주제: 파이썬에서 연결리스트 구현하기
파이썬과 함께하는 자료구조의 이해[개정판] pp.54-60 참고해서 내용 작성하였습니다.
파이썬으로 배우는 자료구조 핵심 원리 pp.54-60 참고해서 내용 작성하였습니다.
1. 파이썬 리스트(List)
- 일반적인 List는 일련의 동일한 타입의 항목들을 의미한다. 예를 들어, 버킷 리스트, 시험 성적, 상점의 판매 품목 등이 있다.
- 리스트의 구현
- 파이썬 리스트(List)
- 단순연결리스트
- 이중연결리스트
- 원형연결리스트
- 리스트의 구조
: 항목들이 순서대로 나열되어 있고, 각 항목들은 위치를 갖는다.
리스트는 임의의 위치에서도 항목의 삽입과 삭제가 가능하다.
- Stack, Queue, Deque과의 차이점은?
: 자료의 접근 위치
1.1 배열구조와 연결된 구조의 차이점
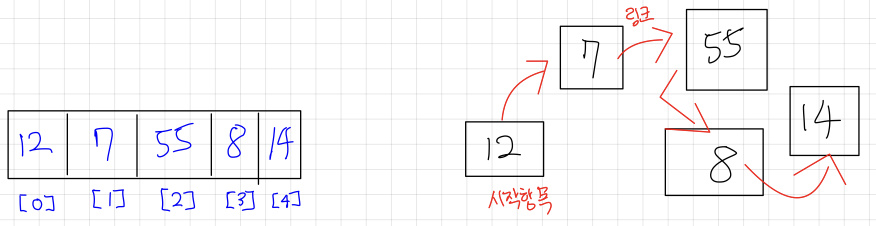
<왼쪽 그림은 배열구조의 리스트, 오른쪽 그림은 연결된 구조의 리스트>
| 배열구조 | 연결된 구조 |
|---|---|
| 구현이 간단 | 구현이 복잡 |
| 항목 접근이 O(1) | 항목 접근이 O(n) |
| 삽입, 삭제시 오버헤드 | 삽입, 삭제시 효율적 |
| 항목의 개수 제한 | 크기가 제한되지 않음 |
1.2 리스트 용어 정리
- 파이썬 리스트
: C언어에서의 배열이 진화된 형태의 스마트한 배열이다. 배열 또는 배열 구조의 의미로 사용한다.
- 연결 리스트
:자료들이 일렬로 나열할 수 있는 연결된 구조를 의미한다. 배열 구조에 대응되는 의미로 사용된다.
- 자료구조 리스트
: 구현하기 위해 배열구조(파이썬의 리스트) or 연결된 구조(연결 리스트)를 사용하는 것이다.
1.3 파이썬 리스트의 시간 복잡도
- append(e) 연산
: 대부분의 경우 O(1)
- insert(pos,e)연산
: O(n)
- pos(pos)연산: O(n)
2. 연결된 구조란?
정의
: 연결된 구조는 흩어진 데이터를 '링크'로 연결해서 관리하는 것을 의미한다.
- 특징
-용량이 고정되지 않는다.
-중간에 자료를 삽입하거나 삭제하는 것이 용이하다.
즉, n번째 항목에 접근하는데 O(n)의 시간이 걸린다.
3. 단순연결리스트
정의
: 단순연결리스트(Singly Linked List)는 동적 메모리 할당을 이용해 리스트를 구현하는 가장 간단한 형태의 자료구조를 의미한다.
- 특징
-동적 메모리 할당을 받아 노드(node)를 저장하고, 노드는 레퍼런스를 이용하여 다음 노드를 가리키도록 만들어 노드들을 한 줄로 연결시킨다.
-연결리스트에서는 삽입이나 삭제 시 항목들의 이동이 필요 없다.
-배열(C,C++,JAVA)의 경우 최소에 배열의 크기를 예측하고 결정하기 때문에 배열에 빈 공간을 가지고 있다. 하지만 연결리스트는 빈 공간이 존재하지 않는다.
-연결리스트에서 항목을 탐색하려면 항상 첫 노드부터 원하는 노드를 찾을 때까지 차례로 방문하는 순차탐색(Sequential Search) 을 해야 한다.
