데이터 분석 FLOW

위 과정을 조금 더 자세하게 풀어보면,

이번 챕터에서 사용해볼 툴
DB는 MySQL,
SQL 쿼리 작성은 DBeaver,
Python은 구글 Colab,
BI는 Power BI
EDA 에는 무슨 과정이 포함될까?
요청 사항
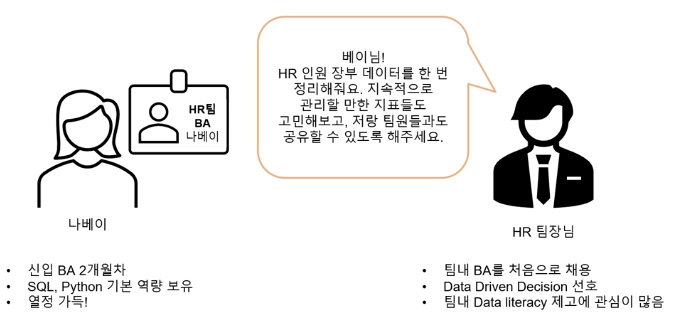
Data Literacy : 데이터 문해력
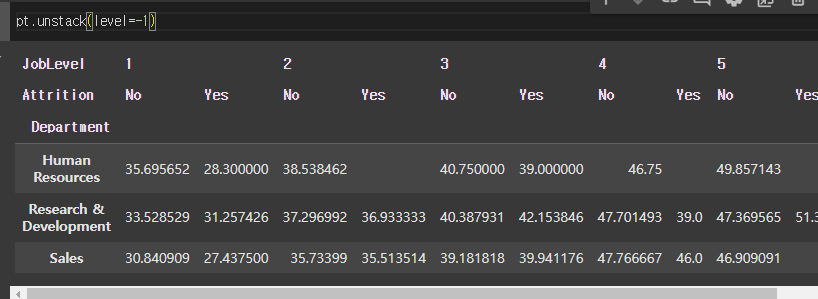
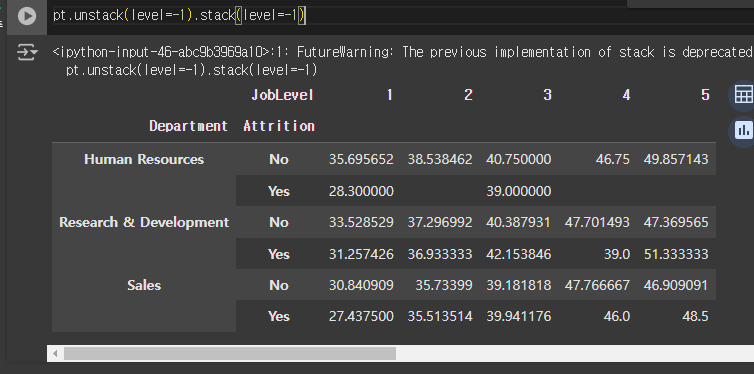
stack vs unstack
원본 피봇테이블
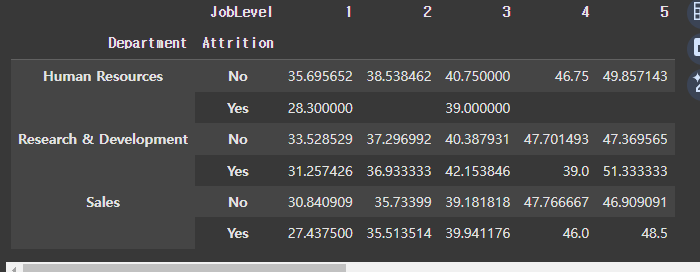
unstack
- level = -1 : 앞의 index는 그대로 index에 냅둠
