통계야 놀쟈,,,☆
*이미지 출처 : 전소현튜터님💕
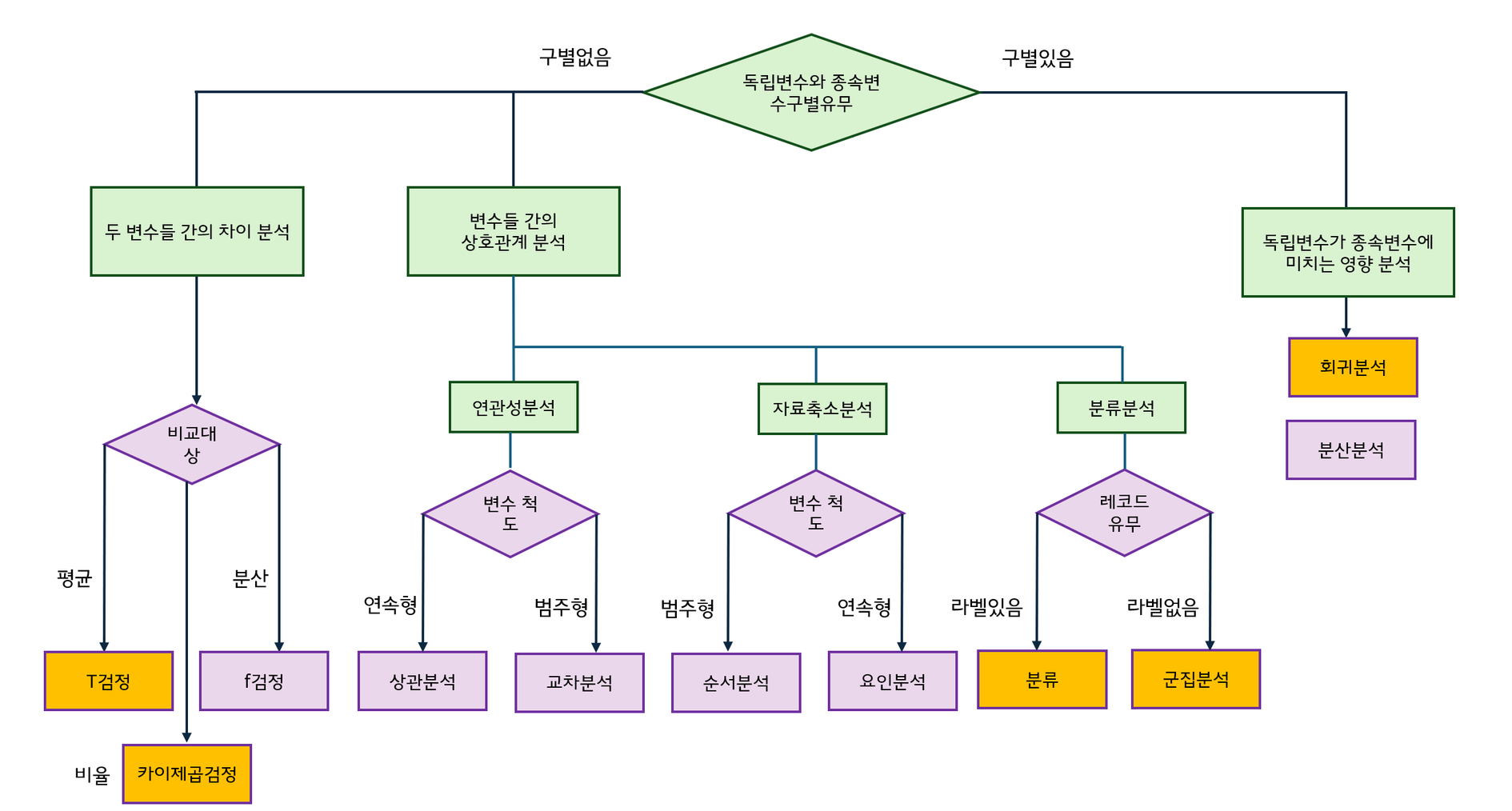
1. 데이터 분석가의 통계적 실험
- 실험설계는 어떤 가설을 확인하거난 기각하기 위한 목표를 가지고 있다.
