Spark 의 필요성
데이터의 양이 정말 방대해지면 데이터 로드하고 통계치 하나 계산하는 데에만 몇 시간씩 이어진다고 함.. EDA하고 시각화하고 인사이트까지 뽑아야 하는데.. 시간이 너무 소요되는 것임
따라서, 대용량의 데이터를 빠르고 효율적으로 처리하는 방법이 필요해짐
과정별로 사용할 툴
Spark란?
분산 클러스터 컴퓨팅 오픈소스 프레임워크
분산 클러스터?
시스템의 성능을 향상시키기 위해, 계산 부하량을 여러 노드에서 병렬 처리하도록 구성하는 방식
Spark 구조
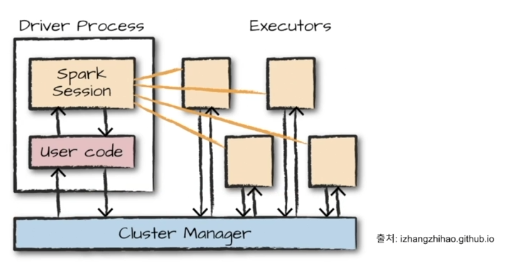
Cluster Manager :
- 사용 가능한 자원을 파악
- 클러스터의 데이터 처리 작업을 관리하고 조율
- 사용자는 클러스터 관리자에 스파크 어플리케이션을 제출
- 붙이거나 뗄 수 있는 일종의 컴포넌트
Driver Process:
- 클러스터 노드 중 하나
- 드라이버 프로그램의 명령을 Executor에서 실행하도록 분석, 배포, 스케줄링
Executor:
- 각 executor는 드라이버 프로세스가 할당한 작업을 수행
- 진행 상황을 다시 드라이버 노드에 보고함
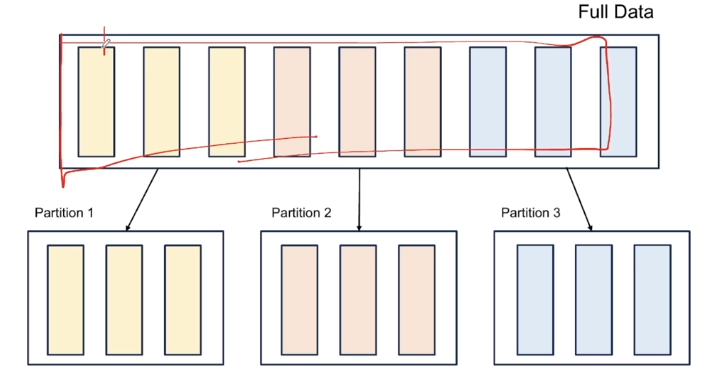
Spark의 데이터 처리 방식 1 : Parition
- 모든 executor가 병렬로 작업을 수행할 수 있도록, '파티션'이라고 불리는 청크 단위로 데이터를 분할함
- 파티션은 클러스터의 물리적 머신에 존재하는 Row들의 집합
즉, Spark의 병렬성은 Partition와 executor의 개수로 결정됨
Spark의 데이터 처리 방식 2 : Transformation
- Spark의 핵심 데이터 구조는 불변함
- 변경을 원할 때, Transformation으로 Spark에게 변경 방법을 알려주면, Spark는 논리적인 실행 계획을 세우게 됨. (실제로 연산이 일어나는 것은 아님)
Spark의 데이터 처리 방식 3 : Lazy Evaluation & Action
Lazy Evaluation :
-
특정 연산 명령이 내려진 즉시 데이터를 수정하지 않고, 원시 데이터에 적용할 Transformation만 실행 (액션 전까지 전체 데이터 흐름을 최적화할 수 있다는 장점)
-
예를 들어서, 어떤 원시 데이터에 대해 A라는 계산과 B라는 계산과 C라는 계산을 해서, 결과물을 얻고자 함. 이때, A, B, C 계산을 순차적으로 모두 진행하는 것이 아니라, 전체적인 계산 과정을 최적화한 후에 결과물을 얻는다는 것임
Action :
- 실제 연산을 수행하기 위한 사용자 명ㅇ령 (Transformation으로부터 결과를 계산하도록 지시함)
- 예를 들어, 카운트/콘솔에서 데이터를 보는 액션/데이터를 저장하는 액션 등, 실제로 데이터를 변형하는 행동은 아닌 것들
Spark의 카탈리스트
- Transformation을 적용할 때, 스파크 SQL은 논리 계획이 담긴 트리 그래프를 생성함.
