통계야 놀쟈,,,☆
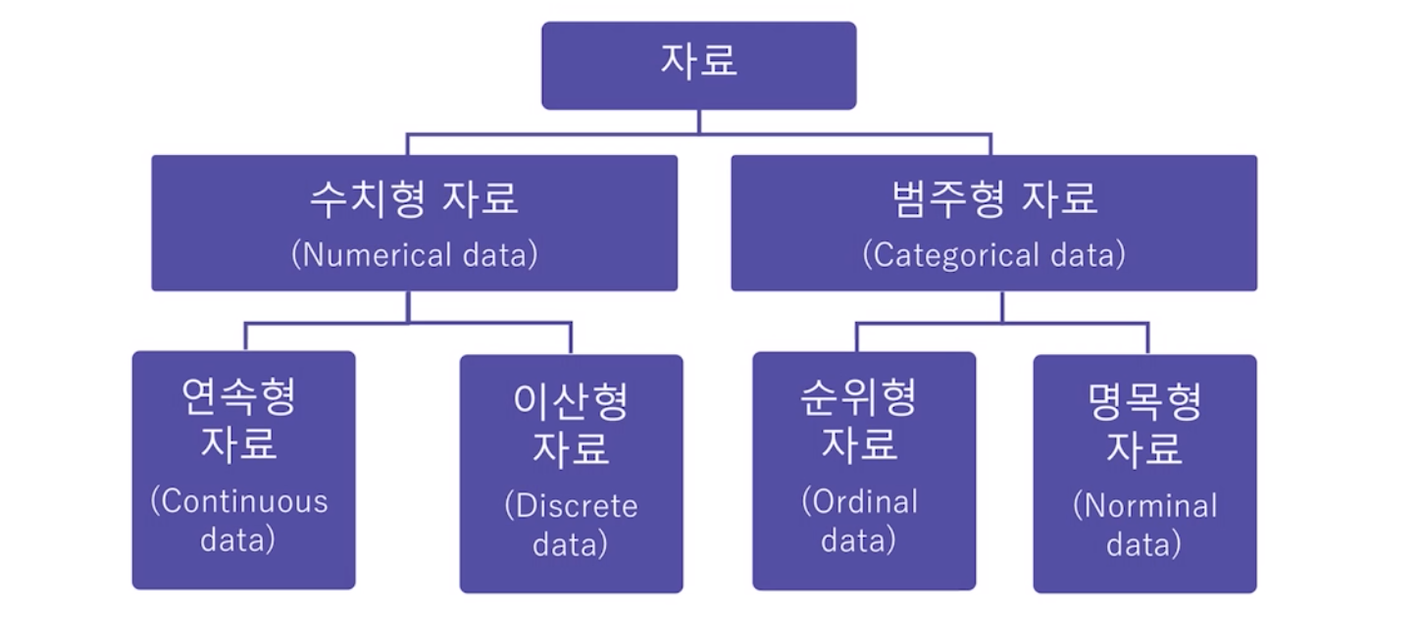
1. 데이터의 종류 분류
데이터의 생김새에 따라 시각화, 해석, 통계모델 결정에 중요한 역할을 한다.
