural GPU, ByteNet, ConvS2S를 기초로 형성했다.
Transformer 등장 배경에 앞서서 Attention의 등장 배경을 알아야지 이해되기 때문에 간단히 짚고 넘어가겠다.
2.1 Attention
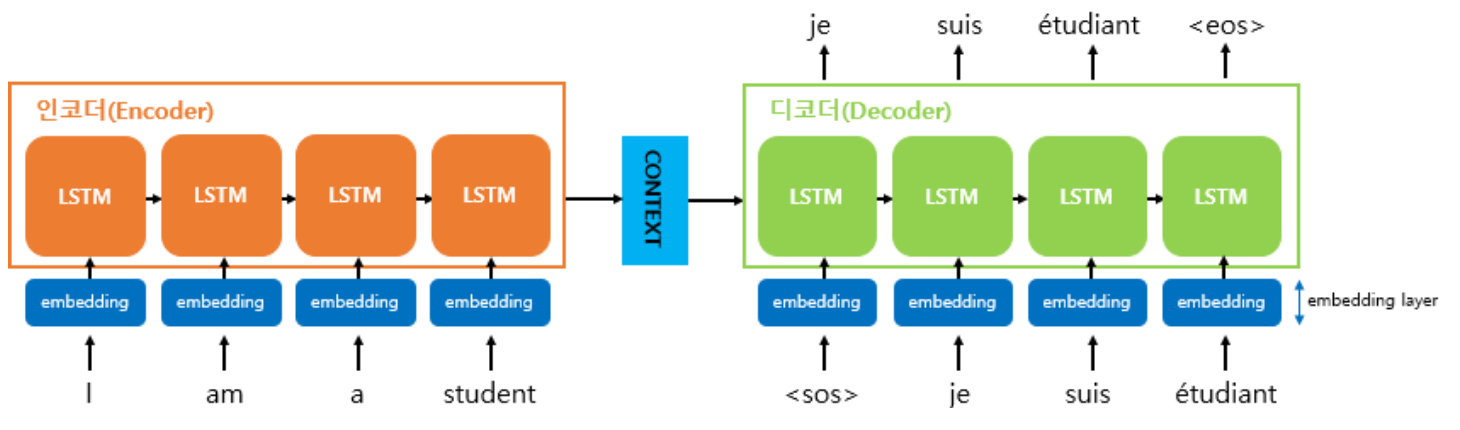
- 기존의 Seq2seq 모델은 항상 고정된 길이의 벡터를 출력하기 때문에 입력 문장의 정보를 모두 활용하지 못한다는 문제점이 존재하였다.
그렇다면 '입력 문장의 길이에 맞게 Encoder의 출력 벡터의 길이를 변화시키면 어떻게 될까?' 라는 질문에서 출발한 것이 Attention 접근 방식이다.
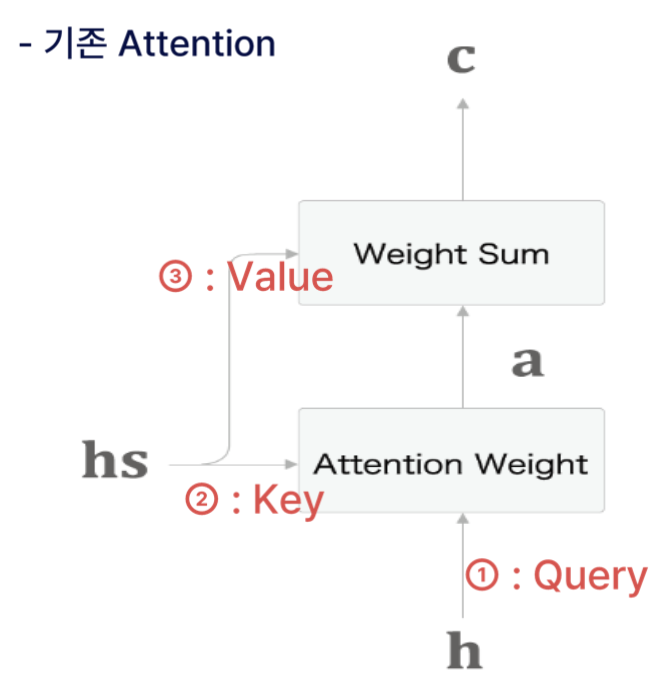
ㄱ. Encoder 개선
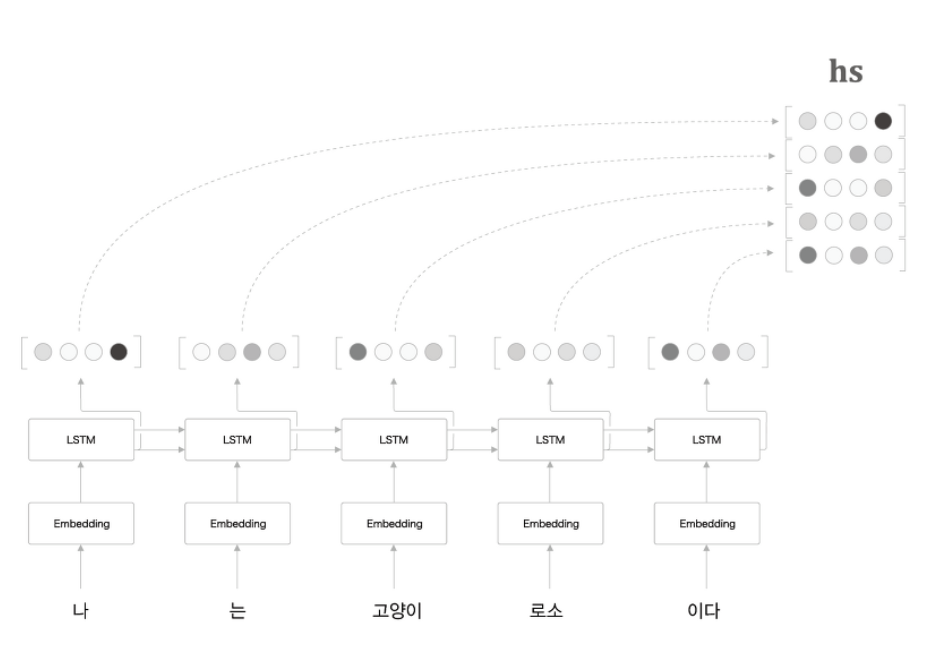
- 은닉층의 마지막 시점을 출력하는 것이 아닌 모든 시점에서의 벡터를 출력하는 것이다.
- 각 시점에서의 나오는 출력 벡터
-> 해당 시점 입력 단어의 정보 + 이전 시점에서의 정보
- 모든 벡터를 활용한다면, 각 시점에서의 정보를 최대화하여 활용할 수 있다.
-> 각 시점에서의 출력을 하나의 행렬로 묶어 Decoder로 전달해야 한다.
- 이 hs 행렬을 Decoder의 모든 시점에 전달해야 한다.
여기서
hs란모든 시점에 대해 정보를 갖고 있는 행렬을 의미한다.
ㄴ. Decoder 개선
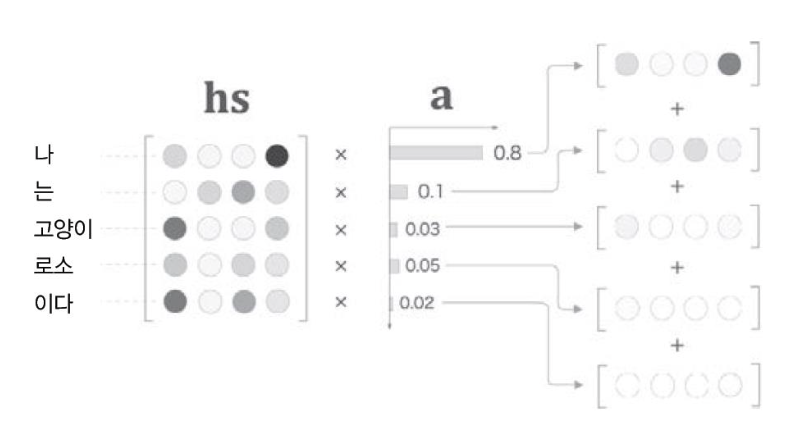
어떻게 하면 Encoder에서 전달 받은 행렬을 잘 활용할 수 있을까?
- 본인 시점에서 맞는 벡터만 선택해서 활용해야 한다.
-> 순전파 과정에선 가능하지만 오차역전파 계산이 불가능
--> 오차역전파 계산이 가능하면서도 원하는 벡터만 선택해야 한다면,행렬 내 각 벡터의 중요도를 계산하여 가중치 합을 구해야 한다.
- 위의 그림에서
a란벡터의 중요도를 의미한다.
- Decoder에서 LSTM을 거쳐서 나온 vector가 얼마나 유사한지를 vector의 중요도로 판단한다.
- 즉, 현 시점에서 어떤 값에 집중할지를 나타내는 것을 의미한다.
그렇다면 벡터의 중요도는 어떻게 구하는 것일까..?
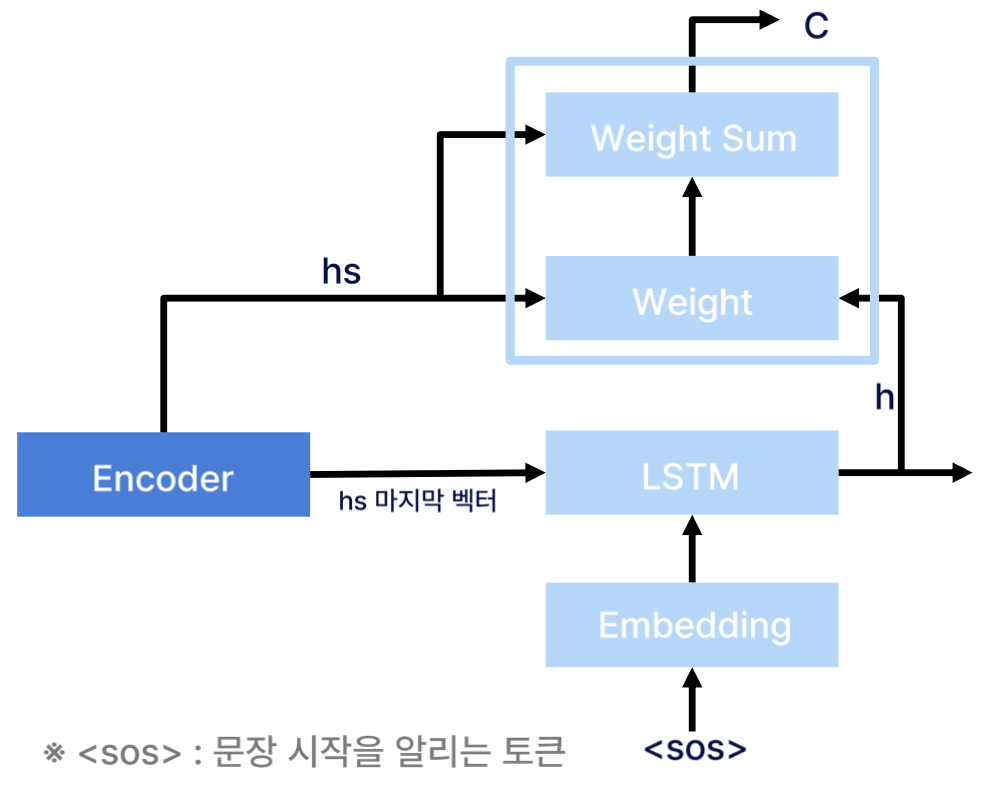
그 과정은 다음과 같다.
1) hs행렬(Encoder에서 받은 행렬)과 h벡터(LSTM을 거쳐서 나온 벡터)를 내적한다
-> 내적한 값이 크다는 의미는 두 벡터의 방향이 유사하다는 의미이고, 내적 값이 큰 벡터가 더 많이 유사하다는 것을 알 수 있다.
2) softmax함수를 적용한다.
-> 구하고자 하는 것은 가중치이므로 그대로 사용하면 안되고 가중치처럼 보이게 하기 위해 softmax를 적용한다.
- 지금까지 Weight 계층에서 하는 일에 대해 서술하였다.
- 다시 정리하면,
hs 행렬과h벡터의 내적 +softmax함수 적용
3) Weight sum 계층을 통해 맥락벡터(c)를 출력한다.
-> Weight 계층으로부터 입력 받은 가중치(a)와 hs 행렬을 곱하여 맥락벡터(c)를 출력
ㄷ. 최종 정리
- Attention이란, Encoder에서 각 계층마다 나오는 벡터(모든 위치에서의)를 행렬로 묶어서 전달하는 것을 의미한다. 이때, Weight 계층과 Weight Sum 계층이 하는 일에 대해서 잘 알아야 한다.
- 맥락백터(c)란, Encoder에서 전달받은 hs행렬에서 현 시점에서 가장 필요한 정보만을 담은 벡터를 의미한다.
-> 이를 활용해 단어를 예측하면 기존의 Seq2seq 모델보다 더 정확한 예측이 가능하다.
2.2 Transformer
ㄱ. 기존 RNN 계열의 문제점
1) 기존의 Seq2seq 모델 같은 경우, Encoder를 거친 최종 마지막 벡터만 Decoder로 전달하였다. 즉, input 정보를 고정된 길이의 벡터로 Decoder에 전달했기 때문에 input 데이터의 정보가 너무 압축되어서 정보 손실이 일어난다.
-> Attention의 출현으로 보정
2) 하지만 Attention 또한 RNN 모델에 의존적이다.(병렬화를 배제)
-> 여기서 병렬화를 배제했다는 것은 RNN 구조 자체가 하나씩 전달 해야 하는데, 이렇게 데이터를 앞에서 하나씩 읽어야 되는 단점이 있다.
-> Encoder or Decoder에 LSTM(RNN)이 존재한다.
3) Attention mechanism은 모델이 아니라 RNN을 보정하는 정도이다.
그렇다면 '
RNN 모델을 사용하지 않고 Attention 구조만을 사용해서 모델 구현할 순 없을까?' 라는 질문으로 시작해서 Transformer가 나오게 되었다.
