주제: CNN(합성곱 신경망)
- CNN은 특히 이미지 인식 분야에서 딥러닝 활용을 많이 한다.
- 지금까지의 신경망은 완전히 연결된 계층인 Affine 계층을 사용하였다. 하지만 CNN은 합성곱 계층(convolutional layer)과 풀링 계층(pooling layer)이 새롭게 등장한다.
0. CNN 모델의 발전

-LeNet: 최초의 CNN 모델
-CNN 다양한 모델은 추후 논문 리뷰를 통해 소개할 예정임
1. 합성곱 계층
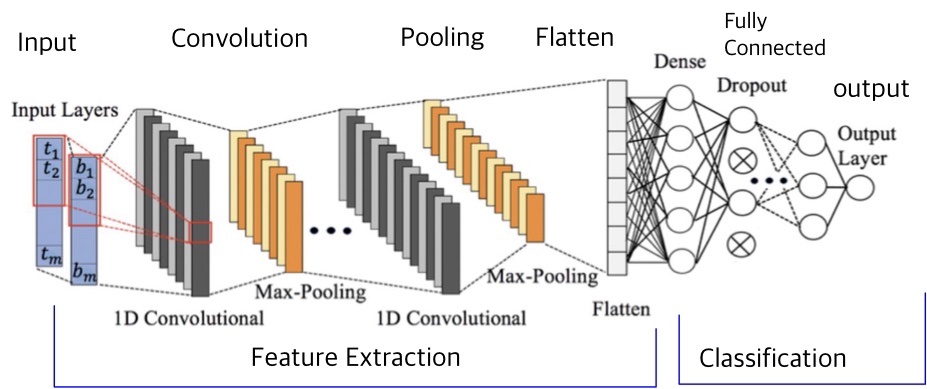
📚 출처: Negar Emami(2022.04.), 'Structure of the generic 1D-CNN built and trained by RC-TL',
ResearchGate,https://www.researchgate.net/figure/Structure-of-the-generic-1D-CNN-built-and-trained-by-RC-TL_fig2_363024811 (검색일: 2023.04.03.).
합성곱 계층은 Convolution 연산을 통해 이미지의 지역 정보(Region Feature, Graphic Feature)를 학습한다. 그리고 합성곱 계층은 이미지를 3차원 데이터로 입력받으며, 형상을 유지한다. 또한 다음 계층에도 3차원 데이터로 전달한다. 합성곱 계층의 입출력 데이터를 '특징맵', 입력 데이터를 '입력 특징 맵', 출력 데이터를 '출력 특징 맵'이라고 한다.
- Convolution Layer
: Region Feature를 뽑아내기 위한 계층- Pooling Layer
: Feature Dimension을 줄이기 위한 계층
- Fully Connected Layer
: 최종적인 분류를 위한 계층
1.1 완전연결 계층의 문제점
완전연결 계층에서는 인접하는 계층의 뉴런이 모두 연결되고 출력의 수는 임의로 정할 수 있었다. 하지만 '데이터의 형상이 무시'된다는 문제점을 가지고 있었다. 즉, 형상을 무시하고 모든 입력 데이터를 같은 차원의 뉴런으로 취급하여 형상에 담긴 정보를 살릴 수 없었다.
1.2 합성곱 신경망 등장 배경
-
신경망은 한 Input에 대하여 한 개의 노드를 사용하지만, Image는 그 Inpput의 숫자가 엄청 많다
ex) Image가 224 x 224인 경우, RGB channel을 다 고려하면 약 150,000개의 weight 필요하다 즉, 학습이 잘 안되거나, 오버피팅 발생 가능성이 증가한다. -
Shifted Image에 대해 학습이 잘 되지 않는다.(Image의 공간정보를 잘 활용할 수 없다)
요약
- 전통적인 Computer vision에서는 Image processing을 위해서 손수 Feature engineering을 했다.
- 이를 위한 기존 신경망 구조는 Image를 다루기에 부적합한 요소가 많다
- Image processing을 잘 하기 위한 CNN(합성곱 신경망) 필요
1.3 합성곱 신경망 개요

📚출처: https://towardsdatascience.com/basics-of-the-classic-cnn-a3dce1225add
-
컴퓨터가 Image를 보는 것과 사람이 Image를 보는 것은 차이가 있다.
-컴퓨터는 Image을 Pixel값으로 구성된 행렬로 인식한다 ex) 224X224X3(Height, Width,RGB)
-Pixel값은 0~225의 값 -
이러한 Pixel 값들을 연산, 처리하여 Output을 만들어 낸다.
-
합성곱 신경망의 첫 Layer는 대부분 Convolutional Layer이며 전체 Image를 좌상단부터 돌아가면서 축약해나간다
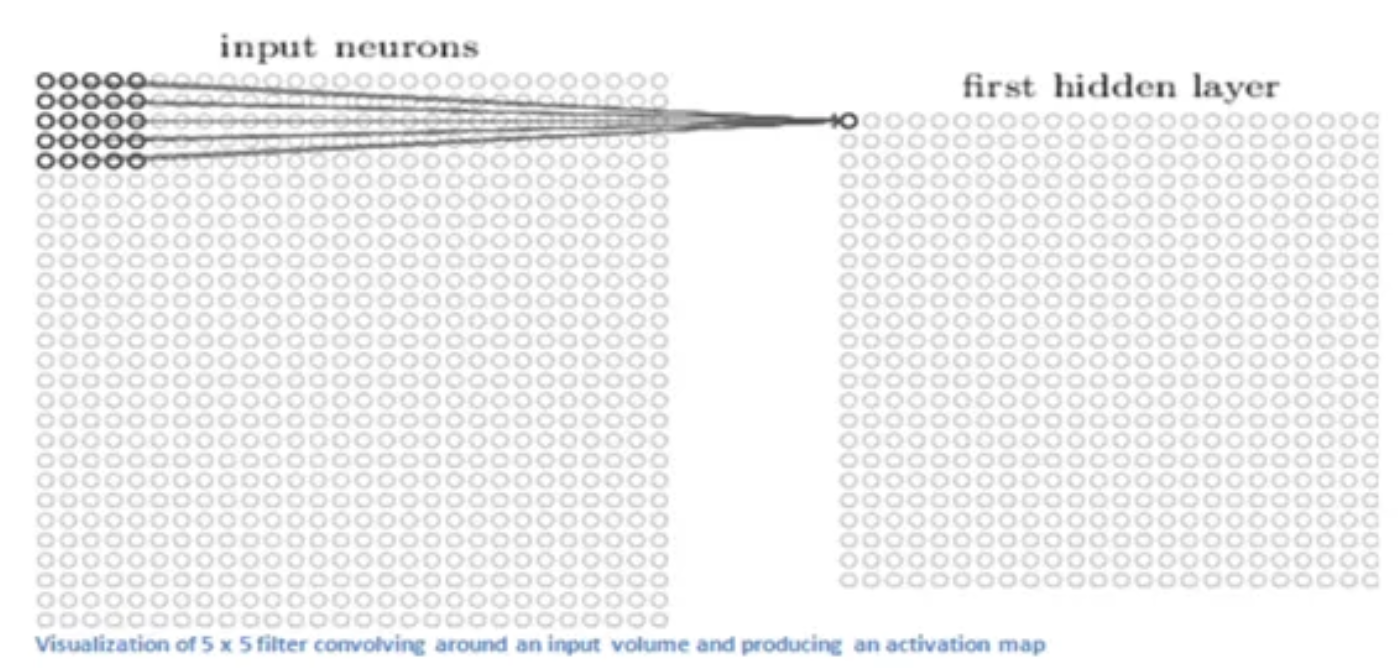
📚출처: https://towardsdatascience.com/basics-of-the-classic-cnn-a3dce1225add
1.4 합성곱 신경망 구성 요소
- Filter(Kernel)
- Preceptive field
- Stride
- Feature Map(or Activation Map)
- Channel
- Pooling
2. Filter
-
Image의 특징을 잡아내기 위한 detector의 역할을 수행한다.
ex) 비둘기를 보고 비둘기라고 판단하려면, 비둘기가 가지고 있는 특징을 우선 파악해내야 한다. (검은 색깔, 짧은 다리,목) -
Neural network 학습을 통해 Filter value를 학습한다.