2. 편차, 분산, 표준편차, 표본분포
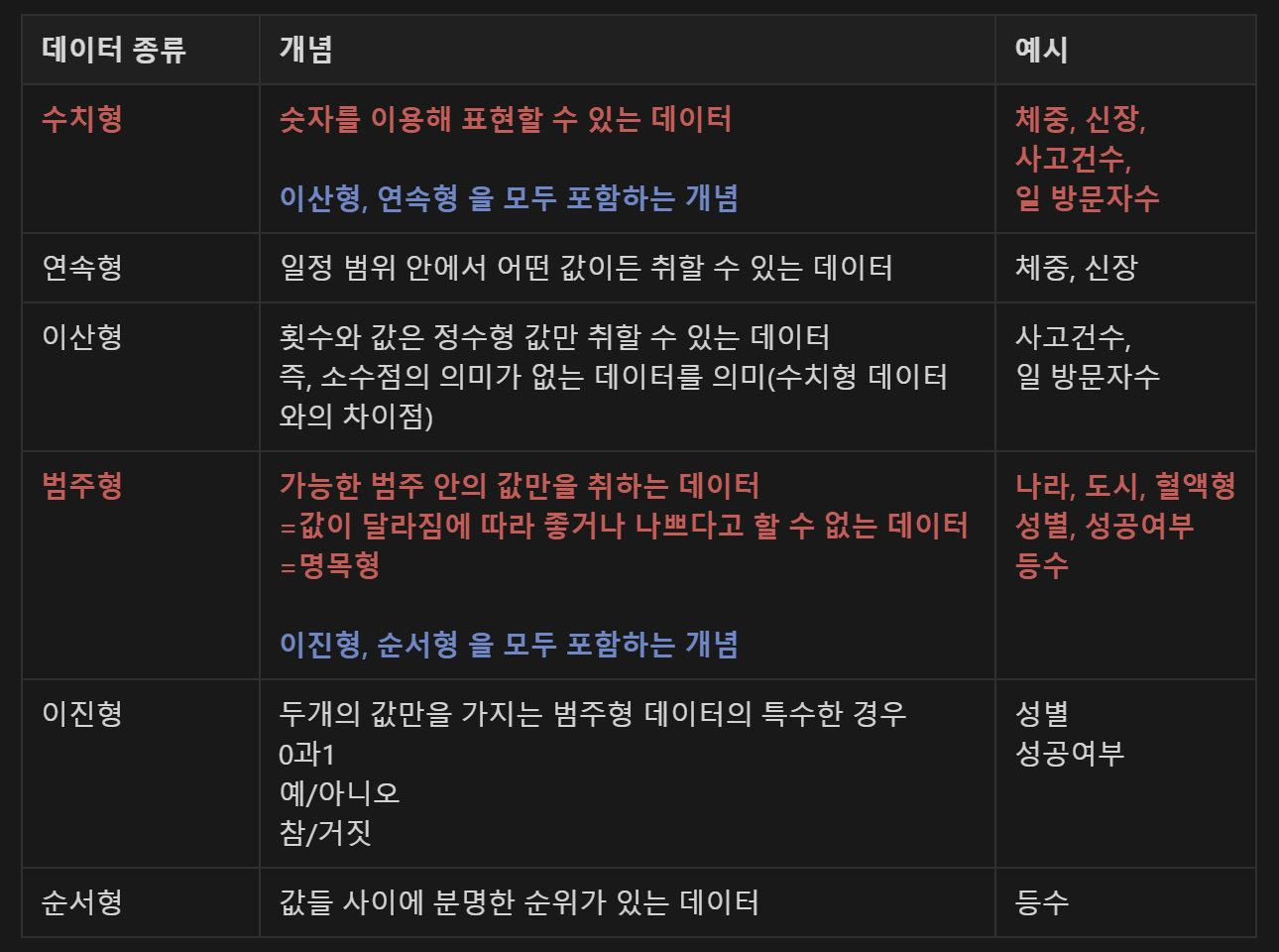
- 데이터프레임 : 행과 열로 구성된 이차원의 행렬
- 테이블이 주어졌을 때, 가장 먼저 해야하는 일 : 각 컬럼의 '대표값'을 구하는 것.
- 대표값 : 평균, 중앙값, 최빈값
# 평균
df['점수'].mean()
# 중앙값
df['점수'].median()
# 최빈값
df['점수'].mode()
: 두 그래프의 평균이 같다. 하지만 분포가 다르다.
- 평균, 중앙값, 최빈값 : 'where=(어디에 존재하는가)'의 개념
- 분산, 편차 : 'How=(어떻게 존재하는가? 얼마나 퍼져있는가?)'의 개념
편차(deviation) : 하나의 값에서 평균을 뺀 값 = 평균으로부터 얼마나 떨어져있어?
- A 학생의 영어점수: 30점
- B 학생의 영어점수: 70점
- C 학생의 영어점수: 80점
- A,B,C 학생의 평균 영어점수: 60점
> A 학생의 편차: -30
> B 학생의 편차: +10
> C 학생의 편차: +20
학생 전체의 편차를 나타내기 위해 각 학생들의 편차를 모두 더하게 되면 0이 나오게 됩니다.