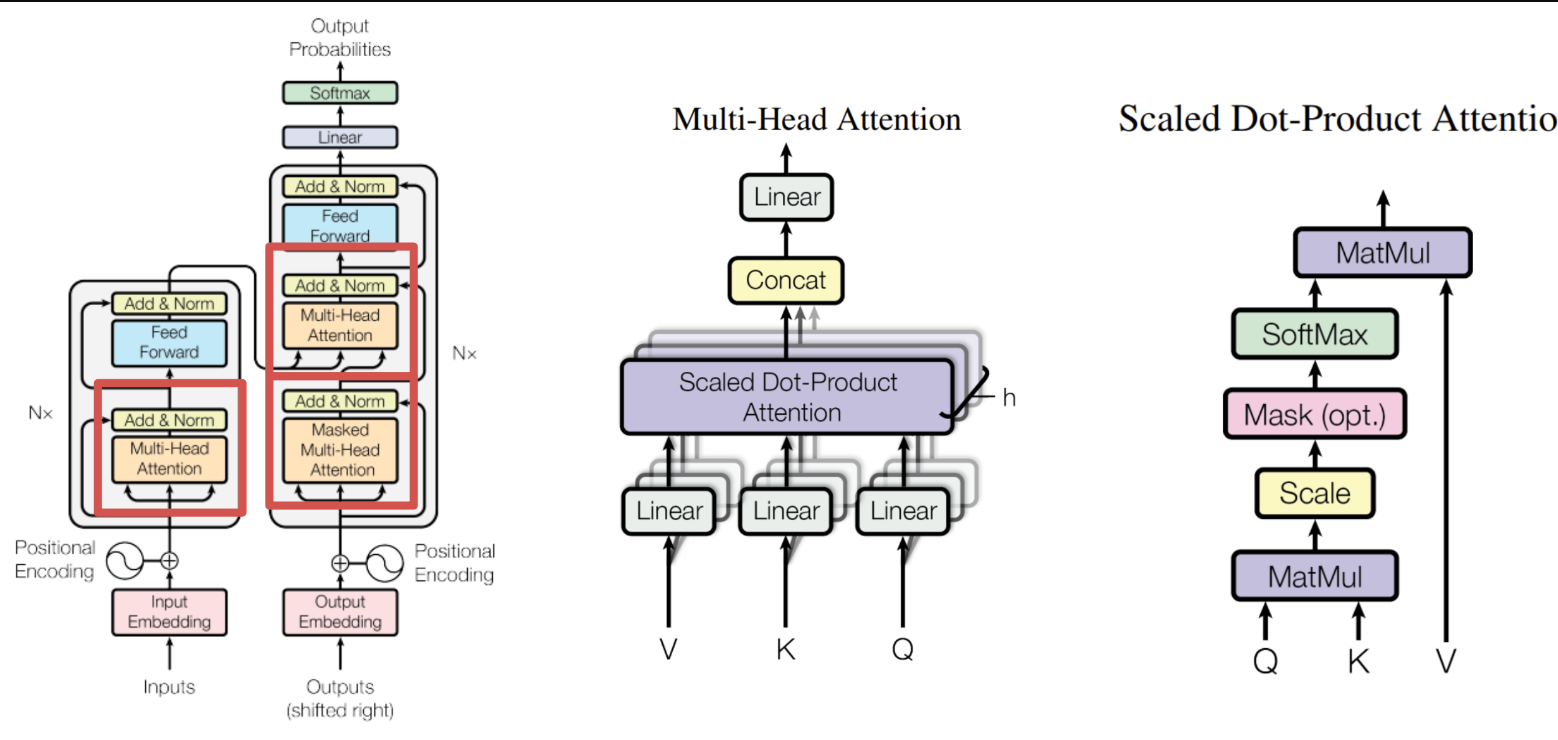
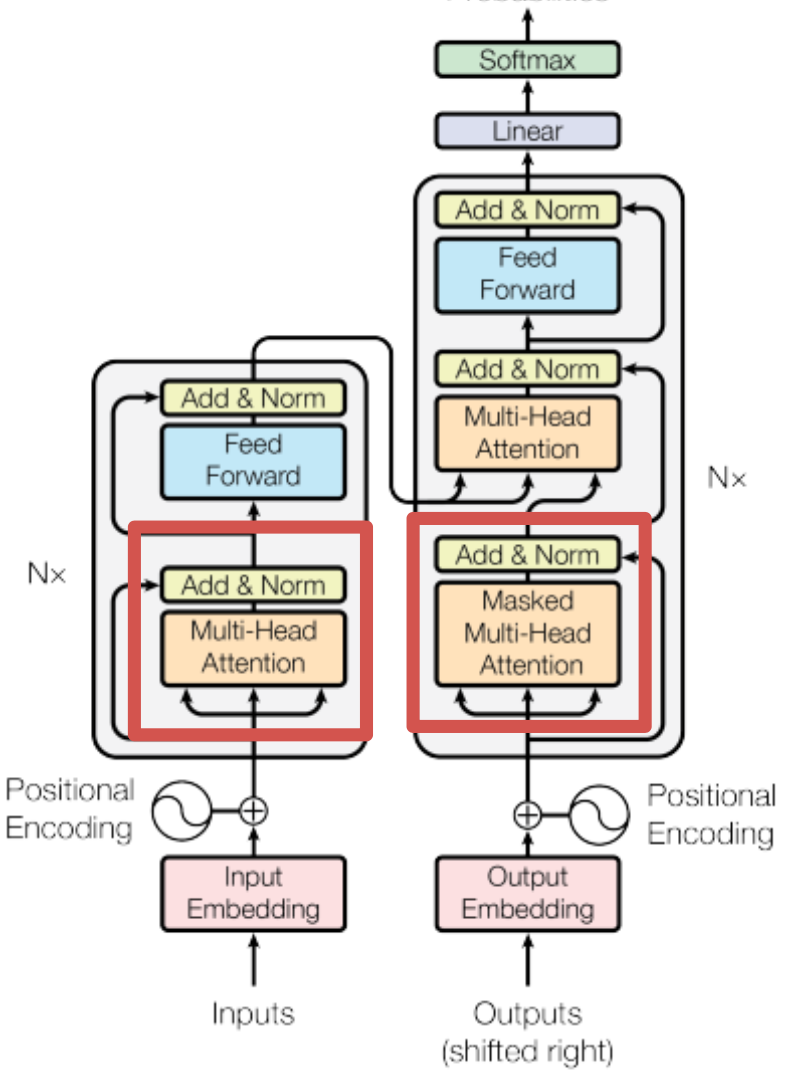
3. Model Architecture
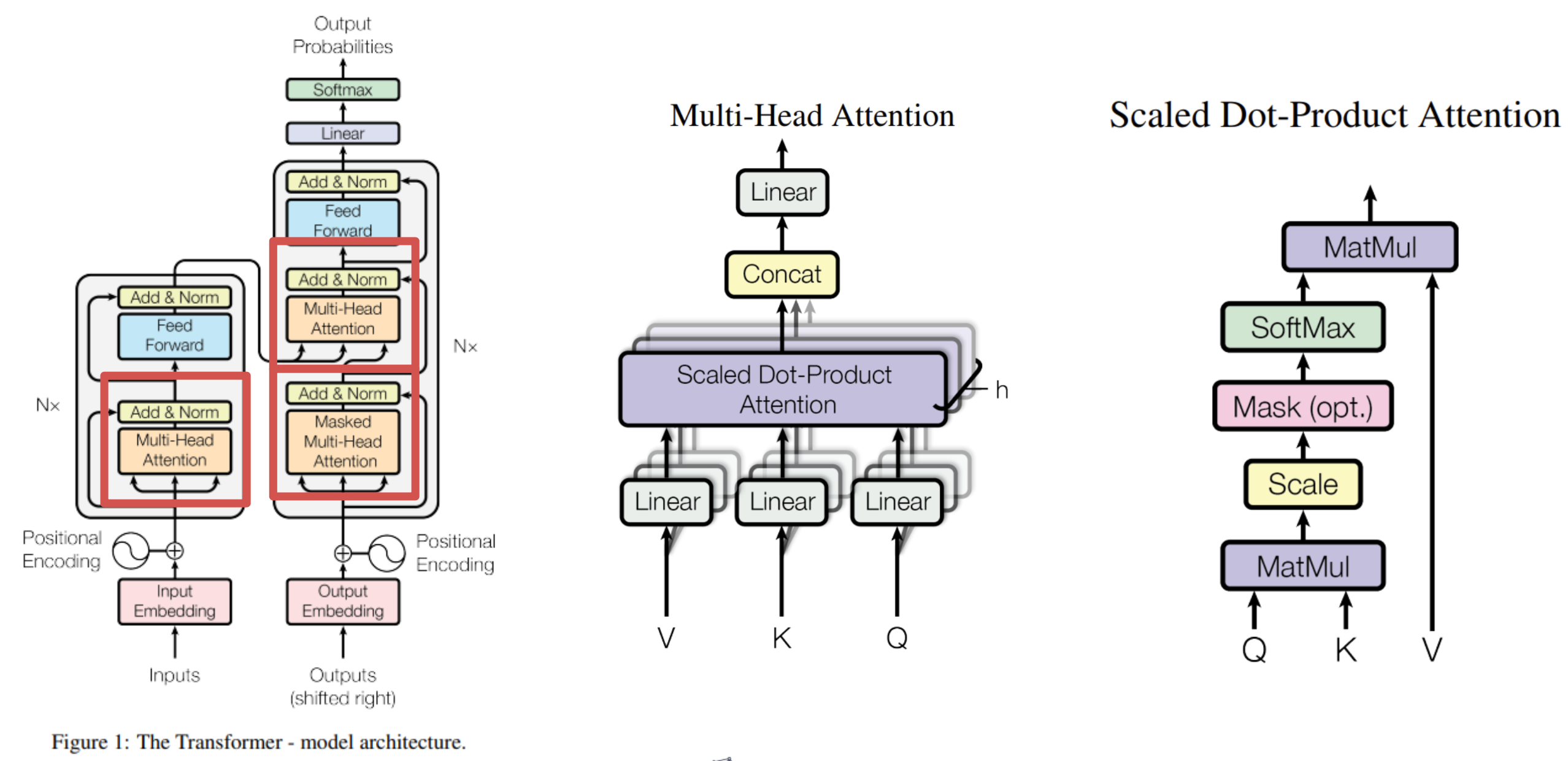
- 왼쪽 그림은 Transformer의 전체적인 구조를 의미한다. 그리고 중간 그림은 Multi-Head Attention구조를 의미하고, 오른쪽 그림은 Multi-Head Attention 중 가운데 부분인 Scaled Dot-Product Attention 구조를 의미한다.
- 아키텍처는 다음과 같다.
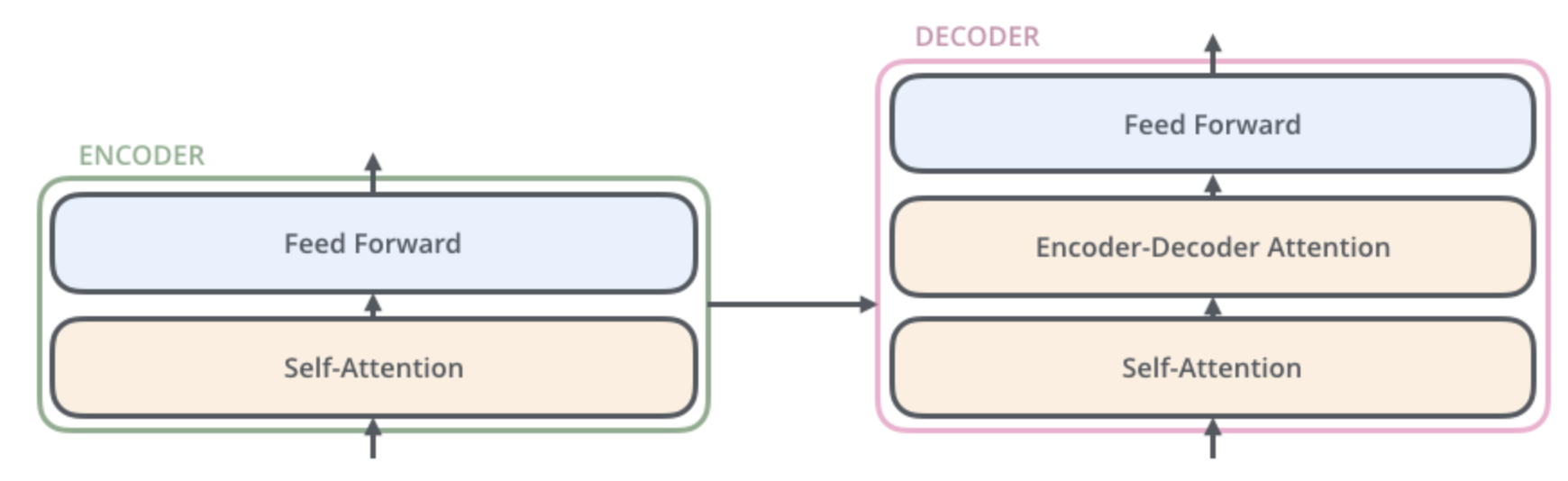
Encoder, Decoder 구조를 가지고 있고, Encoder와 Decoder를 모두 더해 stacked self-attention과 포인트 단위의 Fully Connected Layers를 거쳐 최종 출력을 한다.
3.1 Encoder and Decoder Stacks
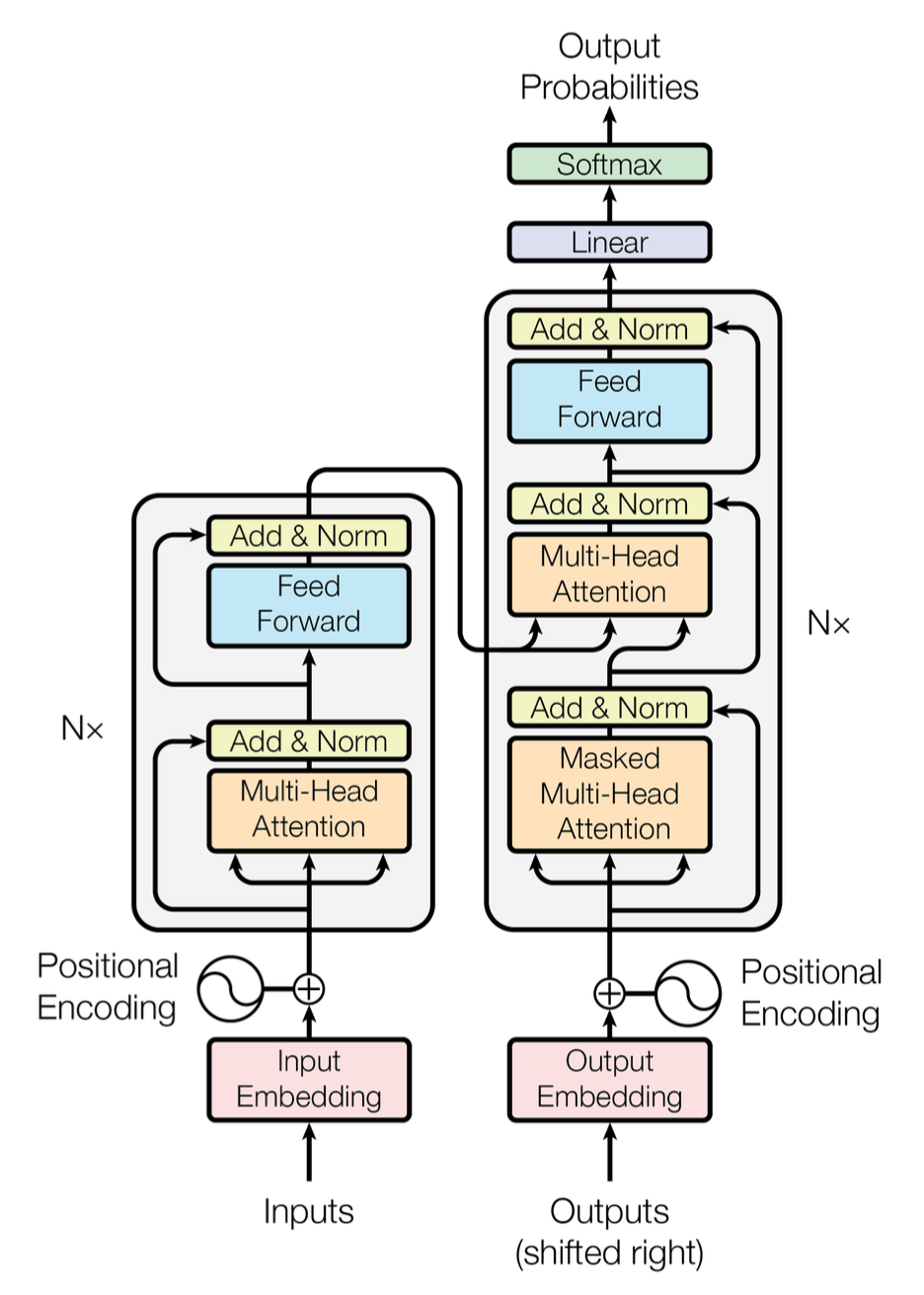
Encoding Block vs Decoding Block
=UnmaskedvsMasked
= 2단 구조 vs 3단 구조
ㄱ. Encoder
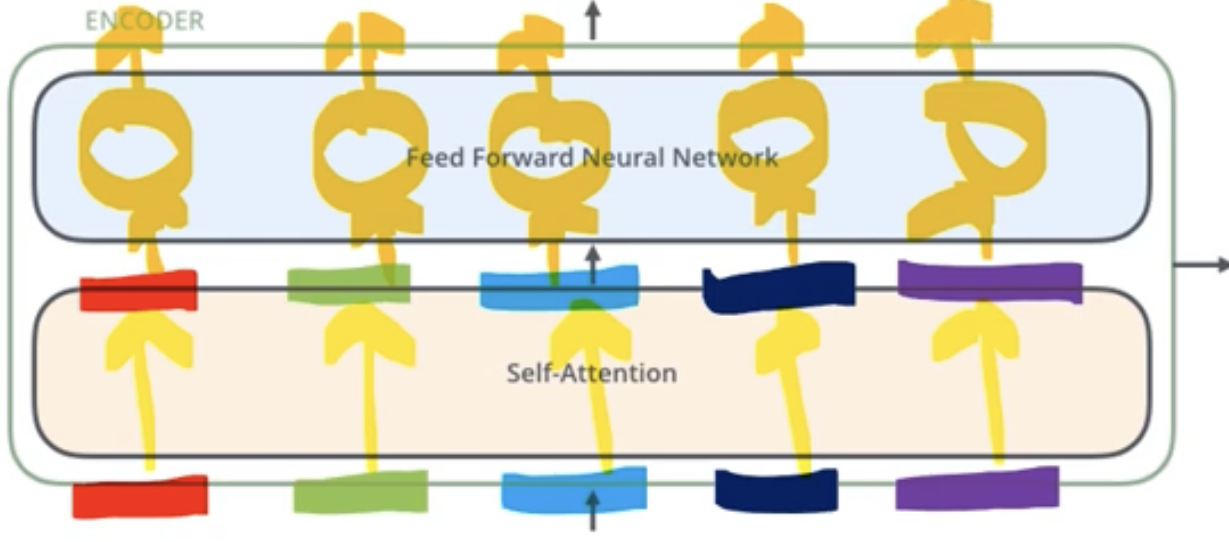
1. 인코더의 모든 구조는 동일하지만 해당하는 가중치를 share하는 것은 아니다.