-
곡선 부분에서는, 계산 시 큰 값이 나오게 된다.
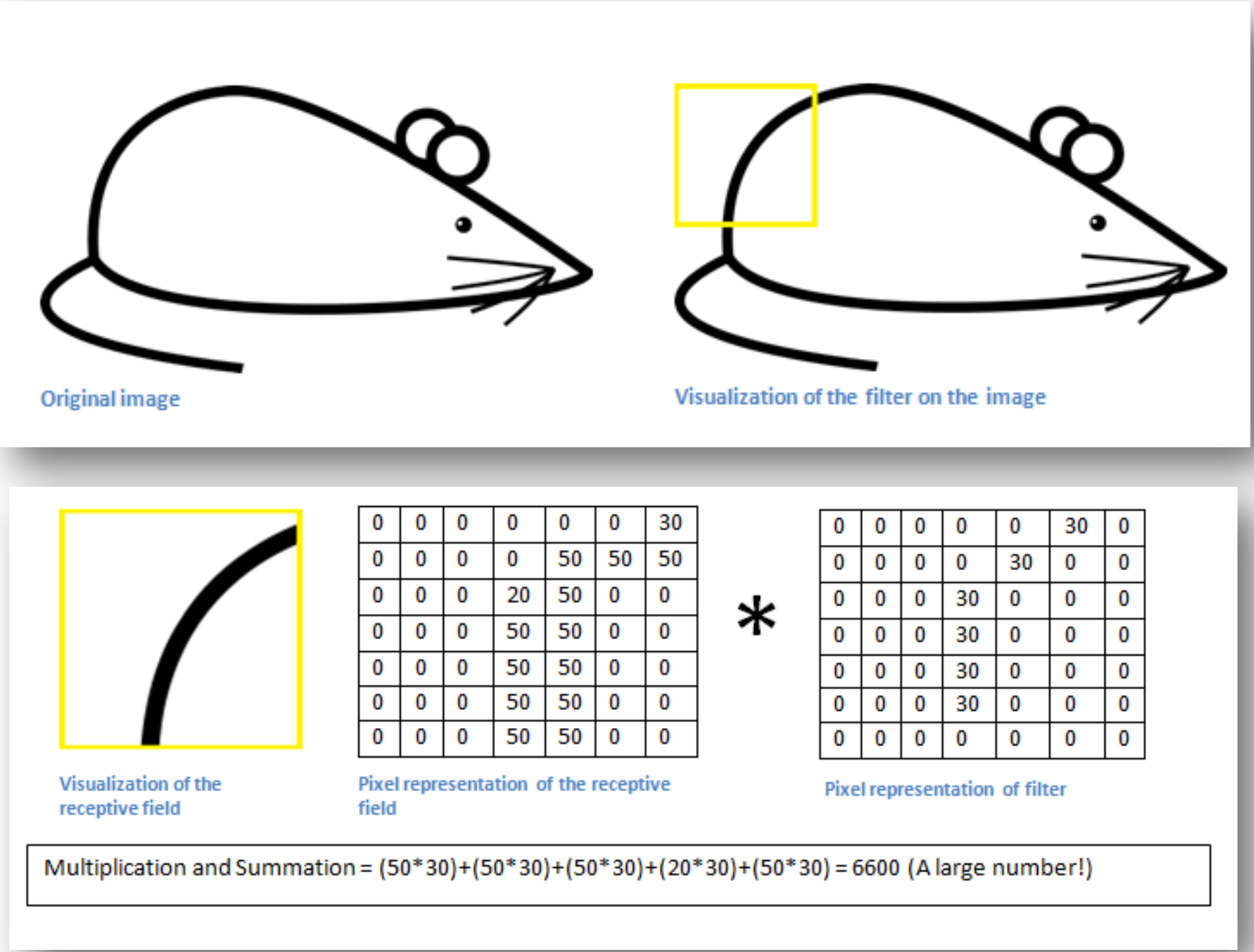
- Filter을 통한 합성곱 연산
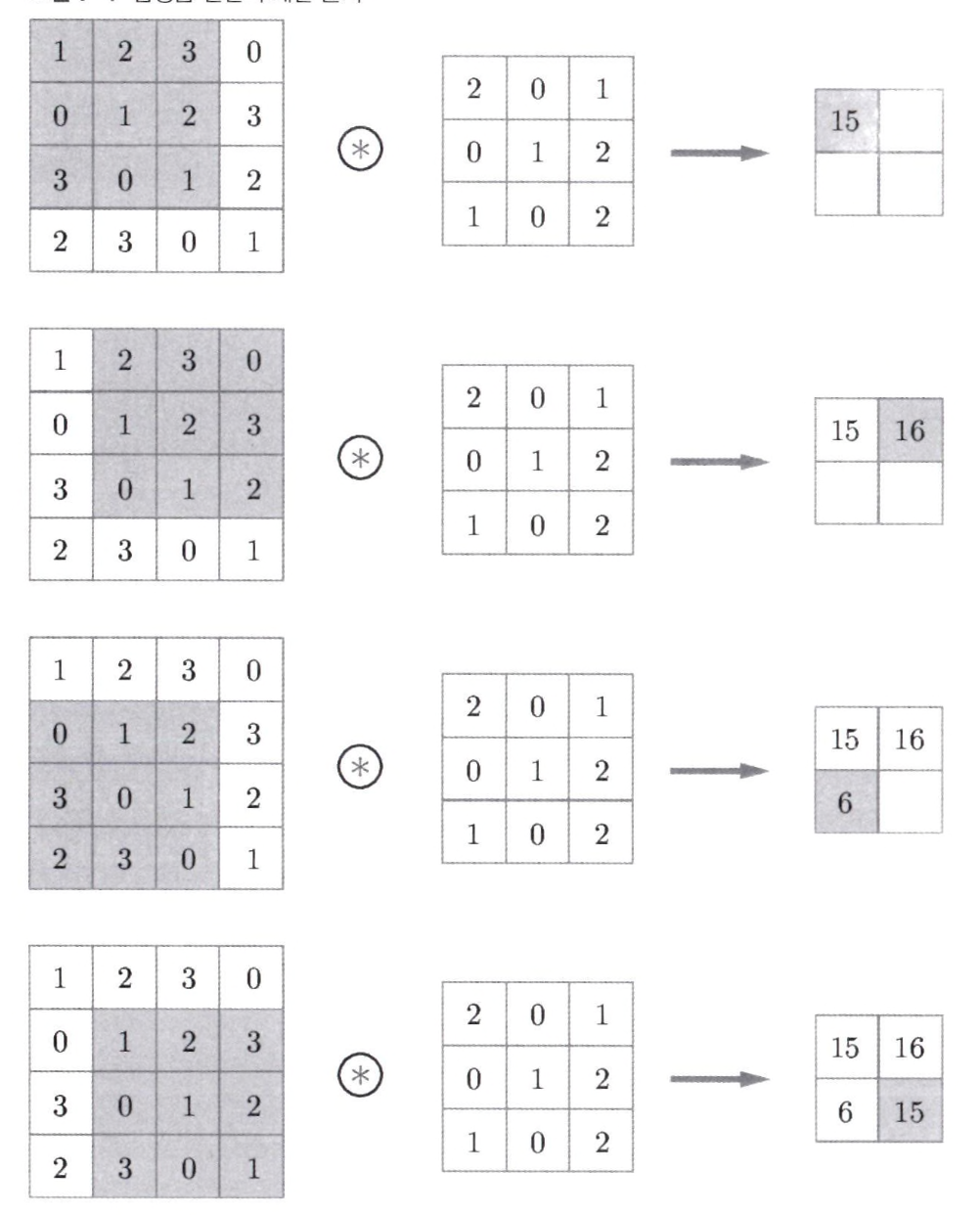
- 합성곱 연산은 입력 데이터에 필터를 적용한다. 문헌에 따라 필터를 커널이라 말하기도 한다. 필터는 이미지의 Region별 Feature를 찾아내기 위한 파라미터로 일반적으로 (3,3), (4,4)와 같은 정사각행렬로 정의한다.