3.1 연결리스트 이해하기
1) 연결리스트의 삽입 전
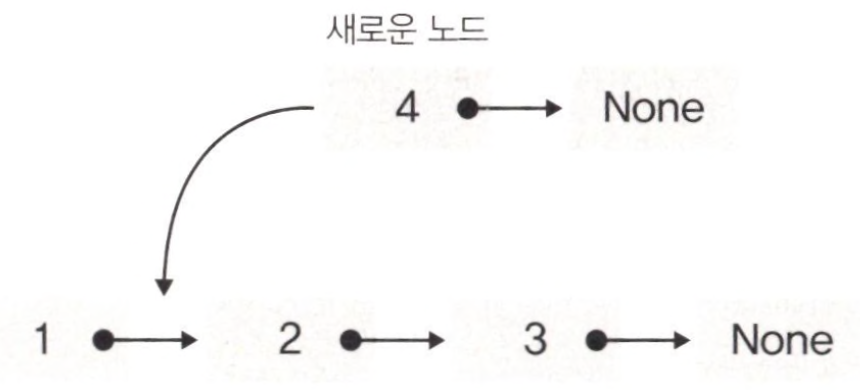
- 위의 그림은 연결리스트에 새로운 노드를 삽입하는 첫 번째 과정이다. 노드 1과 2 사이에 4라는 새로운 노드를 삽입하려고 한다.
2) 연결리스트의 삽입 후
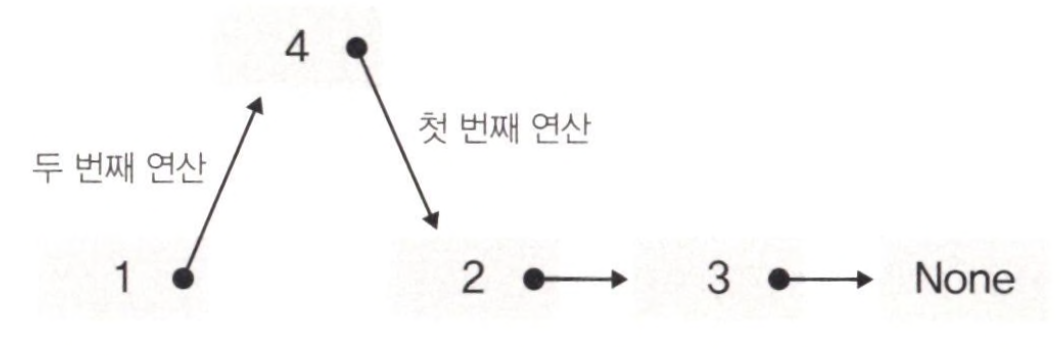
- 위의 그림과 같이 4의 Link는 2를 가리키게 하고, 1의 Link는 4를 가리키게 하면 된다.
3) 연결리스트의 삭제 전,후
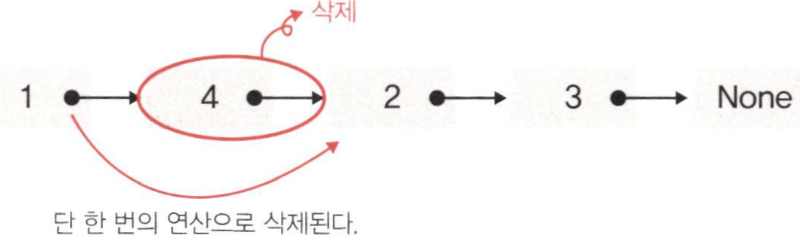
- 위의 그림을 보면, 노드 4를 삭제할 때는 노드 1의 Link가 2를 가리키게 하면 된다. 그렇게 하면 노드 4를 따로 처리하지 않아도 메모리에서 사라진다. 이는 파이썬이 언어 차원에서 메모리를 관리해주기 때문이다. (가비지 컬렉션)
- 노드 4를 보면, 노드 1이 2를 가리키면 자신을 가리키고 있는 어떤 노드도 없기 때문에 가비지 컬렉션으로 삭제 된다.
- 가비지 컬렉션
: 언어 차원에서 메모리를 관리해 주는 것을 의미한다. 파이썬의 경우 레퍼런스 카운트로 가비지 컬렉션을 지원한다.