stack
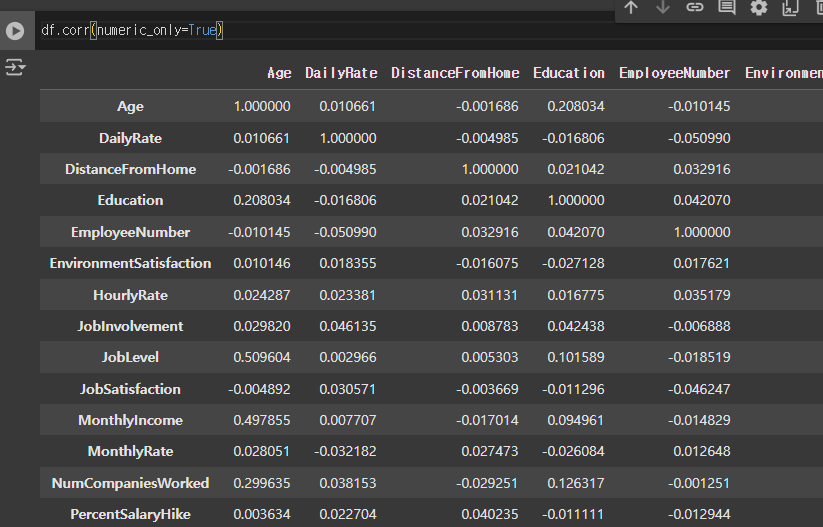
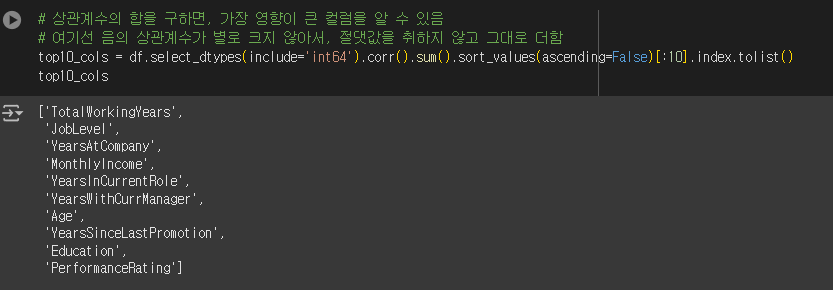
corr
수치형 변수에 대해서만 corr을 구할 수 있음
시각화
상관계수 시각화
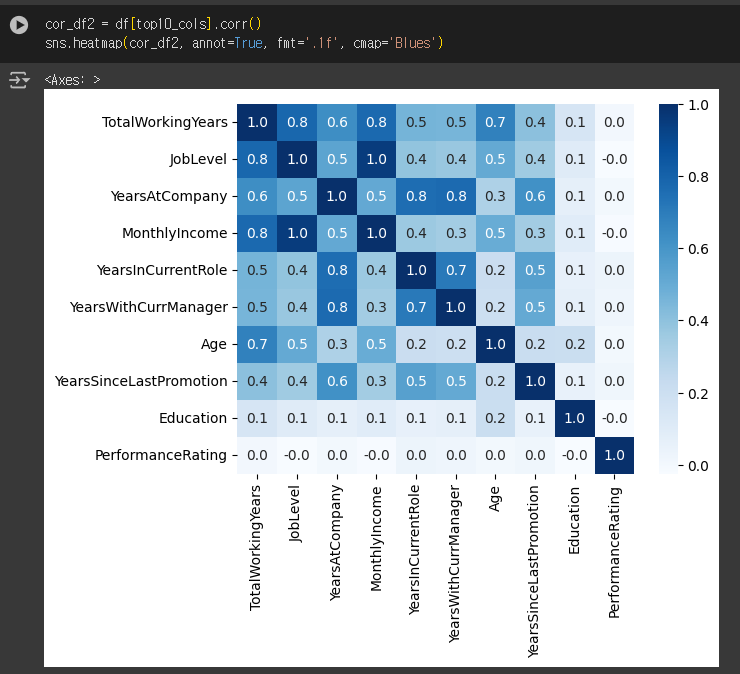
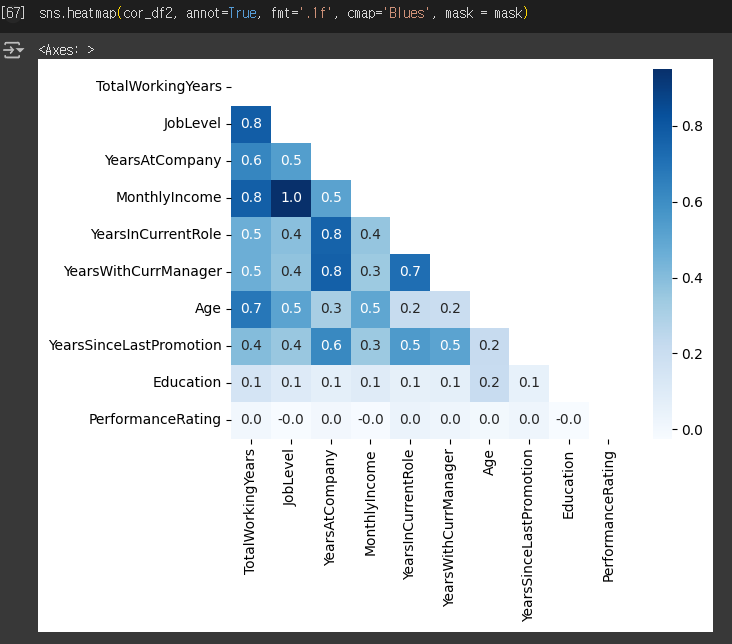
+) 마스크 씌우기
FacetGrid
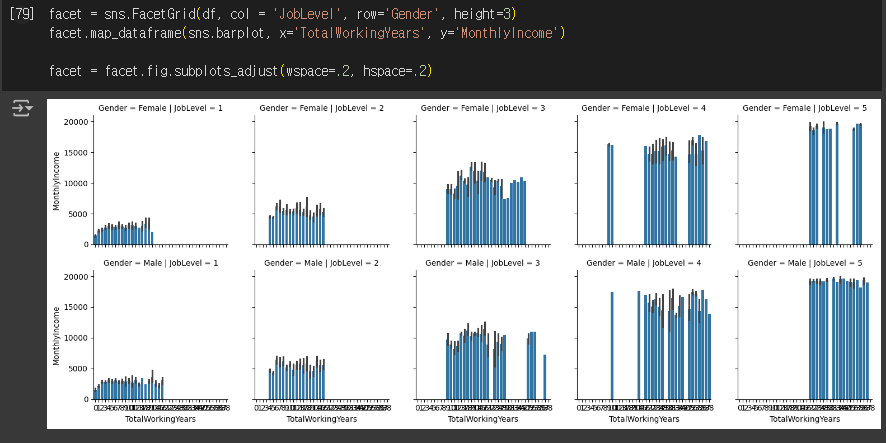
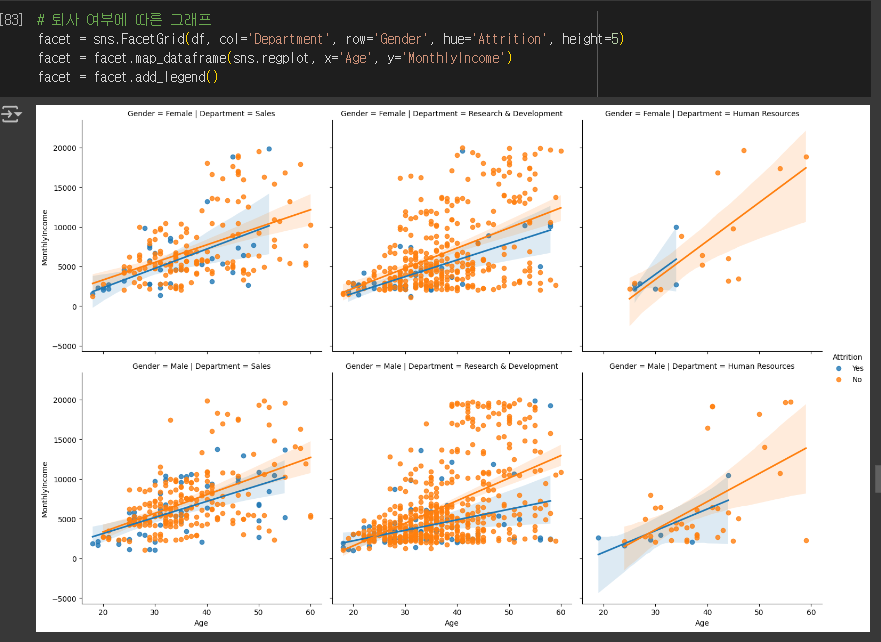