따라서 편차로는 반 전체의 점수 분포를 정확히 알 수가 없기에 나온 개념이 분산입니다.분산(variance) : 편차의 합이 0으로 나오는 것을 방지하기 위해 생성된 개념 = 편차 제곱합의 평균
- A 학생의 편차 제곱: (-30)^2 = 900
- B 학생의 편차 제곱: (+10)^2 = 100
- C 학생의 편차 제곱: (+20)^2 = 400
> 편차 제곱합: 1400
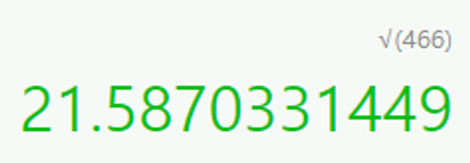
> 편차 제곱합의 평균(분산): 1400/3 = 466
분산은 466이 도출되었습니다. 그러나 점수라는 값에 제곱이 들어가며(점수에 제곱..!)
그 단위가 달라지게되었어요. 실제 데이터가 어느정도로 차이가 있는 지 알기 어렵게 되었습니다.
이를 해결하기 위해 도입된 개념이 표준편차입니다. 표준편차 : 분산에 제곱근을 씌워준 값. (=원래 단위로 되돌리기 = standard deviation(σ))
- 분산: 466 - 분산의 제곱근 = 표준편차 = 약 21.6 이 되겠습니다.= 즉, 반 전체의 영어점수가 약 20만큼 퍼져있다.(분산되어 있다.)라고 해석할 수 있다.
3. 모집단, 표본, 표본분포
-
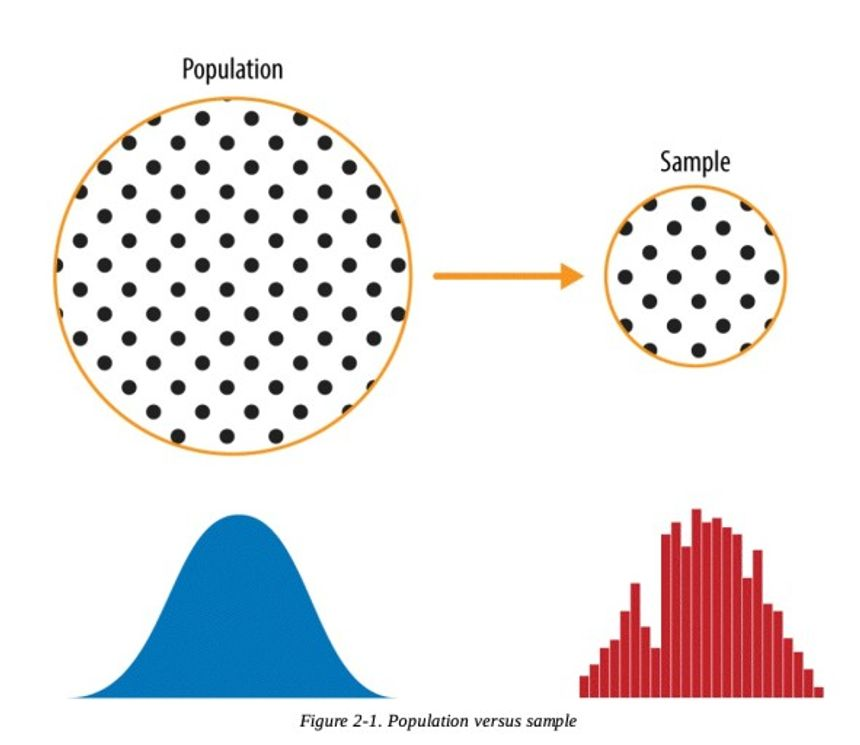
모집단 : 어떤 데이터 집합을 구성하는 전체 대상
-
표본 : 모집단 중 일부. 모집단의 부분집합
-
표본분포 : 표본의 분포. 표본이 흩어져 있는 정도. 표본통계량으로부터 얻은 도수분포
- 표본평균의 분포 : 모집단에서 여러 표본을 추출하고 각 표본의 평균을 계산한다면, 이는 중심극한정리에 따라 정규분포에 가까워진다. 이는 표본의 크기가 충분히 크다면 어떤 분포에서도 표본 평균이 정규분포를 따른다는 것을 의미한다.