- 예를 들어, 1번째 Encoder block과 3번째 Encoder block의 구조는 동일하지만, 다만 그 구조 안에서 가질 수 있는 가중치들은 학습을 통해서 달라질수 있다.
2. 인코더의 구조는 2개의 sub-layers로 구성된다.
- 먼저 self-attention layer를 거치고 feed-forward neural network를 거쳐서 output이 나오게 된다.
- 예를 들어, 위의 그림처럼 5개의 word가 있다고 가정하면, self-attention을 통해서 5개의 word가 position을 유지한 채 그대로 나오게 된다. 그 뒤 feed forward nerual network를 적용할 때 한꺼번에 적용 하는 것이 아니라, 각각의 단어들에 대해서 각각 feed forward nerual network를 적용한다. 이것이 Transformer Encoder의 가장 큰 특징이다.
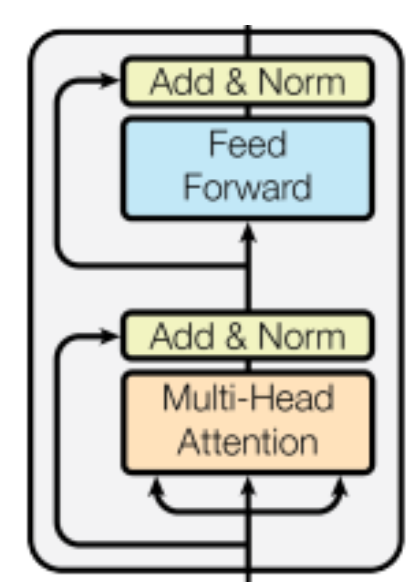
- Encoder는 N=6개의 layers가 쌓여있고, 두 개의 sub-layers를 가지고 있다.
Transformer의 Encoder 과정은 다음과 같다.
- 입력된 행렬을 Query, Key, Value 3개로 나눈다.
- Multi-Head Attention 계층을 거친다.
- Skip-Connection이 적용된 행렬과 Add & Norm을 수행한다.
- Feed Forward 계층을 거친다.
- Skip-Connectrion이 적용된 행렬과 Add & Norm을 수행한다.
- 해당 행렬을 다시 1번 과정으로 돌아간다.
위 과정을 총 N번 수행하는데, 이 논문에서는 이를 총 6번 수행하였다.
ㄴ. Decoder
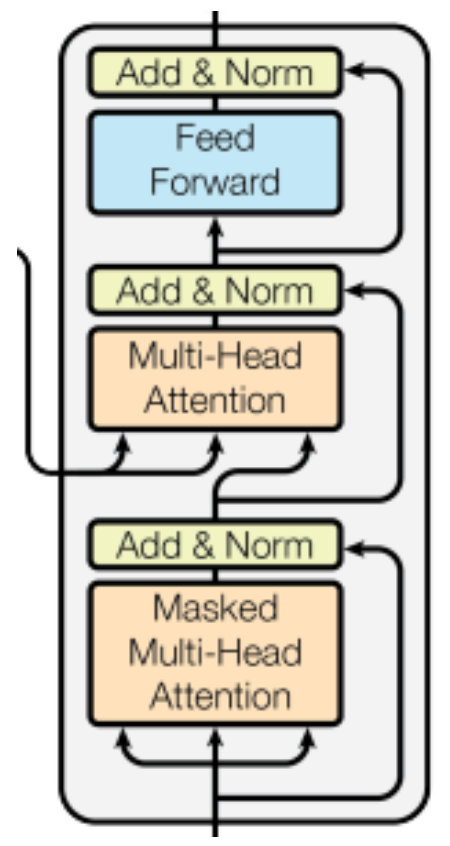
- Decoder도 역시 N=6개의 layers가 쌓여있고, 세 개의 sub-layer를 가지고 있다.
Transformer의 Decoder 과정은 다음과 같다.
- 입력된 행렬을 Query, Key, Value 3개로 나눈다.
- Masked Multi-Head Attention 계층을 거친다.
- Skip-Connectrion이 적용된 행렬과 Add & Norm을 수행한다.
- Encoder로부터 입력된 행렬을 Key, Value 3번 과정으로 부터 나온 행렬을 Query(Decoder에서 나오는 h벡터)로 사용한다.
5.Multi-Head Attention 계층을 거친다.- Skip-Connectrion이 적용된 행렬과 Add & Norm을 수행한다.
- Feed Forward 계층을 거친다.
- Skip-Connectrion이 적용된 행렬과 Add & Norm을 수행한다.
- 해당 행렬로 다시 1번 과정을 수행한다.
위 과정을 총 N번 수행하는데, 이 논문에서는 이를 총 6번 수행하였다.
3.2 Self-Attention
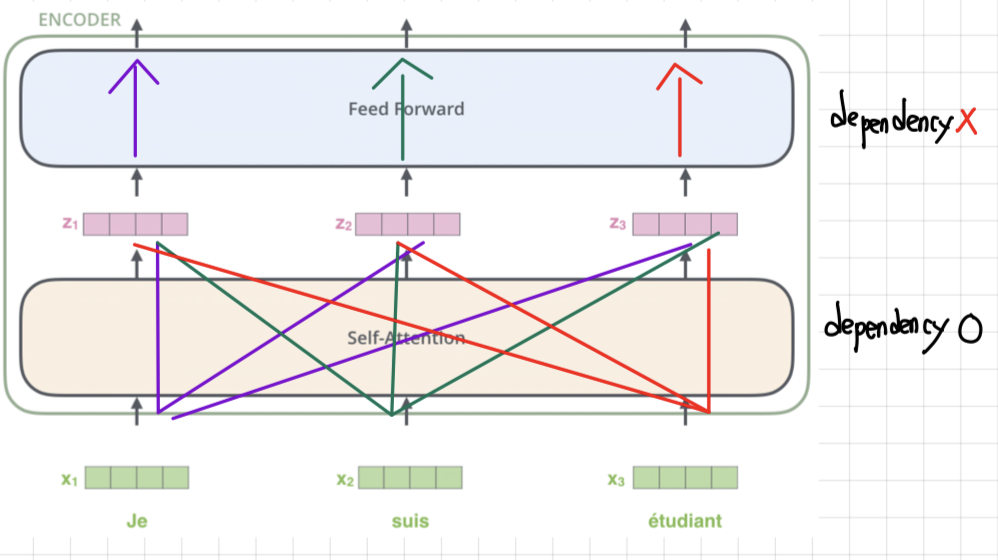
- Self-Attention은 dependency O <-> Feed Forward에는 dependency X
- dependency가 있다는 것은 서로 영향을 미친다는 의미이지, 서로 바뀐다는 의미는 아니다.
Self-Attention이 하는 역할은?
- 예를 들어, The animal did't cross the street because it was too tired 라는 문장이 있다. 이때 it은 The animal이라고 사람은 금방 생각할 수 있지만 컴퓨터는 바로 생각할 수 없다.
- Self Attention은 input sequence에 있는 다른 단어들도 다 훑어 가면서 it과 연관되는 단어가 무엇인지 찾는 것이다. 즉, 현재 processing 중인 단어에 대해서 의미를 정확히 파악하고, 그것에 대한 처리를 보다 정확하게 하기 위해서 동일한 input sequence 단어에 대해서 살펴보겠다는 것이다.
Self-Attention in Detail

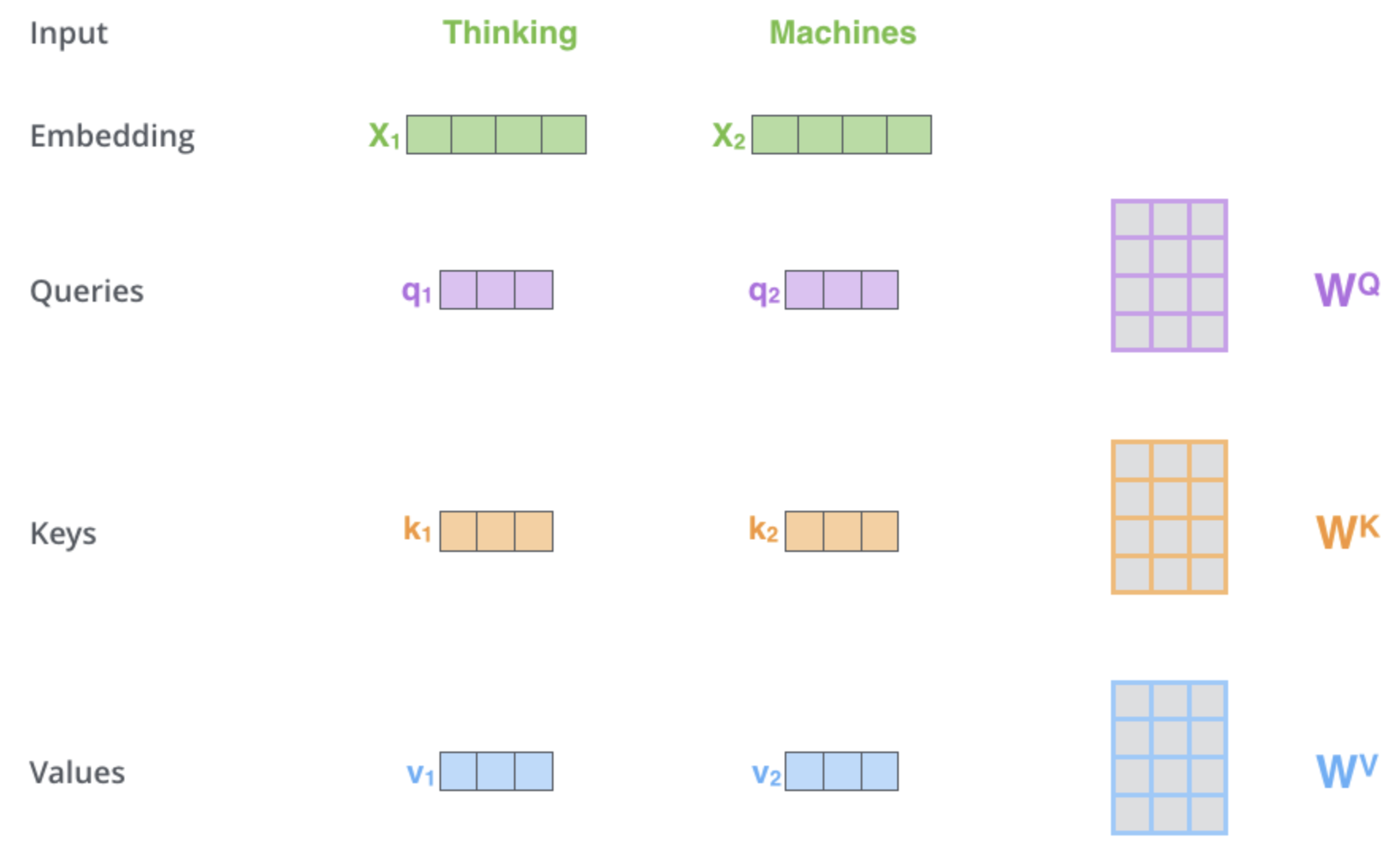
1) encoder 각각의 3개의 input vector를 만든다.
Query: 현재 내가 보고 있는 단어의 representation이다. 다른 단어들을 scoring하기 위한 기준이 된다.Key: labels과 같은 역할을 하며, 어떤 Query가 주어지고 유의미한 단어를 찾을 때, key값은 identity로 원하는 값을 쉽게 찾을 수 있게 하는 역할을 한다. (=labels 값)Value: 실제 단어의 representation이다. (=실제 값)
- Query, Key, Value, Output은 모두 vector이다.
- Encoder Input / Output vectors의 차원보다 Q,K,V의 차원을 적게 잡는다.
ex) Q,K,V: 64차원 <-> Encoder Input / Output: 512차원
ex) 512 = 64 x 8 (multi-head) - Output은 값의 가중치 합으로 계산되고, 각 값에 할당된 가중치는 Query와 해당 Key의 compatibility function에 의해 계산된다.
2) Calculate a score
- 'Thinking'에 대한 self-attention을 계산한다고 가정할 때, 이 단어에 대해 입력 문장의 각 단어에 점수를 매겨야 한다.
- 점수는 특정 위치에서 단어를 encoding할 때 입력 문장의 다른 부분에 얼마나 많은 초점을 둘 것인지를 결정한다.
- 점수는 점수를 매기는 각 단어의 Key 벡터와 Query 벡터의 내적을 취하여 계산된다.
따라서 위치 #1 에 있는 단어에 대한 Self-Attention을 처리하는 경우 첫 번째 점수는 q1 과 k1 의 내적이 되고, 두 번째 점수는 q1 과 k2 의 내적이 된다.