- 윈도우(window)를 일정 간격으로 이동해가며 입력 데이터에 적용한다. 여기서 말하는 윈도우는 회색 3 x 3 부분을 가리킨다. Filter를 일정 간격만큼 이동하여 Input과 대응하는 위치의 원소끼리 곱한 후 그 총합을 구하는 연산을 한다.
🎯합성곱 연산 과정 영상을 보고 싶다면 이걸 클릭하세요!!🎯
📚출처: http://ufldl.stanford.edu/tutorial/supervised/FeatureExtractionUsingConvolution/
3. Receptive Field
- Feature를 만들어내기 위한 Input의 참고 영역(Filter의 크기)
- 어느 영억에서 참고하고 있는지를 보여준다.
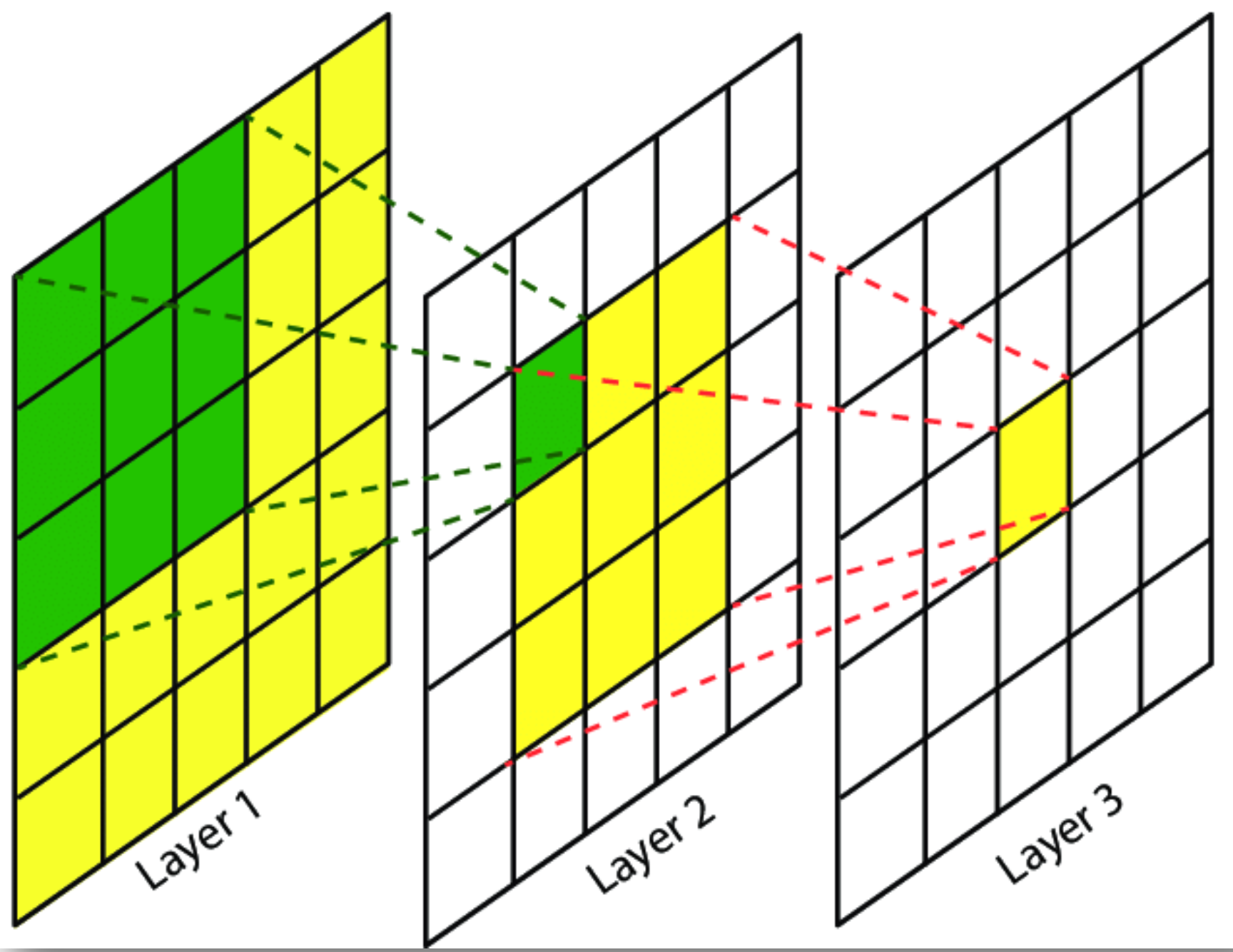
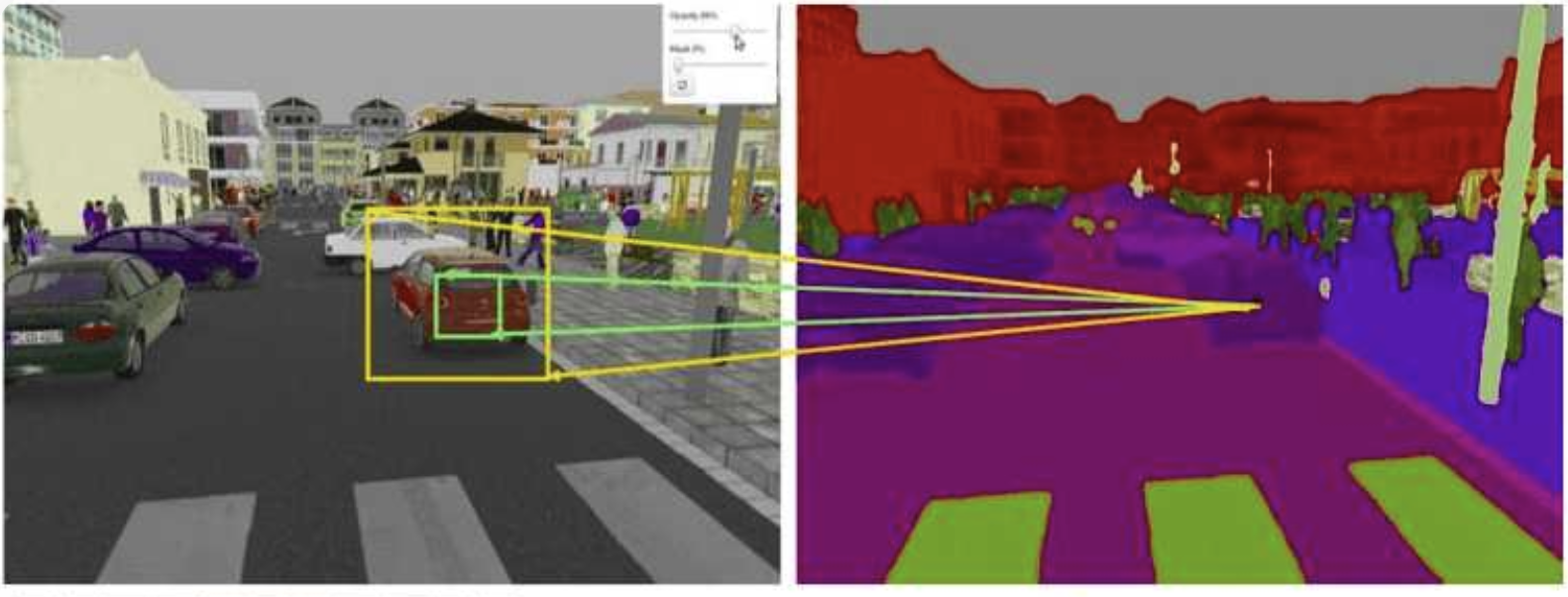
📚출처: https://theaisummer.com/receptive-field/
- 풀고자 하는 문제에 따른 적절한 크기의 Receptive Field를 고려해야한다. 만약, 객체의 경계를 예측하기 위해서는 모델이 객체의 관련 부분 전체에 대한 정보를 입력 받아야 한다. 위의 사진과 같이 자동차의 한 부분을 검출하려면, 자동차 전체에 대한 정보를 입력받아야 한다는 것이다.
