제로베이스 데이터 분석 부트캠프
1.데이터 분석 부트캠프를 시작한 계기

이 벨로그는 내가 유니티 개발자로 활동하던 시절, 새로 배운 점들을 기록하는 장소였습니다.그런데 요 몇 달 동안 새 포스팅을 잘 올리지 못했습니다.이유는 현재 제가 유니티 개발자에서 다른 커리어로 직무 전환을 하는 과정에 있기 때문입니다.입과 전, 저는 개발자 -> 퇴
2.CH 04. 데이터 조작 언어, SELECT INSERT UPDATE DELETE
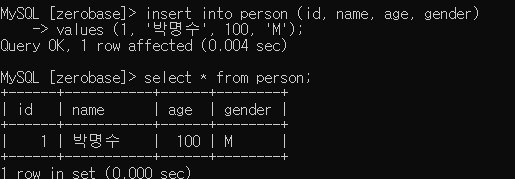
입력한 컬럼 이름의 순서와 데이터의 순서가 일치해야 함!!(단, 모든 컬럼값을 추가하는 경우에는 컬럼 이름을 일일이 지정하지 않아도 됩니다.)(INSERT할 데이터의 수가 방대하다면, 파일을 통째로 넣는 방법도 있습니다.)실습 결과테이블 내의 특정 컬럼의 데이터를 조회
3.CH 03. Table을 사용해보자
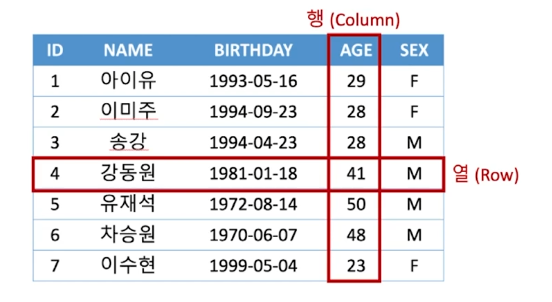
DB 안에서 데이터가 저장되는 형태이며, 행(Row)과 열(Column)로 구성됩니다.Table의 이름과 column의 이름을 지정해주어야 합니다.이 외에 다른 옵션도 존재합니다.id(int)와 name(varchar(16)) 콜룸을 가지는 mytable 이라는 이름의
4.CH 02. Database를 사용해보자

여러 사람이 공유하여 사용할 목적으로 체계화해 통합, 관리하는 데이터의 집합체사용자와 DB 사이에서 사용자의 요구에 따라 정보를 생성해주고 데이터베이스를 관리해주는 소프트웨어 ex. MySQL(structured Query Langauge)서로 관계있는 데이터 테이블을
5.CH 05. ORDER BY
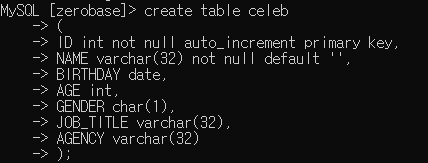
NOT NULL : 해당 컬럼에 null을 받지 않도록 합니다.AUTO_INCREMENT : 데이터를 추가할 때 자동으로 값을 오름차순으로 넣어줍니다. ID 같은 값에 좋을 듯PRIMARY KEY : 해당 컬럼을 primary key로 지정합니다.DEFAULT ~ :
6.CH 06. Comparison Operators (비교 연산자)
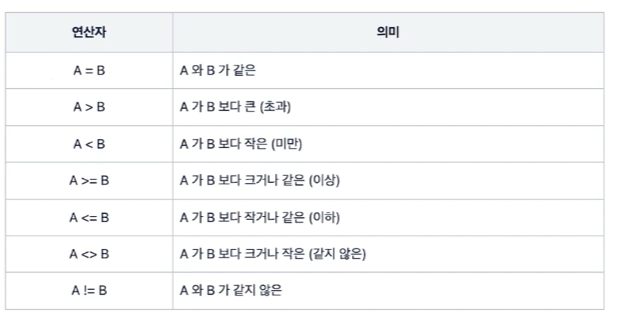
나이가 30세 이상인 데이터 검색하기🔵 흥미로웠던 점C🔵 다음 학습 계획논리 연산자에 대해 학습할 것입니다.
7.CH 07. Logical Operators (논리 연산자)
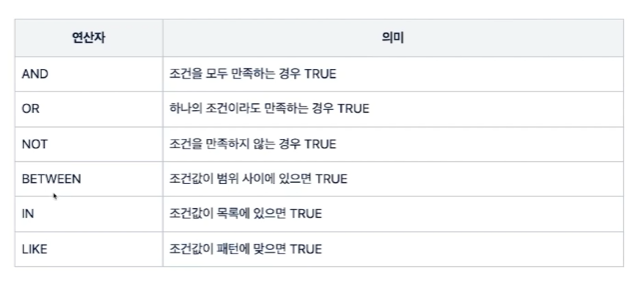
실습 결과실습 결과나이가 40보다 많거나 30보다 적은 데이터를 age 순으로 정렬합니다.실습 결과나이가 33보다 적고 여자이거나, 나이가 40보다 크고 남자인 데이터를 나이와 성별 순으로 정렬합니다.주의 사항처리 순서가 AND(1순위) > OR(2순위) 이기 때문에,
8.CH 08. Union
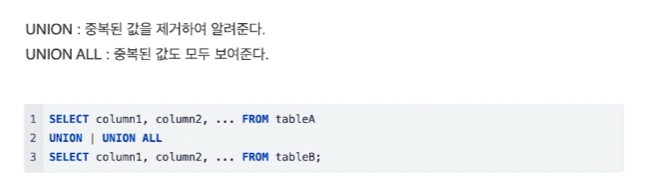
여러 개의 SQL문을 합쳐서 하나의 SQL 문으로 만들어주는 방법(단, 검색할 컬럼의 수가 같아야 한다.)세미콜론은 유니온이 끝난 후에 찍어줍니다.실습 결과test1의 모든 데이터와 test2의 모든 데이터를 중복된 값을 포함하여 검색합니다.중복된 값을 제거하여 검색하
9.CH 09. Join
두 개의 테이블에서 공통된 요소들을 통해 결합하는 방식입니다. (=교집합만 가져옴)하단 코드에서는 tableA의 column와 tableB의 column이 같은 경우에만 Join합니다.실습 결과두 개의 테이블에서, 공통영역을 포함해 왼쪽 테이블의 다른 데이터들을 포함하
10.CH 10. Concat

여러 문자열을 하나로 합치거나 연결해주는 함수입니다.컬럼이나 테이블 이름에 별칭을 생성합니다.컬럼에 Alias 사용하기select 컬럼명 as '별칭' from 테이블명;여러 개의 컬럼에 Alias 사용하기Concat과 Alias 합쳐서 사용하기실습 문제 : Join
11.CH 11. AWS RDS

AWS에서 제공하는 관계형 데이터베이스 서비스입니다.클라우드 상에 데이터베이스를 구축할 수 있습니다.1\. AWS RDS에 접근 가능하도록, 규칙을 추가하기(EC2 > 보안 그룹 > ID 클릭 > 인바운드 규칙 편집 > 규칙 추가 클릭)이렇게 하고 규칙 저장을 누릅니다
12.CH 12. SQL File & Database 백업

실습할 폴더를 생성하고, 해당 폴더로 이동합니다.VSCode에서 sql 파일 생성하기사진처럼 마우스를 올린 후, 파일 생성 버튼을 누르고 확장자를 .sql로 써줍니다.SQL 쿼리를 모아놓은 파일입니다.SQL File 실행 방법 : (1) 로그인 이후STEP 1. SQL
13.CH 14. Primary key, Foreign key
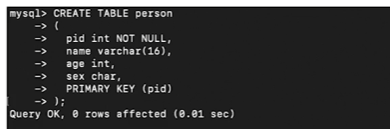
테이블을 식별하는 역할다른 데이터와 중복되지 않는 고유값이어야 함NULL 값을 포함할 수 없음테이블 당 1개의 기본키를 가짐1개의 column을 기본키로 설정할 경우Create Table 시 Primary Key (데이터명) 으로 지정해주면 됩니다.여러 개의 colum
14.CH 15. Aggregate Functions (집계함수)
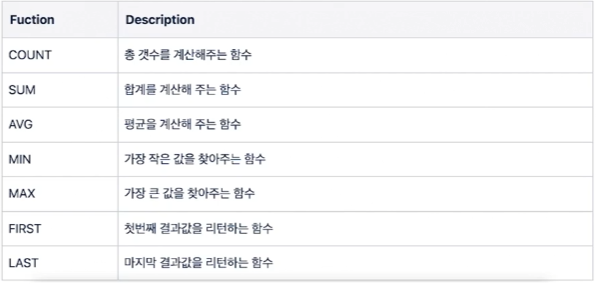
여러 컬럼 혹은 테이블 전체의 컬럼으로부터 하나의 결과값을 반환해주는 함수총 개수를 계산해주는 함수실습 문제crime_status 테이블에서 경찰서는 총 몇 군데인지 알아보세요.결과 :숫자 컬럼의 합계를 구해주는 함수실습 문제crime_status 테이블에서 범죄 총
15.CH 16. Scalar Functions