3) Divide the score by (= 8 in the original paper since dk=64)
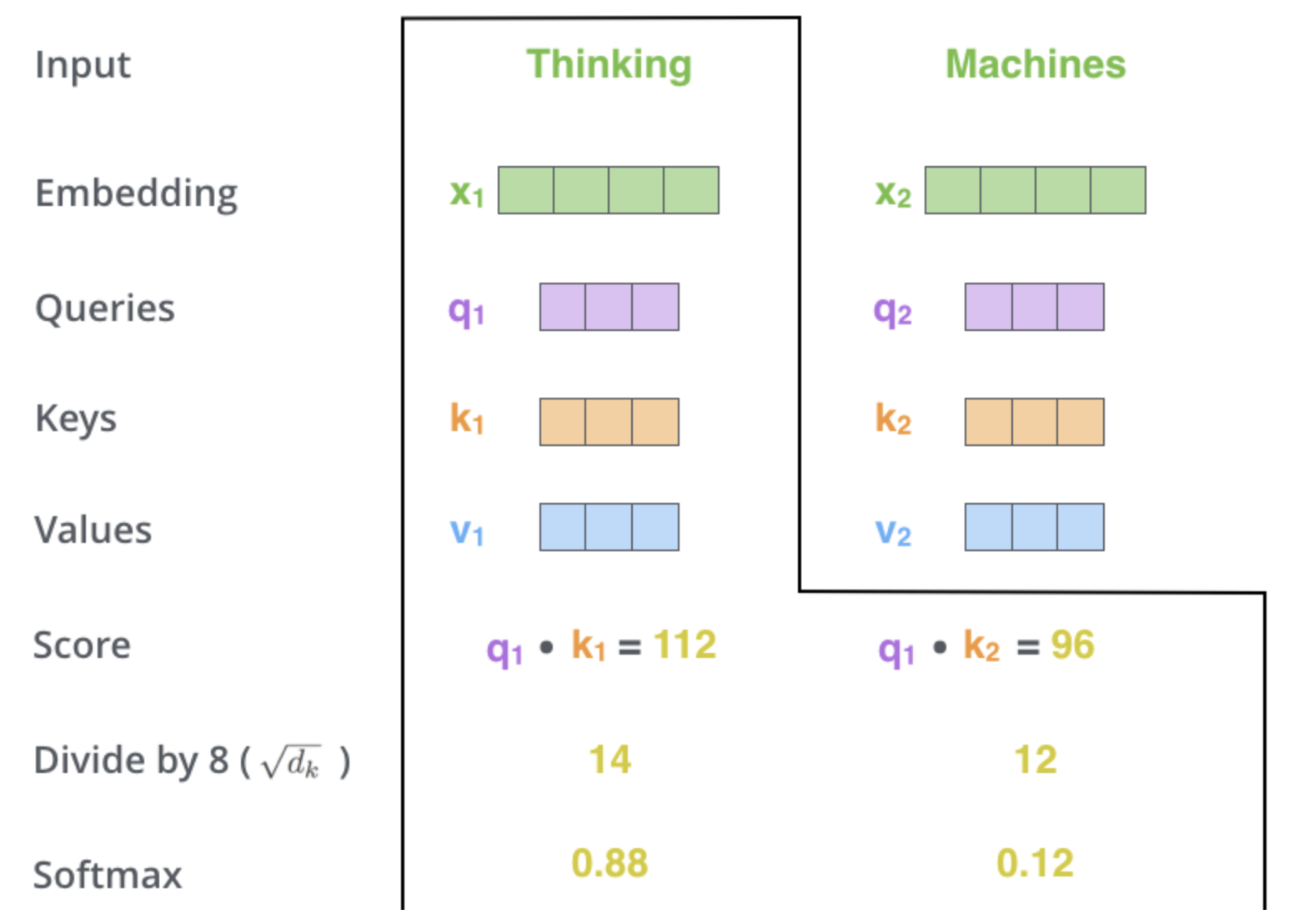
- gradients가 stable하는데 도움이 된다.
4) Pass the result through a softmax operation
- Softmax score는 현재 position에 해당하는 단어가 현재 자신이 보고 있는 단어에 대해 얼마나 중요한 역할을 하는가의 의미이다.
5) Multiply each value vector by the softmax score
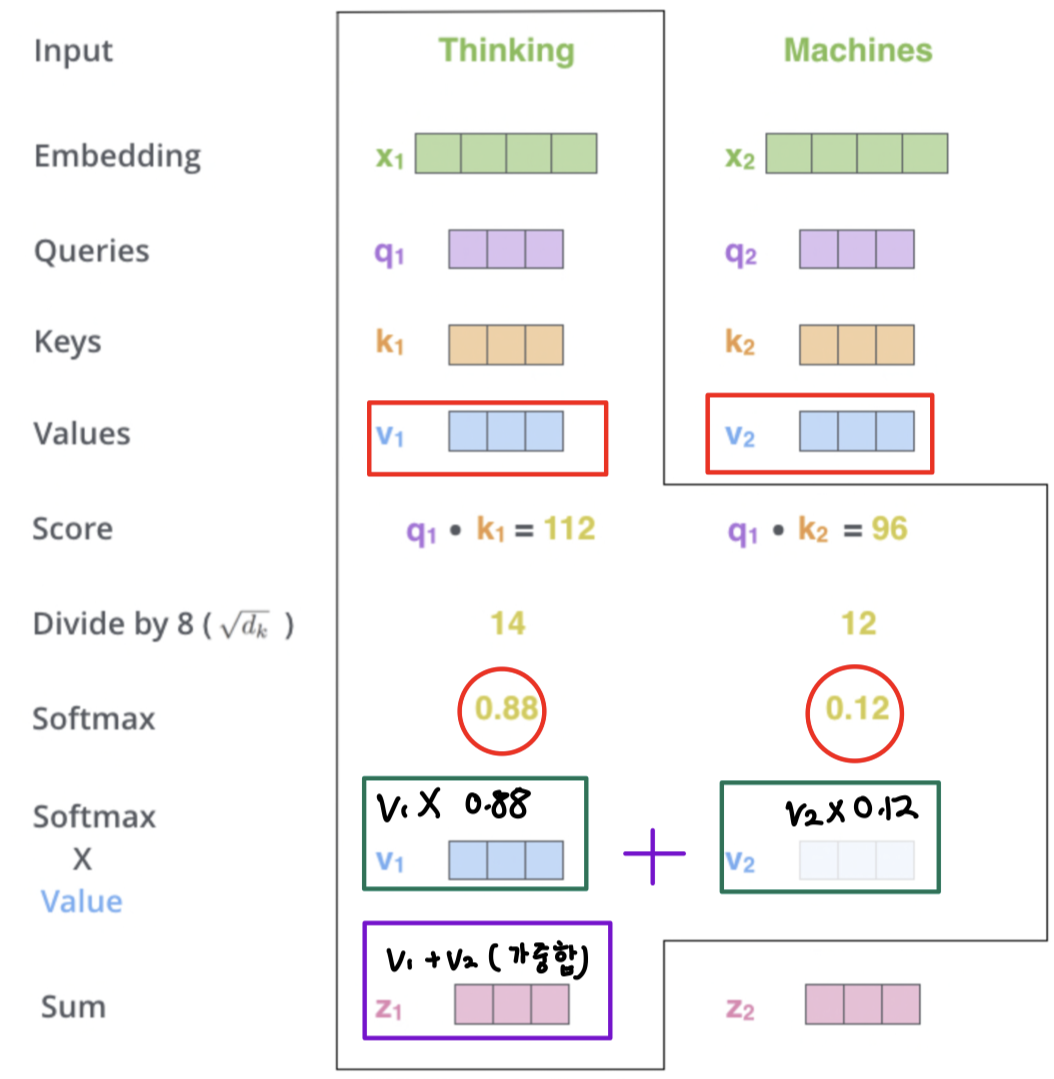
- values 벡터에 softmax를 곱하는 것이다.
- 집중하려는 단어의 values에 대해 더 집중하고, 관련 없는 단어는 제거하는 과정이다.
6) Sum up the weighted value vector which produces the output of the self-attention layer at this position
- softmax x value인 가중값 벡터 값을 합산한다.
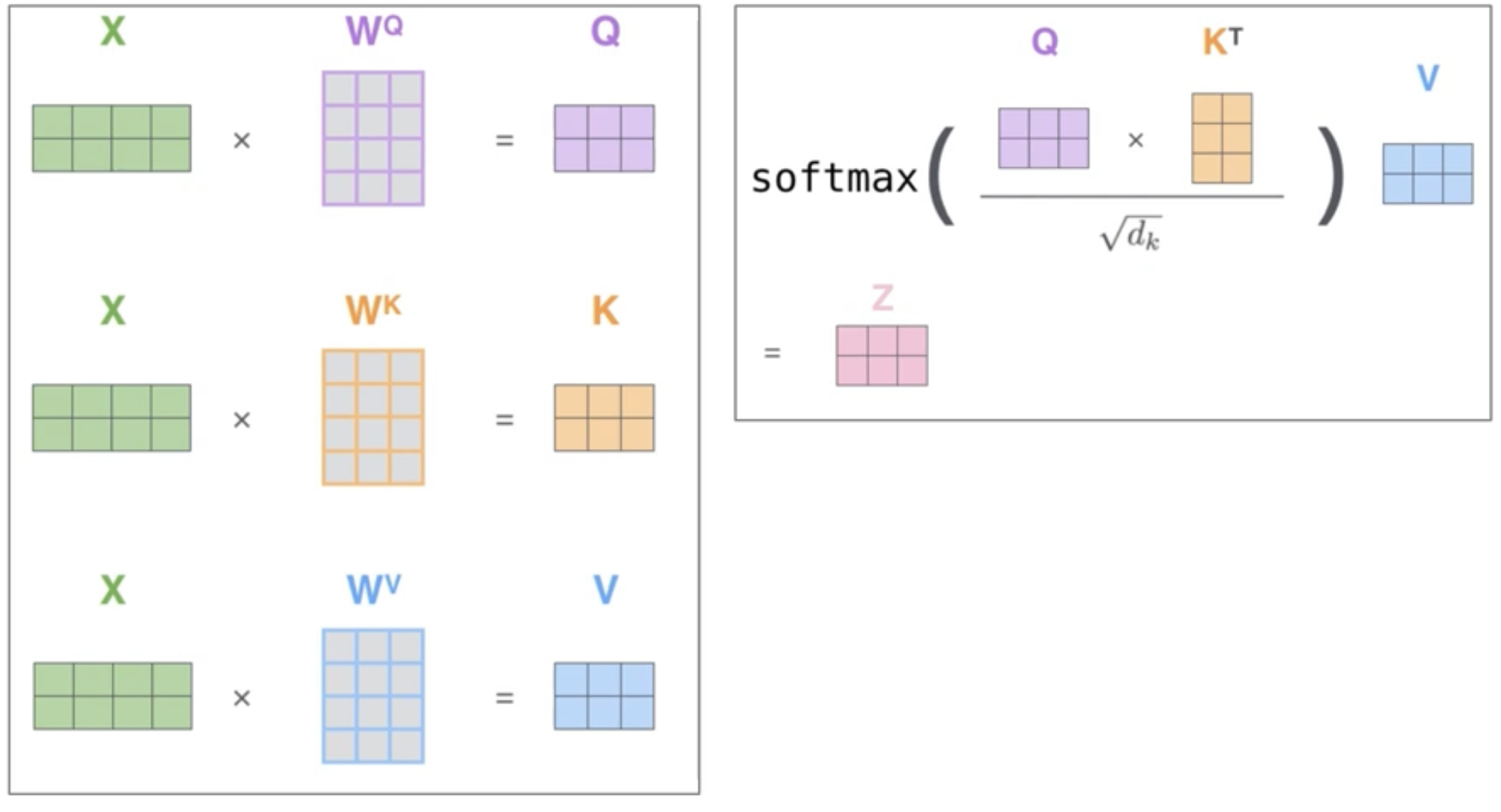
- 위의 과정을 다음과 같이 하나의 공식으로 축약하여 self-attention 레이어의 출력을 계산할 수 있다.
3.2.1 Scaled Dot-Product Attention
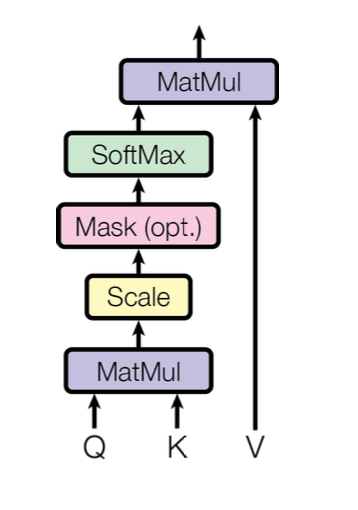
Scaled Dot-Product Attention 계산 순서는 다음과 같다.
- 하나의 입력만으로
Q,K,V를 생성- Query 행렬과 Key행렬을 행렬 곱 수행
- 기존 Attention 계층에서 hs 행렬과 h 벡터 사이의 유사도를 구하는 과정
- 출력된 행렬에
Scaling을 적용
- 위 식에서 로 나누는 것(dk= Key행렬의 차원 수)
기울기 소실 문제를 방지하기 위함
Masking과정을 거친다.
- 해당 과정은 Decoder에 위치한 Masked Multi-Head Attention에서만 수행
Softmax함수 적용
- 기존 Attention 계층과 마찬가지로 가중치로 사용하기 위해 수행
- 가중치와 Value 행렬을 행렬 곱하여 새로운 Value 행렬을 생성
- 기존 Attention 계층에서
맥락벡터(C)를 구하는 것과 동일
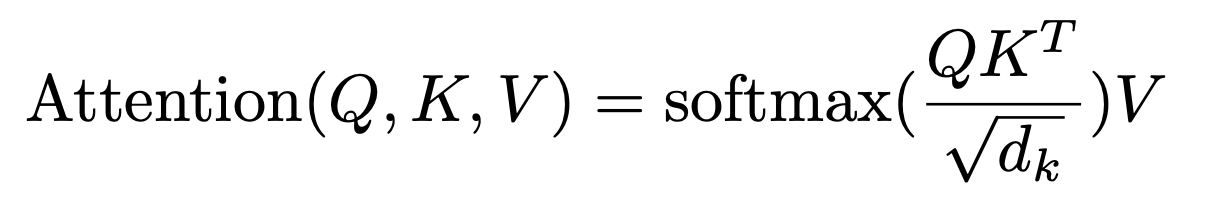
- Input은 Query
- dk 차원의 Keys
- dv 차원의 Values 구성
논문에서는 Dot Products는 크기를 키우고, 큰 dk 는 좋지 않은 영향이 있을거라고 주장한다.
Masking
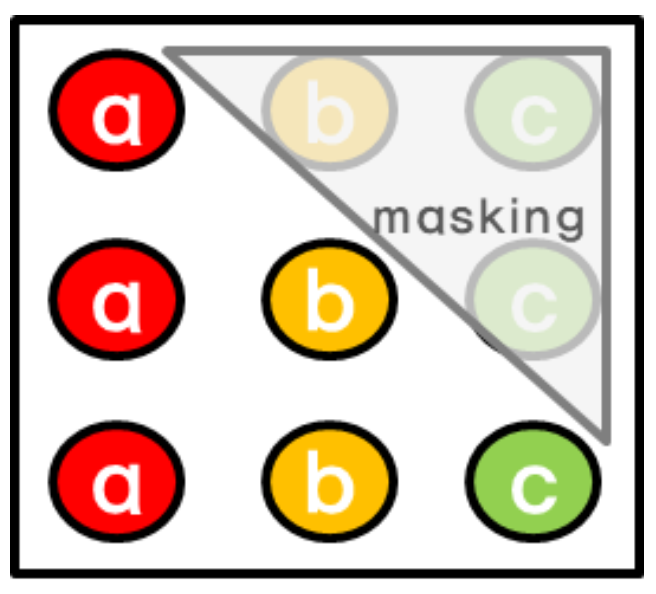
- 마스킹이란, 해당 시점 이전의 정보만을 참고하기 위해 수행하는 과정을 의미한다.