- 레퍼런스 카운팅
: 어떤 객체를 가리키는 객체 개수가 0이 될 때 해당 객체를 지우는 것을 의미한다.
4) 연결리스트의 탐색
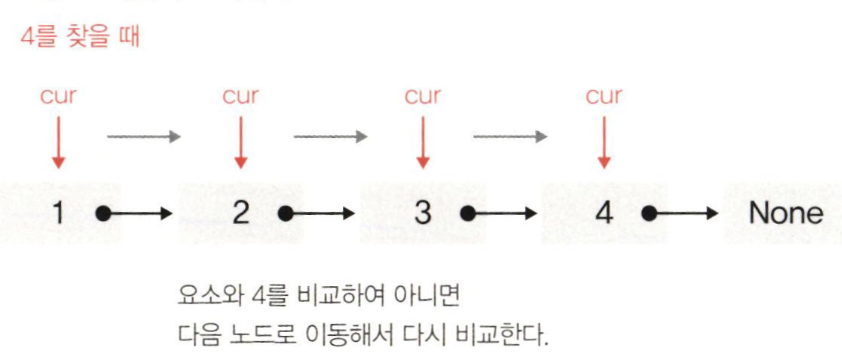
- 먼저 cur 변수를 두어 리스트의 첫 노드를 가리키게 한다. 그 후 찾고자 하는 값 4를 비교하여 아니면 다음 노드로 이동해서 계속 비교한다. 최악의 경우는 데이터가 리스트 마지막에 있을 때이기 때문에 빅오는 O(n)이다.
3.2 코드 구현
🤜 입력
class SList:
class Node:
def __init__(self, item, link):
self.item = item # 노드 생성자 항목
self.next = link # 다음 노드 레퍼런스
def __init__(self):
self.head = None
self.size = 0
def size(self): return self.size
def is_empty(self): return self.size ==0
def insert_front(self, item):
if self.is_empty(): # empty인 경우
self.head = self.Node(item, None) # head가 새 노드를 참조
else:
self.head = self.Node(item, self.head) # head가 새 노드를 참조
self.size += 1
def insert_after(self, item, p):
p.next = self.Node(item, p.next) # 새 노드가 p 다음 노드가 된다.
self.size += 1
def delete_front(self):
if self.is_empty(): # empty인 경우 에러 처리
raise EmptyError('Underflow')
else:
self.head = self.head.next. # head가 둘째 노드를 참조한다.
self.size -= 1
def delete_after(self, p):
if self.is_empty():
raise EmptyError('Underflow')
t = p.next
p.next = t.next. # p 다음 노드를 건너뛰어 연결한다
self.size -= 1
def search(self, target):
p = self.head # head로부터 순차탐색한다.
for k in range(self.size):
if target == p.item: return k # 탐색 성공
p = p.next
return None # 탐색 실패
def print_list(self):
p = self.head
while p:
if p.next != None:
print(p.item, ' -> ', end='')
else:
print(p.item)
p = p.next. # 노드들을 순차탐색한다
class EmptyError(Exception): # underflow시 에러 처리
pass3.3 코드 이해하기
각 메소드 코드를 그림을 통해 하나하나 뜯어보자!