✅ 데이터 분석가는 상황에 알맞은 분석을 설계하고 진행한다.👩 사업 : 이번 제품의 가격이 지난번 가격보다 수익성이 좋을까용?
🤶 분석 : select 가격 from 매출테이블... 넹,, 살펴보고 말씀드릴게여..통계적 실험이란?
1) 정의 : 어떤 목적을 가지고 관찰을 통해 측정값을 얻어내는것
2) 목적 : 통계적 추론을 통해 보다 진실에 가까운 값을 도출하기 위함
- ex) 모든 까마귀는 검정색이다 → 안보이아나? → 통계적 추론 실시 → 진실에 가까운 값 도출
3) 프로세스 : 가설 수립 → 실험 설계 → 데이터 수립 → 추론 및 결론의 도출제한된 환경에서의 관찰을 통해 확보된 사실을 바탕으로 제한된 결론을 내리고, 확률적 판단으로 제한된 결론을 내려 진실에 가까운 값 도출
2. A/B 테스트
⚠️ 비즈니스 마케팅시 필수!!!!!!!
⚠️ 다양한 통계 개념을 바탕으로 실험 진행
A/B테스트란?
1) 정의 : 대조실험과 같다.
- A/B TEST는 두 가지 처리 방법 중 어떠한 쪽이 더 좋다라는 것을 입증하기 위해 실험군을 두 그룹으로 나누어 진행하는 실험이다.
- 버킷테스트 또는 분할테스트라고 불린다.
- 종종 두 가지 처리 방법 중 하나는 기준이 되는 기존 방법이거나 아예 아무런 처리도 적용하지 않는 방법이다.
ex) A와 B중 A는 쌩 데이터
2) 목적 : 웹/앱 서비스의 광고 및 UI,UX의 ROI(투자 대비 수익) 상승.
✅즉, 최소 투자로 최대 이익을 창출하고자 하는 것
- UI/UX 개선 : 서비스에 진입한 방문자의 니즈에 알맞게 UI,UX가 친절하지 않은 경우 이탈할 가능성이 높다. 고객이 될 수 있었던 방문자를 놓치지 않으려면 A/B 테스트를 통해 이를 개선하는 작업이 중요!!
(ex. 이 페이지에서는 구매버튼을 찾기 어렵네!) - 전환율 증가 : A/B 테스트를 통해 무엇이 효과가 있는지(or 없는지) 파악하면 전환율 상승에 도움이 된다.
(ex. C배너보다 D배너의 전환이 더 좋네!) - 매출 증가 : A/B테스트를 통해 UX가 개선되면 전환율이 상승할 뿐만 아니라, 브랜드에 대한 고객 충성도도 높아진다. 이는 곧 반복 구매로 이어져 매출 증가에 영향을 미치게 된다.
3) 주요지표
- 서비스의 가입율
- 재방문율
- CTR(노출 대비 클릭율)
- CVR(클릭 대비 전환율, 구매전환율)
- ROAS(캠페인 비용 대비 캠페인 수익)
- eCPM(1,000회 광고 노출당 얻은 수익)
- A/B 테스트는 이렇게 TEST 그룹과 CONTROL 그룹으로 나누어 진행한다.
- 근데 꼭 2개 그룹으로 나눌 필요 없음.