- Optimizer에 의해 최적의 논리를 받아와 데이터를 반환해주기 때문에, 성능이 좋음
카탈리스트의 논리 계획 4단계
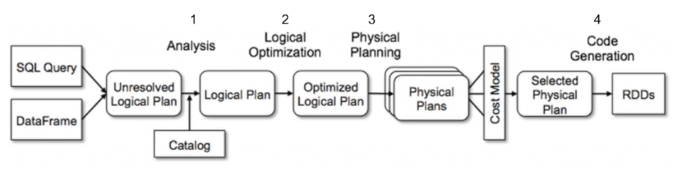
- Analysis : 컬럼의 타입, 컬럼이 Valid한지 등 기본적인 분석 수행
- Logical Optimization : 연산 과정 최적화
- Physical Planning : 실제로 수행할 연산을 반환
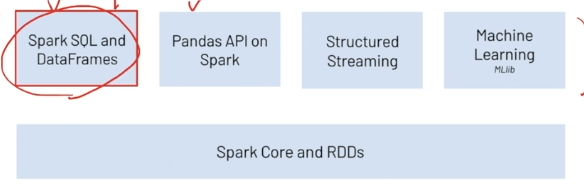
Pyspark 란?
-
Python 환경에서 Apache Spark를 사용할 수 있게 해주는 API
-
대용량 정형 데이터 처리를 위한 SQL 인터페이스를 지원함 (SQL 쿼리 사용 가능)
-
Pandas API를 지원하여 Pandas 문법 사용 가능함
-
DataFrame 형식으로 데이터를 표현함 (RDBMS의 table과 유사한 2차원 구조로, 사용하기 용이함)
-
분류, 회귀, 차원 축소 등 다양한 머신러닝 기능 제공함
실습에 사용할 데이터셋
Kaggle의 Iowa Liquor Sales (아이오와주 주류 판매 데이터)
요구 사항 가정

데이터셋 다운로드
아래 코드 참고해서,
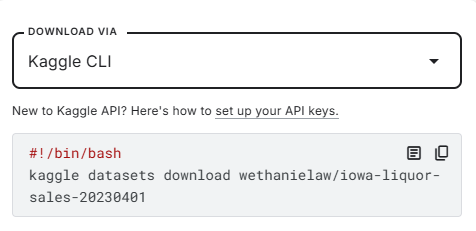
!mkdir -p ~/.kaggle/
!cp kaggle.json ~/.kaggle/
!chmod 600 ~/.kaggle/kaggle.json
!kaggle datasets download -d wethanielaw/iowa-liquor-sales-20230401
!unzip iowa-liquor-sales-20230401.zip주의사항
이 데이터에는 한 점포(store)당 여러 개의 매출 데이터가 존재하는데,
도시별 매출 평균을 집계할 때 점포를 무시하면 안 됨!!!
예를 들어서
한 점포에 여러 개의 매출 데이터가 있을때,
점포를 무시하고 도시별로만 평균을 집계하면
City1의 점포는 3개인데 데이터가 4개라서, 평균을 3이 아니라 4로 나누게 되고,
매출이 더 축소됨!
그래서 일단 점포별 합계(=점포별 총 매출)를 구한 후,
이 데이터에 대해서 평균을 구해야 함
메모장으로 직접 예시 들어봄

csv 파일 로드
df = spark.read.csv(
path='Iowa_Liquor_Sales.csv', header=True, inferSchema=True
)- csv외에도 json, parquet, avro, orc, jdbc등 다양한 형식 읽기 가능
- header : 컬럼명이 데이터 내에 포함되어있으면 True로 설정
- inferSchema : True로 설정 시 스키마 자동 설정
스키마 ?