1. insert_front() 코드
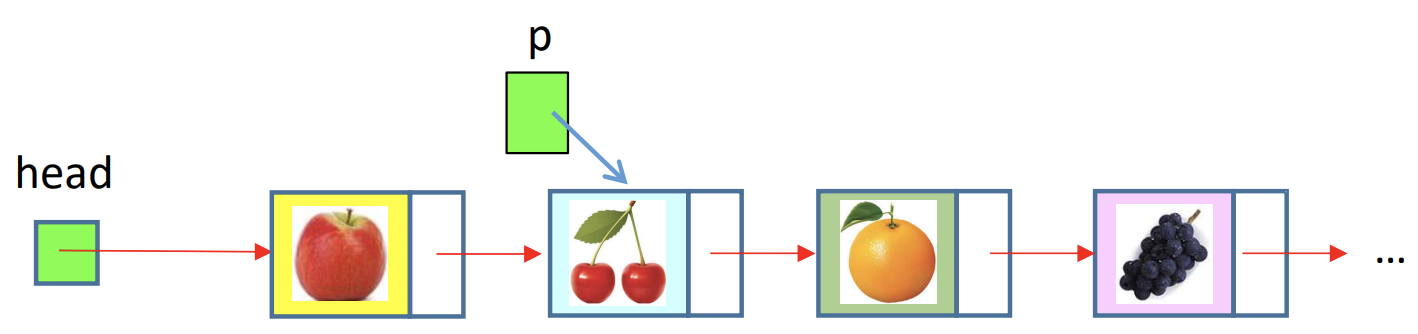
1) 새 노드('apple') 삽입 전
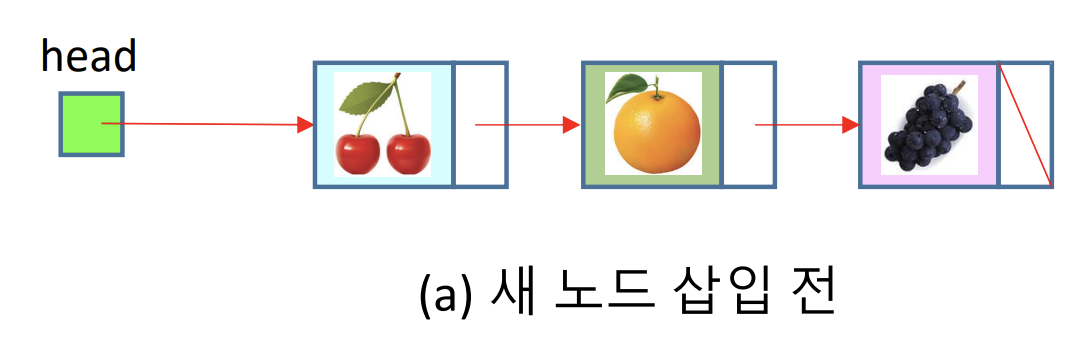
2) 새 노드('apple') 삽입 후
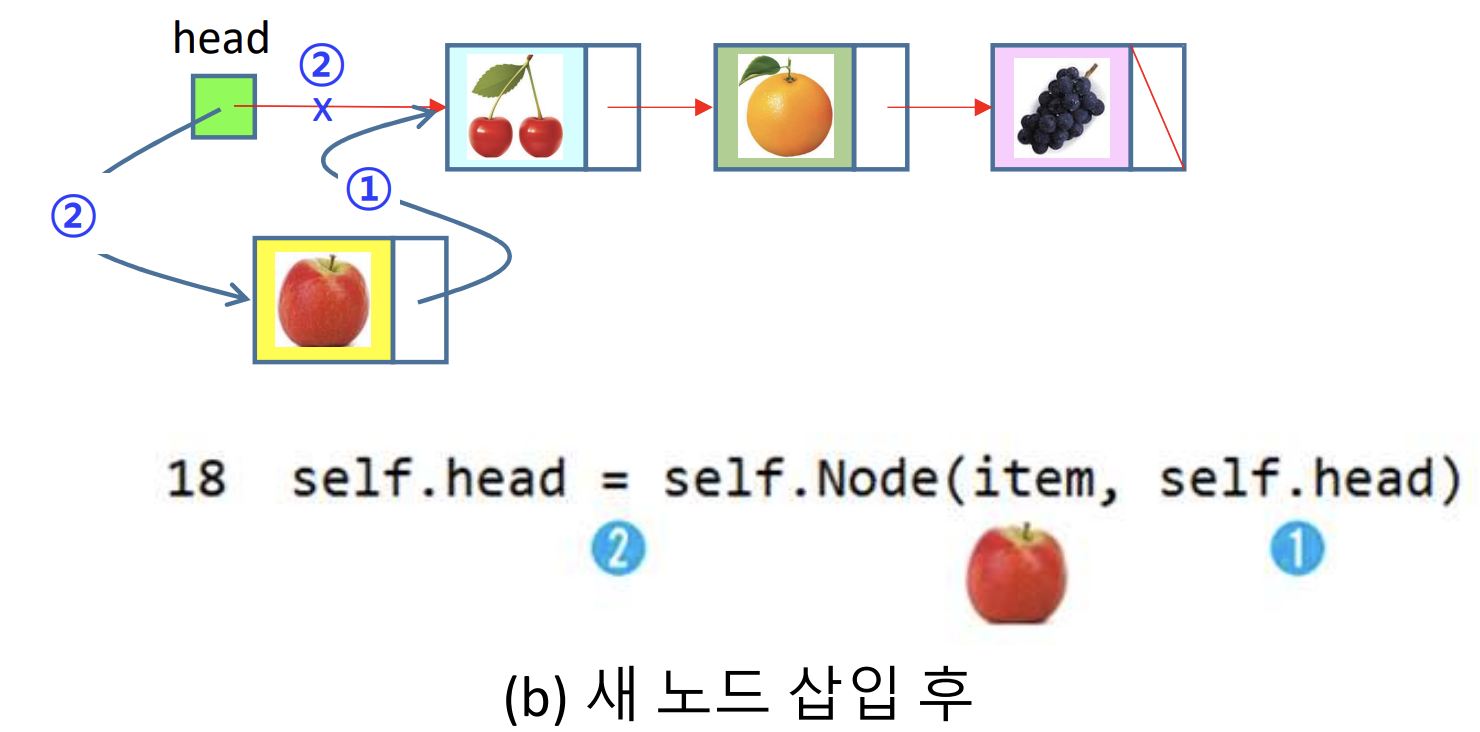
- 먼저 item('apple')의 링크를 cherry에 연결한다. 그 이후 head의 링크는 item('apple)에 연결한다.