입력한 값을 기준으로 단일 값을 반환하는 함수영어를 대문자로 변경영어를 소문자로 변경, 사용법은 UCASE와 동일합니다.문자열의 일부를 반환하는 함수첫 번째 글자부터 4글자를 조회할 경우,뒤에서 4번째 글자에서 4글자를 조회할 경우,문자열의 길이를 반환하는 함수지정한
16.CH 17. SQL Subquery
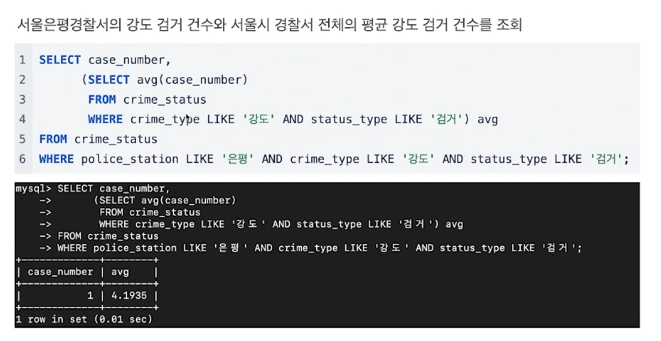
하나의 SQL문 안에 포함된 또 다른 SQL문을 말합니다.(1) 서브쿼리는 메인쿼리의 컬럼 사용 O, 메인쿼리는 서브쿼리의 컬럼 사용 X(2) 서브쿼리는 괄호로 묶어서 사용(3) 단일 행 or 복수 행 비교 연산자와 사용 가능(4) 서브쿼리에서는 order by 사용
17.[Git] CH 1. VCS (Version Control System)
협업이 가능해짐commit 하는 순간 배포(push)되어 다른 개발자에게도 버그 유발 가능인터넷이 안 되면 작업 불가능자신만의 version history Xcommit 하더라도 개인 저장소 내에 적용됨원하는 순간에 push 가능오프라인에서도 작업 가능자신만의 vers
18.[Git] CH 2~4. Git의 버전관리 그 외
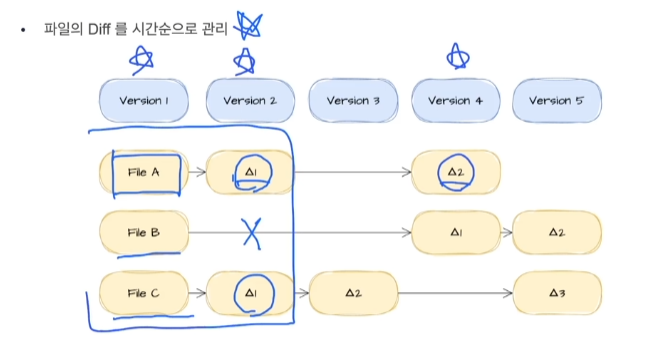
파일의 diff를 시간순으로 관리합니다.단점 : 파일이 버전별로 관리되는 게 아니었기 때문에, 특정 시점의 파일로 돌아가기가 어려웠다고 함파일을 저장하는 순간을 스냅샷으로 저장파일의 변경사항이 없는 경우, 파일을 새로 저장하지 않음Working Directory (내
19.[Git] CH 5. Git 설정

System ConfigGlobal Config (유저별로 적용해야 하는 설정인 경우)Local ConfigCRLF = 줄바꿈 문자Windows : CR(\\r) + LF(\\n) 모두 사용 (2글자)Unix or Mac : LF(\\n)만 사용 (1글자)서로 다른 O
20.[Git] CH 6. Git Repository
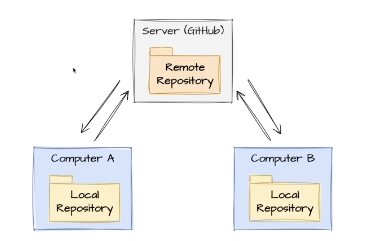
Repository(레포지터리)란, Git으로 프로젝트를 관리하는 저장소 입니다.파일과 디렉토리가 포함되며, 버전관리를 할 수 있습니다.로컬 Repository : 본인 컴퓨터의 저장소원격 Repository : 서버의 저장소git init : 프로젝트 폴더를 Git
21.[Git] CH 7. Git 기본 사용법

Working directory와 stating area의 상태를 표시합니다.파일들의 상태(staged인지?)를 확인할 때 사용합니다.Working directory에서 생성한 파일을 staging area에 추가합니다.수정 후 modified 상태가 된 파일을 sta
22.[Git] CH 8. Git Log
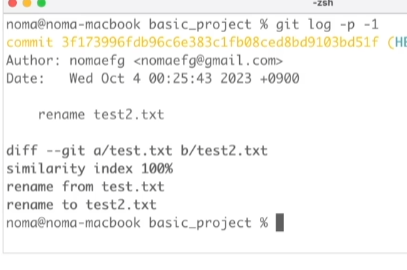
git log를 통해서 커밋 히스토리를 볼 수 있습니다.해쉬코드작성자커밋날짜diff 뒤에 변경사항이 무엇인지 나열됩니다.아래 2가지 정보만 출력합니다.해쉬코드 앞 7자리 (원래 출력되는 해쉬코드는 매우 길지만, 로그를 구분하는 데 쓰이는 문자는 앞 7자리라고 합니다.)
23.[Git] CH 9. Remote repository
원격 저장소와 연결할 때에는 원격 저장소의 url(remote_repo_url)이 필요합니다.이때, 원격 저장소의 이름을 지정할 수 있는데, 처음에는 위 코드에서처럼 origin으로 지정하는 것이 추천됩니다.이미 연결한 원격 저장소의 url 설정을 변경할 수 있는데,
24.[Git] CH 10. Checkout 과 branch
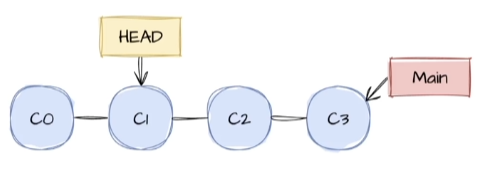
특정 시점 or 브랜치로 이동할 수 있는 명령어입니다.즉, <commit_id>일 때의 커밋으로 나의 작업 폴더를 변경해줍니다.특히, --oneline했을 때 출력되는 7자리 코드만으로도 checkout을 사용할 수 있습니다.해당 시점(=버전)으로 작업 폴더가 변
25.[Git] CH 11. Merge와 conflict
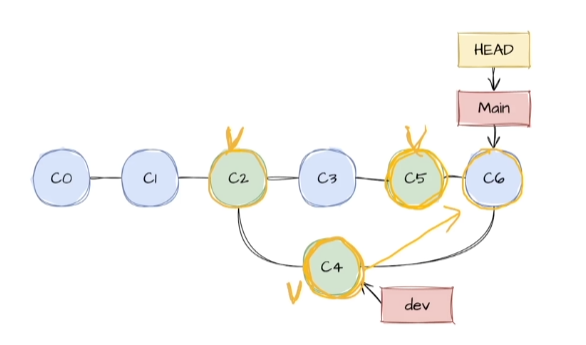
현재 위치한 버전에 다른 버전을 병합함push+pull 할 때에도 일어남기준이 될 브랜치에 HEAD를 두어야 함main의 C5에 dev의 C4를 병합하여 main에 C6시점을 만듬서로 다른 브랜치에서 같은 부분을 수정하는 경우, Auto merge가 불가능한 상황에서
26.[Git] CH 12~13. Git tag 와 README