- 표본분산의 분포 : 모집단에서 여러 표본을 추출하고 각 표본의 분산을 계산한다면, 이 표본분산들의 분포는 카이제곱 분포를 따른다. 이는 모집단이 정규분포를 따를 때 보다 높게 성립된다.
-
표준오차 : 표본의 표준편차. = 표본평균의 평균과 모평균의 차이
-
중심 극한 정리 : 표본들을 뽑아서 평균내어 모은게 종모양의 정규분포의 형태를 띄는 원리
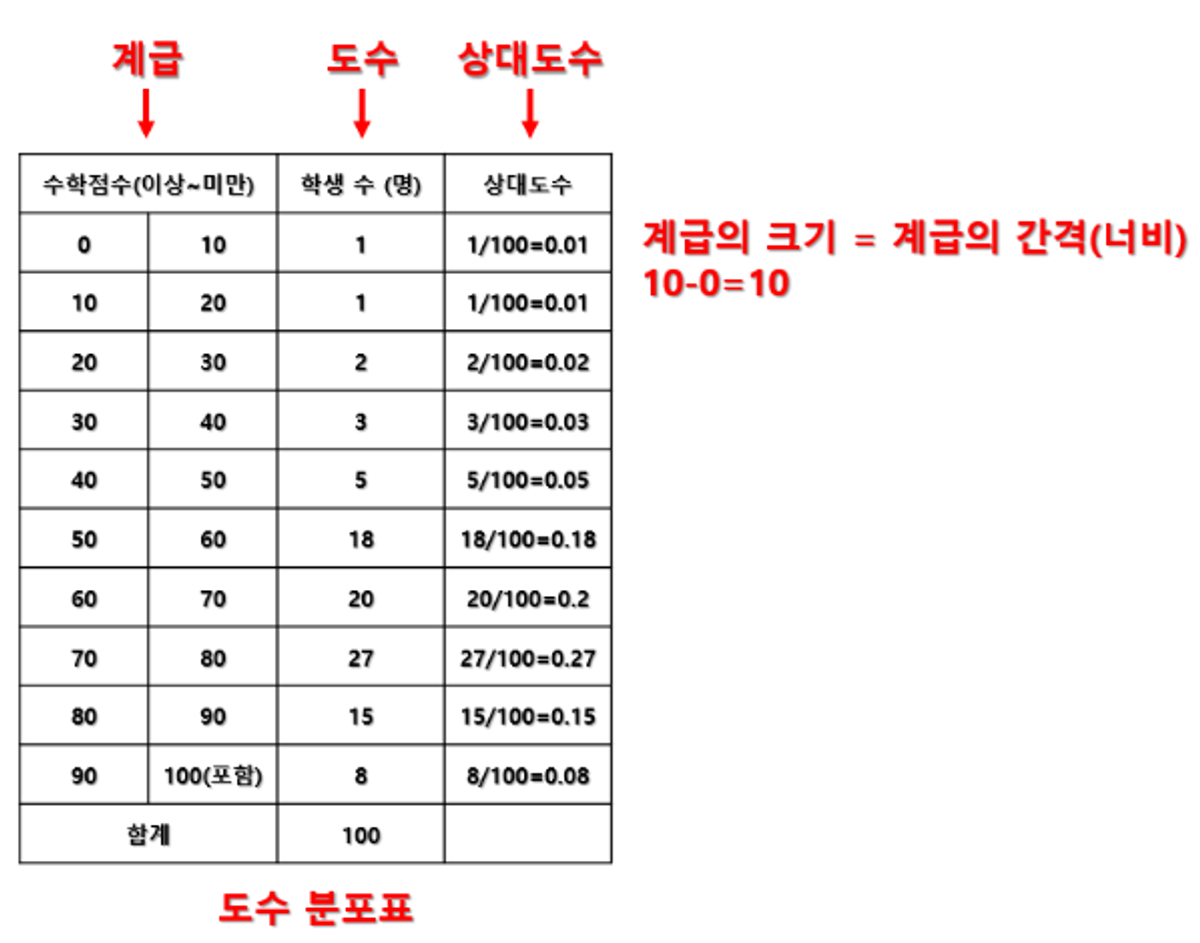
- 도수 : 특정 구간에 발생한 값의 수
- 상대도수 : 특정 도수를 전체 도수로 나눈 비율
- 도수분포표 : 각 값에 대한 도수와 상대도수를 나타내는 표
- 히스토그램 : 도수분포표를 활용하여 만든 막대그래프
- 임의표본추출 : 무작위로 표본을 추출하는 것