- 기존 RNN 모델들은 앞에서부터 하나씩 순차적으로 입력했었는데, Transformer부터는 문장 하나를 동시에 입력으로 진행하기 때문에 뒤 단어(본인이 예측하는 단어)를 같이 입력을 받게 된다.
-> Attention에서의 입력은 모든 시점의 정보가 입력된다.
- 마스킹 과정을 하지 않는다면, 뒤 정답이 있는 채로 예측을 하게 되기 때문에 이를 방지하기 위해 Decoder에서 수행하게 된다.
마스킹하는 방법은 다음과 같다.
- 입력 받은 행렬에서 본인 시점 이후의 값을 모두 -♾️로 변경
- 변경한 후 Softmax 함수를 적용하게 되면 변경된 값이 모두 0이 된다. 즉, 가중치가 0이 된다.
가중치가 0이기 때문에 실제 계산에서는 제외된다. 즉, 마스킹 과정을 통해 본인 시점 뒤에 값는 전부 사라지는 효과가 있다.
3.2.2 Multi-Head Attention
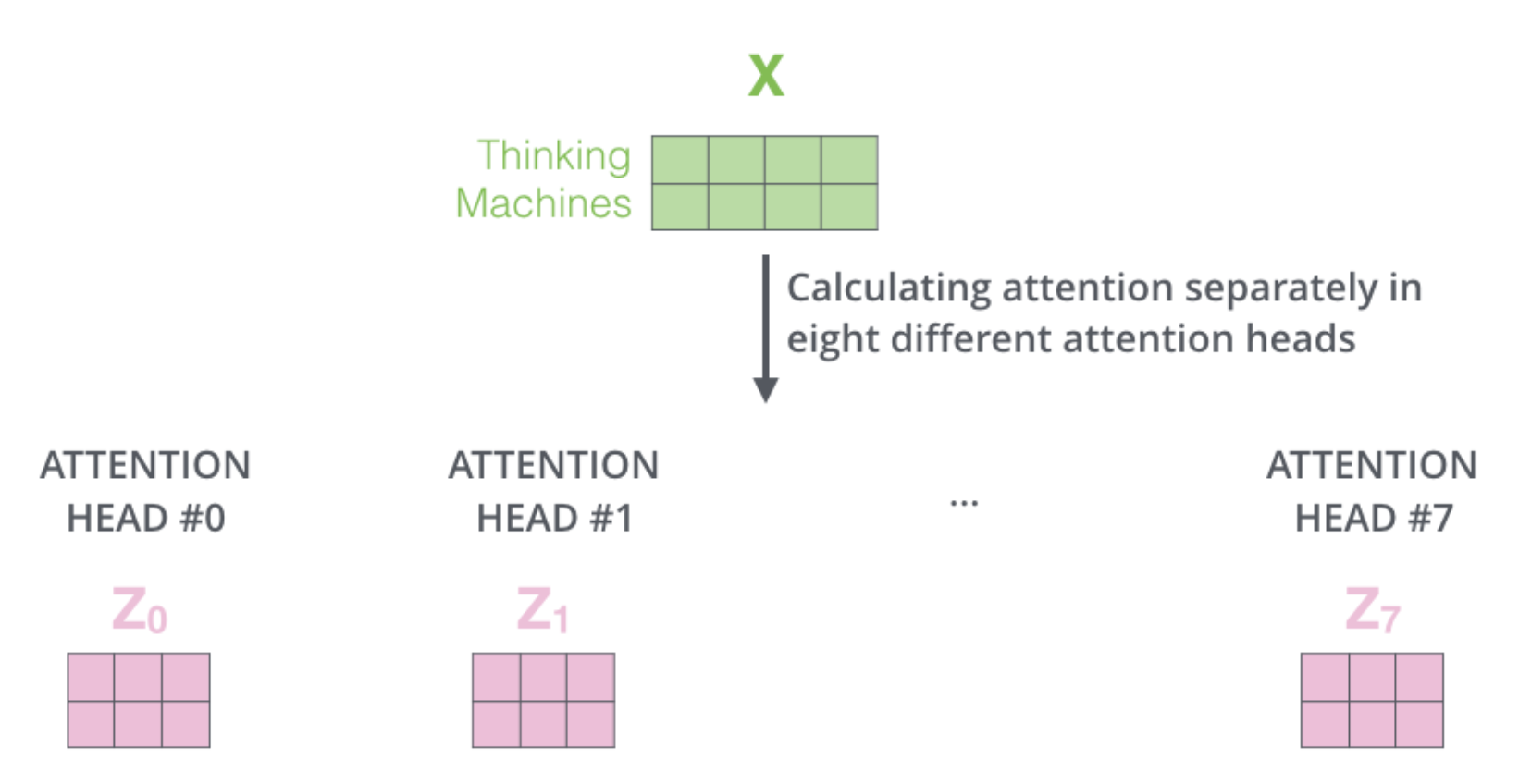
1) 동일한 self-attention 계산을 서로 다른 가중치 행렬로 8번만 수행하면 결국 8개의 서로 다른 가중치 행렬이 생성된다.
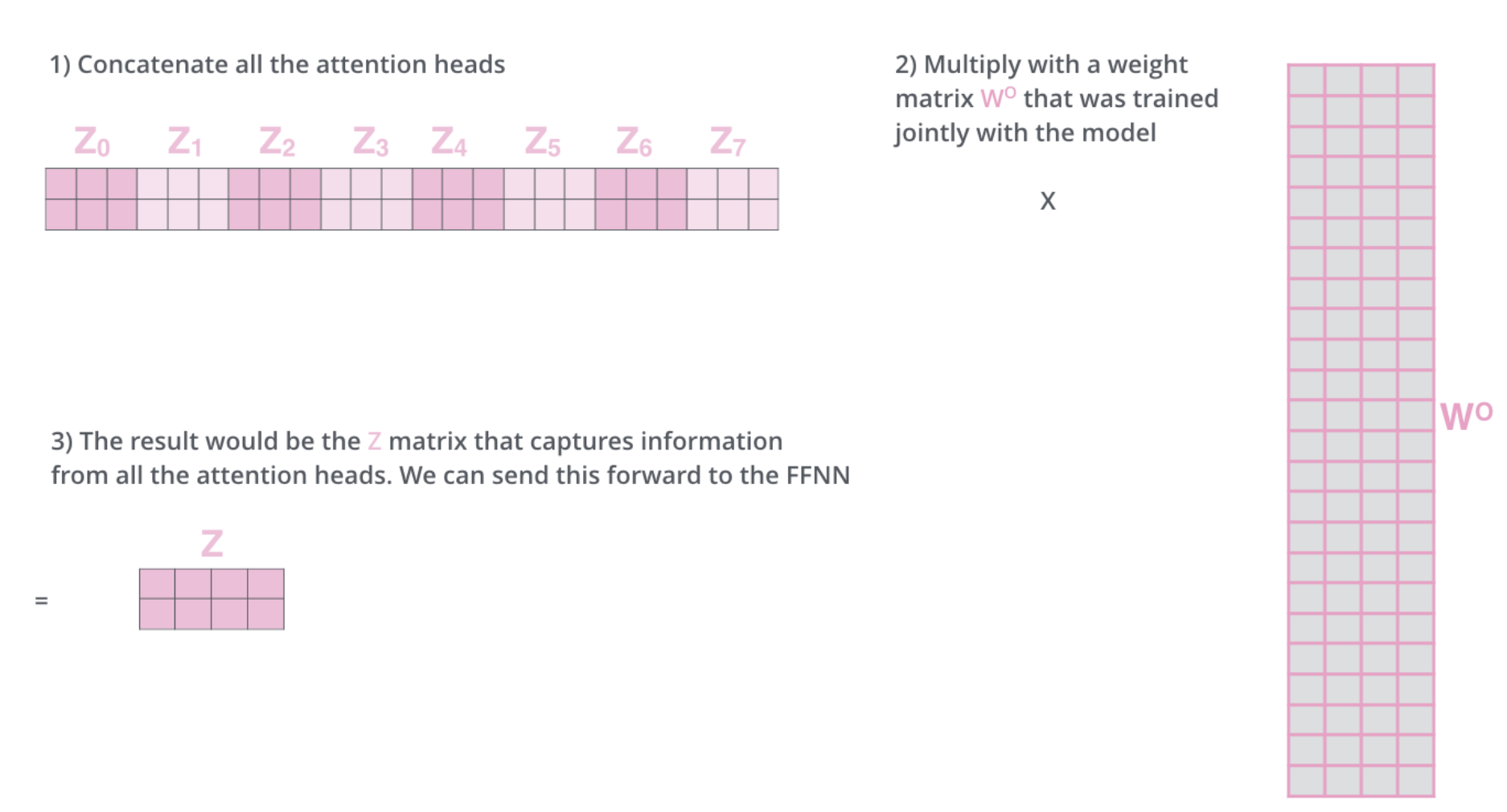
2) 각각의 개별적인 attention을 8개 만들어서 Concatenate을 한다.
- Concatenate한 행렬의 컬럼수를 갖고, 원래 Input Embedding과 같은 차원의 행을 갖는 W0 matrix를 설계할 수 있다. 이는 trained jointly with the model로 즉, Wk, WQ, Wv처럼 모델 학습 과정에서 같이 학습되는 모델이다.
- 이렇게 하면, 우리가 처음 갖고 있었던 Input Embedding의 Dimension과 동일한 Dimension을 갖는 self-attention의 Output을 만들어낼 수 있다.
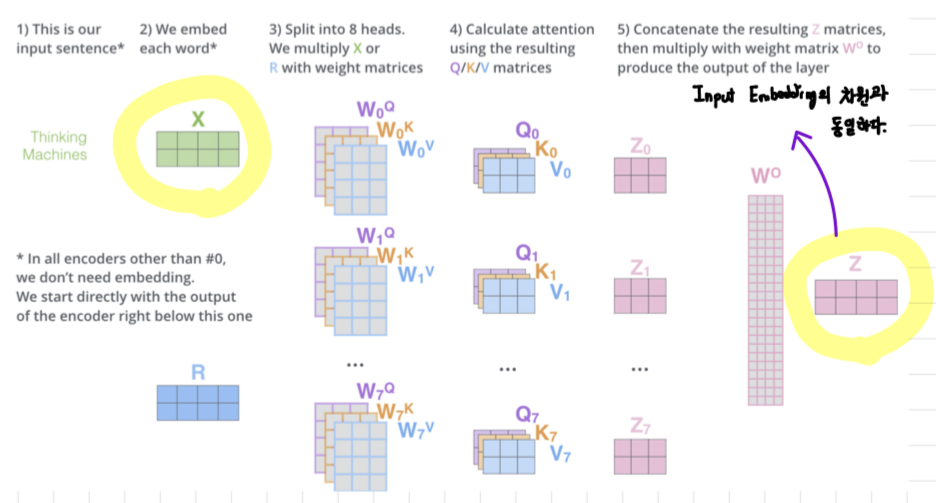
3) 전체적인 과정 요약
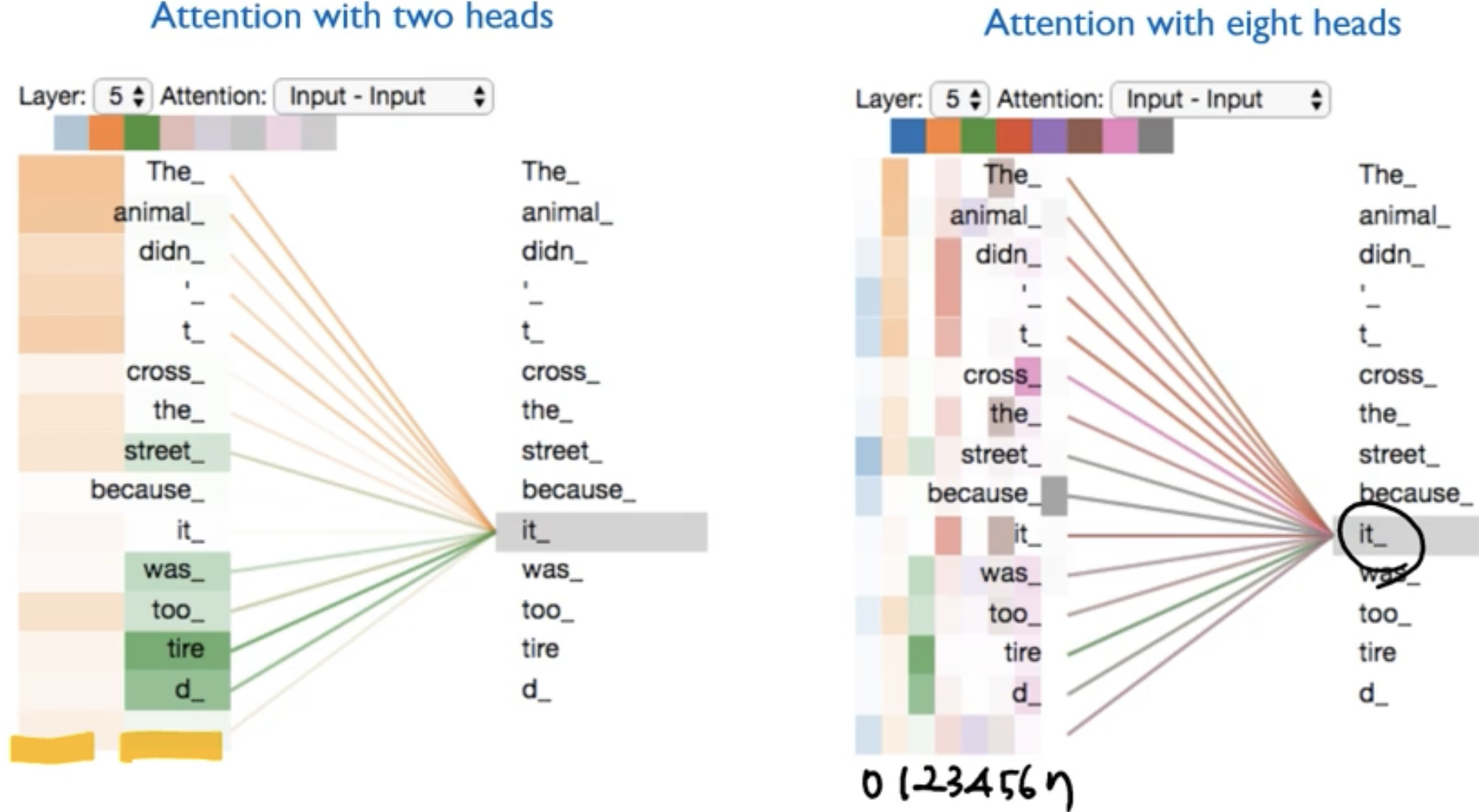
Multi-headed Attention(2개) vs Multi-headed Attention(8개) 비교
- Multi-headed 개수에 따라 scoring이 달라진다.