2. insert_after() 코드
1) 새 노드('apple') 삽입 전
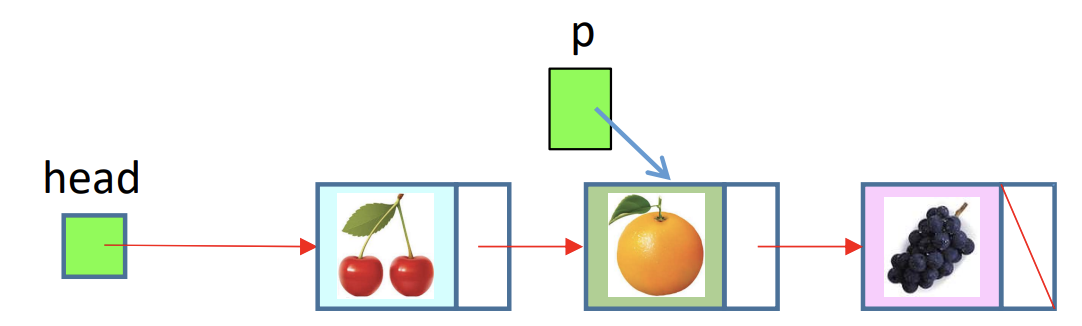
2) 새 노드('apple') 삽입 후
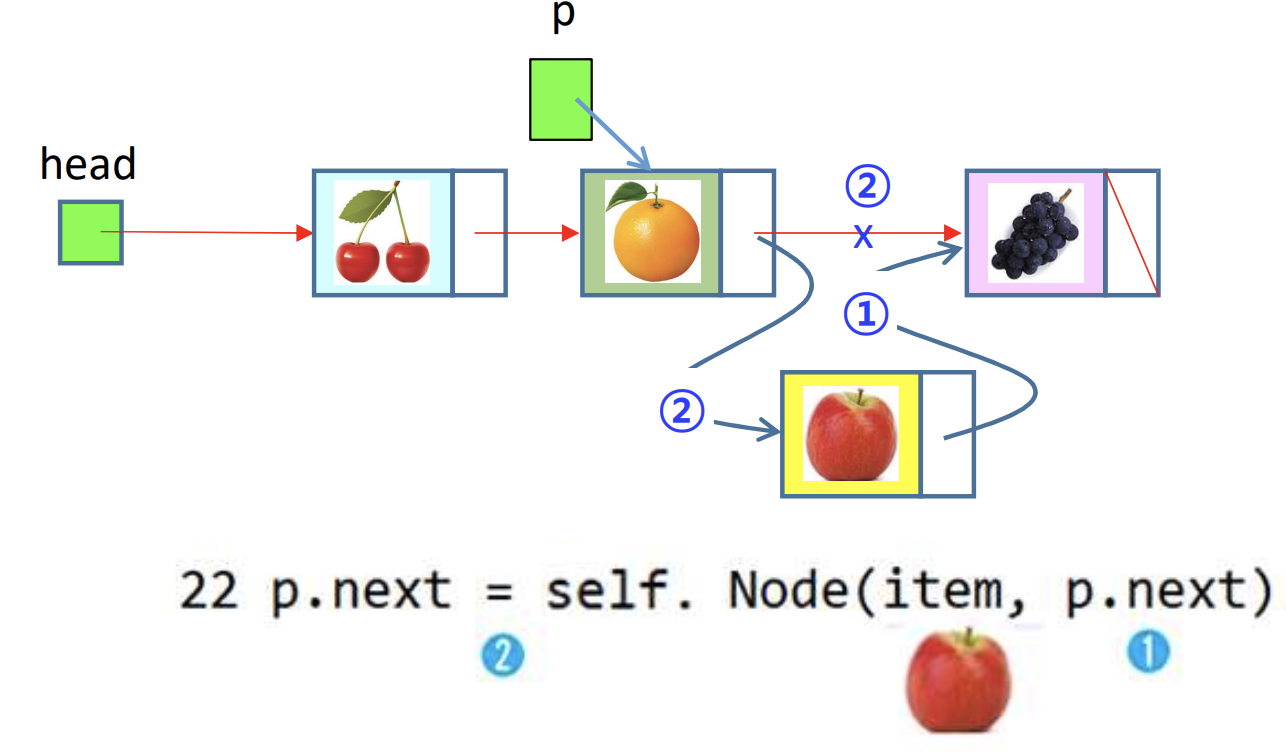
- p가 가리키는 노드의 다음에 삽입하는 경우이다. 그 위에서 삽입 했을 때는
self.head = self.Node(item, self.head)라고 표기를 했었다. 