- 편향 : 한쪽으로 치우쳐져 있음
- 도수분포표 만들기

4. 정규분포, 신뢰구간
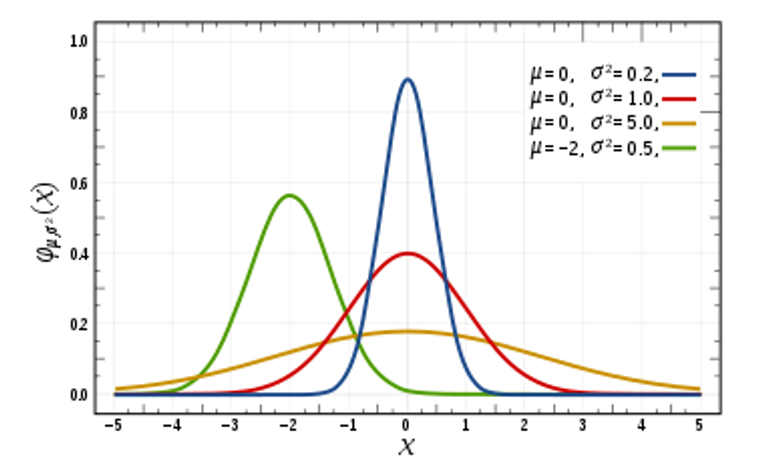
*x는 평균, y는 확률
1) 정규분포 :
표본을 선정할 때 그 경우의 수는 매우 많을 것이고 → 중심극한정리에 따라(경우의 수를 평균내어 모아보면) 다음과 같은 종 모양의 분포를 띄게 되는데, 이를 정규분포라고 한다.
2) 정규분포의 특징
- 분포는 좌우 대칭. 평균치에서 가장 그 확률이 높다.
- 곡선은 각 확률값을 나타내며, 모두 더하면 1이 된다. (동전 앞면 확률 1/2 + 뒷면 확률 1/2 = 1)
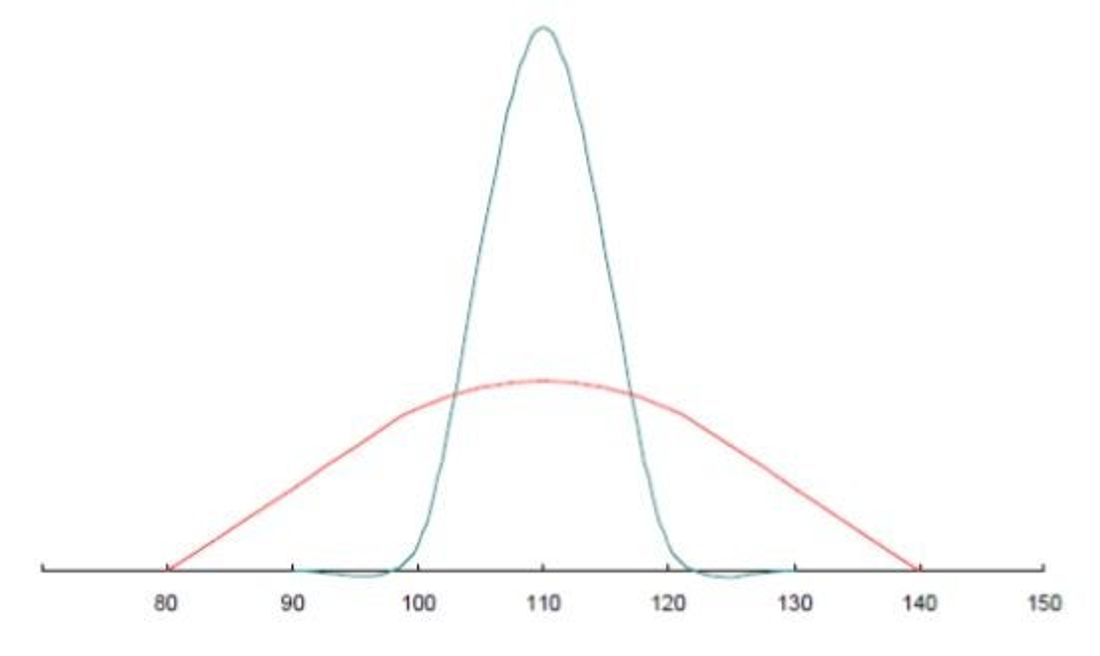
- 정규분포는 평균과 분산(퍼진정도)에 따라 다른 형태를 가진다.