4. Feature Map
- 합성곱 연산의 결과를 Feature Map이라고 한다.
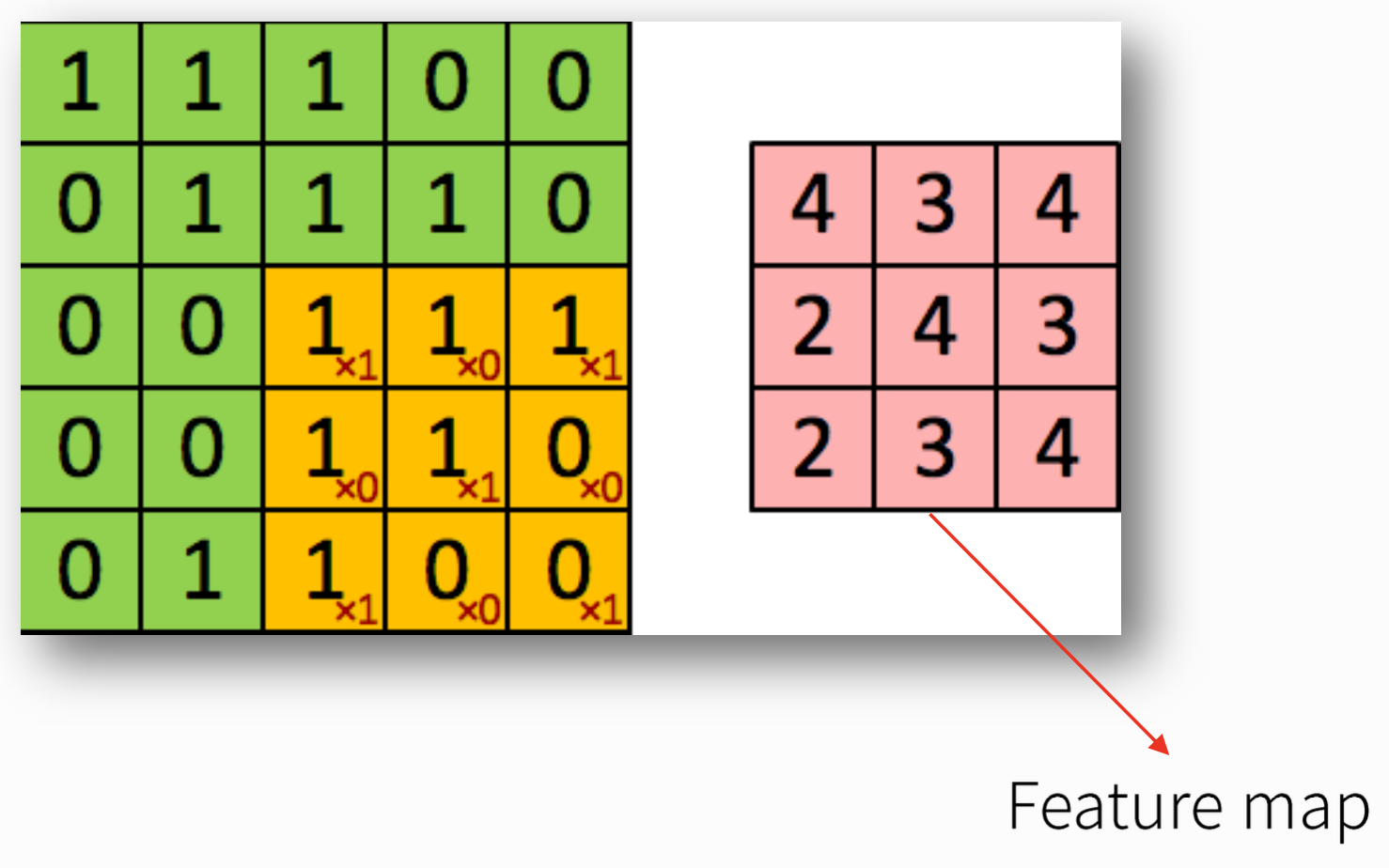
📚출처: http://ufldl.stanford.edu/tutorial/supervised/FeatureExtractionUsingConvolution/
- Activation Map: Feature Map에 Activation function을 적용한 Array를 의미한다. 즉, Convolution Layer의 최종 결과가 Activation Map이 된다.
4.1 Feature Map size 계산


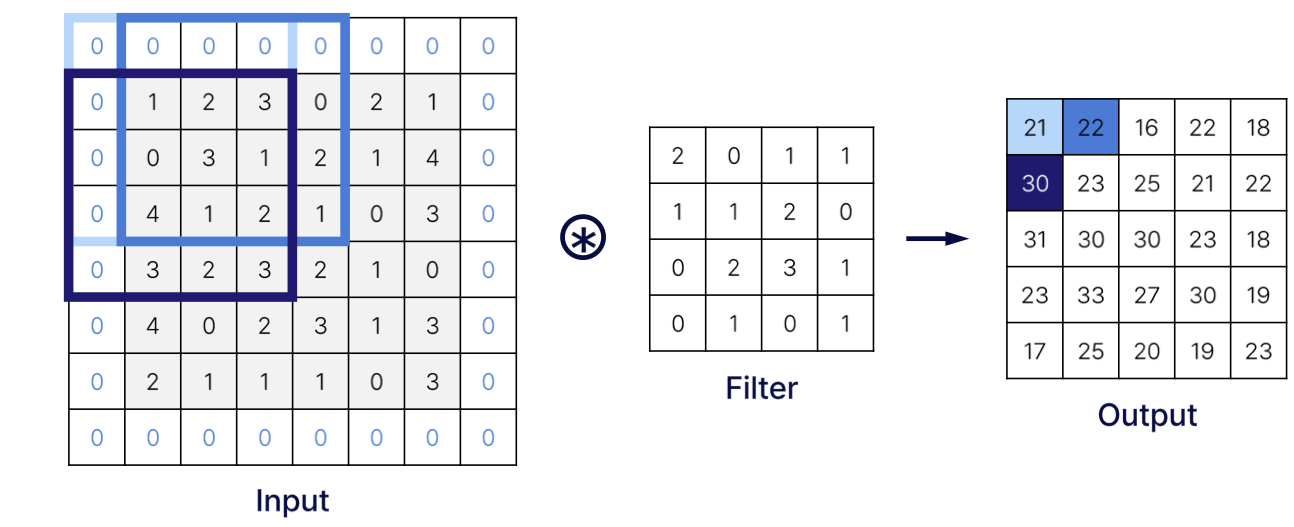
이처럼 스트라이드를 키우면 출력 크기는 작아지고, 패딩을 크게 하면 출력 크기가 커진다.
5. Stride
- Filter가 Height / Width 방향으로 몇 칸 식 이동하면서 정보를 추출할지 정하는 요소
- 스트라이드는 필터를 적용하는 위치의 간격을 의미한다.
- Stride 크기에 따라 Feature Map의 size가 바뀐다.