- DB에서 데이터가 구성되는 방식과 서로 다른 엔티티와의 관계를 설명
- 예를 들어, 이름/타입/Primary 키 여부 등을 설정
JDBC ?
- 자바에서 DB에 접속할 수 있도록 하는 자바 API
- 즉, DB의 데이터를 불러와 데이터프레임으로 처리
빅데이터를 위한 파일 형식
- Avro, Parquet, Orc
- 기계가 읽을 수 있는 바이너리 형식
- 여러 개의 디스크로 나뉠 수 있으며, 이 특징으로 인해 확장성 확보 + 동시 처리 가능
Avro
- row (행) 기반으로 저장
- 따라서, 모든 필드에 접근해야 할 때 유용함 (큰 분량을 쓸 때 유리함)
- 가장 많이 사용되는 플랫폼 : Kafka, Druid
Parquet
- column (열) 기반으로 저장
- 따라서, 특정 필드(열)에 접근해야 할 때 유용함 (큰 분량을 읽고 분석해야할 때 유리함)
- 가장 많이 사용되는 플랫폼 : Impala, Spark
ORC
- column (열) 기반으로 저장
- 따라서, 특정 필드(열)에 접근해야 할 때 유용함 (큰 분량을 읽고 분석해야할 때 유리함)
- 가장 많이 사용되는 플랫폼 : Hive, Presto
Spark : 기본적인 데이터 살펴보기
# 기본적으로 20개의 데이터 노출
df.show()
# 5개의 데이터 노출
df.show(5)Spark : 데이터프레임을 parquet 형식으로 저장하기
df.write.format('parquet').save(
path= 'data_parquet', # 해당 폴더에 파일을 분산하여 저장함. 폴더가 없는 경우 새로 생성함
header=True
)Spark : 데이터 살펴보기
df_parquet.show(5)데이터 개수 세기
df_parquet.count()데이터 스키마 확인하기
df_parquet.printSchema()Spark : 결측치 처리하기
from pyspark.sql import functions as F컬럼별 결측치 개수 세기
(
df_parquet
.select([
F.count(F.when(F.isnull(c), c)).alias(c) for c in df_parquet.columns
])
).show(5)
# alias = sql의 as와 같이 컬럼명을 지정해주는 역할. 여기선 컬럼명을 그대로 사용
# F.when(조건, 값) = 조건을 만족하면 값을 반환해라
# count 개수 세기
# 즉, columns의 각 컬럼 c에 대해서 null인 데이터의 개수를 셈df_parquet.filter(F.col('StoreLocation').isNull()).show(5)when
- if문이랑 비슷한 역할
- F.when(조건(True), 조건 만족할 경우 반환할 값).otherwise(조건 만족하지 않을 경우 반환할 값)
filter
- 조건을 만족하는 값을 필터링
- where 함수도 동일한 기능
컬럼 삭제
df = df_parquet.drop('StoreLocation', 'CountyNumber')지역에 대한 컬럼에 대해서만 null 개수 계산
region_cols = ['Address', 'City', 'ZipCode', 'County']
df.select(
[F.count(F.when(F.isnull(c), c)).alias(c) for c in region_cols]
).show()결측치가 가장 적은 컬럼 : City !!!
City 컬럼이 null인 행을 제거하기
df = df.filter(F.col('City').isNotNull())city로만 지역 정보를 표시하자. 즉, Address, ZipCode, County 컬럼은 삭제하기
df = df.drop('Address', 'ZipCode', 'County')결측치 다른 값으로 대체하기
from pyspark.sql import Window as W
(
df
.withColumn(
'CategoryName_cnt',
F.size(
F.collect_set('CategoryName').over(W.partitionBy('Category'))
) # Category별로 고유한 CategoryName 개수를 세어서, CategoryName_cnt 컬럼에 넣어준다.