특정 버전에 Tag를 달아 구분해야 할 때 사용합니다. (예 : 릴리즈 버전 관리)Tag 이름으로 checkout 할 수도 있습니다.git log --oneline으로 commitID 확인한 후, 원하는 commit에 tag를 생성할 수 있습니다.브랜치와 마찬가지로,
27.[Python] CH 1. 기초
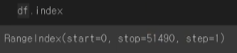
데이터프레임의 행이나 열에 접근할 수 있음n번째 행에 접근할 때 : ilocnn번째 열에 접근할 때 : iloc:,nstart = 0 : 0번째부터 시작stop = 51490 : 51489번째 행까지 존재 (stop=51490이라 되어있지만, 실제 마지막 행은 -1을
28.[Python] CH 2. 필터링과 정렬

대괄호 1개: 하나의 열만 선택 (Series로 반환)대괄호 2개: 여러 개의 열을 선택 (DataFrame으로 반환)여기에선 'item_price' 컬럼이 $1.23 같은 string으로 저장되어있다고 가정합니다.여기에서 $를 없애고, 숫자값을 float로 저장합니다
29.[Python] CH 3. 그룹핑
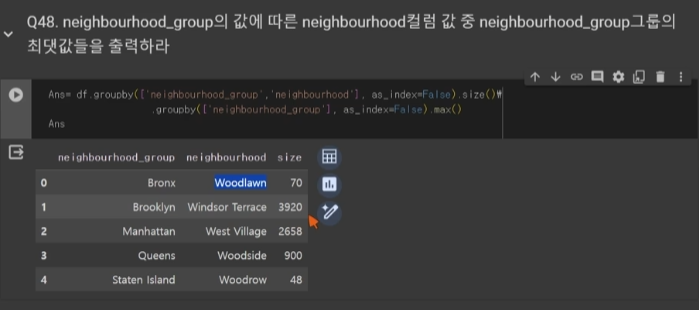
예를 들어서,포함 관계가 A > B (B가 A에 포함됨)인 두 그룹 존재A, B 기준으로 그룹핑 (A로 묶은 후 B로 묶음)A 그룹별 최댓값 출력하는 상황이 있다고 할 때,예시 :아래 사진에서 볼 수 있듯,unstack을 하기 전에는 survived의 여부(0,1)가
30.[Python] CH 4. Apply & Map
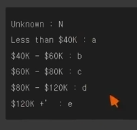
Income_Category에 포함되어있는 데이터 : 새롭게 맵핑할 값(0-9 : 0, 10-19: 10, 20-29:20 ...)\+) 비슷한 문제Credit_Limit 컬럼값이 4500 이상인 경우 1, 그 외의 경우에는 모두 0으로 변경하여 새로운 컬럼에 정의하고
31.[Python] CH 5. Time series (시계열 데이터)
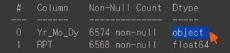
날짜 데이터의 형식이 object로 선언되어있는 상태입니다.(0시가 24시로 표시되는 경우도 처리해야 함)datetime.timedelta(days=1)는 Python의 datetime 모듈에서 시간을 더하거나 빼기 위한 시간 간격(시간 차이) 을 나타내는 객체입니다.
32.[Python] CH 6. Pivot
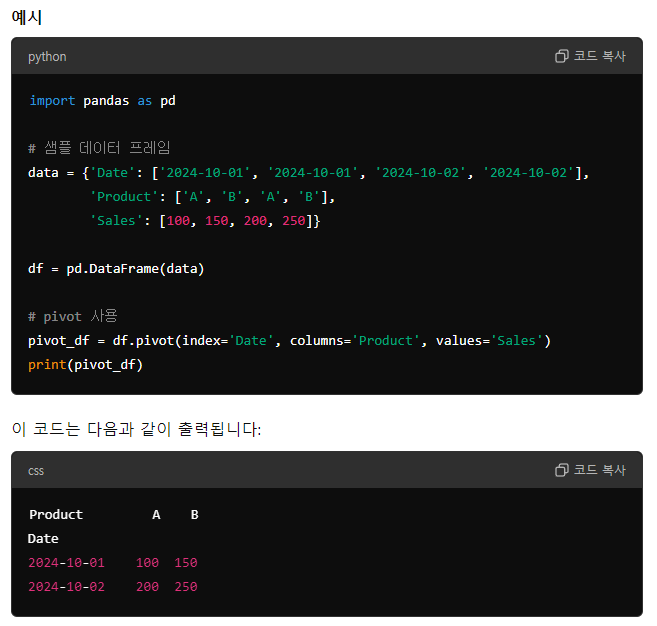
데이터프레임에서 두 개의 열을 가지고 행/열 형태의 새로운 테이블로 reshape하는 것을 의미합니다.(1) pivot(index, columnm, value)(2) pd.pivot_table(data, value, index, column, aggfunc)1\. pi
33.[Python] CH 7. Merge & Concat
간단히 말하면, pandas에서 데이터프레임을 결합하거나 연결할 때 사용되는 함수입니다.둘의 차이점을 선요약해보자면, 데이터프레임을 단순 연결할지(=concat), 공통된 키를 기준으로 병합할지(=merge)에 따라 선택하면 됩니다.역할두 개 이상의 데이터프레임을 행(
34.[Python] CH 8. Stats
이번 챕터에서는 지금까지 배운 내용을 토대로 통계에 응용하는 방법을 다룹니다.데이터셋에 남성 이름이 더 많나요, 아니면 여성 이름이 더 많나요?코드 :데이터셋을 이름별로 그룹화하여 'Count'의 합계를 구하고, names라는 변수에 할당하세요. 그리고 Count순으로
35.[Python] CH 9. Series & DataFrame
컬럼의 순서를 name, type, hp, pokedex로 변경하세요.새로운 컬럼을 생성하고, 임의의 값을 할당하세요.각 컬럼에 대한 타입을 확인하세요.hp가 40 이상인 데이터를 출력하세요.전체 데이터 셋에서 name과 type만 출력하세요.데이터 셋의 인덱스를 on
36.[Python] CH 10. Visualization (시각화)
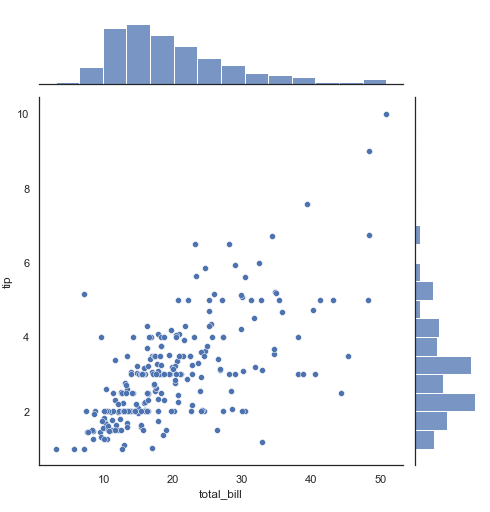
히스토그램이란?히스토그램이란 연속적인 데이터를 일정 구간 (=bin) 으로 나눈 후, 각 구간에 해당하는 값(해당 구간의 데이터의 합)을 막대 형태로 나타낸 그래프입니다.히스토그램을 통해 데이터가 정규 분포를 따르는지 한 눈에 알 수 있습니다.사용 예시 1 :사용 예시
37.[Python] CH 11. Deleting
결측치(null)를 전처리하거나, 컬럼을 삭제하는 방법에 대해 배웁니다.컬럼별로 NA 값이 존재하는지 확인하세요.'petal_length'의 10번째부터 29번째 행의 값을 NaN으로 변환하세요.NaN값을 1로 채워 넣으세요.'class' 컬럼을 삭제하세요3개의 행에
38.[Python] CH 13. 실무 속 문법