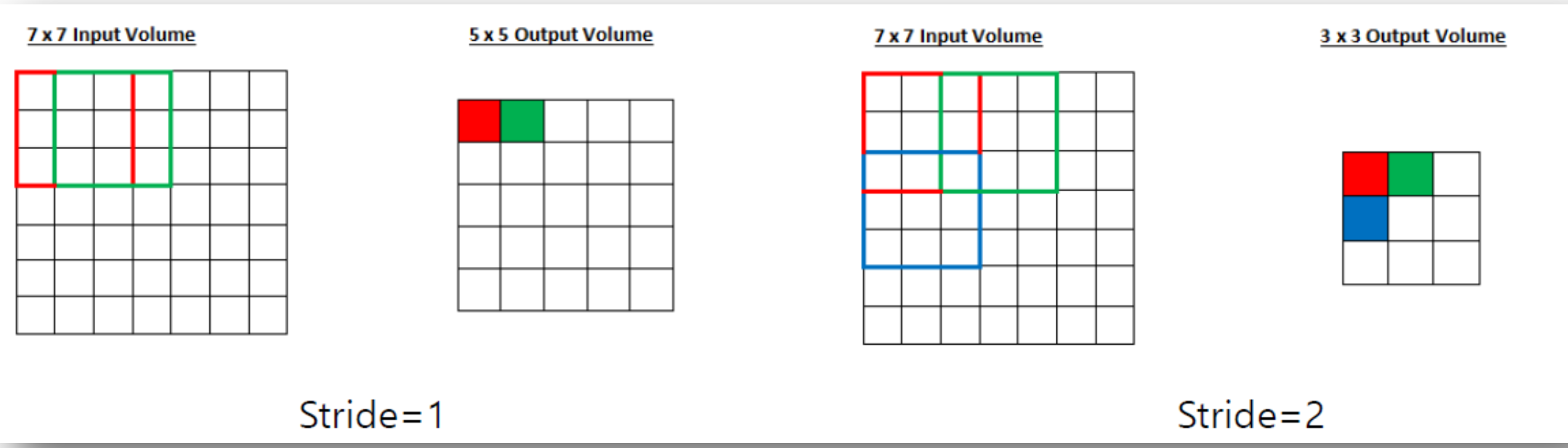
6. Padding
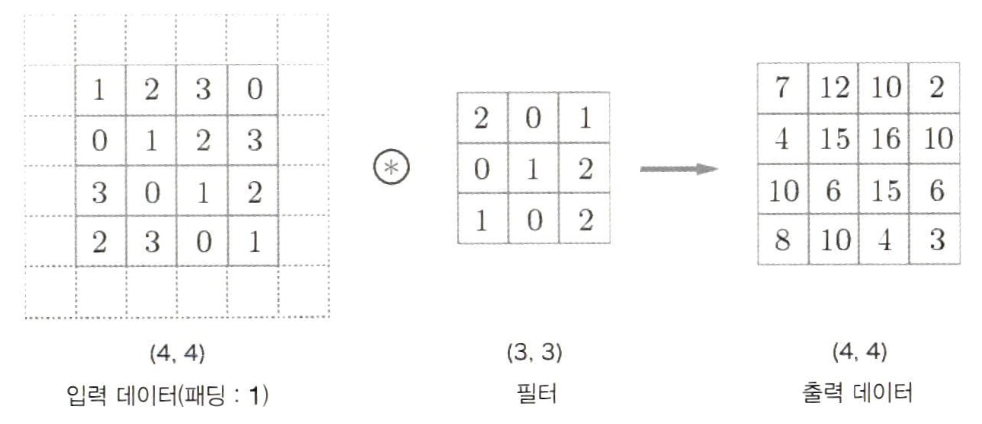
- Output data의 size가 줄어드는 것을 막기 위하여 Pixel을 특정 값으로 채워넣는 것을 의미한다.
-합성곱 Layer 연산의 결과로 만들어진 Feature Map의 size는 input보다 작다.
-정보가 축소 되어 모서리 부분의 정보는 다음 합성곱 연산에 이용되는 횟수를 감소시킨다.
-Padding을 사용하여 다음 합성곱 연산에 모서리 부분의 정보가 활용되는 비중을 유지시킨다.
📚출처: https://www.researchgate.net/figure/Padding-of-a-2D-image_fig7_336587478
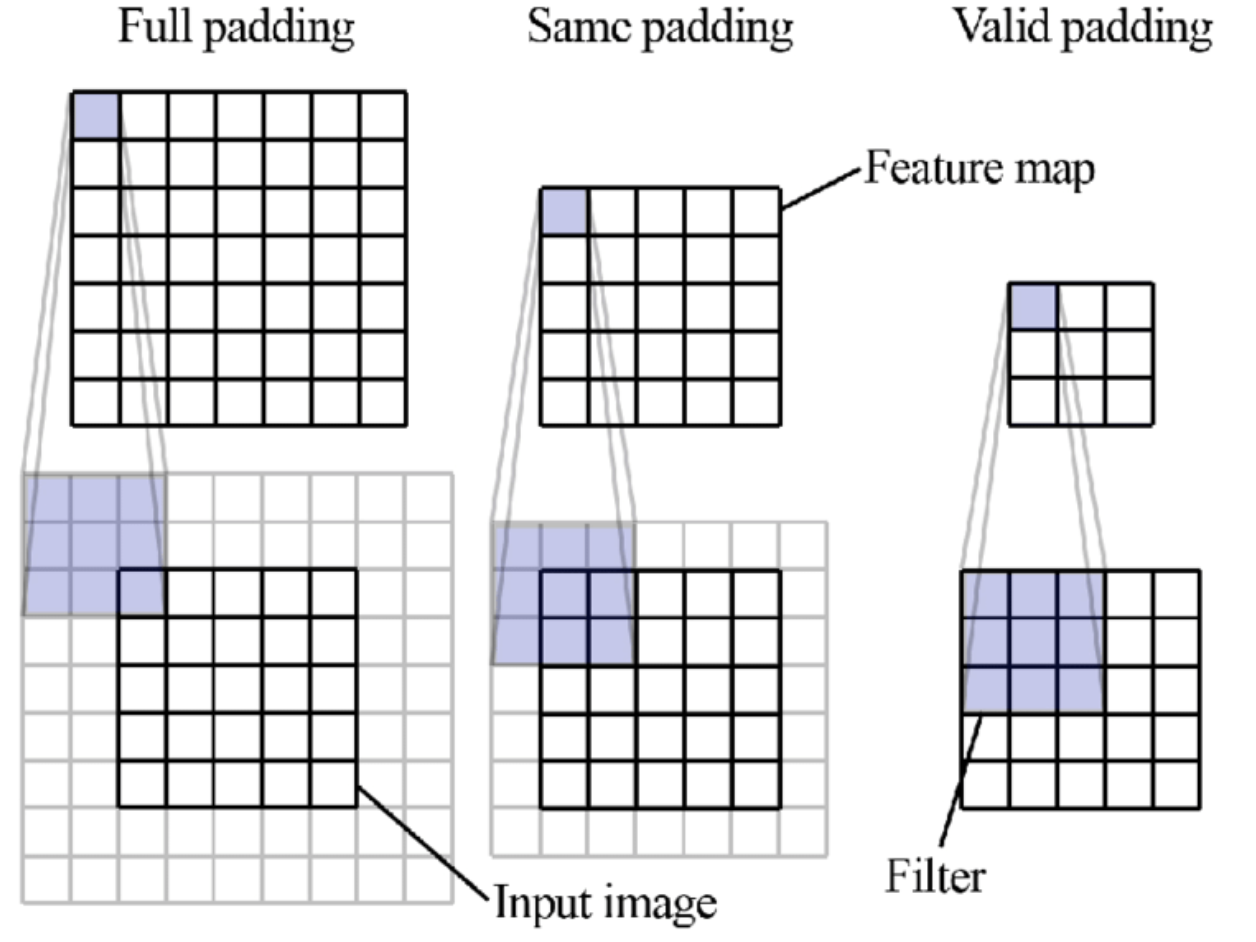
패딩의 종류
- Zero Padding: 패딩에 들어가는 값을 0으로 하는 것 (제일 많이 사용함)
- Full Padding: 모든 요소들이 같은 비율로 연산에 참여하도록 하는 것
- Same Padding: Output의 크기를 Input의 크기와 동일하도록 하는 것
- Valid Padding: Padding을 안하는 것
7. Channel
- 모든 색은 빛의 삼원색(Red, Green, Blue)를 이용하여 표현 할 수 있다.
- Image Pixel의 색을 표현하기 위해서 R,G,B에 해당하는 3개의 실수 값을 사용한다.