)
.filter(F.col('CategoryName_cnt') >= 2)
# CategoryName_cnt의 개수가 2 이상, 즉 한 Category에 여러 개의 CategoryName을 가진 경우만을 보여준다.
).show()
한 Category에 여러 개의 CategoryName을 가진 경우가 존재함.
따라서, Category를 기반으로 CategoryName을 채워주려면 특정 기준을 따라야 함.
여기선 Category별로 가장 최근 날짜이면서, null이 아닌 값 중 가장 첫 번째로 등장하는 CategoryName을 덮어씌워주기
df = (
df
.withColumn(
'CategoryName',
F.first(
F.col('CategoryName'), ignorenulls=True
).over(W.partitionBy(F.col('Category')).orderBy(F.col('Date').desc()))
)
)데이터형 변환하기
date가 string으로 되어있어서, 형변환 필요
df = df.withColumn('Date', F.to_date(F.col('Date'), 'MM/dd/yyyy'))
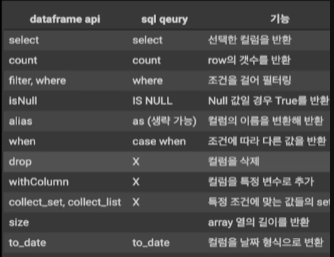
Spark : DataFrame API와 sql 쿼리 비교하기
Plotly 로 인터랙티브 시각화
Plotly 설치
%pip install plotly==5.11.0pyspark dataframe을 pandas dataframe으로 변환
sample_pd = df.filter(F.col('City')=='WAUKEE').toPandas()
Hover Label 꾸미기 + 날짜 범위 슬라이더 추가하기
fig = px.line(WAUKEE_pd,
x='Date',
y='BottlesSold',
title='Bottles Sold amount at WAUKEE'
, text = 'Sale_Dollars') #아래 update_trace에서 text로 사용할 컬럼 지정!!!
fig.update_layout(
hoverlabel_bgcolor='white',
hoverlabel_font_size = 10,
hoverlabel_font_color = 'black',
hoverlabel_font_family = 'Rockwell'
)
# hover label의 내용 작성
# html 스타일
fig.update_traces(hovertemplate = '총 매출: %{text}달러 <br>'
'날짜: %{x} <br>'+
'판매량: %{y}개')
# 날짜 범위 슬라이더 생성
fig.update_layout(xaxis=dict(rangeslider_visible=True))
fig.show()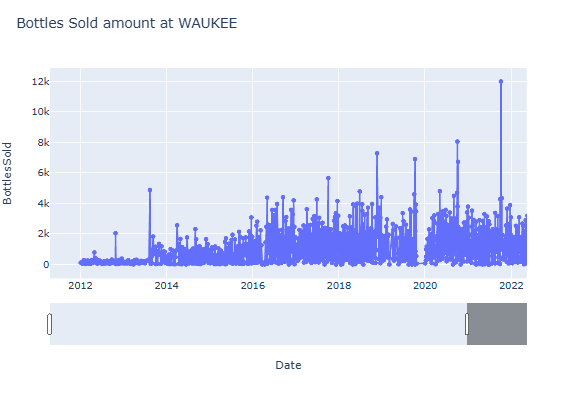
드롭다운 추가하기
import plotly.graph_objects as go
fig = go.Figure()
# 1번 그래프
fig.add_trace(go.Line(
name="BottlesSold",
x=WAUKEE_pd["Date"],
y=WAUKEE_pd["BottlesSold"]
))
# 2번 그래프
fig.add_trace(go.Line(
name="Sale_Dollars",
x=WAUKEE_pd["Date"],
y=WAUKEE_pd["Sale_Dollars"]
))
fig.update_layout(
updatemenus=[
dict(
type="dropdown",
direction="down",
buttons=list([
dict(label="Both",
method="update",
args=[{"visible": [True, True]},
{"title": "BottlesSold & SaleDollars"}]),
dict(label="BottlesSold",
method="update",
args=[{"visible": [True, False]},
{"title": "BottlesSold",}]),
dict(label="Sale_Dollars",
method="update",
args=[{"visible": [False, True]},
{"title": "Sale_Dollars",}]),
]),
),
]
)
fig.show()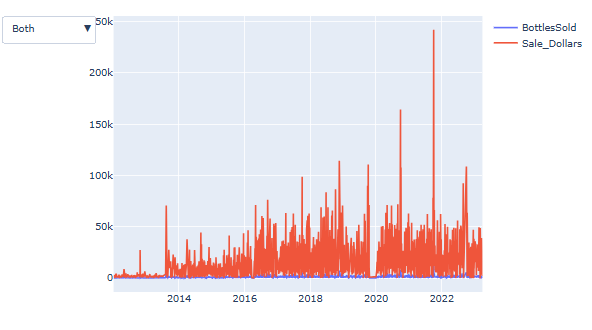
주류시장 동향 파악하기
매출 추이와 성장률
- 전반적으로 매출이 증가하고 있는가?