- 표준정규분포 : 평균 0, 분산 1을 가지는 경우. (그림의 붉은색 그래프)
3) 표준정규분포의 중요성
- 위의 그래프에서 각각의 그래프는 평균과 분산값에 따라 다르게 그려진다.
- 즉, 확률을 계산할 때 힘들다.
- 표준화 : 분포의 평균과 분산 값을 통일하는 작업
- 표준화 공식 : 확률변수 x에서 평균 m을 빼고 표준편차로 나누기!
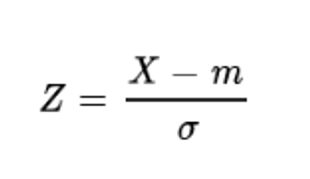
- 데이터 분석 시 표준화가 필요한 경우 : 머신러닝 모델을 만들 때, 데이터의 범위가 많이 차이나는 경우.
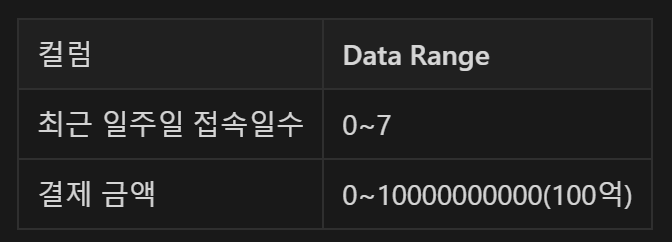
ex)
- 최근 일주이 접속일수의 1과 결제금액의 1은 같은 의미가 아니다!
- 근데 파이썬이 해당 값의 의미를 같게 받아들이고 처리할 수 있다!
- 범위가 큰 데이터의 경우 숫자가 가지는 절대치를 잘못 받아들일 수 있다! (ex. 100억은 100억만큼 기여도가 있어!)
- 그래서 반드시 표준화를 해야한다!
5. 신뢰구간, 신뢰수준
- 신뢰구간 : 특정 범위 내에 값이 존재할 것으로 예측되는 영역
ex. 영어점수가 10점에서 90점 사이 일 것 같아요. - 신뢰수준 : 실제 모수를 추정하는데 몇 퍼센트의 확률로 신뢰구간이 실제 모수를 포함하게 되는 확률. 주로 95%와 99%를 이용한다.
ex. 영어점수가 10점에서 90점 사이에 분포할 확률이 95% 같아요.