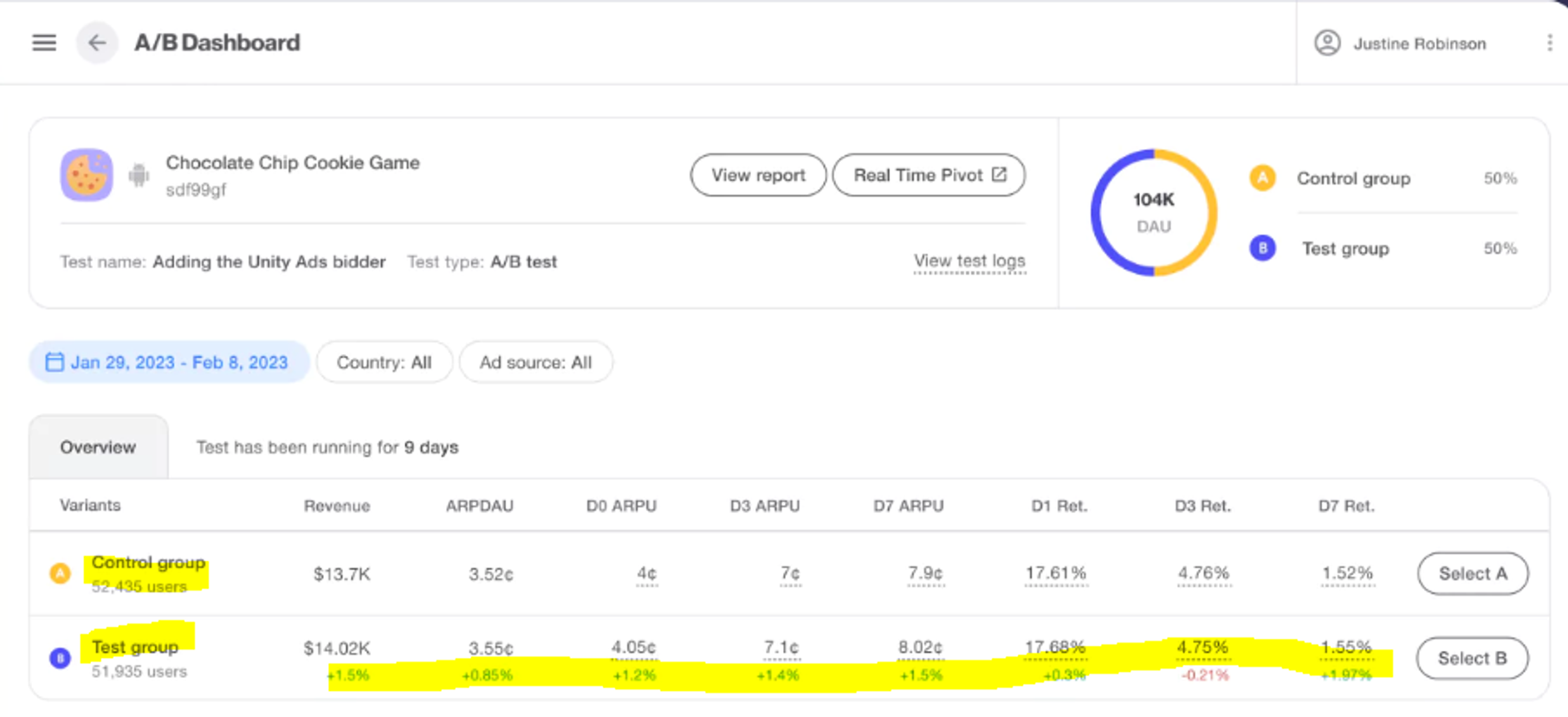
A/B 테스트 프로세스 : 5단계(통계적 개념 필수!)
1) 현행 데이터 탐색
- 앞서 살펴본 주요 지표를 기준으로 현재 데이터 탐색
2) 가설 설정
- 비즈니스 목표를 달성하는데 필요한 KPI(Key Performence Indicator=핵심 성과지표) 정의
- KPI 전환율 증가를 위한 귀무가설, 대립가설 설정
- 귀무가설
- 통계학에서 처음부터 버릴 것을 예상하는 가설
- 차이가 없거나 유의미한 차이가 없는 경우의 가설
- "새로운 광고배너를 게재해도 기존과 차이가 없을 것이다."
- 대립가설
- 귀무가설에 대립하는 명제
- "새로운 광고배너를 게재하면 기존과 차이가 있을 것이다."
3) 유의수준 설정 : ex. ≤ 0.05
- 귀무가설(버릴 것)이 맞을 때 오류를 얼마나 허용할 것인지 기준을 정하는 단계
4) 테스트 설계 및 실행
- 사용자를 대조군과 실험군의 두 그룹으로 분리
- 대조군 그룹에게는 제품이나 서비스의 현재 버전을 보여주고, 실험군 그룹에게는 새 버전을 노출 처리
5) 테스트 결과 분석
- 측정 항목(가설)에 대해 두 그룹의 결과를 분석합니다. (검정통계량 분석)
- 통계적 방법으로 결과를 분석하여 대조군과 실험군 사이의 통계적으로 유의미한 차이가 있는지 확인한다.