데이터프레임의 특정값 치환하기Null 값을 이전 값으로 채우기특정 조건을 만족하는 값 쉽게 변경하기inf(무한대) 데이터 null 처리lag 데이터 생성중복 데이터 처리문자열 데이터 앞 공백 제거날짜 데이터 형식 변경list 중복 제거 (list끼리 합쳤을 때 중복 생
39.[선형대수] CH 1. 벡터
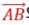
벡터는 사물의 움직임을 프로그래밍하기 위한 가장 기본적인 구성요소벡터는 크기와 방향을 가짐벡터와 달리 크기만을 갖는 값은 스칼라(Scalar)라고 함공학에서는 보통 벡터 공간 = 유클리드 공간. 따라서, 유클리드 벡터/기하 벡터/공간 벡터 라고도 부름점 A에서 점 B까
40.[선형대수] CH 2. 행렬
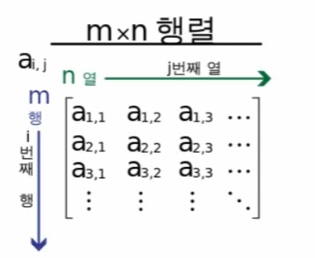
말 그대로 행(행 벡터)과 열(열 벡터) 로 이루어진 배열행x열(mxn) 로 나타낼 수 있음행은 가로로 가는 벡터라고 볼 수 있고, 열은 세로로 가는 벡터라고 볼 수 있다고 함행렬을 이용하면 복잡한 자료를 쉽게 계산하고 이해할 수 있다고 함각 Amn을 A의 m번째 행
41.[선형대수] CH 3. 선형대수학 (1) : 소개 ~ 소거법
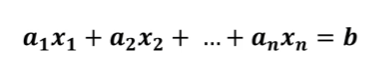
선형대수학 챕터는 다루는 개념이 많아서 포스팅을 나누려고 합니다.이번 챕터에서 가장 중요한 개념은 아래 3가지입니다.LU 분해 (LU decomposition)고유벡터와 고유 값특이값 분해(SVD)직선으로 나타낼 수 있는 방정식직선으로 나타낼 수 없는 방정식 (예를 들
42.[선형대수] CH 3. 선형대수학 (2) : 선형 방정식의 특이한 경우
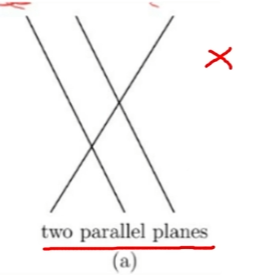
아래 그림처럼, 만일 두 개의 평행한 직선(A,B)을 가로지르는 선(C)이 있고, 두 개의 교점이 발생한다고 해도,교점(A,C)는 B를 만족시킬 수 없고, 교점 (B,C)는 A를 만족시킬 수 없기 때문입니다.물론 세 개의 선or평면이 모두 교차하면 해가 있겠지만, 아래
43.[선형대수] CH 3. 선형대수학 (3) : 역행렬
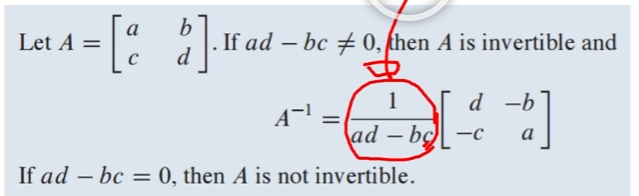
역행렬이 있다 = 해가 존재한다 는 의미데이터 분석에서는 종종 여러 변수들 간의 관계를 설명하는 선형 방정식을 다룸.예를 들어, 선형 회귀 모델은 종속 변수 𝑦 와 여러 독립 변수 𝑋 간의 관계를 설명함.이 때, 선형 방정식을 해결하기 위해서는 행렬을 사용하여 문제
44.[선형대수] CH 3. 선형대수학 (5) : LU 분해 (LU decomposition)
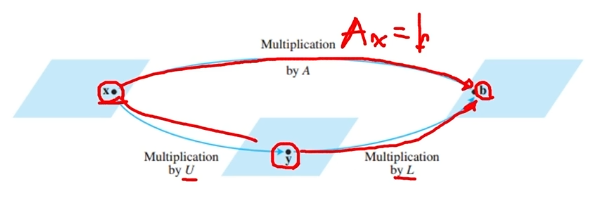
하나의 행렬을 두개 이상의 행렬 곱으로 표현하는 식을 의미합니다.Ax=b와 같은 선형 방정식에서 A행렬을 L(=하삼각행렬), U(=상삼각행렬)로 분해하는 방식을 의미합니다.단, 하삼각행렬의 대각성분은 1이어야 합니다.요약 :A를 L(=하삼각행렬), U(=상삼각행렬)로
45.[선형대수] CH 3. 선형대수학 (6) : 행렬식 개요
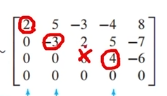
행렬의 Rank란, 행렬의 dimension을 의미함만일, 행렬은 x,y,z차원이지만 A행렬로는 x,y밖에 표현을 못 한다면, Rank=2이고 Null space=1이라고 함이게 무슨 말이냐 하면, rank == pivot column의 수 라는 말임그렇다면 pivot
46.[선형대수] CH 3. 선형대수학 (7) : 고유벡터와 고유값
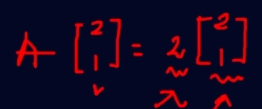
행렬은 벡터를 변환시키는 작업을 합니다. 예를 들어, 2차원 평면에서 행렬을 사용하면 벡터의 길이를 늘이거나 줄이고, 방향을 바꾸거나 회전시킬 수 있습니다.하지만, 모든 벡터의 방향이 바뀌는 것은 아닙니다.행렬을 곱해도 방향이 변하지 않는 특수한 벡터 들이 존재하는데,
47.[선형대수] CH 3. 선형대수학 (8) : 특성 방정식
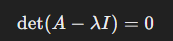
특성 방정식은 det(A-고유값) = 0 임을 의미합니다.즉, free variable이 존재함(자명한 해가 없음)을 의미합니다.그래서 임의의 변수 '람다'가 특성 방정식을 만족하면, '람다'는 행렬A의 고유값이라고 할 수 있습니다.사실 저번 포스팅에서 설명한 부분과
48.[선형대수] CH 3. 선형대수학 (9) : 대각화 (Diagonalization)
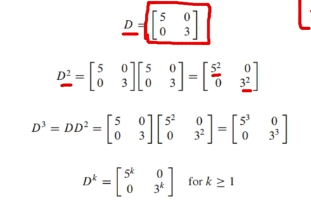
아래 그림처럼, 대각 행렬의 제곱은 대각 성분의 제곱이므로, 연산이 매우 간단해짐!즉, 대각화는 연산을 단순하게 해주는 데 목적이 있다고 할 수 있습니다.이 말은 즉슨,정사각행렬 A가 대각 행렬과 유사(similar)하다면 A를 대각화 가능(diagonalizable)
49.[선형대수] CH 3. 선형대수학 (10) : 대칭 행렬의 대각화
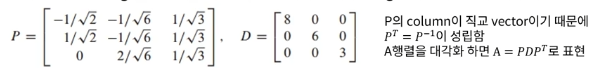
행렬 A가 있다고 할 때,정사각행렬 이면서A의 Transpose = A를 만족하는 행렬즉, 대칭 행렬은 항상 대각화가 가능하고, 이 대각화 과정으로 복잡한 행렬을 더 간단한 형태로 변환해 문제를 해결하는 데 유용합니다.고유벡터는 선형적으로 독립적임P는 column이 고
50.[선형대수] CH 3. 선형대수학 (11) : 특이값 분해(SVD, Singular Value Decomposition)

대칭행렬의 대각화 이론은 행렬 A를 PDP(^-1)로 분해하는 이론이었음하지만, 모든 행렬에 적용되지 못함.왜냐하면 D는 대각행렬이기 때문에, 행렬 A가 (mxm) 정사각 행렬이어야 함.특이값 분해는 행렬의 크기와 상관 없이 대각화가 가능함mxn 크기의 행렬 A의 특이
51.[선형대수] CH 3. 선형대수학 (12) : Reduced SVD, 유사역행렬
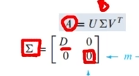
SVD시, 대각행렬 D는 대각 요소가 특이값으로 이루어진 행렬입니다.즉, Σ에는 rxr크기의 행렬에만 특이값이 포함되어있고, r+1행과 r+1열부터는 값이 0입니다.U와 V가 Σ와 곱해지면, r+1행과 r+1열부터는 0과 곱해져 무조건 0이 나오므로,어차피 0이 나오는
52.[기초통계] CH 1. 기초통계와 데이터분석 기초