하지만 이 코드에서는 'Apple'을 기준으로 전, 후가 head가 아닌 다른 item을 갖기 때문에p.next = self.Node(item, p.next)라고 표기를 하였다. 즉, 새 노드가 p 다음 노드가 된다는 것을 알 수 있다.
3. delete_front() 코드
1) 첫 노드('apple') 삭제 전

2) 첫 노드('apple') 삭제 후
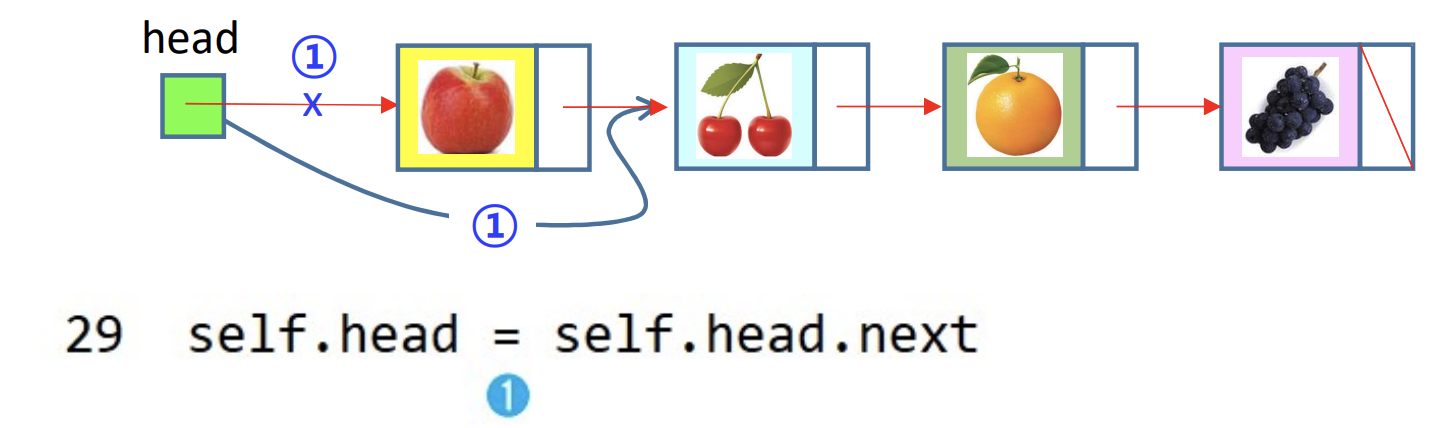
- 가비지 컬렉션이 동작되기 때문에 head를 cherry로 연결하게 되면 apple 노드는 없어진다.