A/B 테스트 주의사항❗
1) 적절한 표본 크기
- 표본의 크기가 충분하지 않으면 유의미한 결과를 얻을 수 없다. 적절한 표본 크기를 결정하고, 그에 맞는 시간과 자원을 투자해야 한다.
2) 하나의 변수만 변경
- A/B 테스트에서는 하나의 변수만을 변경해야한다. 두 가지 이상의 변수를 동시에 변경하면 뭐때문인지 알 수 없음.
3) 무작위성
- A/B 테스트는 무작위로 선택된 사용자들에게 각각 다른 변수를 적용해야 합니다.
4) 적절한 분석 방법
- A/B 테스트 결과를 해석할 때는 가설 검증을 위한 통계적 분석 방법을 선택하고, 유의수준을 설정해야한다.
5) 테스트 결과의 의미
- A/B 테스트 결과가 통계적으로 유의미하더라도 항상 실제로 의미 있는 결과인지 한번 더 생각해보아야한다.
6) 정해진 기간 동안 진행
- A/B 테스트는 일정 기간 동안 진행되어야한다. 그 기간동안에만 결과를 수집하고, 분석해야한다. 너무 짧은 기간 동안에는 결과를 수집하기 어렵고, 너무 긴 기간동안에는 사용자들의 행동이 변할 수 있다.

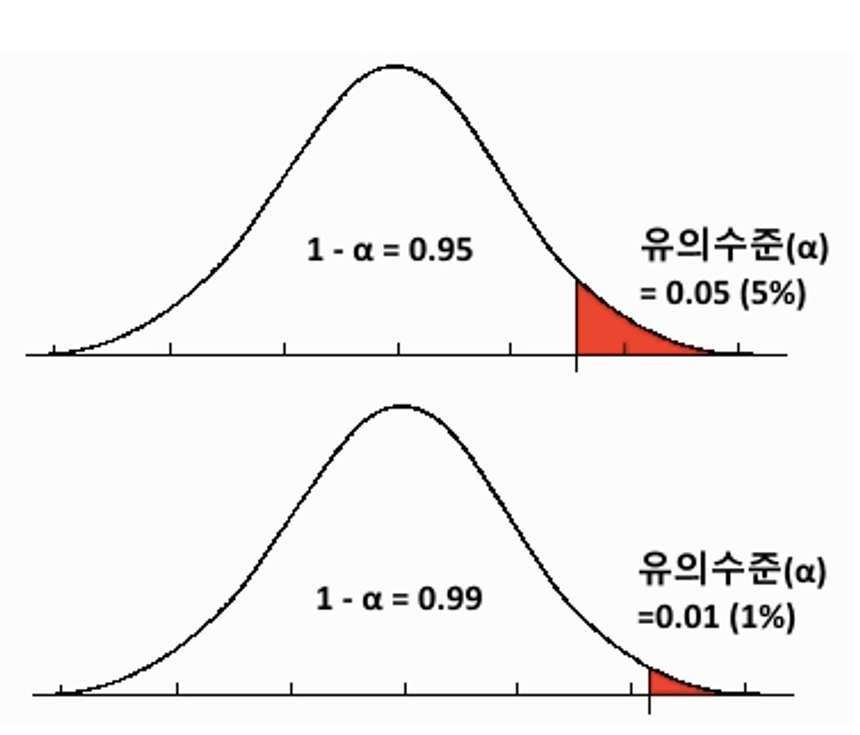
3. 유의수준 설정하기!
💡유의수준은 신뢰수준의 반대 개념이다.
여기서 잠깐❗ 중심극한정리란?
- 표본수집을 기반으로 한 추리통계에서 모집단의 분포가 어떤 모양이더라도 모집단의 크기가 충분히 크다면 표본평균의 분포가 모수 기반의 정규분포를 이룰 것이므로 수집한 표본의 통계량을 이용해 모집단의 모수를 추정할 수 있도록 하는 것.
유의수준 = 오류 허용 범위
- 표본을 추출하는 순간 모집단과 100% 일치할 수 없기 때문에, 오류의 가능성이 존재함.
- 가설 검정에서 결론을 해석하기 위해서는 기준을 세우고, 그 기준을 만족하는지 확인해야 한다.
- 이 '기준'이 바로 유의수준이다.