수치형 데이터 (Numerical)정의:수치값으로 표현 가능한 데이터연속적 또는 이산적예시:연속적인 경우 = 키, 몸무게, 온도 등이산적인 경우 = 판매된 제품의 개수, 사람 수 등분석방법:중앙값, 평균, 표준편차 등의 통계적 수치를 통해 분석 가능함시각화 방법으로 히
53.[기초통계] CH 2. 상관관계 & 회귀분석
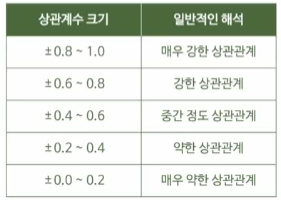
두 연속형 변수 간의 선형적 관계를 분석하는 기법선형적인 관계 정도를 나타내기 위해 상관계수 사용예를 들어, A변수가 증가함에 따라 B변수가 증가 or 감소되는지 분석하는 것(+)일 수록 강한 상관관계인 게 아니라!!!절대값일 수록 강한 상관관계를 가짐!!!두 변수의
54.[머신러닝 기초] CH 1. 회귀 문제 (2) : Feature selection 기법
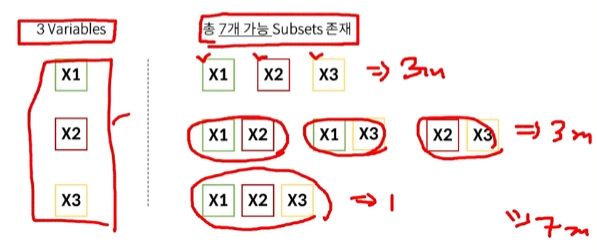
요약 한줄 요약 : Over-fitting을 해결하는 방법조금 더 긴 요약 : 회귀 분석에서, 독립 변수 X의 개수가 너무 많으면(예: 100개 이상) 모델을 fitting 하기에 너무 복잡해짐. 따라서, 중요한 Feature(X)를 선택하여 모델을 학습시켜야 함.설명
55.[머신러닝 기초] CH 1. 회귀 문제 (3) : Regularized Model 3가지

목적:모델의 회귀계수(weight)를 작게 만들어 과적합을 방지하기 위함특징 :단, feature selection은 되지 않음feature의 크기가 결과에 큰 영향을 주기 때문에, Scailing(크기 맞추기)이 매우 중요함방법:손실 함수에 회귀계수들의 제곱합을 페널
56.[SQL 분석] CH 1. 공공 데이터를 통한 시장 동향 이해 : list comprehension
리스트에 값을 하나씩 넣지 않고, 대괄호 안에 조건문이나 for문을 사용하여 리스트를 간단히 만드는 방법입니다.값을 하나씩 넣을 때list comprehension 활용값을 하나씩 넣을 때list comprehension 활용값을 하나씩 넣을 때list comprehe
57.[SQL 분석] CH 1. 공공 데이터를 통한 시장 동향 이해해보기 : 전처리
BI (Business Intelligence) 란? 조직에서 사람과 기술의 힘을 사용하여, 전략적/일상적 의사 결정 프로세스에 사용될 데이터를 수집하고 분석하는 프로세스입니다. 조직이 데이터 기반 의사 결정을 할 수 있도록 지원하는 '비즈니스 분석, 데이터 마이닝,
58.[SQL 분석] CH 1. 공공 데이터를 통한 시장 동향 이해해보기 : 반복 작업 처리
만약, 여러 csv 파일에 대해 동일한 작업을 해주어야 한다면 아래 코드 활용하기
59.[SQL 분석] CH 1. 공공 데이터를 통한 시장 동향 이해해보기 : 차트 생성해보기
요구사항 파악하기 (중요!!!) 대시보드를 키기 전에, 우리가 받은 질문이 무엇을 요구하는지, 즉 어떤 지표를 필요로 하는지부터 파악해야 한다. (중요) 예를 들어.. 그렇다면, 이번 목적인 시장 동향을 파악하기 위한 지표는 무엇일까?? Tableau 인터페이스
60.[SQL 분석] CH 1. 공공 데이터를 통한 시장 동향 이해해보기 : 대시보드 만들기
이제 이전까지 만들었던 여러 차트들을 '한 판'에 나타내보자!!하단에서 '새 대시보드' 만들기! (워크시트 아님)좌측에서 원하는 워크시트 드래그해서 우측에 놓기!이제 원하는대로 수정하면 됨 (텍스트 서식 등. ..)사용자가 원하는 값만 필터링해서 볼 수 있는 기능상품군
61.[SQL 분석] CH 1. 공공 데이터를 통한 시장 동향 이해해보기 : 인터랙티브 대시보드
원하는 대시보드 구성 후,상단 툴바에서 대시보드 > 구성 클릭새롭게 창이 뜰 텐데, 동작 추가 클릭하면 추가할 수 있는 동작 리스트가 표시됨여기서는 '필터' 동작을 추가해보겠음이름 : 동작의 이름을 정의. (나중에 동작이 너무 많아지면 이름만 보고 식별할 수 있어야 하
62.[SQL 분석] CH 1. 공공 데이터를 통한 시장 동향 이해해보기 : 관계와 조인
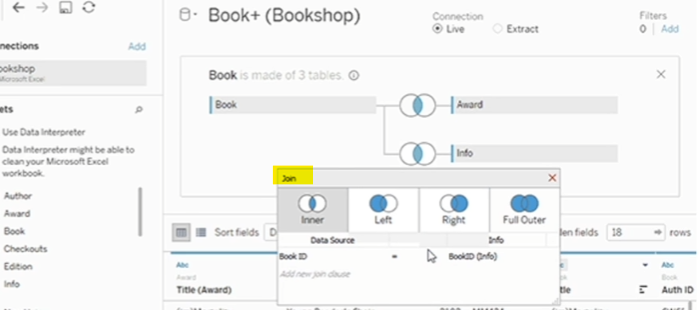
두 개 이상의 테이블을 물리적으로 결합하여 하나의 테이블로 만듬 (SQL의 조인(내부 조인, 외부 조인 등)과 비슷함)테이블 간 공통 필드를 기반으로 병합함조인은 데이터를 물리적으로 결합하므로, 결합 후의 데이터의 양이 많아질 경우 성능에 영향을 미칠 수 있음!중복되는
63.[SQL 분석] CH 1. 공공 데이터를 통한 시장 동향 이해해보기 : Looker Studio
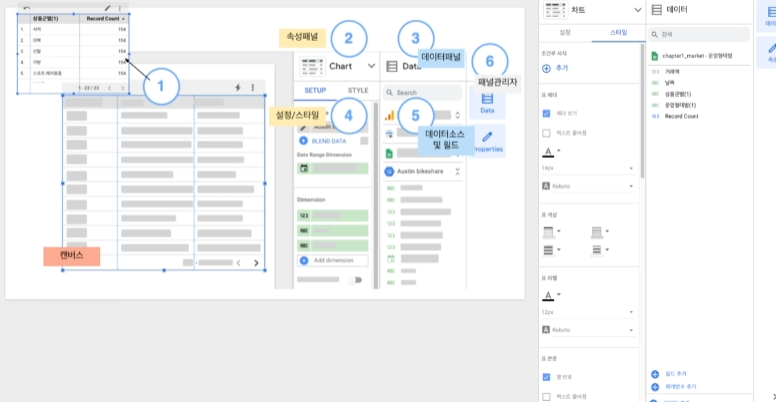
1: 캔버스. 표나 그래프를 나타낼 수 있음. 클릭 시 우측에 차트(= 2로 표시된 속성 패널) 보임2: 속성 패널. 데이터셋의 데이터 필드를 결정할 수 있음. 데이터의 디자인 요소를 변경할 수도 있음. 상단의 화살표를 누르면, 표현 가능한 다양한 형태 노출함.3: 데
64.[SQL 분석] CH 2. 이커머스 데이터를 통한 사업 현황 파악 : Google Big Query
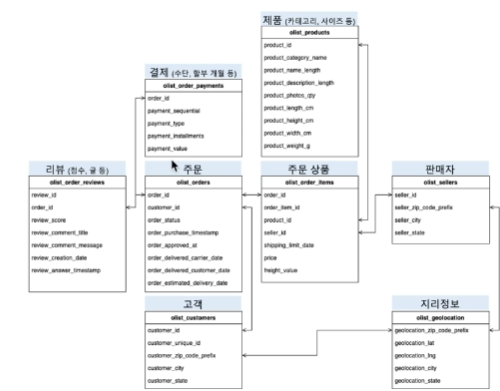
이번 실습에서 사용할 데이터셋은 ...Kaggle의 'Brazilian E-Commerce Public Dataset by Olist' 데이터셋!링크는 여기약 10만 건의 실제 브라질 이커머스 주문 데이터주문 데이터 외에도 지리 정보, 리뷰 등 다양한 데이터를 포함함2
65.[SQL 분석] CH 2. 이커머스 데이터를 통한 사업 현황 파악 : 이커머스 비즈니스 지표
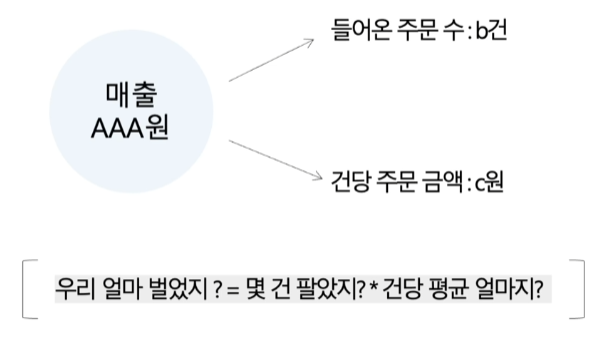
예를 들어서, 이커머스의 매출은 (간단히 말해서) 주문 건수 \* 건당 주문 금액이 됨월 매출을 당월의 주문 건수로 나누면, 해당 월의 평균 건당 주문 금액을 얻을 수 있음즉, 매출이 늘었다고 해서 주문 건수가 증가했다는 의미는 아닐 수 있음1번에서는 건당 평균 금액을
66.[SQL 분석] CH 2. 이커머스 데이터를 통한 사업 현황 파악 : Big Query 유용한 함수