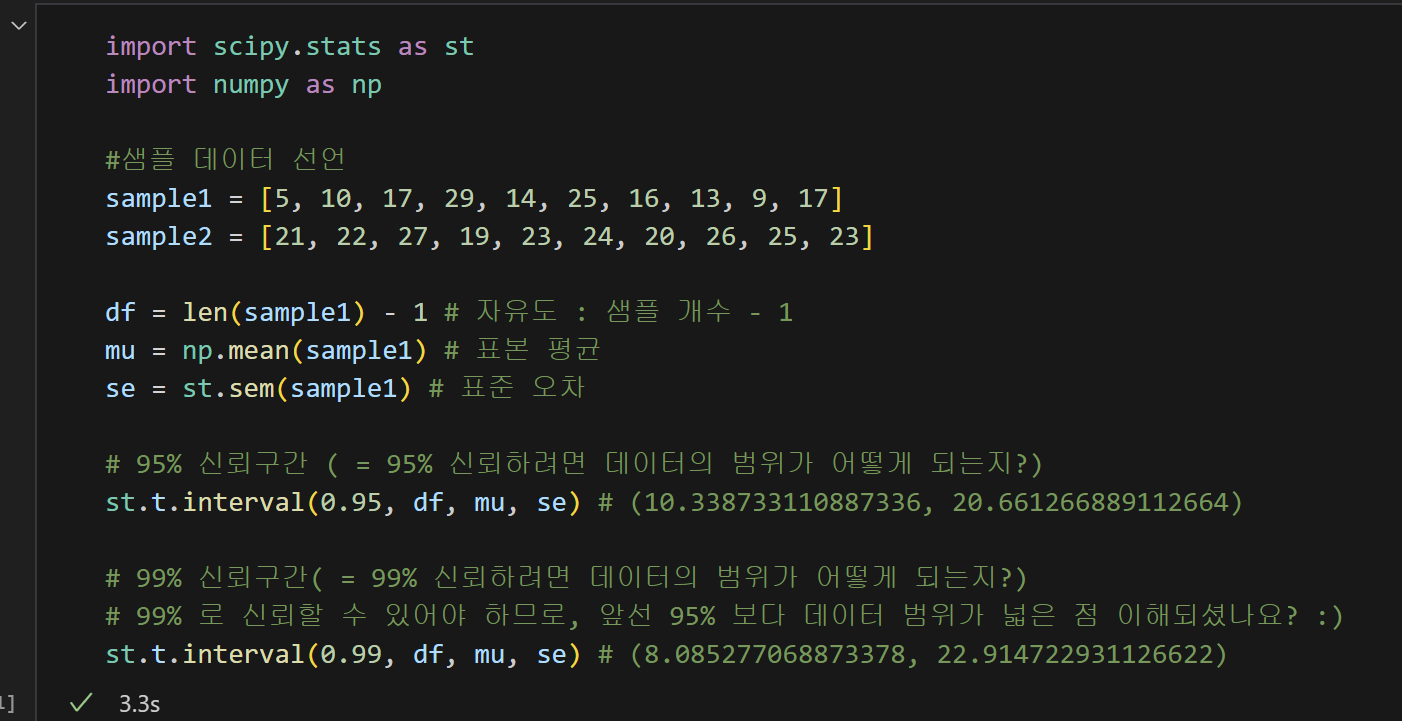
'scipy'를 활용하여 95%와 99%의 신뢰구간을 확인하면,
= 95%보다 99%의 범위가 더 넓다. 왜냐하면, 그만큼 확률이 높기 때문에 더 큰 범위를 말하는 거다.
- 해당 데이터에서는 데이터의 양이 적기때문에 모집단 전체를 표본으로 잡았다.
6. Summary
- Python은 데이터의 종류에 따라 관련된 계산을 어떤식으로 수행할 지 결정한다.
- 데이터의 종류는 대표적으로 수치형, 범주형 데이터가 있다.
- 데이터 대표값에는 평균, 중간값, 최빈값이 있다.
- 데이터 분포를 보다 명확히 파악하기 위해 편차, 분산, 표준편차를 확인한다.
- 편차는 합이 0이다.
- 음수값을 없애기 위해 제곱을 취하는 분산의 개념이 도입되었다.
- 분산은 제곱값으로 그 단위가 달라 표준편차 즉, 제곱근을 씌워 다시 단위를 맞춰줬다.
- 무수히 많은 데이터의 효과적인 통계분석을 위해 표본추출을 한다.
- 모집단 : 어떤 데이터의 전체 집합. 표본 : 부분집합
- 중심극한정리 : 표본의 분포를 가지고 모집단의 분포를 추정하며, 해당 과정에서 무수히 많은 경우의 수의 표본이 생성될 수 있다. 표본 크기가 충분히 크다면 어떤 분포에서도 표본 평균이 정규분포를 따른다.
- 정규분포 : 종모양. 좌우 대칭의 형태. 평균치에서 그 확률이 가장 높다.
- 표준정규분포 : 정규분포에서 평균 0, 분산 1을 가지는 경우 > 데이터 분석 시 : 표준화라고 부름
- 데이터 분석 시 표준화가 필요한 경우 : 머신러닝 모델을 만들 때, 데이터의 범위가 많이 차이나는 경우. > 1이 가지는 무게가 다르다. 범위가 큰 데이터의 경우 숫자가 가지는 절대치를 잘못 받아들일 수 있기 때문.

First time, Last time, Every time.