✅ 유의수준 : 귀무가설(버릴 가설)이 맞을 때 오류허용 기준(확률)
-
IF α로 표시하고 95%의 신뢰도를 기준으로 한다면 (1−0.95)인 0.05값이 유의수준 값이다.
-
유의수준은 신뢰수준의 반대 개념. 즉, 오류가 나타날 확률이다. 보통 0.05를 사용한다.
-
확률값이므로, 역시 0부터 1 사이의 값을 가집니다.
-
우리는 유의수준을 0.05로 설정하겠습니다. (= 95% 신뢰도로 기준을 정한 것!)
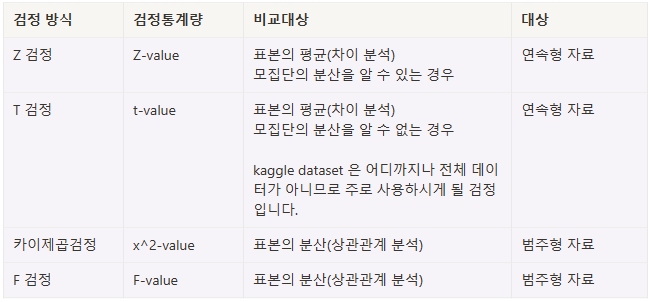
4. 검정통계량과
유의수준 정하고, 실험도 했다! 그럼 결과 해석은?!
🚩결과 해석 단계
1단계) 검정 방식 정하기 & 검정통계량 계산하기
- 귀무가설을 채택할지, 기각할지 결정해야한다.
- 검정통계량이란? 귀무가설을 채택 또는 기각하기 위해 사용하는 확률변수
→ 확률변수란? 특정 확률로 발생하는 각각의 결과를 수치값으로 표현하는 변수
ex) 주사위를 던졌을 때 나오는 숫자를 확률변수 X라고 가정했을 때,
각 X에 대한 확률 P(X)를 구해라
📌 확률변수 X는 1, 2, 3, 4, 5, 6이다.
📌 주사위 값이 1~6 중 어떤 수가 나올지 모르기 때문에 '확률변수'라고 한다.
📌 각 X에 대한 확률은 1/6이다.
- 검정통계량은 표본 평균, 비율, 상관 계수 간의 차이 등 다양한 형태를 취할 수 있다.
- 검정방식의 선택은 가설과 데이터 종류에 따라 다르다.
2단계)
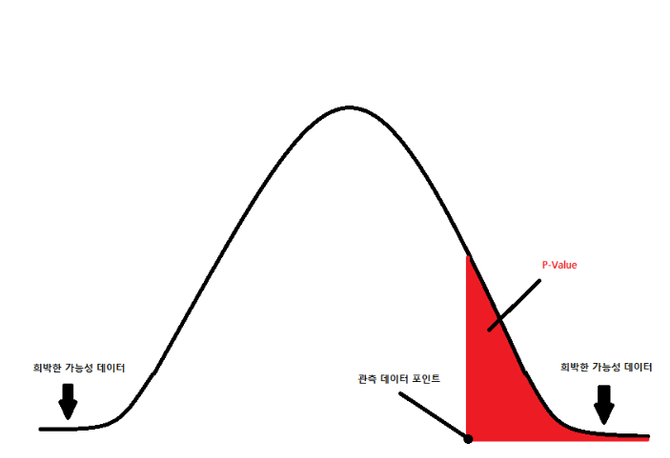
- 란? 어떤 사건이 우연히 발생할 확률
- = Probability-value = '확률'
- 확률이므로, 0이상 1이하 이다.
🎯 목표 : 대립가설 채택! = 가 작아야한다! = < 유의수준
- < 0.05 = 우연히 일어났을 가능성이 낮다 = 인과관계 ⭕!!
- > 0.05 = 우연히 일어났을 가능성이 높다 = 인과관계 ❌!!
IF 중심극한정리를 통해, 모집단이 큰 경우 표본평균이 정규분포를 따르게 된다고 가정한다.
- 정규분포의 그래프 아래쪽이 확률값이다.
- 유의수준을 설정하고, 를 도출해서 의미를 해석해야한다.
3단계) 근데 이거 직접해야함?
🤬 NO!!