except 이용하기replace 이용하기예를 들어서, price라는 컬럼에 1000을 곱해서 import하고 싶을 때...CAST 이용하기SAFE_CAST 이용하기결과이 외에도, 오류를 발생하지 않는 SAFE 연산은 다양함특히, DIVIDE의 경우 0을 나누는 경우를
67.[SQL 분석] CH 2. 이커머스 데이터를 통한 사업 현황 파악 : 과제 실습

코드 1:코드 2:위처럼 inner join의 유무로 2가지 코드를 써봤음.코드 1은 order_items 테이블과 inner join을 하므로 실제 구매가 발생한 주문에 한하여 데이터를 수집함코드 2는 전체 주문에 대하여 데이터를 수집함(만약 취소된 주문이나 구매가
68.[SQL 분석] CH 2. 이커머스 데이터를 통한 사업 현황 파악 : AD HOC QUERY

먼저,애드혹 쿼리(ad-hoc-query)는 사용자가 직접 쿼리 명령 및 함수를 사용하여 직접 입력하는 방식으로 데이터를 추출하는 쿼리를 의미함(출처: https://docs.logpresso.com/ko/enterprise/4.0/ui/query)코드코드즉,
69.[SQL 분석] CH 2. 이커머스 데이터를 통한 사업 현황 파악 : 빅쿼리로 만든 데이터 tableau에 올려보기
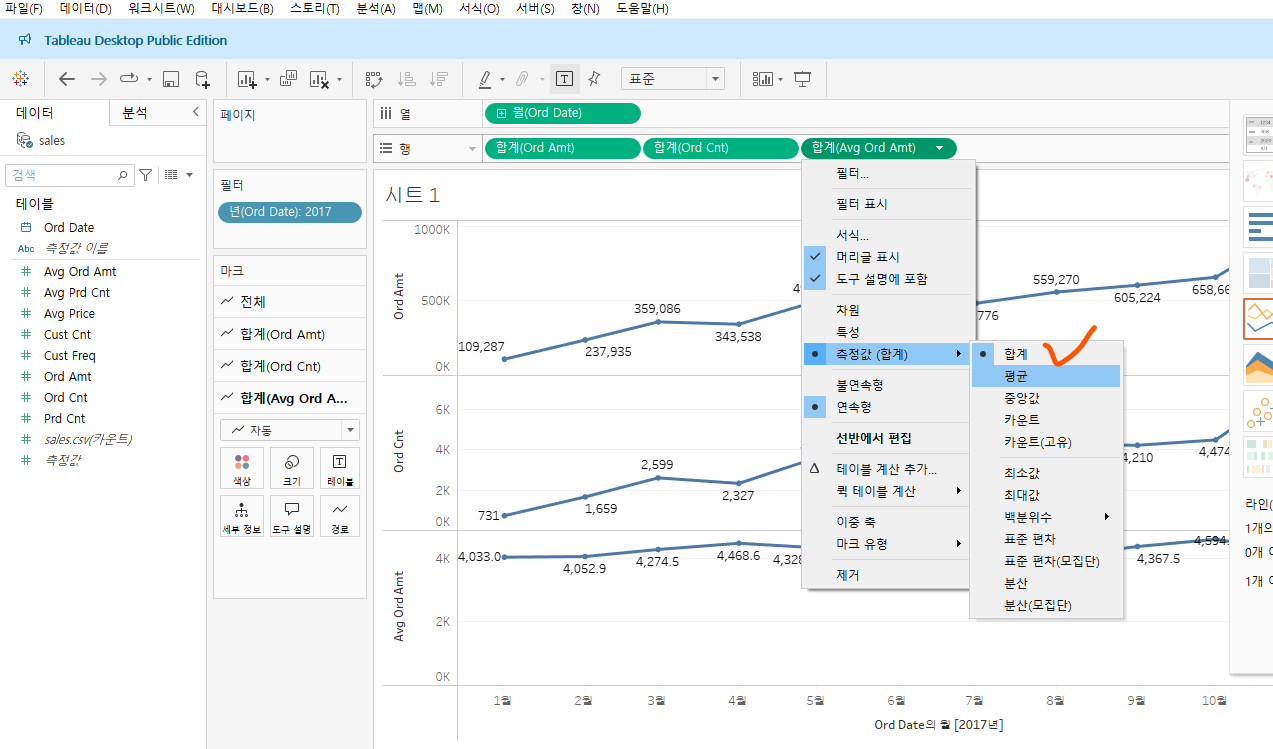
빅쿼리로 다듬은 데이터를 Tableau에 올려 시각화해보기주문 금액 합계(ord_amt)와 주문 수 합계(ord_cnt)는 그대로 더블클릭해서 행에 올리면 되지만,평균 주문 금액(avg_ord_amt)는 그냥 더블클릭해서 올리면 '합산(sum)'을 계산해버림!!!따라서
70.[SQL 분석] CH 2. 이커머스 데이터를 통한 사업 현황 파악 : Tableau 세일즈 대시보드 제작하기
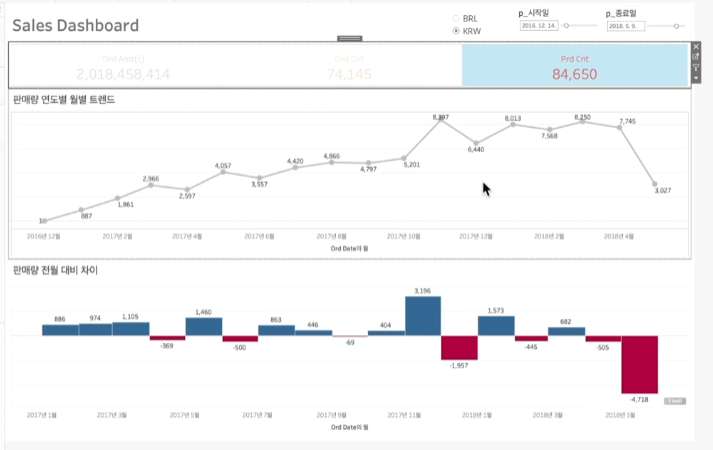
이런 대시보드를 만들어 볼 예정통화 범위 (브라질 돈, 한국 돈) 라디오 버튼 선택시작일/종료일 슬라이더 선택하이라이트 및 필터링특히, '통화 범위 (브라질 돈, 한국 돈) 라디오 버튼 선택'을 만들기 위해선를 다룰 수 있어야 함데이터 패널에 마우스 오른쪽 클릭 > 매
71.[SQL 분석] CH 2. 이커머스 데이터를 통한 사업 현황 파악 : 시각화 팁
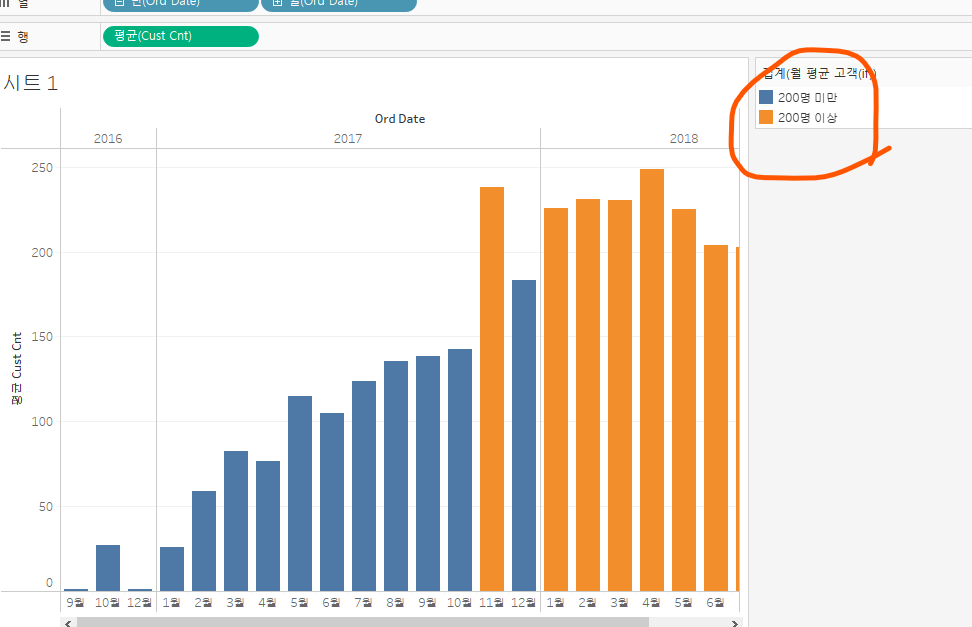
아래 사진처럼 내가 원하는 숫자를 기준으로 색상을 나눠주고 싶을 때계산된 필드 만들기 > 아래처럼 써주기위에서 생성한 필드를 마크 카드의 '색상'에 드래그해주면 됨!위와 같이 조건이 1개인 경우는, iif로 아래처럼 간단히 써줄 수도 있음elseif 로 다른 조건 추가
72.[SQL 분석] CH 2. 이커머스 데이터를 통한 사업 현황 파악 : Looker Studio 대시보드
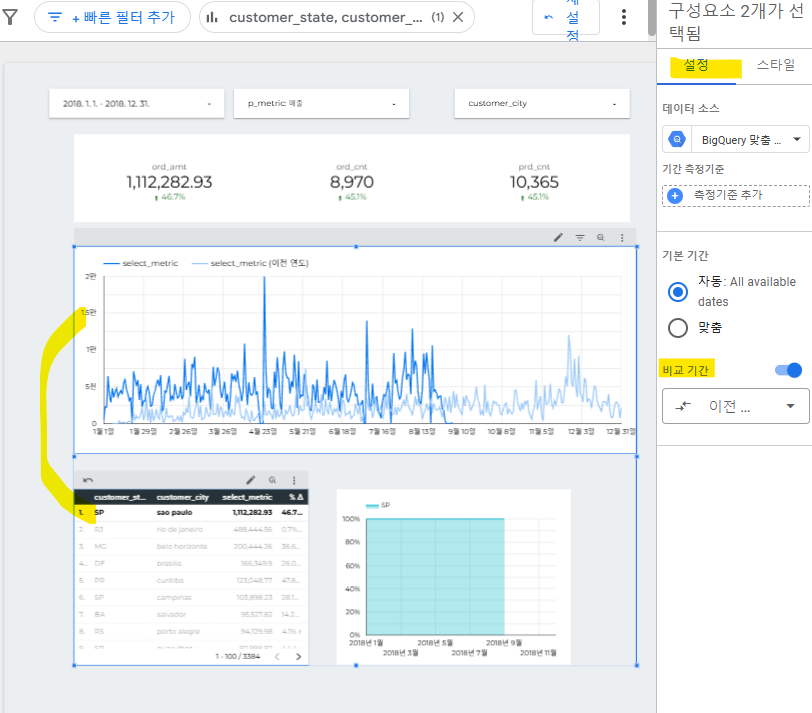