- 최초 Input은 Red, Green, Blue 세 개의 Channel을 사용하게 되며,
이후에는 Filter 개수 = Output channel 개수 가 된다
- 최초 Input은 Red, Green, Blue 세 개의 Channel을 사용하게 되며,
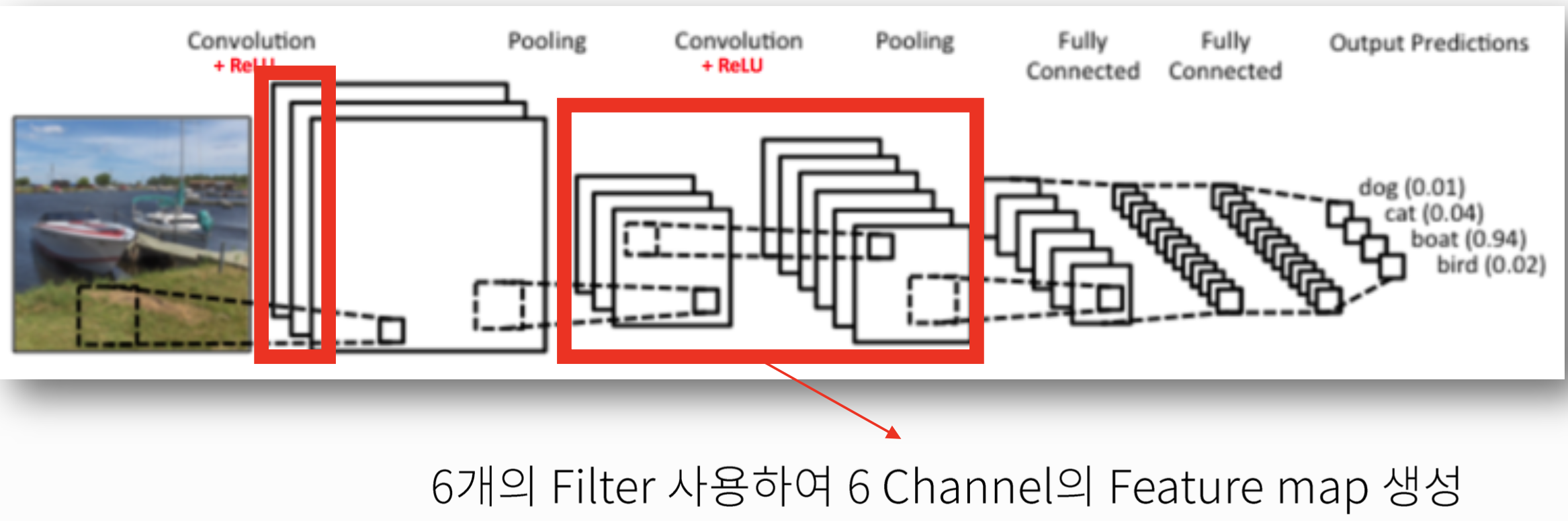
📚출처: https://medium.com/@Aj.Cheng/convolutional-neural-network-d9f69e473feb
Input의 Channel 수 = Filter(Kernel) Depth
사용한 Filter만큼 Feature Map이 만들어진다.
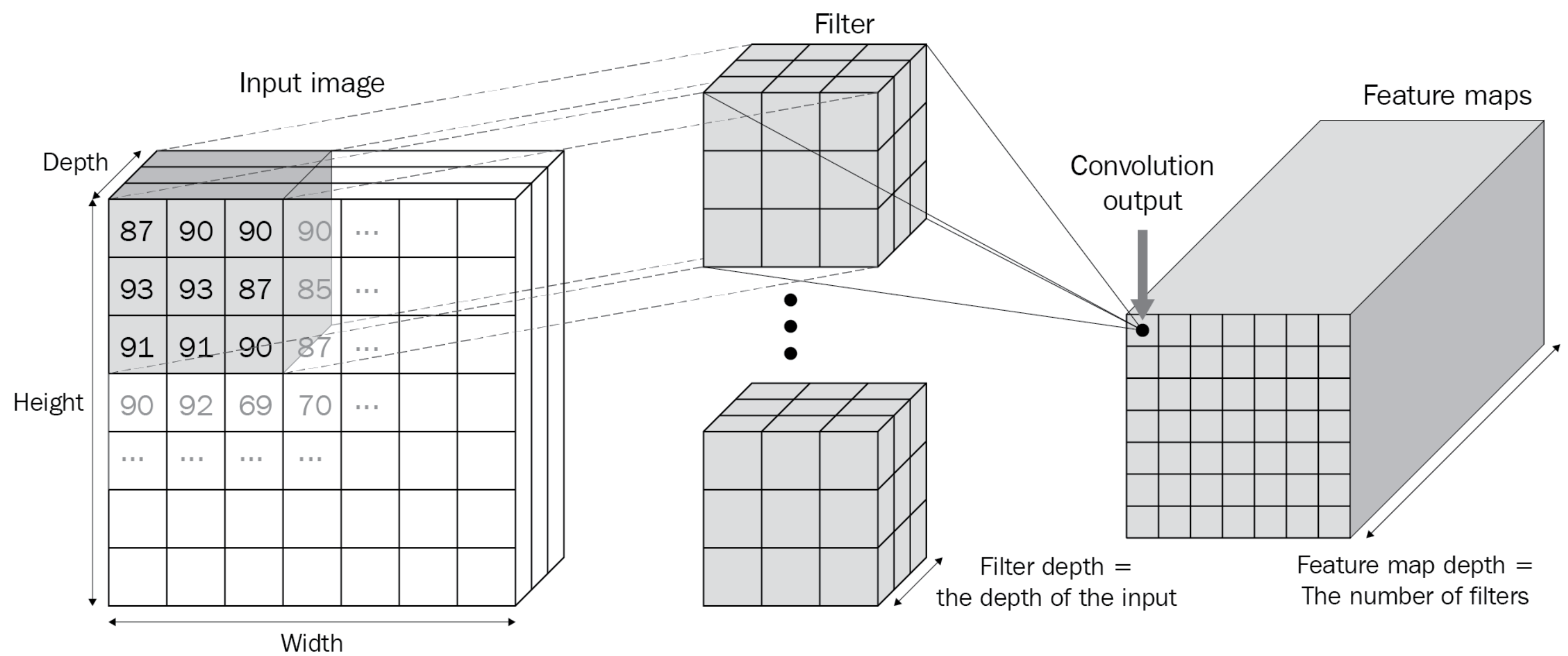
📚출처: Modern Computer Vision with PyTorch
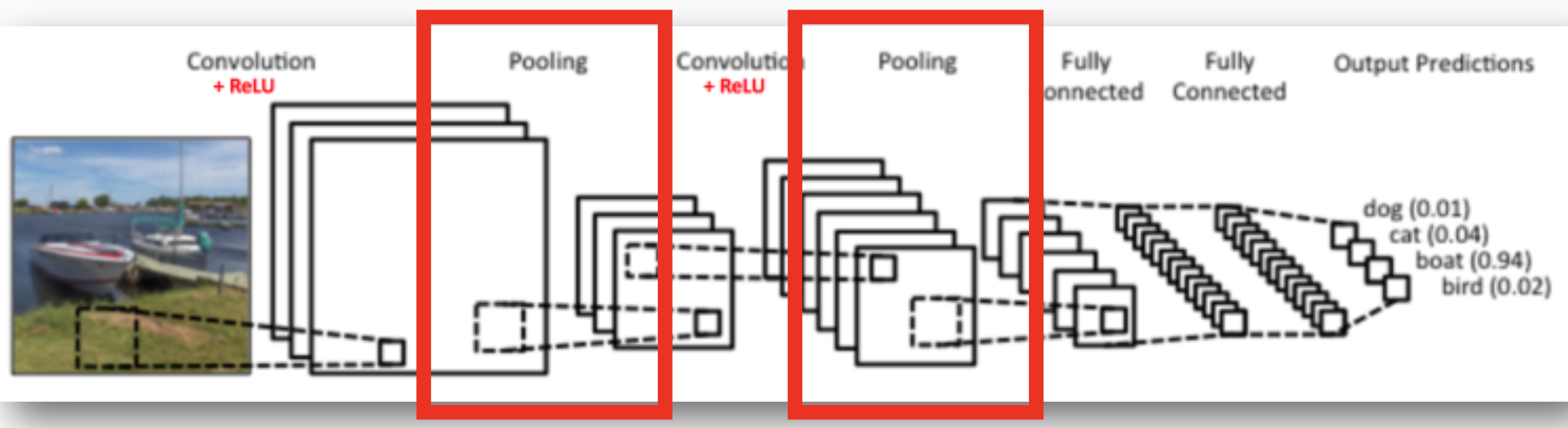
8.Pooling Layer (풀링 계층)
- Pooling Layer에서는 합성곱 Layer의 Output을 Input으로 하여 Activation Map의 크기를 줄이거나, 특정 Input을 강조한다
- 풀링은 세로 • 가로 방향의 공간을 줄이는 연산이다.