😆 Python의 Library를 사용하면 돼!!
import pandas as pd # 라이브러리 호출 import numpy as np import scipy.stats as stats # 과학 계산용 파이썬 라이브러리 from PIL import Image df = pd.read_csv("users1.csv") #t-test # 가설 설정 # 귀무가설: 남성과 여성의 구매금액에 차이가 없을 것이다 # 대립가설: 남성과 여성의 구매금액에 차이가 있을 것이다 # 실제 데이터 비교 df.groupby(['Gender'])['Purchase Amount (USD)'].mean().reset_index() # 데이터 분리 # mask method : 원하는 데이터 뽑아서 데이터프레임에 합치는거. mask=(df['Gender']=='Male') mask1 = (df['Gender']=='Female') m_df = df[mask] f_df = df[mask1] # 결제금액 컬럼만 가져오기 m_df=m_df[['Purchase Amount (USD)']] f_df=f_df[['Purchase Amount (USD)']] # 차이가 있는 것으로 보여짐 # 유의수준은 통상적으로 많이 쓰이는 0.05 로 정함 # scipy 라이브러리를 이용해 t-score 와 pvalue 를 확인할 수 있습니다. # t-test 는 표본의 평균(차이 분석)을 알고자 할 때 사용되며, 모집단의 분산을 알 수 없는 경우 주로 사용됩니다. t, pvalue=stats.ttest_ind(m_df, f_df) # tscore 는 그룹 간 얼마나 차이가 있는지에 대한 지표 # tscore 가 크면 그룹 간 차이가 큼을 의미합니다. # p-value 는 우연에 의해 나타날 확률에 대한 지표입니다. # p-value가 0.05 보다 크다 = 우연히 일어났을 가능성이 높다 = 인과관계가 없다고 추정 # 여기서 p-value 값은 0.05 보다 크므로, 인과관계가 없다고 추정할 수 있습니다. # 대립가설 기각 t, pvalue #카이제곱검정 # 가설 설정 # 귀무가설: 성별과 구매Size 에는 관련성이 없을 것이다 # 대립가설: 성별과 구매Size 에는 관련성이 있을 것이다 # 실제 데이터 비교 df.groupby(['Gender','Size'])['Customer ID'].count().reset_index() # pandas 라이브러리의 crosstab 함수를 통해, 두 범주형 자료의 빈도표를 만들어 주겠습니다. result = pd.crosstab(df['Gender'], df['Size']) # 카이제곱 검정을 stat 함수를 통해 구현 # chi2_contingency를 통해, 카이제곱통계량, p-value를 출력할 수 있습니다. stats.chi2_contingency(observed=result) # 각 값들을 별도로 보기 # 카이제곱 검정 통계량, pvalue, 자유도를 확인할 수 있습니다. stats.chi2_contingency(observed=result)[0] # p-value 는 우연에 의해 나타날 확률에 대한 지표입니다. # p-value가 0.05 보다 크다 = 우연히 일어났을 가능성이 높다 = 인과관계가 없다고 추정 # 여기서 p-value 값은 0.05 보다 크므로, 인과관계가 없다고 추정할 수 있습니다. # 대립가설 기각 stats.chi2_contingency(observed=result)[1] # 자유도와 유의수준을 통해 귀무가설 기각 여부를 판단하기도 합니다. # 자유도란, 굉장히 복잡한 개념이므로,,, (변수1 그룹의 수-1)*(변수2 그룹의 수-1) 가 되겠습니다. # 1*3 = 3 이 도출되었습니다. stats.chi2_contingency(observed=result)[2]
5. Summary
- A/B 테스트라는 방법론을 활용할땐 통계개념(가설 설정, 통계적 의미 해석(), 가설 검정(T검정, 카이제곱검정))을 사용해야 한다.
- A/B 테스트는 5단계로 진행된다.
- 현행 데이터 탐색 → 가설 설정 → 유의수준 설정 → 실험 → 해석
- 귀무가설은 차이가 없거나 유의미한 차이가 없는 경우의 가설(=버릴 가설)이다.
- 대립가설은 차이가 있는 경우의 가설이다.
- 는 어떠한 사건이 우연히 발생할 확률이다.
- <0.05 = 우연히 일어났을 가능성이 거의 없다 = 인과관계 '⭕'라고 추정 = 대립가설 채택