원하는 차트 선택한 다음, 설정 탭 > 비교 기간 ON 하고 이전연도or이전월 등으로 설정해주기그럼 아래 그림처럼 이전 연도 값이 같이 표시됨비교 기간을 설정하면 처음에는 %로 나옴.이 수치를 절대량으로 변경하려면, 원하는 그래프를 선택한 후, 스타일 탭 > 절대 변경
73.[SQL 분석] CH 3. 고객 행동 분석을 통한 서비스 헬스체크 : 데이터셋 소개, 고객 행동 지표
CH2에서는 '주문' 데이터, 즉 이미 결제 완료한 고객들의 데이터들을 다루었음.하지만 실제 서비스에서는 결제완료 고객 수보다, 방문 고객 수가 훨씬 많음.CH3에서는 결제 이전에 무슨 일이 일어나고 있는지 체크함.이번 실습에서 사용할 데이터셋 :https:/
74.[SQL 분석] CH 3. 고객 행동 분석을 통한 서비스 헬스체크 : Tableau 대시보드 실습

위와 같은 요청이 들어왔다고 가정하고, 대시보드 만들어보기우선 우리 쇼핑몰에 몇 명이 들어오는지 확인해야 해요 = 활성 유저 숫자 확인우리에게 중요한 행동을 몇 명이나 하는지도 알고 싶어요! = 중요한 행동이 무엇인지 검토, 모수(값)와 비율(%)을 전부 제공하자그래서
75.[SQL 분석] CH 3. 고객 행동 분석을 통한 서비스 헬스체크 : Tableau 과제

요청 사항참고 사항'week'와 'day' 둘 중 하나를 선택할 수 있는 매개변수 p_date 생성하기아래와 같이 p_date 사용하여 거래액의 비율차이 집계하는 계산된 필드 생성해주기p_date 사용하는 날짜 필드 만들어주기행/열 선반에 위에서 만든 필드 올려주고,
76.[SQL 분석] CH 4. HR 데이터를 통한 채용 기획하기 : Python 시각화

위 과정을 조금 더 자세하게 풀어보면,DB는 MySQL,SQL 쿼리 작성은 DBeaver,Python은 구글 Colab,BI는 Power BIData Literacy : 데이터 문해력원본 피봇테이블unstacklevel = -1 : 앞의 index는 그대로 index에
77.[SQL 분석] CH 4. HR 데이터를 통한 채용 기획하기 : DBeaver

아래 블로그에서 잘 설명해주셨다.요약하자면,1\. Connet to a database 창에서 Driver Properties 탭 클릭 2\.allowPublicKeyRetrieval=trueuseSSL=false위 2개 키를 추가해주거나, 이미 있으면 값을 변경해주기
78.[SQL 분석] CH 4. HR 데이터를 통한 채용 기획하기 : DBeaver (Join 등)
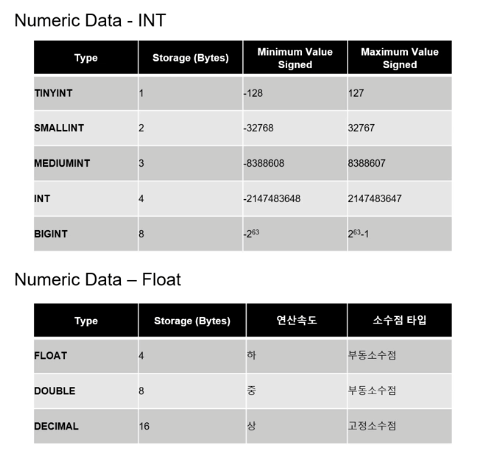
어떤 TEXT를 입력할지 고정된 게 아니라면, 대부분 VARCHAR 사용함MySQL에서 대소문자 구분 설정값 확인하는 법(대소문자 구분 여부를 직접 설정해줄 수도 있음)데이터 타입을 VARBINARY로 설정하면, OS와 관계 없이 대문자와 소문자를 구분해줌엔티티 관계도
79.[SQL 분석] CH 4. HR 데이터를 통한 채용 기획하기 : Window Function