- 일반적으로 Convolution Layer를 거친 다음에 Pooling Layer에 적용한다.
일반적으로, 한 원소가 두 번 이상의 Pooling 연산에 사용되지 않는다.
Stride와 Pooling의 크기가 같다.
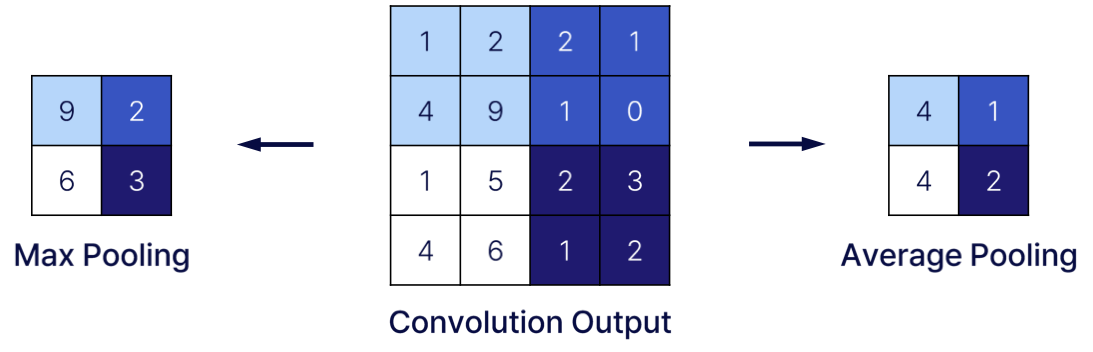
📚출처: https://medium.com/@Aj.Cheng/convolutional-neural-network-d9f69e473feb
특징
- 학습해야 할 Parameter가 없음
-영역에서 최대값이나 평균을 취하는 연산만 수행하기 때문- Channel 수는 변하지 않음
-채널마다 독립적으로 계산하기 때문- 입력의 변화에 영향을 적게 받음(강건함)
-입력 데이터의 차이를 Pooling이 흡수해 사라지게 하기 때문- 최근에는 사용하지 않으려는 경향이 있음
-많은 정보를 활용하고 학습 속도를 높일 수 있는 알고리즘이 많이 개발되었기 때문
9. Fully Connected Layer
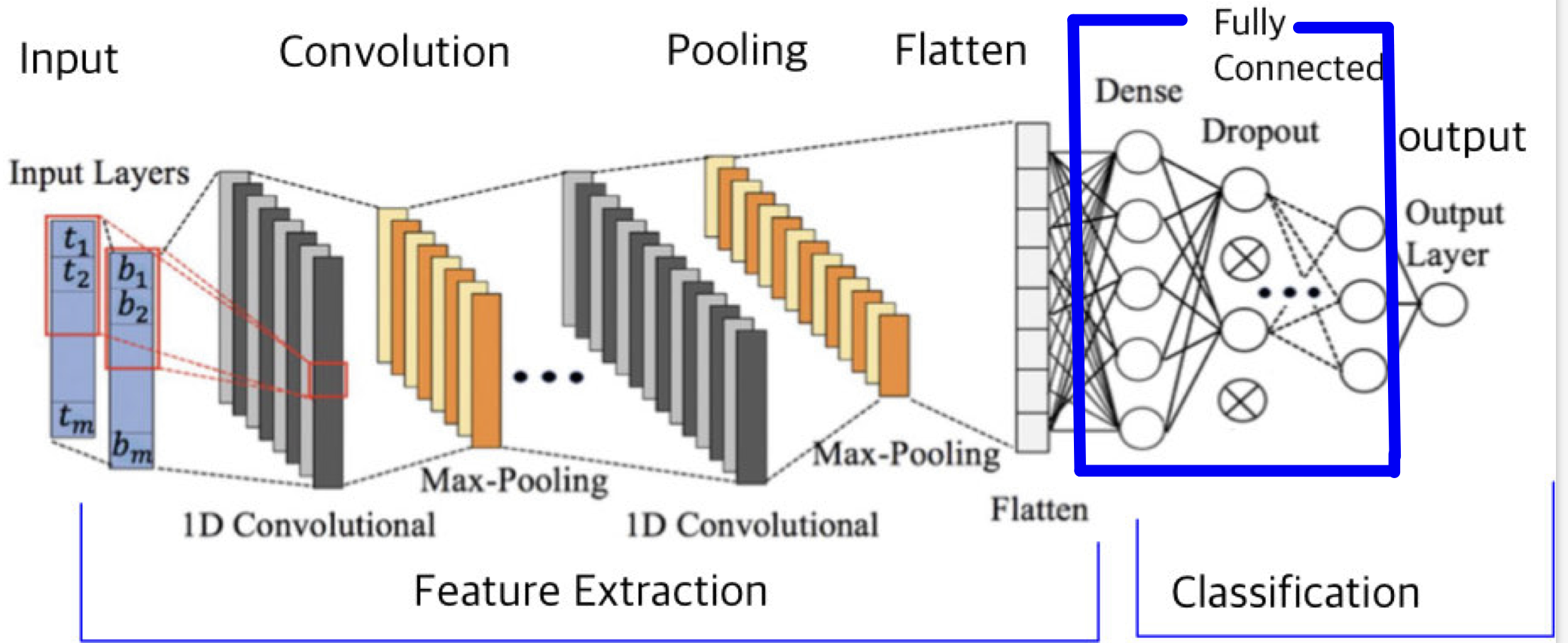
이미지를 정의된 라벨(클래스)로 분류하기 위한 Layer
- 일반적인 MLP의 구조와 동일
- Pooling Layer에서 나온 Feature를 Flatten 시킨 후에 MLP의 input으로 놓고 학습 진행
9.1. Flattening
- 합성곱 & Pooling Layer를 거친 이후 모든 Feature map들을 펼친다
ex) 3X3 Feature Map인 경우, Flatten을 수행하면 9X1이 된다.
ex) Channel 개수: 256개이면, (3,3,256) -> (3X3X256,1)로 바뀐다.
9.2. 최종 Output & Loss 계산
- Fully-Connected Layer를 거쳐 최종 output을 만들고, Loss를 계산한다.
- 각각 class에 대한 확률의 합이 1이 되게 하기 위해 Softmax를 사용한다.
- Image class의 개수만큼 최종 Node가 존재하기 때문에 최종 Node의 값과 Image label과의 비교를 통해 Loss를 계산한다.
- 계산된 TotalError을 사용하여 역전파를 통해 전체 신경망을 학습시킨다.
10. im2col(참고)
합성곱 연산을 구현하려면 for문을 사용하기 때문에 성능이 떨어진다는 단점이 있다.
im2col은 Image to column라는 의미로 '이미지에서 행렬로'라는 뜻이다. 즉, 입력 데이터를 필터링(가중치 계산)하기 좋게 전개하는 함수이다. 필터 적용 영역이 겹치게 되서 원래 블록의 원소 수보다 많아진다. 그래서 im2col을 사용해 구현하면 메모리를 더 많이 소비한다는 단점이 있다. 하지만 컴퓨터는 큰 행렬을 묶어서 계산하는 데 탁월하기 때문에 선형 대수 라이브러리를 통해 행렬의 곱셈을 빠르고 효율적으로 사용할 수 있다.
*카페와 체이너 등의 딥러닝 프레임워크는 im2c이이라는 이름의 함수를 만들어 합성곱 계층을 구현할 때 이용하고 있다.