- 전반적으로 상점 수가 증가하고 있는가?
연도별 총 매출 + 총 상점 수
pd1 = (
df
.withColumn('Year', F.year('Date').cast('long'))
.filter(F.col('Year') < 2023) # 2023년은 정보가 일부만 존재하므로 제외
.groupBy('Year')
.agg(
F.sum('Sale_Dollars').cast('long').alias('SaleDollars_sum'), # 총 매출
F.countDistinct(F.col('StoreNumber').cast('string')).alias('Store_cnt') # 총 상점 수
).orderBy('Year') # 연도순
).toPandas()시각화
import plotly.express as px
fig = px.line(x=pd1['Year'], y=pd1['SaleDollars_sum'], title='매출 추이')
fig.show()fig = px.line(x=pd1['Year'], y=pd1['Store_cnt'], title='상점 수 추이')
fig.show()매출 성장률은?
- 성장률(= 증감률) (growth rate)이란?
- 100 * (이번결과값 - 지난번결과값) / 지난번결과값
- 즉, 과거 대비 이번에 증감한 비율
- 연도별 총매출/상점수 구하기
- withColumn과 F.lag로 이전연도의 총매출을 새 컬럼으로 추가
- 2번에서 구한 이전연도 총매출을 이용하여, withColumn으로 이번연도 총매출 - 이전연도 총매출 / 이전연도 총매출 해서, 매출 성장률에 대한 컬럼 생성
pd2 = (
df
.withColumn("Year", F.year("Date").cast("long")) #년/월/일에서 년도 정보만 추출
.filter(F.col("Year") < 2023) # 2023년은 정보가 일부만 있으므로 제외
.groupBy("Year") # 년도별로 group화
.agg(
F.sum("Sale_Dollars").cast("long").alias("SaleDollars_sum"), # SaleDollars 총합
F.countDistinct(F.col("StoreNumber").cast("string")).alias("Store_cnt") # StoreNumber 고유 갯수
)
.withColumn("SaleDollars_sum_bef", F.lag("SaleDollars_sum").over(W.orderBy("Year")))
# Year를 기준으로 이전 년도 SaleDollars_sum 값을 반환
# 성장률 계산하기
.withColumn(
"SaleDollars_growth_rate",
100*(F.col("SaleDollars_sum")-F.col("SaleDollars_sum_bef"))/F.col("SaleDollars_sum_bef")
)
).toPandas()시각화
fig = px.line(x=pd2["Year"], y=pd2["SaleDollars_growth_rate"],title="매출 성장률 추이")
# 위 그래프와 동일
fig.show()매출이 높은 지역 찾기
pd3 = (
df
.withColumn("Year", F.year("Date").cast("long")) #년/월/일에서 년도 정보만 추출
.filter(F.col("Year") < 2023) # 2023년은 정보가 일부만 있으므로 제외
.groupBy("Year", 'City') # 년도별 + 도시별 group화
.agg(
F.sum("Sale_Dollars").cast("long").alias("SaleDollars_sum"), # SaleDollars 총합