# 퇴사 여부에 따른 그래프
facet = sns.FacetGrid(df, col='Department', row='Gender', hue='Attrition', height=5, hue_order=['No', 'Yes'], palette = {'Yes': 'red', 'No': 'gray'})
facet = facet.map_dataframe(sns.regplot, x='Age', y='MonthlyIncome', fit_reg=False)
facet = facet.add_legend()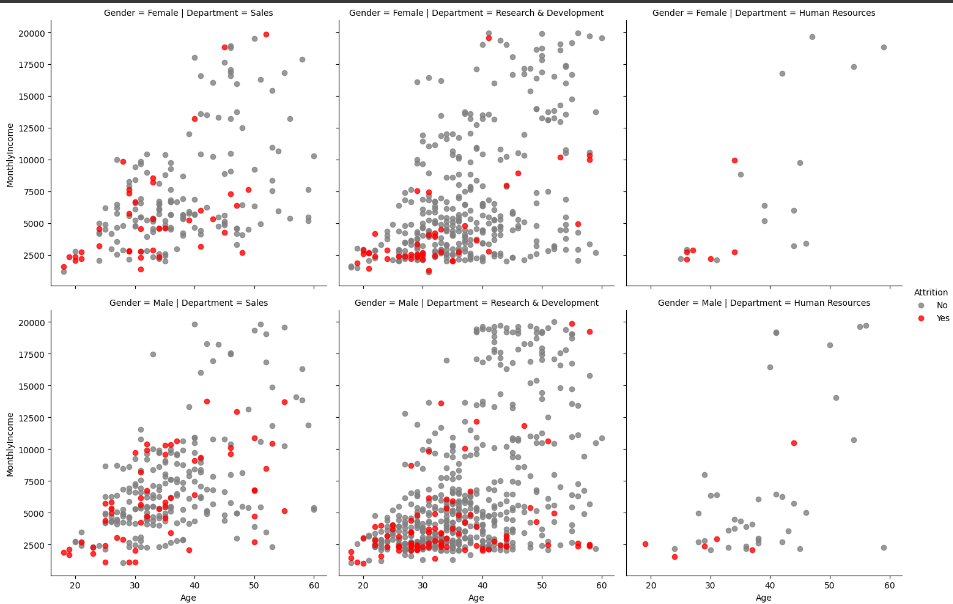
facet = sns.FacetGrid(df, col='OverTime', row='Department', hue='Attrition', height=5, palette = {'Yes': 'red', 'No': 'gray'})