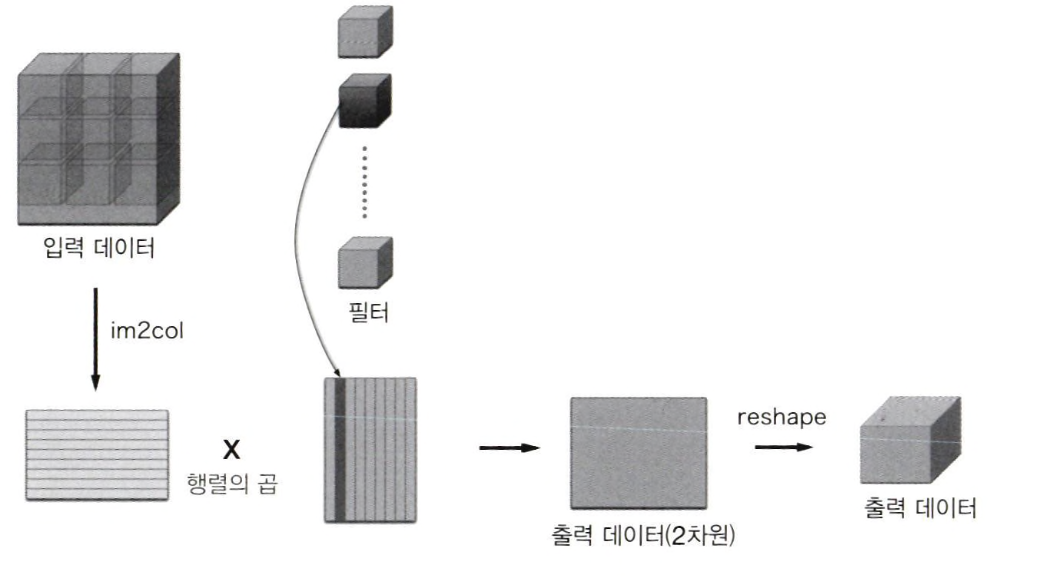
위의 그림은 합성곱 연산의 필터 처리 상세 과정이다. 필터를 세로로 1열로 전개하고,im2col이 전개한 데이터와 행렬 곱을 계산 후 출력 데이터를 변형(reshape)한다.
11. CNN 구현

1) 초기화 인수로 주어진 합성곱 계층의 하라미터를 꺼내고, 가중치 매개변수를 초기화
2) 합성곱 계층과 나머지 두 완전연결 계층의 가중치와 편향을 저장
3) CNN 계층을 생성하여 순서가 있는 딕셔너리인 layers에 계층들을 차례로 추가하고, Softmax WithLoss 계층만큼은 last_layer라는 변수에 별도로 저장

4) 손실 함수를 구하는 loss 메서드는 predict 메서드의 결과를 인수로 마지막 층의 forward 메서드를 호출 즉, 첫 계층부터 마지막 계층까지 forward를 처리
5) 순전파와 역전파를 반복하여 오차역전파를 구하고, grads라는 딕셔너리 변수에 각 가중치 매개변수이 기울기를 저장
12. 대표적인 CNN
12.1 LeNet
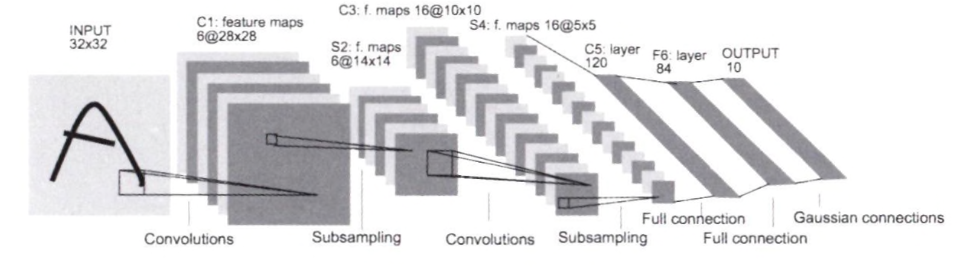
- LeNet은 손글씨 숫자를 인식하는 네트워크로, 1998년에 제안됨
- 합성곱 계층과 풀링 계층('원소를 줄이기'만 하는)을 반복하고, 마지막으로 완전연결 계층을 거치면서 결과를 출력
- 시그모이드 활성화 함수를 사용하고, 서브샘플링을 하여 중간 데이터의 크기를 줄임
-> 현재는 ReLU 활성화 함수를 사용하고, 최대 풀링을 자주 씀
12.2 AlexNet
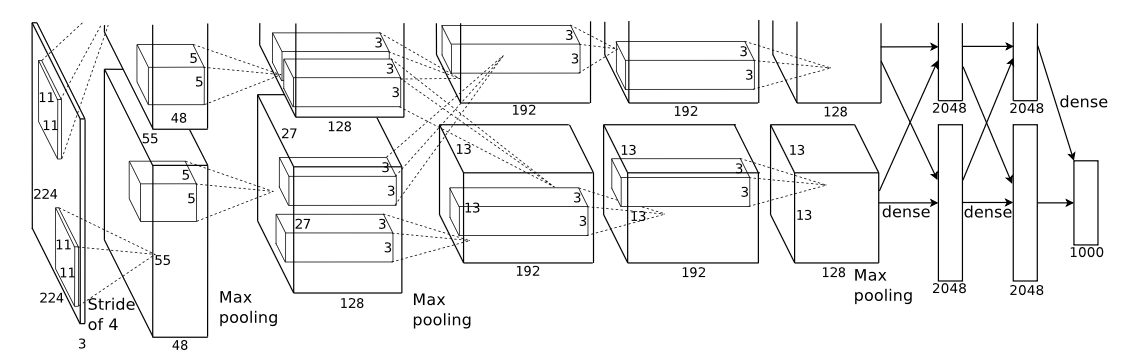
- AlexNet은 2012년에 발표되었고, 그 구성은 기본적으로 LeNet과 크게 다르지 않음
- 합성곱 계층과 풀링 계층을 거듭하며 마지막으로 완전연결 계층을 거쳐 결과를 출력함
- LeNet에서 큰 구조는 바뀌지 않았지만 다른 점은 1) 활성화 함수로 ReLU를 이용 2) LRN(Local Response Normalization)이라는 국소적 정규화를 실시하는 계층을 이용 3) 드롭아웃을 사용한다는 것이다.
13. 내용 정리
- CNN은 완전연결 계층 네트워크에 합성곱 계층과 풀링 계층을 새로 추가함
- 풀링 계층과 합성곱 계층은 이미지를 행렬로 전개하는 함수인 im2col를 이용하면 효율적이고 간단하게 구현할 수 있음
- CNN을 시각화해보면 계층이 깊어질수록 고급 정보가 추출됨
- 대표적인 CNN에는 LeNet과 AlexNet이 있음
밑바닥부터 시작하는 딥러닝 pp227-259 참고해서 내용 작성하였습니다.
🎯 Summary
합성곱 계층과 풀링 계층에 개념이 어려웠지만 내용을 정리하다보니 이해하는 데 도움이 되었다.
패션에 관심이 많아서 CNN을 공부하는 데 상당히 재밌었다. 이제는 CNN 관련 논문 리뷰를 통해서 CNN에 대해 더 깊이 공부하고 싶다.
📚 References
- 사이토 고키(2017), '밑바닥부터 시작하는 딥러닝', 한빛미디어, pp.227-259.
- towardsdatascience(Chandra Churh Chatterjee),'Basics of the Classic CNN',https://towardsdatascience.com/basics-of-the-classic-cnn-a3dce1225add (검색일: 2023.04.29.).
- UFLDL Tutorial,'Feature Extraction Using Convolution', http://ufldl.stanford.edu/tutorial/supervised/FeatureExtractionUsingConvolution/ (검색일: 2023.04.29.).
- AI SUMMER, Nikolas Adaloglou(2020.07.02.), 'Understanding the receptive field of deep convolutional networks', https://theaisummer.com/receptive-field/ (검색일: 2023.04.29.).
- ResearchGate, https://www.researchgate.net/figure/Padding-of-a-2D-image_fig7_336587478 (검색일: 2023.04.29.).
- Search Midium, Long(2017.06.01), 'Convolutional Neural Network', https://medium.com/@Aj.Cheng/convolutional-neural-network-d9f69e473feb (검색일: 2023.04.29.).
- V Kishore Ayyadevara , Yeshwanth Reddy, Modern Computer Vision with PyTorch