F.countDistinct(F.col("StoreNumber").cast("string")).alias("Store_cnt") # StoreNumber 고유 갯수
)
.withColumn("SaleDollars_sum_bef", F.lag("SaleDollars_sum").over(W.orderBy("Year")))
# Year를 기준으로 이전 년도 SaleDollars_sum 값을 반환
# 성장률 계산하기
.withColumn(
"SaleDollars_growth_rate",
100*(F.col("SaleDollars_sum")-F.col("SaleDollars_sum_bef"))/F.col("SaleDollars_sum_bef")
).orderBy('Year')
).toPandas()시각화
fig = px.line(
pd3,
x = "Year", y = "SaleDollars_sum", color = 'City', hover_data = ['City'])
fig.update_layout(title_text = "지역 별 매출 추이")
fig.show()fig = px.line(
pd3,
x = "Year", y = "SaleDollars_growth_rate", color = 'City', hover_data = ['City'])
fig.update_layout(title_text = "지역 별 매출 성장률 추이")
fig.show()매출 상위 10개 지역(City)만 살펴보기
top10_city = (
pd3[pd3.Year == 2022]
.nlargest(n=10, columns='SaleDollars_sum')
)['City'].tolist()
# 2022년의 총 매출 상위 10개인 데이터의 'City' 열만 가져와서 list화
top_10_city_loc = pd3.City.isin(top10_city) # City가 top10 안에 있는 경우, true 반환
fig = px.line(
pd3.loc[top_10_city_loc],
x = "Year", y = "SaleDollars_growth_rate", color = 'City', hover_data = ['City'])
fig.update_layout(title_text = "지역 별 매출 성장률 추이")
fig.show()점포별 평균 매출
pd4 = (
df
.withColumn("Year", F.year("Date").cast("long")) #년/월/일에서 년도 정보만 추출
.filter(F.col("Year") < 2023) # 2023년은 정보가 일부만 있으므로 제외
.groupBy("Year", "City", "StoreNumber") # 년도별, 지역별, 점포별로 group화
.agg(
F.sum("SaleDollars").cast("long").alias("SaleDollars_sum"), # SaleDollars 총합
)
# 연도별, 도시별, 점포별로 group화하여 구한 총 매출에 대해서,
# 연도와 도시별로만 그룹화하여 점포별 평균 매출을 구함
.groupBy("Year", "City")
.agg(
F.avg("SaleDollars_sum").alias("Store_SaleDollars_avg"), # 점포 별 매출 평균
F.sum("SaleDollars_sum").alias("SaleDollars_sum") # 총 점포 매출
)
.orderBy("Year") # 년도로 정렬
).toPandas()시각화
fig = px.line(
pd4,
x = "Year", y = "Store_SaleDollars_avg", color = 'City', hover_data = ['City'])
fig.update_layout(title_text = "지역 별 점포 평균 매출 추이")