facet = facet.map_dataframe(sns.barplot, x='WorkLifeBalance', y='JobSatisfaction')
facet = facet.add_legend()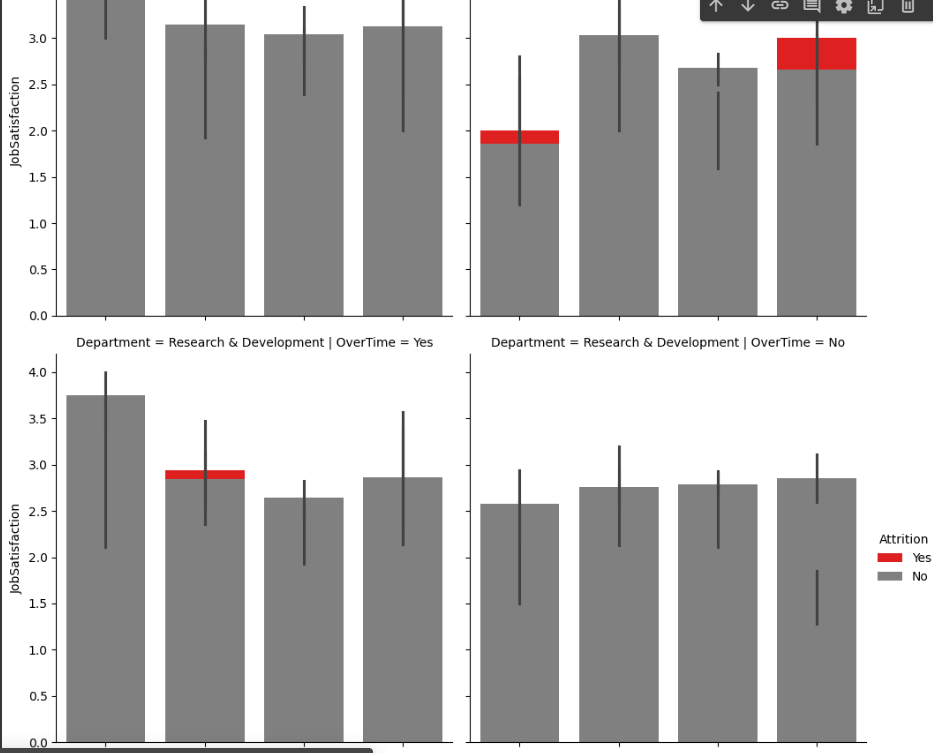
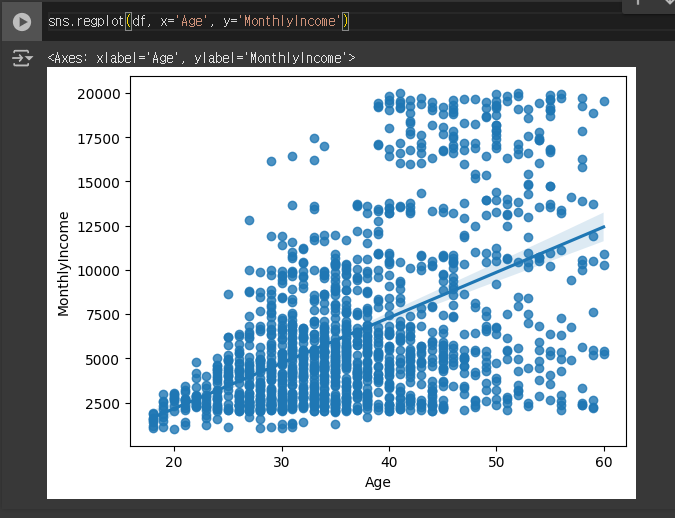
Regression Plot (RegPlot)
Histogram (히스토그램) + 반복문
hist = ['Age', 'DistanceFromHome', 'JobSatisfaction', 'WorkLifeBalance', 'MonthlyIncome', 'YearsAtCompany']
plt.figure(figsize=(10,20))