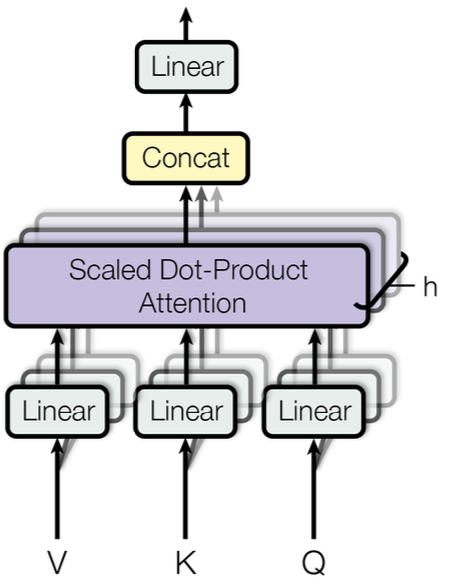
Multi-Head Attention 계산 순서는 다음과 같다.
- 입력된 Query, Key, Value 갑에 각각 다른 가중치를 곱한다
- 각각 총 h개씩 곱하여 Query, Key, Value를 생성
- 서로 다른 가중치를 h개 곱해줘서 서로 다른 행렬 h개를 만들어낸다.
- h개 생성된 Query, Key, Value를 각각 Scaled Dot-Product Attention을 수행
- 총 h번 수행되는 것이며 출력 역시 새로운 Value 행렬 h개가 출력
- h개의 새로운 Value 행렬을
Concat
- Scaled Dot-Product Attention을 거친 h개는 모두 형상이 동일하므로 옆으로
이어붙히기 가능
출력 형상을 조정하기 위해 가중치 행렬과 행렬 곱
- 출력 형상 조정을 위한 과정이며
가중치 행렬은새로운 가중치

- h=8로 병렬 수행하였고 각 Head의 차원 줄이기 위해서 dk=dv=dmodel/h=64
- 총 연산 비용은 Single-Head Attention과 유사
Skip-Connection (Residual) + Add & Norm
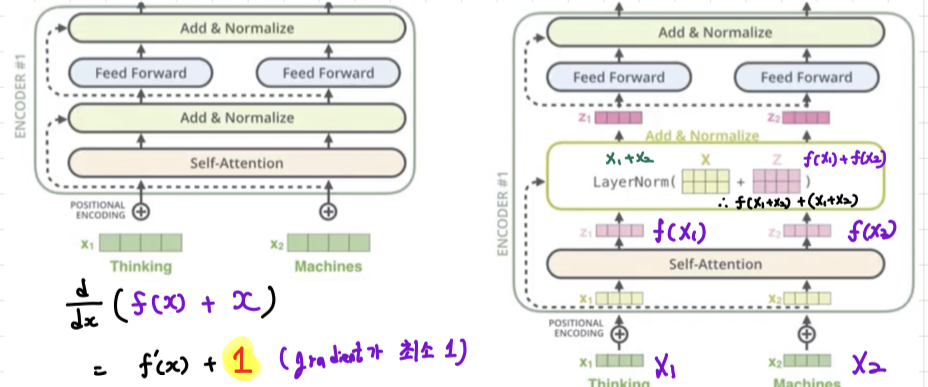
-
Residual Block: Resnet에 나온 개념으로 입력의 input(x)과 self-attention 값 (f(x))을 더해주는 것이다. (= f(x) + x)
이렇게 하는 이유는 미분을 했을 때, f'(x)가 값이 작아져도 gradient가 최소 1만큼을 흘러보낼 수 있다는 장점을 가지고 있어서 학습할 때 매우 유용하다. -
이 후 LayerNorm을 거친 뒤, Feed Forward에 input으로 들어갈 z1과 z2가 만들어진다.
-
모든 Encoder와 Decoder Block에 Residual connection과 LayerNormalization은 계속적으로 수행한다.
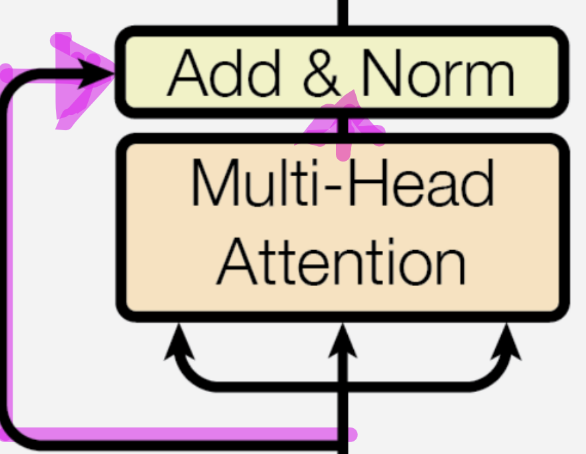
Multi-Head Attentiond에서 출력 형상을 조정하는 이유는 무엇일까?
Skip-Connection과 Add & Norm을 거치기 위해서 Multi-Head Attention에서 출력 형상을 조정하게 된다.
- 위의 그림에서 Multi-Head Attention의 입력되는 행렬을 Multi-Head Attention을 Skip해서 Multi-head Attention의 출력과 더해주는 것을 볼 수 있다.
- 왼쪽 분홍색 형광색 친 부분이
Skip-Connection을 의미한다.
- Skip-Connection을 적용하기 위해서는 두 행렬의 형상이 동일해야 한다. (입력되는 행렬과 Skip 행렬)
Add: Skip-Connection 행렬 + Multi-Head Attention의 출력 행렬
Norm: Add한 행렬을 정규화(Layer Normalizaiton
이 둘을 하는 이유는 Scaling과 같이 기울기 소실 문제를 해결하기 위해서이다.
Layer Normalizaiton
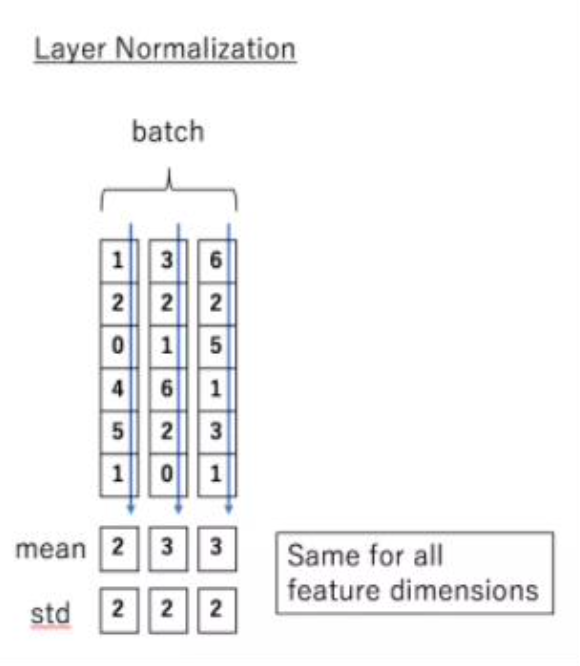
입력 데이터마다 평균과 분산을 활용하여 데이터의 분포를 정규화하는 과정을 의미한다.
- 기존에 Batch Normalization은 입력하는 문장마다 단어의 갯수가 달라서 batch의 값이 계속 바뀌게 된다. 하지만 Transformer는 문장을 한번에 입력하기 때문에 입력 문장 길이를 가변화할 수 있다.
- Ex) I'm a student 가 있다고 하면 입력 데이터마다 정규화 할 수 있는데,
I -> 정규화..
am -> 정규화..
a -> 정규화..
student -> 정규화..
문장의 길이가 변하더라도 정규화를 쉽게 할 수 있다.
3.2.3 Applications of Attention in our Model
- Query는 이전 Decoder 계층에서 나오고 Key와 Values는 Output에서 나온다. 이를 통해 Decoder의 모든 Position이 Input Sequence의 모든 Position에 참석 가능(전형적인 seq2seq 방식과 동일)
- Encoder에는 Self-Attention Layers가 포함된다. 이 Layer에는 모든 Key, Value, Query가 동일한 위치에서 나온다.
- Decoder의 Self-Attention Layers는 Decoder의 각 위치가 해당 위치까지 Decoder의 모든 위치에 주의를 기울일 수 있도록 한다.
3.3 Position-wise Feed-Forward Networks
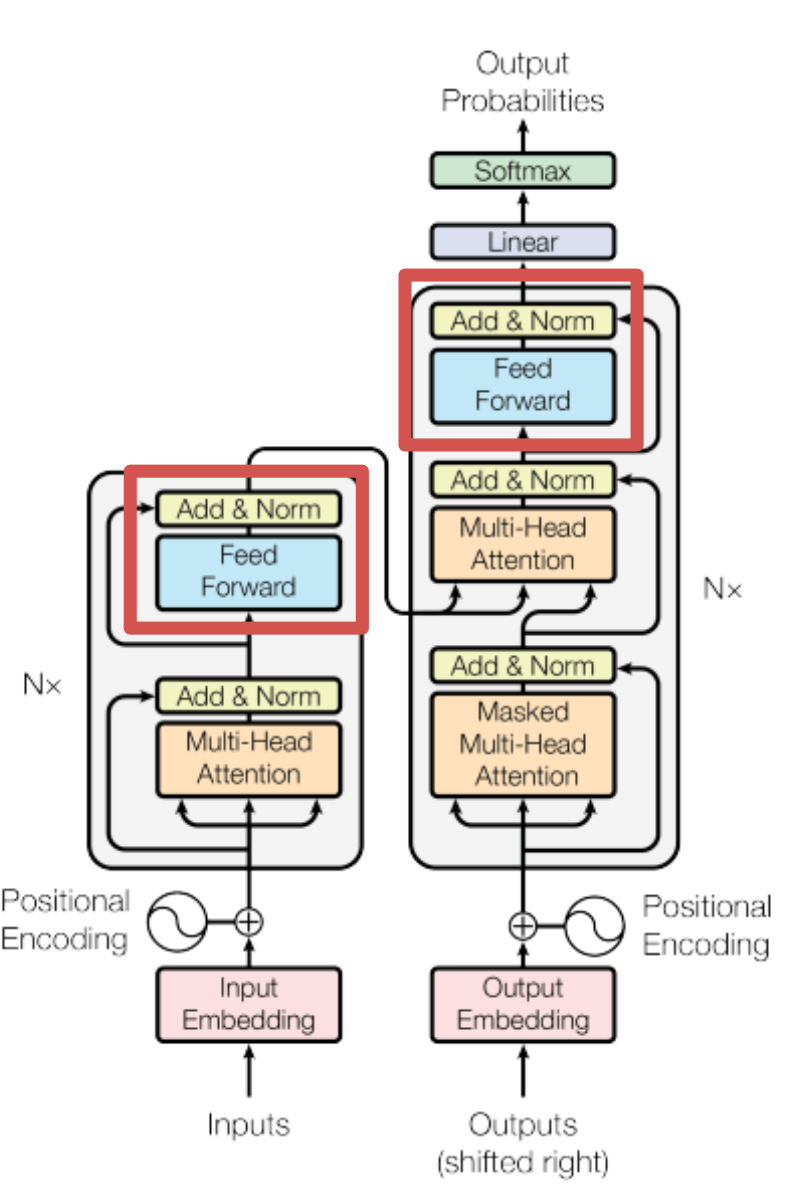
Feed Forward의 계산식은 다음과 같다.
- 입력된 행렬을 Fully-Connected Layer를 거친다.
- ReLU 함수 적용
- 다시 Fully-Connected Layer 거친다.
Feed Forward는 왜 하는걸까...?
- 이 과정에서 Fully-Connected Layer를 거치면서 차원을 키운다. 즉, 좀 더 다양한 정보를 행렬에 담을 수 있기 때문에 Feed Forward를 거치게 된다.
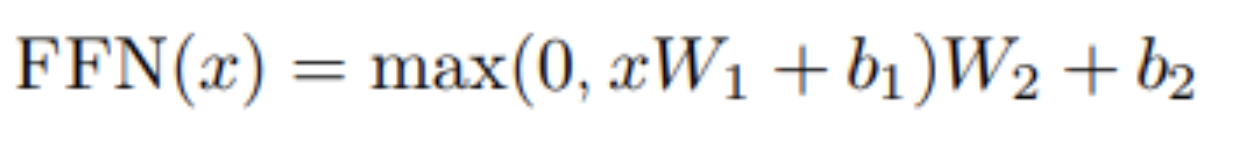
- 위 식을 수행하는 것이 Feed Forward 계층
- input and output dimensionality는 dk=512
- inner-layer는 dff=2048
3.4 Embeddings and Softmax
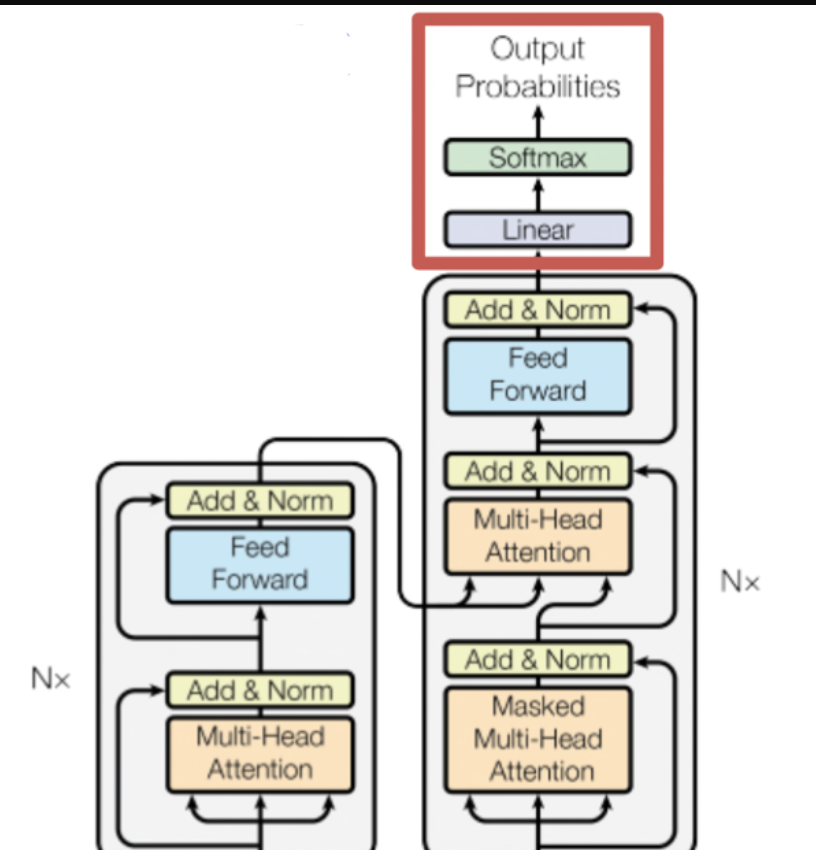
- 최종 입력으로 Decoder의 출력을 Softmax 함수를 통해 확률로 변환하고 각 단어의 확률을 예측한다.
- 다른 Sequence Transduction Models과 마찬가지로, input tokens와 output tokens를 dmodel 차원의 vectors로 변환하기 위해
Learned Embedding을 사용한다.