집계된 결과값을 기존 데이터에 추가하여 보여줌합계, 평균, 순위 매기기, 순서 조작 등 가능사용 방법예시둘 다 그룹화 집계 함수라는 공통점이 있지만, 아래처럼 차이가 있음(그룹 쌍만큼만 보여줌)(집계값이 새로운 컬럼으로 추가됨)Window Function을 아래처럼 여
80.[SQL 분석] CH 4. HR 데이터를 통한 채용 기획하기 : Power BI

csv파일을 불러와서 프로젝트를 진행했을 때,이 csv파일의 경로가 변경되면 이후에 Power BI 파일을 열 수 없다고 함!!따라서 갑자기 파일이 안 열린다면, 연결된 csv 파일의 경로가 바뀌진 않았는지 확인하기만약 아래처럼 첫 행의 컬럼명을 읽지 못하고, Colu
81.[SQL 분석] CH 5. 재고 분석을 통한 물류 기획 관리

데이터셋 :Kaggle의 Historical Sales and Active InventoryFile_Type : Historical = 악성 재고, Active = 활발히 팔리는 제품분석 목표 :입고량판매량재고권장 판매가실 판매가SKUUnit Quantity (상품 개
82.[SQL 분석] CH 5. 재고 분석을 통한 물류 기획 관리 : SKU Grade 기획

창고 계약 기간이 끝나기 전에 재고를 최대한 처리해야 하는 상황으로 가정SKU Grade 분류 계획SKU Grade별 상세 분류 기준상위 n%는 WINDOW Function의 percent_rank() 활용하기사용 예시는 아래 사진 참고(참고로, Window Funct
83.[SQL 분석] CH 5. 재고 분석을 통한 물류 기획 관리 : Power BI
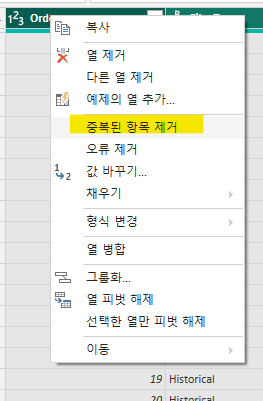
Power BI 킬 때마다 하면 좋은 습관 : 데이터 변환 창에 가서, 모든 컬럼 선택 후, 마우스 우클릭 > 중복 행 제거그냥 Sum을 하면, ItemCount와 PriceReg의 합계를 따로 구하기 때문에,(ItemCount \* PriceReg)의 합을 구하기 위
84.[SQL 분석] CH 6. 유통 SCM 데이터 분석
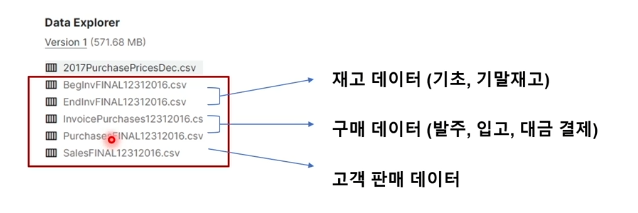
Supply Chain Management (공급망 관리) 의 약자로,생산자, 공급자, 고객에 이르는 물류의 흐름을 하나의 가치사슬 관점에서 파악하고,공급망의 구성요소들 사이에서 이루어지는 전체 프로세스의 최적화를 달성하고자 하는 기법https://www.ka
85.[SQL 분석] CH 7. 대규모 주류 판매 데이터 분석
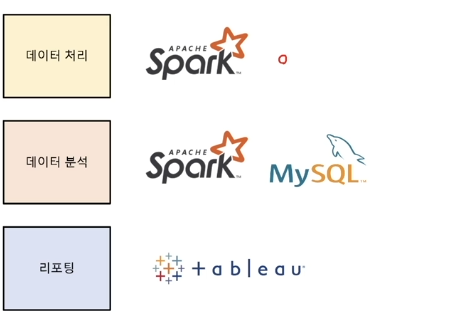
데이터의 양이 정말 방대해지면 데이터 로드하고 통계치 하나 계산하는 데에만 몇 시간씩 이어진다고 함.. EDA하고 시각화하고 인사이트까지 뽑아야 하는데.. 시간이 너무 소요되는 것임따라서, 대용량의 데이터를 빠르고 효율적으로 처리하는 방법이 필요해짐과정별로 사용할 툴분
86.[SQL 분석] CH 8. 지역별 주류 판매 데이터 분석
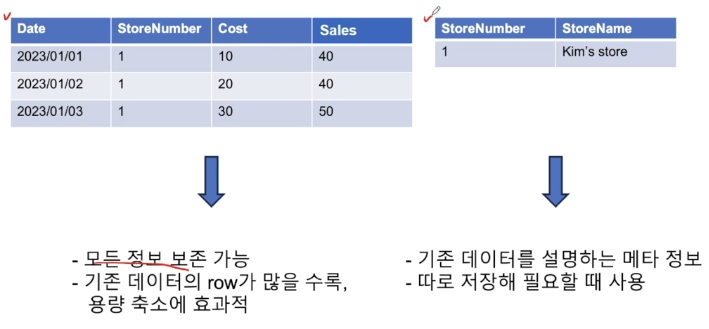
데이터에 관한 구조화된 데이터즉, 다른 데이터를 설명해주는 데이터예를 들어, 파일의 저장 날짜, 종류, 태그 등주로 사용되는 쿼리는 DML, DQL자주 사용하는 쿼리쿼리 실행 순서는 쿼리를 작성한 순서가 아니다!!!따라서, as로 명칭을 붙였더라도 실행 순서에 따라 명
87.[SQL 분석] CH 9. 분석 결과를 바탕으로 주류 시장 대시보드 제작하기 (Tableau)

분석의 관점을 명확히 표현했는가시각화 자료를 보여줄 대상자 층을 고려하였는가자꾸 까먹어서 쓰는..아래처럼 하나의 엑셀 파일에 분석할 파일을 시트로 다 넣어주기xlsx 파일로 저장하기Tableau에서 열기완료데이터에서 만들 수 있는 시각화 정보는 정말 무궁무진함.따라서,
88.[파이썬 분석] CH 0. Anaconda & Jupyter 환경설정

이번 실습에서는 ds_study 라는 이름으로 가상환경 생성 + 사용하기현재 연결된 가상 환경에 \* 표시를 해줌(패키지가 필요한 특정 가상환경에 접속했는지 체크하기)ipykernel은 내 컴퓨터와 jupyter 노트북을 연결해주는 기능을 한다.(ipython이 설치된
89.[파이썬 분석] BG-NBD와 Gamma-Gamma 기반 CLTV 예측
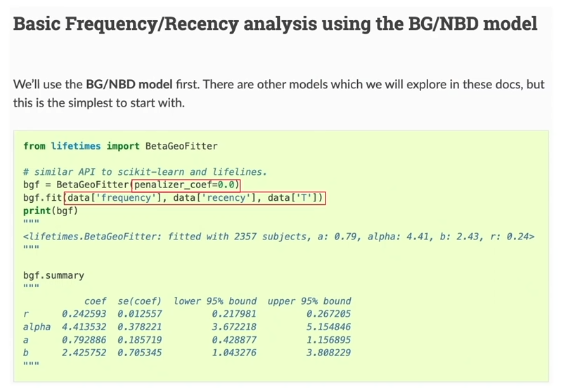
진행을 위해 필요한 최소한의 값 :frequencyrecencyT (Time)penalizer_coef는 모델 객체 초기화 시 사용하는 하이퍼 파라미터로, 복잡성을 제어하고 과적합을 컨트롤하는 데에 사용됨. 공식 문서에 따르면 0.001 - 0.1 사이의 값으로 설정하