for i, col in enumerate(hist):
axes = plt.subplot(6, 3, i+1)
sns.histplot(x=df[col], hue=df['Gender'])
plt.tight_layout()
plt.show()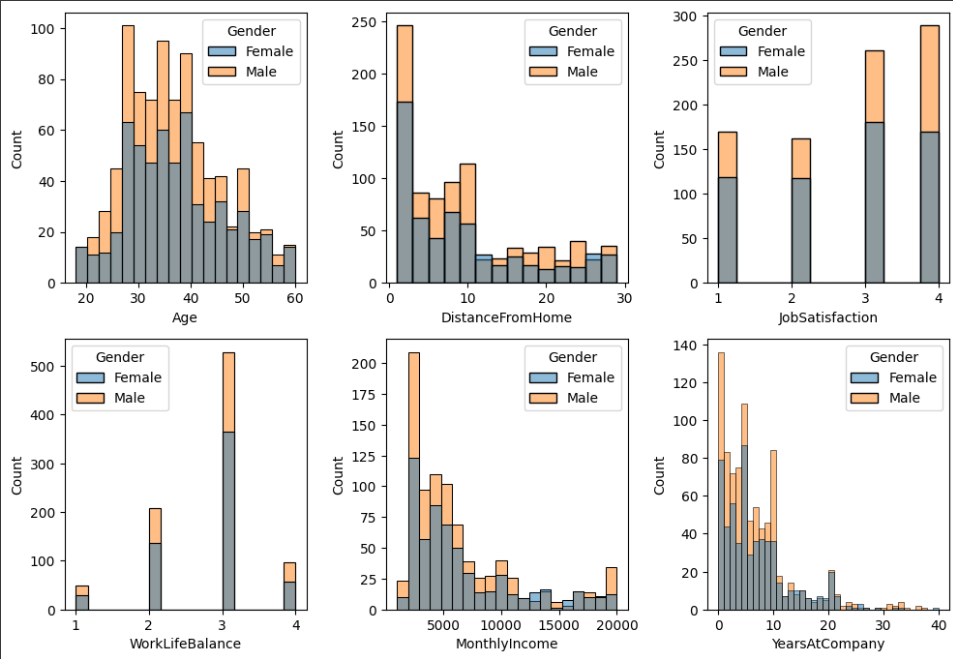
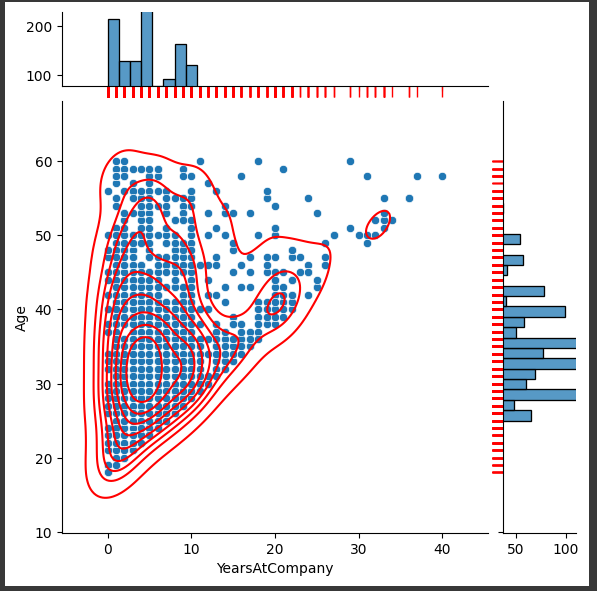
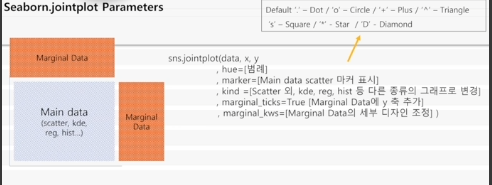
JointPlot
회귀선 같이 나타내기
sns.jointplot(df, x='Age', y='YearsAtCompany', kind='reg')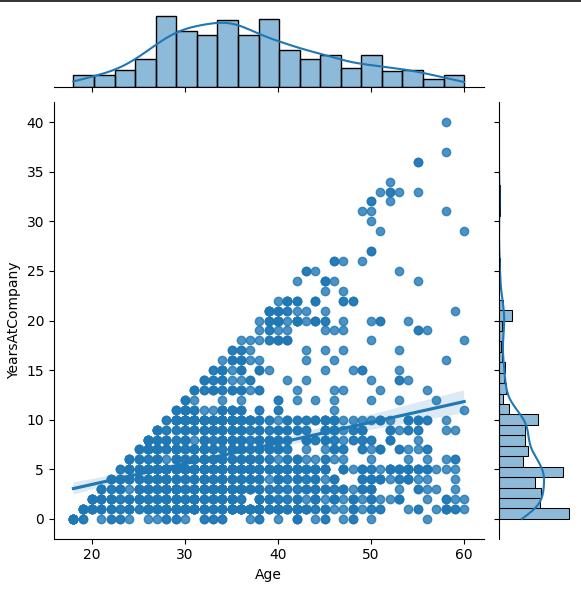