fig.show()도시 전체 매출과 점포별 평균 매출 간의 상관관계 알아보기
fig = px.scatter(
pd4[pd4.Year == 2022],
x = "SaleDollars_sum", y = "Store_SaleDollars_avg", color = 'City', hover_data = ['City'])
fig.update_layout(title_text = "지역 별 점포 평균 매출 & 총 매출 관계")
# 수평선 그리기
fig.add_hline(y= 400000,
line_color='red',)
# 수직선 그리기
fig.add_vline(x=3500000,
line_color='red')
fig.show()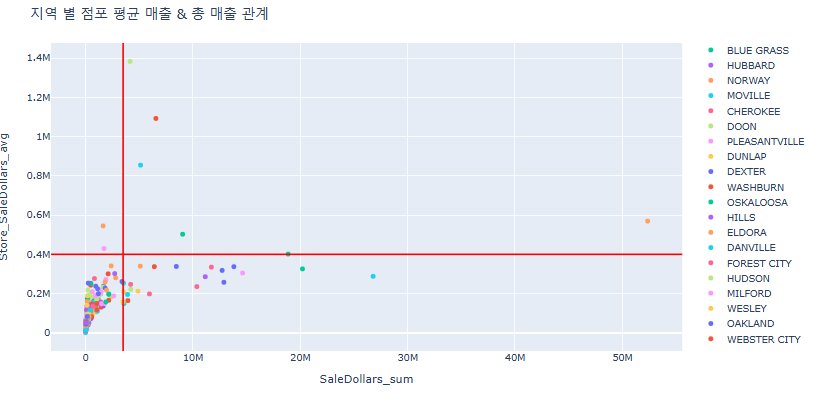
일정 수준 매출이 보장되는 지역 + 가게의 수익이 좋은 상위 5개의 지역을 추천 예정
- 위 빨간 선 그래프의 2사분면 (오른쪽 위)가 가장 좋은 지역일 것
- 즉, MOUNT VERNON, DEWITT, WINDSOR HEIGHTS, CORALVILLE, DES MOINES
영업이익 파악하기
- 영업이익 = 영업 활동을 통해 순수하게 남은 이익
- 즉, 영업이익 = 매출액 - 매출원가 - 기타 비용
- 본 데이터에서 각 점포 당 기타 비용은 모두 동일하다고 가정 후, 매출액 - 매출원가로 영업이익을 판단
- 실제 상황에서는 점포 별 월세, 관리비, 인건비, 배송비등이 모두 기타 비용에 포함될 것
- StateBottleRetail: 판매 가격
- StateBottleCost: 원가
- BottlesSold: 판매 갯수
즉, 영업이익 = BottlesSold * (StateBottleRetail - StateBottleCost)
pyspark udf 사용해보기
udf란?
- User Defined Functions
- 즉, 사용자 정의 함수
- 직접 만든 함수를 pyspark에서 사용할 수 있음
# 영업 이익을 계산하는 udf 만들기
from pyspark.sql.functions import udf
from pyspark.sql import types as T
def calculate_gross_profit(unit_sales, unit_cost, sales_amt):
gross_profit = sales_amt * (unit_sales - unit_cost)
return gross_profit
calculate_gross_profit_udf = udf(
calculate_gross_profit, # udf로 만들 함수
T.DoubleType() # return type
)(
df
.withColumn(
"gross_profit",
calculate_gross_profit_udf( # udf 적용
df.StateBottleRetail,
df.StateBottleCost,
df.BottlesSold
)
)
.select("StateBottleRetail", "StateBottleCost", "BottlesSold", "gross_profit")
).show()pd1 = (
df
.withColumn("Year", F.year("Date").cast("long")) #년/월/일에서 년도 정보만 추출
.filter(F.col("Year") < 2023) # 2023년은 정보가 일부만 있으므로 제외
.withColumn(
"gross_profit",
calculate_gross_profit_udf( # udf 적용
df.StateBottleRetail,
df.StateBottleCost,
df.BottlesSold
)
)
.groupBy("Year", "City", "StoreNumber")
.agg(
F.sum("gross_profit").alias("gross_profit")