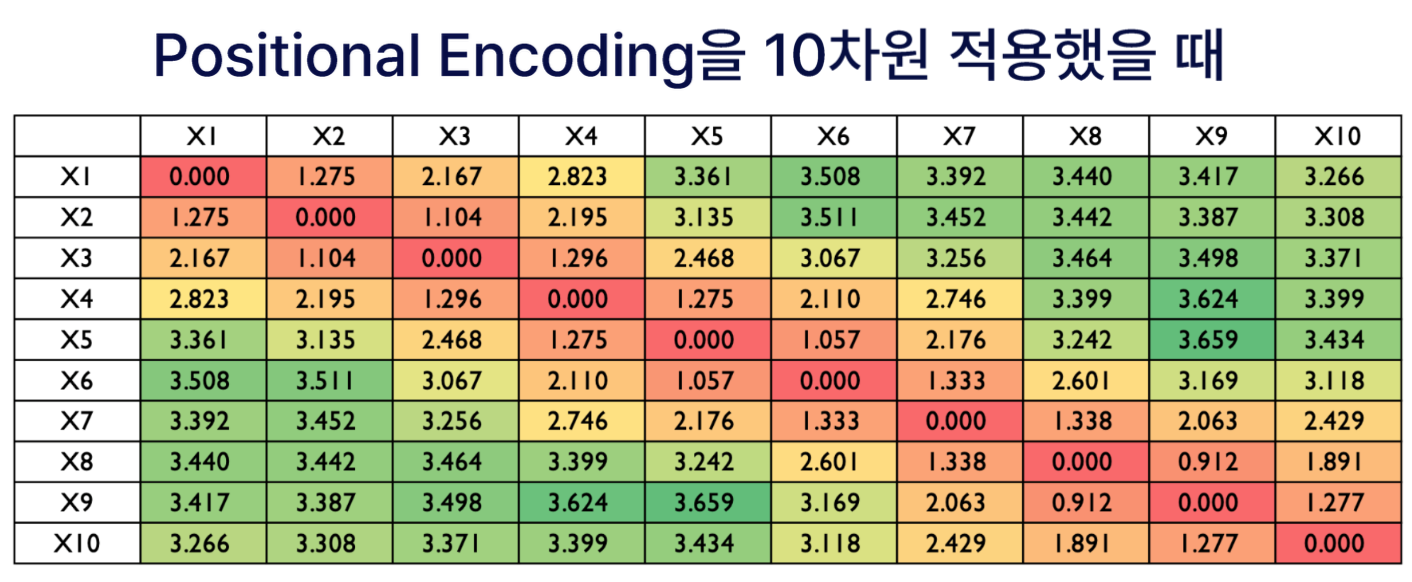
3.5 Positional Encoding
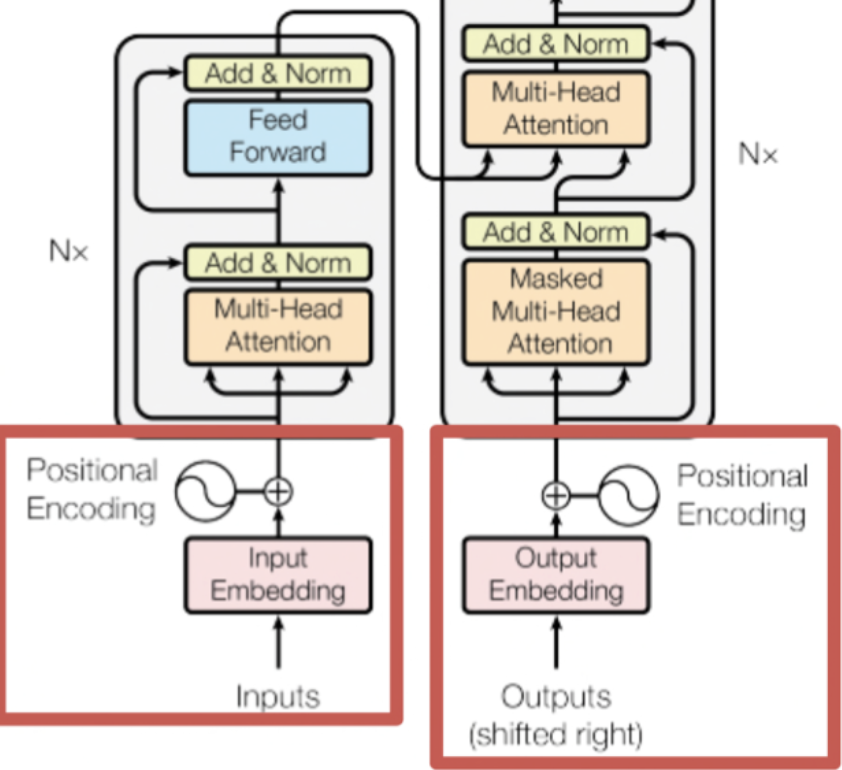
- 최초 입력으로 Encoder와 Decoder에 입력한다.
- 이때 Embedding 과정을 거쳐 단어가 입력되는데 이때
Learned Embedding을 사용한다.Learned Embedding이란 embedding 값을 고정해두는 것이 아닌, 학습 과정에서 가중치를 업데이트 하듯이 계속하여 갱신해 나가는 방식을 의미한다.
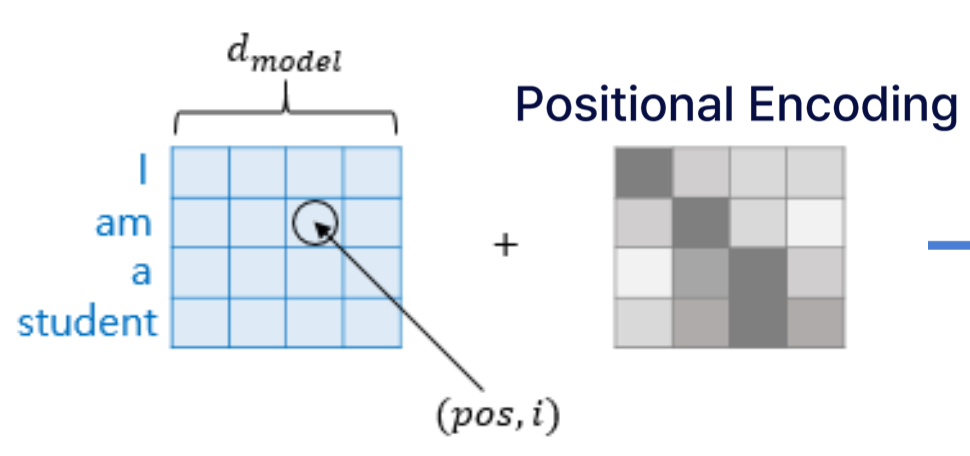
위의 그림 아래를 보면, Positional Encoding이라는 개념이 나온다. 이것은 무엇일까?
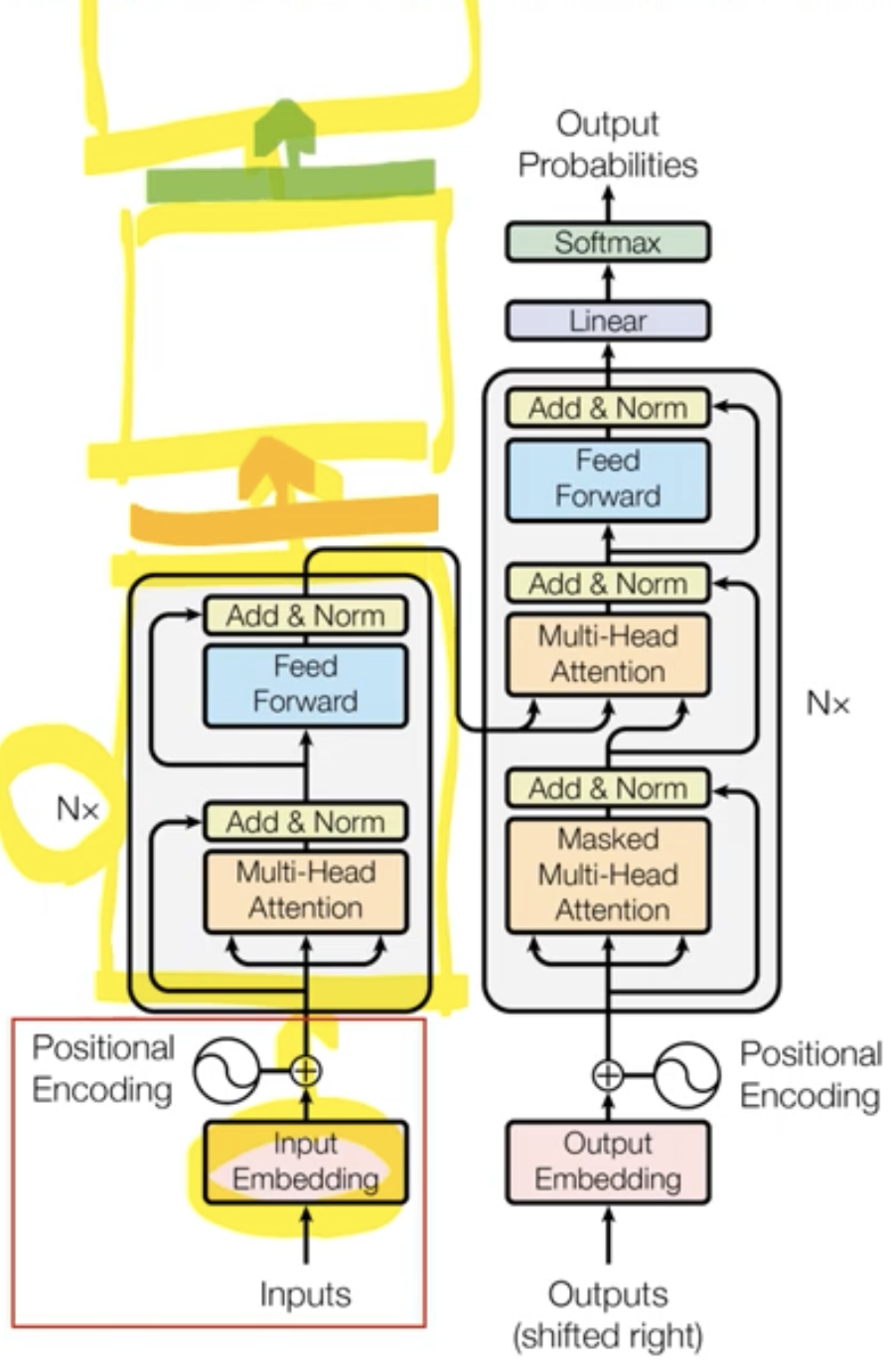
위의 그림의 왼쪽 Encoder Block에서의 N=6인데, 이것을 풀어서 그리면 Encoder Block이 6개 쌓아진다. 여기서 첫번째 Encoder Block에서만
Input Embedding이 그대로 들어가게 되고, 실질적으로 두번쩌 Encoder Block에서의 Input은 첫번째 Encoder Block에서의 output이 들어가게 된다는 것이다.
지금까지의 RNN은 하나의 sequence만 들어갔기 때문에 어떠한 단어가 언제 들어왔는지에 대한 정보를 알 수 있었다. 하지만 Transformer는 한번에 전체 sequence를 집어넣기 때문에 어떤 단어가 몇번째에 위치 되어있는지에 대한 정보를 손실 될 수 있다.
그래서 그 정보를 완벽하게 복원을 하지는 못하더라도 각각의 단어가 가지고 있는 위치 정보를 보존해주자는 목적으로 만들어진 것이 `Positional Encoding이다. 즉, 단어 Input의 sequence에서의 단어의 순서를 어느정도 고려해주는 것이 목적이다.
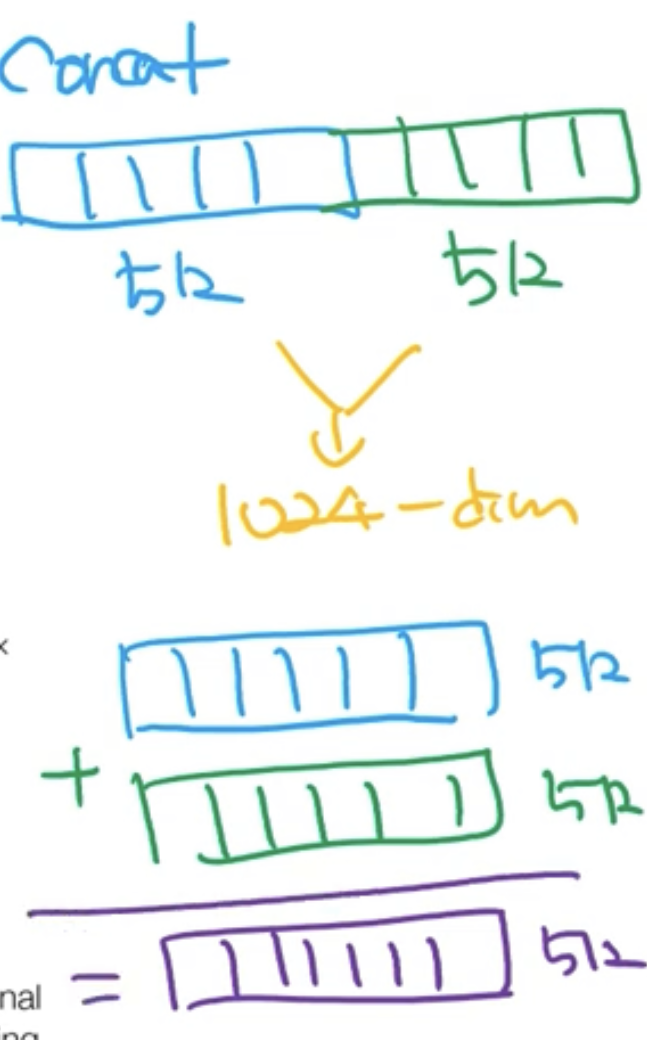
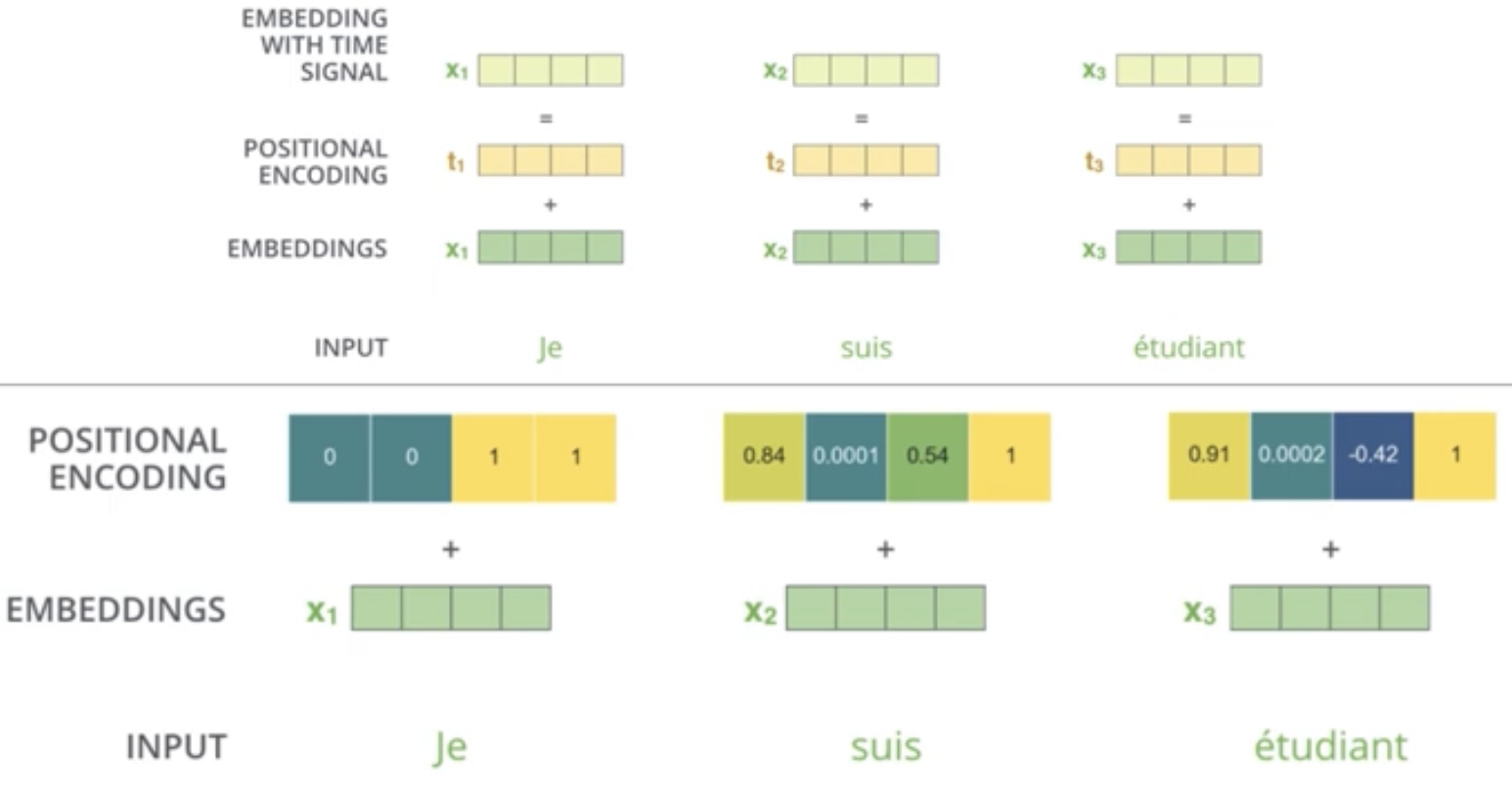
Input Embedding과 Positional Encoding을 concat이 아닌 더해준다.