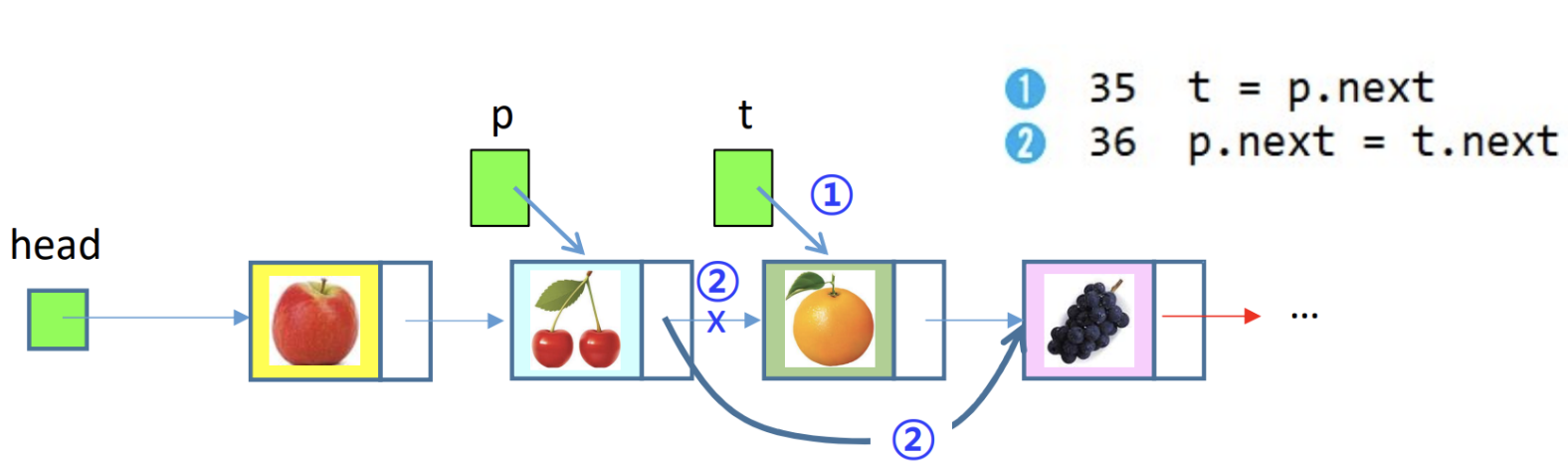
4. delete_after() 코드
1) 노드('orange)' 삭제 전
2) 노드('orange)' 삭제 후
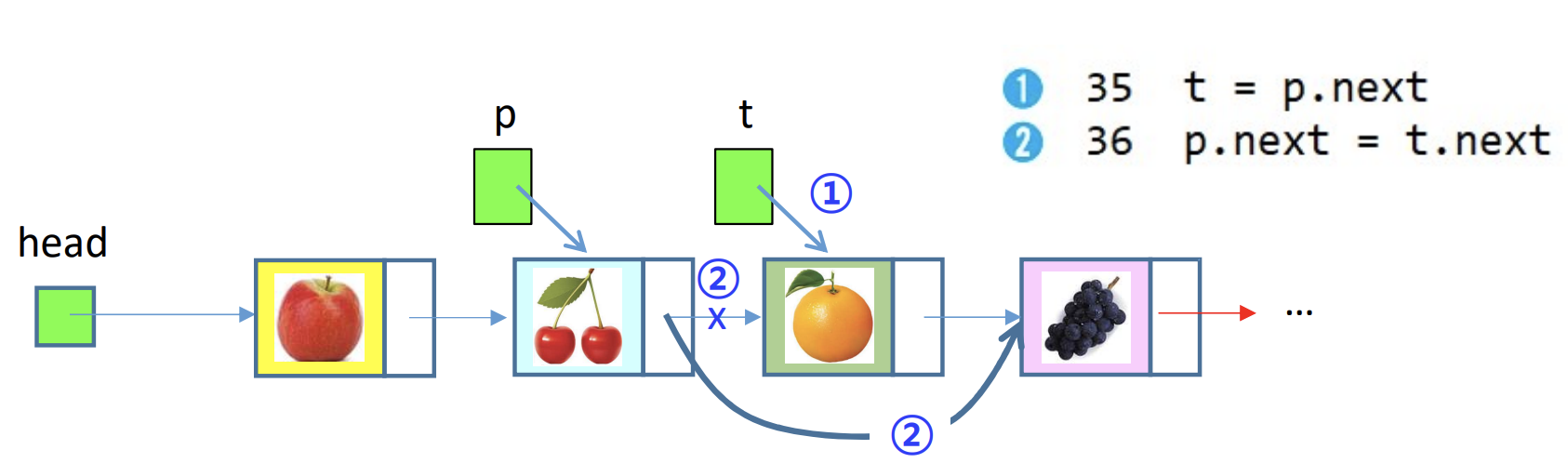
t = p.next로 설정한 후, (2)번p.next = t.next로 연결하게 되면 orange 노드는 없어진다.
4. 삽입, 삭제, 탐색 연산 수행
🤜 입력
from slist import SList # slist.py에서 SList를 import
if __name__== '__main_': # 이 파이썬 파일(모듈)이 메인이면
s = SList() # 단순 연결리스트 생성
s.insert_front('orange')
s.insert_front('apple')
s.insert_after('cherry', s.head.next)
s.insert_front('pear')
s.print_list()
print('cherry는 %d번째' % s.search('cherry'))
print('kiwi는', s.search('kiwi'))
print('배 다음 노드 삭제 후: \t\t', end='')
s.delete_after(s.head)
s.print_list()
print('첫 노드 삭제 후:\t\t', end='')
s.delete_front()
s.print_list()
print('첫 노드로 망고, 딸기 삽입 후:\t', end='')
s.insert_front('mango')
s.insert_front('strawberry')
s.print_list()
s.delete_after(s.head.next.next)