)
.groupBy("Year", "City")
.agg(
F.avg("gross_profit").alias("gross_profit_avg")
)
.orderBy("Year")
).toPandas()시각화
import plotly.express as px
fig = px.line(
pd1,
x = "Year", y = "gross_profit_avg", color = 'City', hover_data = ['City'])
fig.update_layout(title_text = "지역 별 점포 영업이익 추이")
fig.show()우리가 추천할 도시의 line만 다른 색으로 칠해주기
all_cities = pd1['City'].unique().tolist()
our_cities = ["MOUNT VERNON", "DEWITT", "WINDSOR HEIGHTS", "CORALVILLE", "DES MOINES"]
color_dict = {}
for city in all_cities:
if city in our_cities:
color_dict[city] = "red"
else:
color_dict[city] = "gray"# 우리가 뽑은 5개의 지역만 다른 색으로 보기
fig = px.line(
pd1,
x = "Year", y = "gross_profit_avg", color = 'City',hover_data = ['City'],
color_discrete_map=color_dict # 색상 지정
)
fig.update_layout(title_text = "지역 별 점포 영업이익 추이")
fig.show()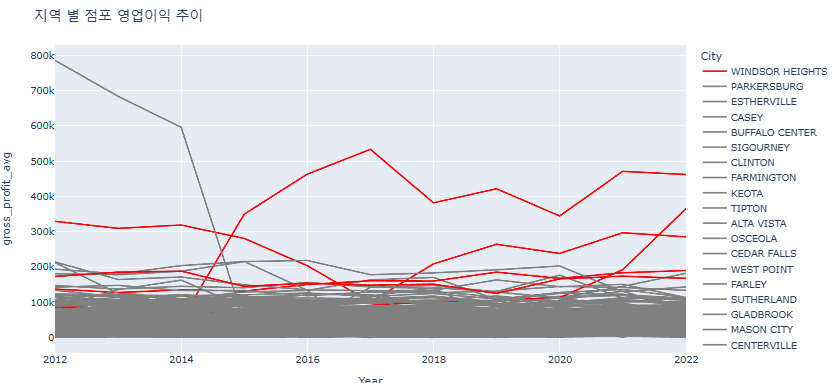
매출과 영업이익 간의 상관관계
pd2 = (
df
.withColumn("Year", F.year("Date").cast("long")) #년/월/일에서 년도 정보만 추출
.filter(F.col("Year") == 2022) # 2022년도를 기준으로
.withColumn(
"gross_profit",
calculate_gross_profit( # udf 적용
df.StateBottleRetail,
df.StateBottleCost,
df.BottlesSold
)
)
.groupBy("City", "StoreNumber")
.agg(
F.sum("SaleDollars").alias("SaleDollars"),
F.sum("gross_profit").alias("gross_profit")
)
.groupBy("City")
.agg(
F.avg("SaleDollars").alias("SaleDollars_avg"),
F.avg("gross_profit").alias("gross_profit_avg")
)
).toPandas()시각화
fig = px.scatter(
pd2,
x = "SaleDollars_avg", y = "gross_profit_avg", color = 'City', hover_data = ['City'])
fig.update_layout(title_text = "지역 별 점포 평균 매출 & 평균 영업이익 관계")
fig.show()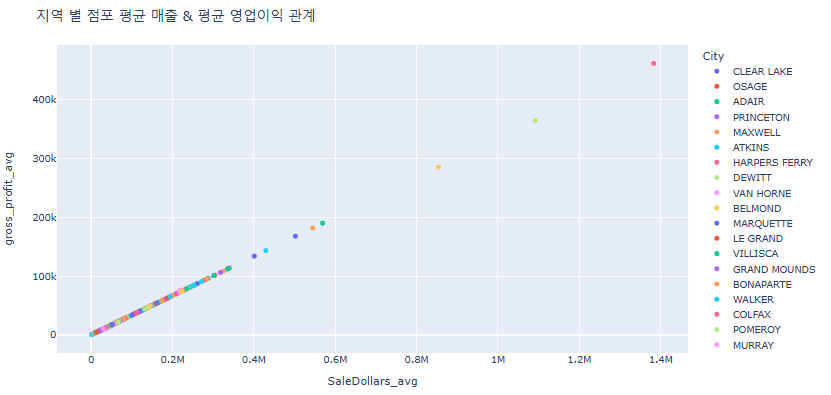
- 굉장히 높은 상관성을 가지고 있음
- 즉, 점포의 매출이 높을 수록 영업이익이 높을 것이라고 예상할 수 있음
🔵 흥미로웠던 점:
pyspark를 처음 배우지만, 사용되는 함수의 개념은 sql과 많이 비슷해서 강의를 통해 언어를 읽고 이해할 수 있었다. 다만 읽는 것과 쓰는 것은 다르기 때문에, 직접 응용을 통해 체득하는 게 중요할 것 같다.
🔵 다음 학습 계획:
MySQL로 지역별 주류 판매 데이터를 분석할 것입니다.