아래 그림과 같이 concat은 512차원의 벡터를 옆으로 붙어주기 때문에 1024차원의 벡터가 만들어진다. 하지만 더한다는 개념은 말 그대로 같은 차원의 벡터를 각각의 위치끼리 더해서 결과물도 같은 차원의 벡터가 되는 것이다.
- Transformersm 모델 자체에서는 어떤 것이 앞에 있고, 뒤에 있고를 구분할 수 없는데 Positional Encoding을 통해
위치 정보를 추가할 수 있다.
- 다른 RNN 계열의 모델과 달리 Transformer는 문장을 단어별이 아닌
문장 전체로 한번에 학습시키고 이로 인해 병렬 처리가 가능해졌다.
-> 즉, 순서 정보가 사라지기 때문에 순서 정보를 추가하기 위해 Positional Encoding을 추가한다.
- 위의 그림에서 보면 'I, am, a, student'은 Embedding을 거쳐서 나온 행렬이고, 이와 같은 크기의 Positional Encoding 행렬을 단순히 더해준다.
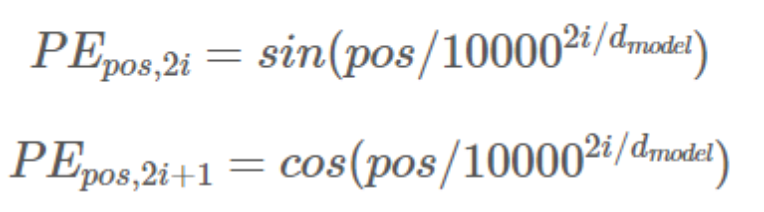
계산 수식은 다음과 같다.
- pos: 단어 번호
- i: 단어의 Embedding 값의 위치
- 다음 함수를 통해 순서 정보를 계산 후 계산된 값을 Embedding 행렬에 더해준다.
이때 sine / cosine 함수를 사용하는데, 그 이유는 무엇일까?
- 각각의 고유한 토큰 위치 값은 유일한 값을 가진다.
-> 전부 값이 달라야 이 값이 어디에 위치해 있는지 알 수 있다.
- 서로 다른 두 토큰이 떨어져 있는 거리가 일정해야한다.
-> 떨어진 정도가 같아야 입력을 할 때, 정보 손실이 일어나지 않는다.
최종 정리하면
1) 각각의 Input에 대한 Embedding과 Positional Encoding을 서로 더해준다.
2) 새로운 Embedding with Time Signal을 만들어준다.
- 그래서 Positional Encoding을 왜하는 것일까?
Transformer는 한번에 모든 sequence를 입력 받기 때문에 단어가 가지고 있는 위치 정보를 고려하지 못하는 단점이 있다. 그래서 단어가 가지고 있는 위치정보를 최대한 반영하고자 하는 장치를 마련햊기 위해 Positional Encoding을 하는 것이다.
- 좋은 Positional Encoding vector가 가져야 하는 조건은?
1) 해당하는 Encoding vector 자체의 크기는 동일해야한다.
2) 위치 관계를 표현하고 싶기 때문에 두 단어 간의 거리가 실제로 input sequence에서 멀어지게 되면 이 둘 사이의 posional encoding 사이의 거리도 멀어져야 한다.
-> The further the two positions, the larger the distance
4. Why Self-Attention
- 결론적으로 말하면, 연산량이 적고 속도가 빠르다는 장점이 있기 때문에 Self-Attention을 사용한다.
1.layer별 총 연산의 complexity
2.필요한 최소 sequential operations으로 측정한 병렬처리 연산량
3. Network에서 long-range dependencies 사이 path length
-> long-range dependencies의 미치는 한가지 요소는 forward 및 backward signal의 길이이다.
-> Input의 위치와 Output의 위치의 길이가 짧을수록 dependencies 학습은 더욱 쉬워진다.
-> 서로 다른 layer types로 구성된 네트워크에서 input과 output 위치 사이 길이가 maximum 길이를 비교한다.
4.1 Self-Attention 등장 배경
- 기존 Attention 계층과는 다르게 Encoder or Decoder의 정보 교류 없이 단독으로 계산된다.
-> Self-Attention의 등장
4.2 Self-Attention 구조
1) 기존 Attention
- 특정 시점의 Decoder의 hidden state(h)
-> LSTM을 거쳐서 나온 h벡터1번: Query 라고 부른다. (Q)
- 모든 시점의 Encoder의 hidden state(hs)
-> 벡터의 중요도를 계산할 때 사용한 hs 행렬2번: Key 라고 부른다. (K)
- 모든 시점의 Encoder의 hidden state(hs)
-> 최종적으로 맥락벡터(C)를 구할 때 사용한 hs 행렬
-> 여기서 Key와 Value는 동일한 행렬3번: Value 라고 부른다. (V)
2) Self-Attention
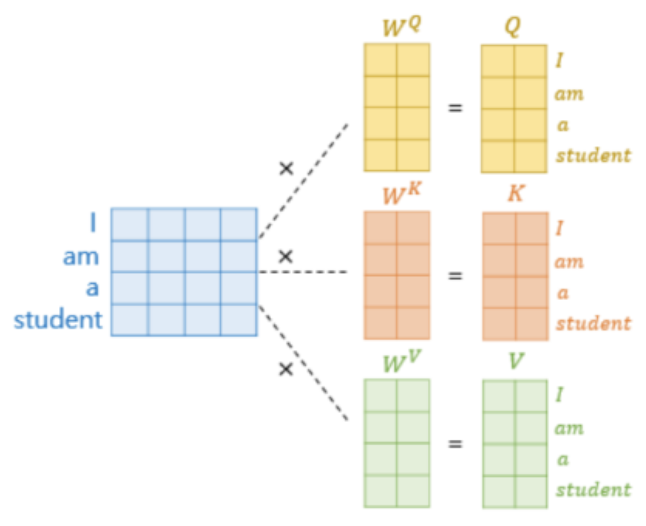
- 해당 부분은 위의 기존 Attention과 달리 입력 정보가 혼합되어 입력되지 않는다.
-> 즉, 하나의 입력으로부터 Query, Key, Value 3개를 만들어낸다.
Idea: 하나의 행렬에 서로 다른 가중치 합을 통해 3개로 나눌 수 있다.
- 위의 그림은 각각 서로 다른 가중치로 스스로의 입력만으로 Attention을 계산하였다. (Self-Attention)
- Attention에서 나온 개념이기 때문에 앞에 Attention과 연결 짓는다면 도움이 될 것이다.
5. Training
5.1 Training Data and Batching
- 약 450만 개의 문장 쌍으로 구성된 표준 WMT 2014 영어-독일어 데이터셋으로 학습 진행
- 문장은 약 37,000개의 바이트 쌍 인코딩을 사용
- WMT 2014 영어-프랑스어 데이터 셋 사용
- 토큰을 32,000개의 단어 조각 어휘로 분할
5.2 Hardward and Schedule
- 8개의 NVIDIA P100 GPU가 장착된 한 대의 머신에서 모델 훈련 진행
- 총 12시간 동안 기본 모델 훈련 진행
5.3 Optimizer
- β1 = 0.9, β2 = 0.98 and ε = 10−9 으로 Adam optimizer 사용
5.4 Regularization
- Residual Dropout 사용
->Dropout = 0.1
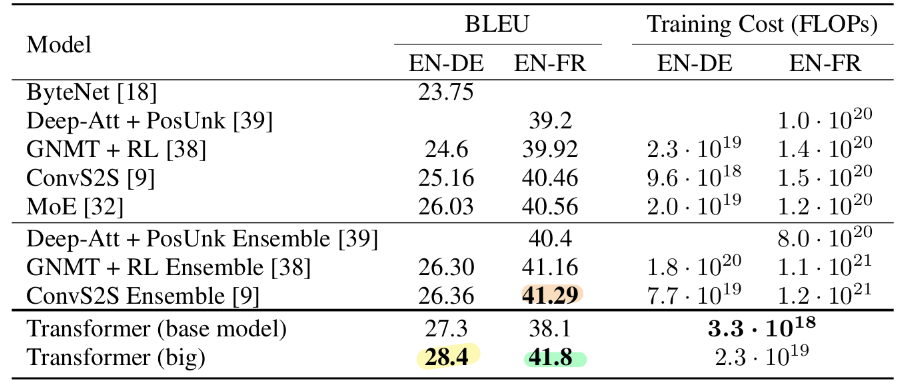
- 위의 그림은 Transformer를 통해 SOTA 달성한 것을 보여준다.
6. Results
6.1 Machine Translation
- 기본 모델 조차도 이전에 발표된 모든 모델의 앙상블을 능가하며, 훈련 비용도 훨씬 저렴하다.
6.2 Model Variations
- Transformer의 다양한 구성요소의 중요성을 평가하기 위해 기본 모델을 다양한 방식으로 변경하여 영어에서 독일어로 번역할 때의 성능 변화를 측정
- 단일 head-Attention은 최상의 설정보다 0.9 BLUE 더 나쁘지만, head 수가 너무 많으면 품질이 떨어진다.
- 위의 그림에서 key 크기 (dk)를 줄이면 모델 품질이 저하되는 것을 확인할 수 있다.
- 모델을 클수록 더 좋으며, Dropout이 오버피팅을 방지하는 데 매우 유용하다는 것을 확인할 수 있다.
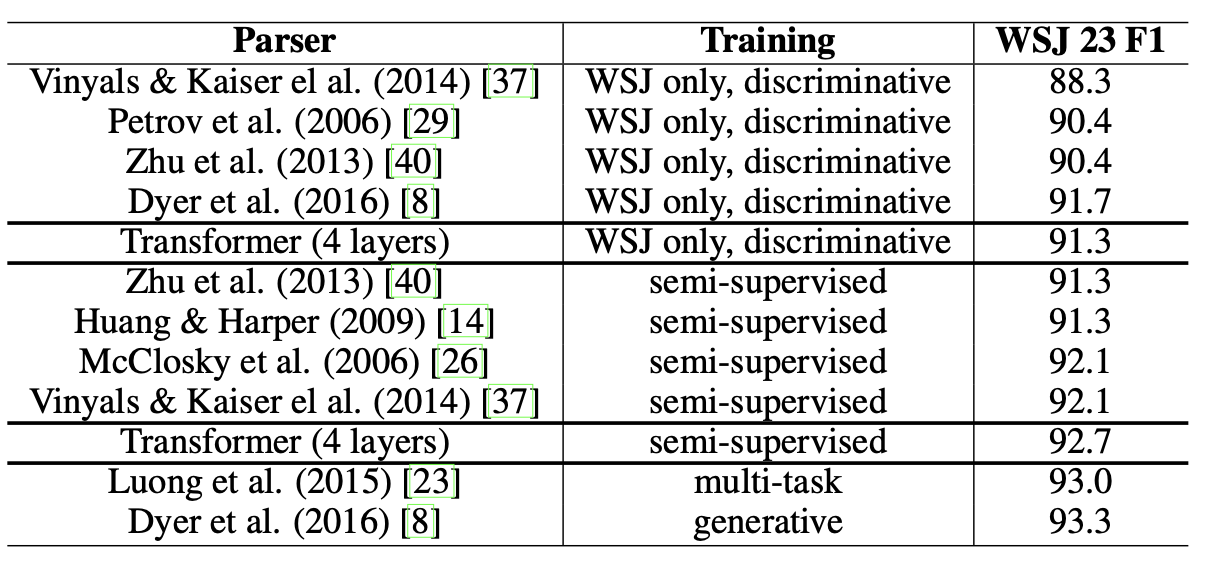
6.3 English Constituency Parsing
생략하겠습니다.
7. Conclusion
- 전적으로 Attention에 기반한 최초의 sequence transduction model이다.
- WMT 2014 영어-독일어 및 영어-프랑스어 번역 작업 모두에서 새로운 최첨단 기술을 달성
- Transformer를 통해 이미지, 오디오, 비디오와 같은 다양한 분야로 확장할 것이며 Attention을 연구할 계획
🎯 Summary
-
저자가 뭘 해내고 싶어 했는가?
-
이 연구의 접근 방식에서 중요한 요소는 무엇인가?
-
어느 프로젝트에 적용할 수 있는가?
-
참고하고 싶은 다른 레퍼런스에는 어떤 것이 있는가?
-
느낀점은?
지금까지의 논문 리뷰 중 제일 어려웠다. Encoder에서 시작되어 Decoder 구조까지.. 복잡하였다. 한 5번 정도 계속 보았고, 블로그랑 유튜브 등 다양한 자료를 찾아가면서 논문 리뷰 정리를 하였다. 사실 아직도 완전히 내 꺼로 만들지 못했다. 시간 날 때마다 Transformer 관련 영상이나 블로그 그리고 논문을 보면서 또 공부해야겠다.
Transformer는 NLP뿐만 아니라 CV, Rec에서도 최근 활발하다. 이를 기반으로 많은 모델이 만들어진만큼 이 논문은 정말 정말 시간 투자를 꼭 해야 된다. 다음은 Item2Vec, Doc2Vec이다. BERT 논문 리뷰를 하는 그 날까지..! 파이팅!
📚 References
- Ashish Vaswani,Noam Shazeer et a.l "Attention Is All You Need" arXiv preprint arXiv:1706.03762v5 (2017).
- https://welcome-to-dewy-world.tistory.com/108
- https://ynebula.tistory.com/51
- https://www.youtube.com/watch?v=mxGCEWOxfe8
- https://jalammar.github.io/illustrated-transformer/
- 고려대학교 산업경영공학부 DSBA 연구실(강필성교수님), https://www.youtube.com/watch?v=0kgDve_vC1o