hue 나타내기
sns.jointplot(df, x='Age', y='YearsAtCompany', hue='Gender')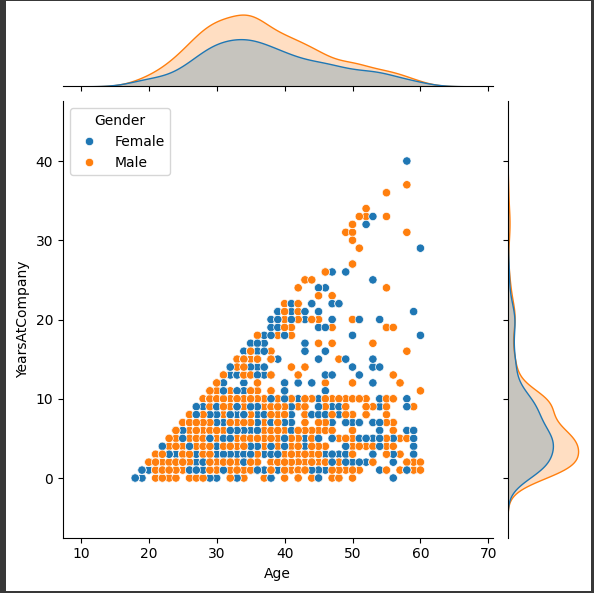
응용
j=sns.jointplot(df, x='YearsAtCompany', y='Age',
markers='+',
#margin에 숫자 표시
marginal_ticks=True,
marginal_kws=dict(bins=30, rug=True))
j.plot_joint(sns.kdeplot, color='r')
# 아래 코드 넣었다 뺐다 해보기
j.plot_marginals(sns.rugplot, color='r', height=-.15, clip_on=False)