BI (Business Intelligence) 란?
- 조직에서 사람과 기술의 힘을 사용하여, 전략적/일상적 의사 결정 프로세스에 사용될 데이터를 수집하고 분석하는 프로세스입니다.
- 조직이 데이터 기반 의사 결정을 할 수 있도록 지원하는 '비즈니스 분석, 데이터 마이닝, 데이터 시각화, 데이터 도구' 등이 모두 포함됩니다.
- BI를 위한 툴에 Tableau, Power BI, Looker 등이 포함됩니다.
데이터셋
통계청 온라인쇼핑동향
이번 프로젝트에서 사용할 데이터셋은 통계청에서 제공하는 온라인 쇼핑 동향 데이터입니다.
링크텍스트
위 사이트에서 '온라인쇼핑'을 검색한 후, '온라인쇼핑몰취급상품범위별상품군별거래액...' 라는 csv파일을 다운받아서 사용합니다.
전처리
위 csv파일에는 아래 4가지 문제가 있어, 전처리가 필요합니다.
(1) 이미 집계가 완료된 상태 (pivot table 형태를 띄고 있음)
(2) 총합, 중간 집계값이 행에 끼어있음
(3) 가전, 전자, 통신기기 카테고리 세분화
(4) 날짜 컬럼 양식 불일치
+) 만일 데이터 타입이 불일치할 경우
(1) 이미 집계가 완료된 상태 (pivot table) 처리
pd.melt() 를 통해 테이블 형태 변형하기
# id_vars : 유지할 컬럼
# value_vars : 변환할 컬럼
# var_name : 변환 후 생성되는 컬럼 이름
# value_name : 변환 후 생성되는 값 컬럼 이름
df.melt(id_vars, value_vars, var_name, value_name)현재 데이터프레임은 이렇게 생겼음
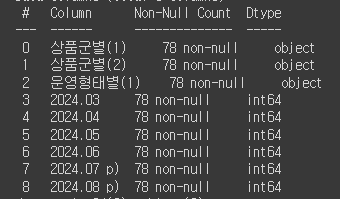
여기서 2024.03, 2024.04, ... 2024.08 p) 컬럼을 '날짜'라는 컬럼의 값들로 변경해주고 싶음
그럼, pd.melt()를 아래처럼 사용하면 됨!
pd.melt(pd.columns[0:2])이렇게만 하면 '날짜'로 쓸 컬럼은 variable, '거래액'으로 쓸 컬럼은 value라는 이름으로 지정되는데, 컬럼 이름을 내가 지정해주고 싶으면 아래처럼 수정하면 됨!
result = pd.melt(pd.columns[0:2], var_name='날짜', value_name='거래액')만일 다시 pivot_table로 변형하고 싶다면
# values = 집계하고 싶은 값
# index = 그룹핑할 기준이 되는 컬럼
# aggfunc(옵션) = 디폴트는 mean(평균), values를 어떤 집계함수로 집계할 것인지
df2.pivot_table(values='거래액',index = '상품군별(1)', aggfunc='sum')(2) 총합, 중간 집계값이 행에 끼어있음 처리
+ (3) 가전, 전자, 통신기기 카테고리 세분화된 것 처리
현재는 '운영형태별(1)' 이라는 컬럼에 온라인전용몰/온오프라인병행몰/계 세 가지 값이 존재함.
이때, 계는 우리에게 필요없는 데이터임. 왜냐하면, 만약 '운영형태별(1)' 컬럼 기준으로 거래액의 합을 집계할 때 문제가 생기기 때문임.
계는 말 그대로 온라인전용몰과 온오프라인병행몰의 거래액을 합친 수치인데, 만약 운영형태별(1) 컬럼을 기준으로 거래액의 합을 집계하면, 온라인전용몰의 거래액 + 온오프라인병행몰의 거래액 + 계 로 그 거래액의 합이 2배가 되어버리기 때문임.
따라서, 특정 컬럼에서 원하는 값을 가진 행만 지우는 코드는 아래와 같음!
result = result[result['운영형태별(1)'] != '계'](4) 날짜 컬럼 양식 불일치 문제 처리
현재 날짜 컬럼의 데이터 중에, '2024.08 p)' 처럼 날짜에 ' p)'가 포함된 경우가 있음.
즉, 날짜 컬럼 데이터들에서 ' p)'만 지워주어야 함
result['날짜'] = result['날짜'].apply(lambda x: x.replace(" p)", ""))
# 또는
def removep(x):
return x.replace(" p)", "")
result['날짜'] = result['날짜'].apply(removep)+) 만일 데이터 타입이 불일치할 경우 처리
def strtoint(x) :
if type(x) == str:
# 데이터 테이블에 숫자값이 아니라 다른 문자가이 있으면 replace
x= x.replace("대체할문자", "0")
x= int(x)
else:
pass
return x
result['거래액'].apply(strtoint)pd.read_csv 인코딩 오류
read_csv 'utf-8' codec can't decode byte 0xbb in position 1: invalid start byte만약 위와 같은 오류가 난다면, read_csv('경로', encoding='cp949') 로 수정하면 됩니다.
'cp949' codec can't decode byte 0xed in position 23: illegal multibyte sequence만약 위와 같은 오류가 난다면, read_csv의 encoding 옵션에 utf-8이나 utf-8-sig를 주면 됩니다.