print('오렌지 다음 노드 삭제 후:\t', end='')
s.print_list()💻 출력

- 수행시간
: search()는 첫 노드부터 순차적으로 방문해야 하므로 O(n)시간이 소요된다. 여기서 n은 노드 수이다. 그러나 삽입, 삭제 연산은 각각 O(1)개의 레퍼런스만을 갱신하므로 O(1) 시간이 소요된다.단, insert_after()나 delete_after()의 경우에 특정 노드 p의 레퍼런스가 주어지지 않으면 head로부터 p를 찾기 위해 search()를 수행해야 하므로 O(n)시간이 소요될 수 있다.
5. 활용
- 단순연결리스트는 매우 광범위하게 활용되는데, 특히 Stack, Queue 자료구조에서 많이 활용된다.
- 해싱의 체이닝(Chaining)에 사용된다.
- 트리도 단순연결리스트의 개념을 확장시킨 자료구조이다.
- 그래프의 인접 리스트에도 활용된다.
- 매우 큰 수의 산술 연산이 가능하다. 비트코인의 블록체인 도 이와 같은 방법을 사용한다.
🎯 Summary
노드의 삽입, 삭제가 자유로운 단순연결리스트의 장점을 알게 되었다. 하나 하나 코드를 뜯어보았고, 교재에 있는 그림을 통해 수월하게 이해할 수 있었다. insert_after 과 delete_after 부분은 헷갈리니 여러 번 복습해야겠다.
전체적으로 어려웠지만 단순연결리스트를 확실히 이해하고 넘어가면 그 뒤에 있는 스택과 큐 공부할 때 매우 도움이 될 수 있으니 열심히 공부해야겠다.
📚 References
- 양성봉(2022),'파이썬과 함께하는 자료구조의 이해[개정판]', 생능출판, pp.54-60.
- 양태환(2021),'파이썬으로 배우는 자료구조 핵심 원리', 길벗, pp.54-60.
