선형회귀의 사례
몸무게와 키 상관관계 찾아내기
- 방정식을 배운 머신이는 몸무게와 키의 데이터를 획득했다. 일정하게 증가하는 패턴이 있어서 미리 몸무게를 알면 키를 알 수 있을 것이라 생각했다.
weights = [87,81,82,92,90,61,86,66,69,69]
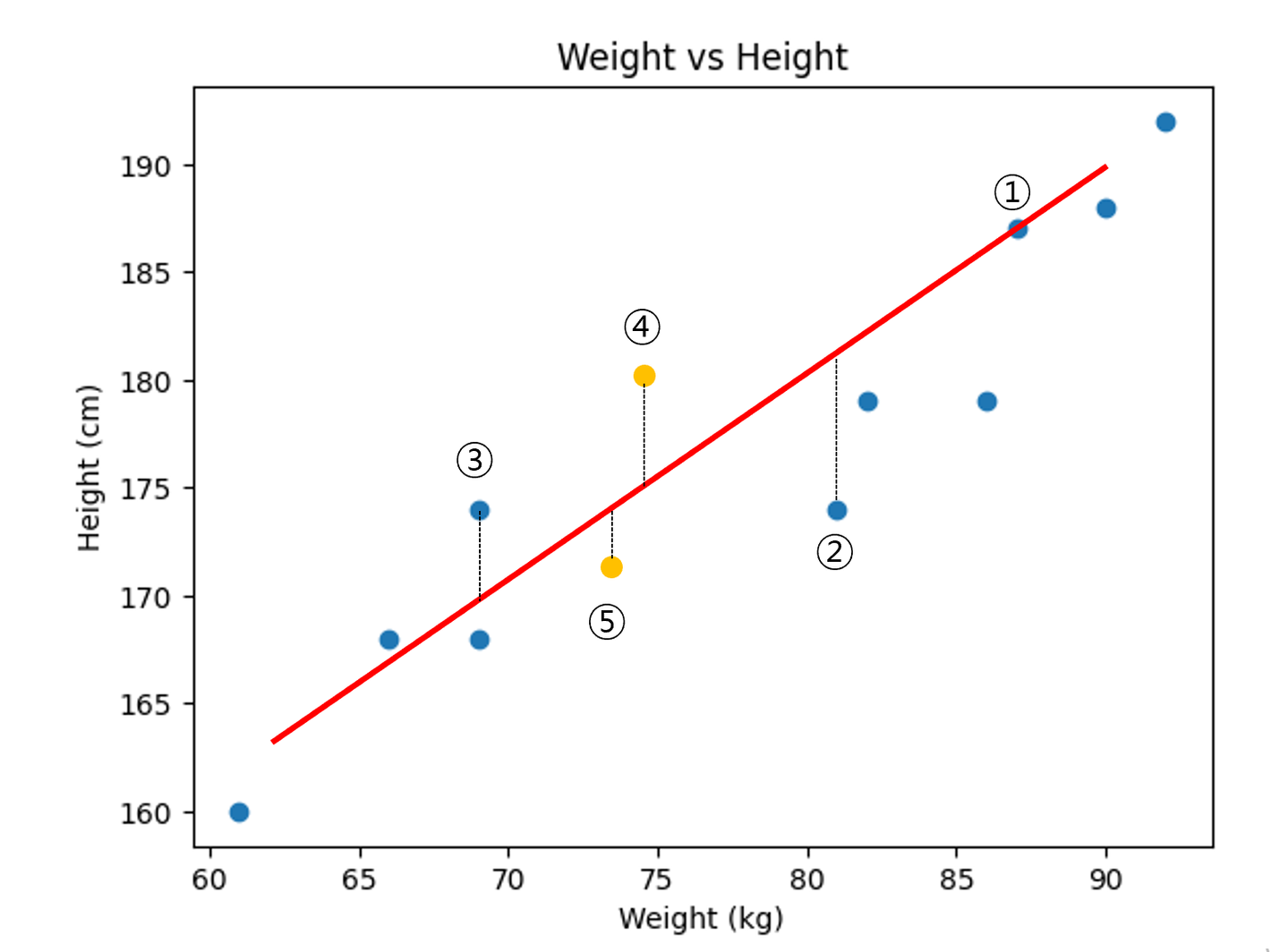
heights = [187,174,179,192,188,160,179,168,168,174]키와 몸무게 간의 산점도
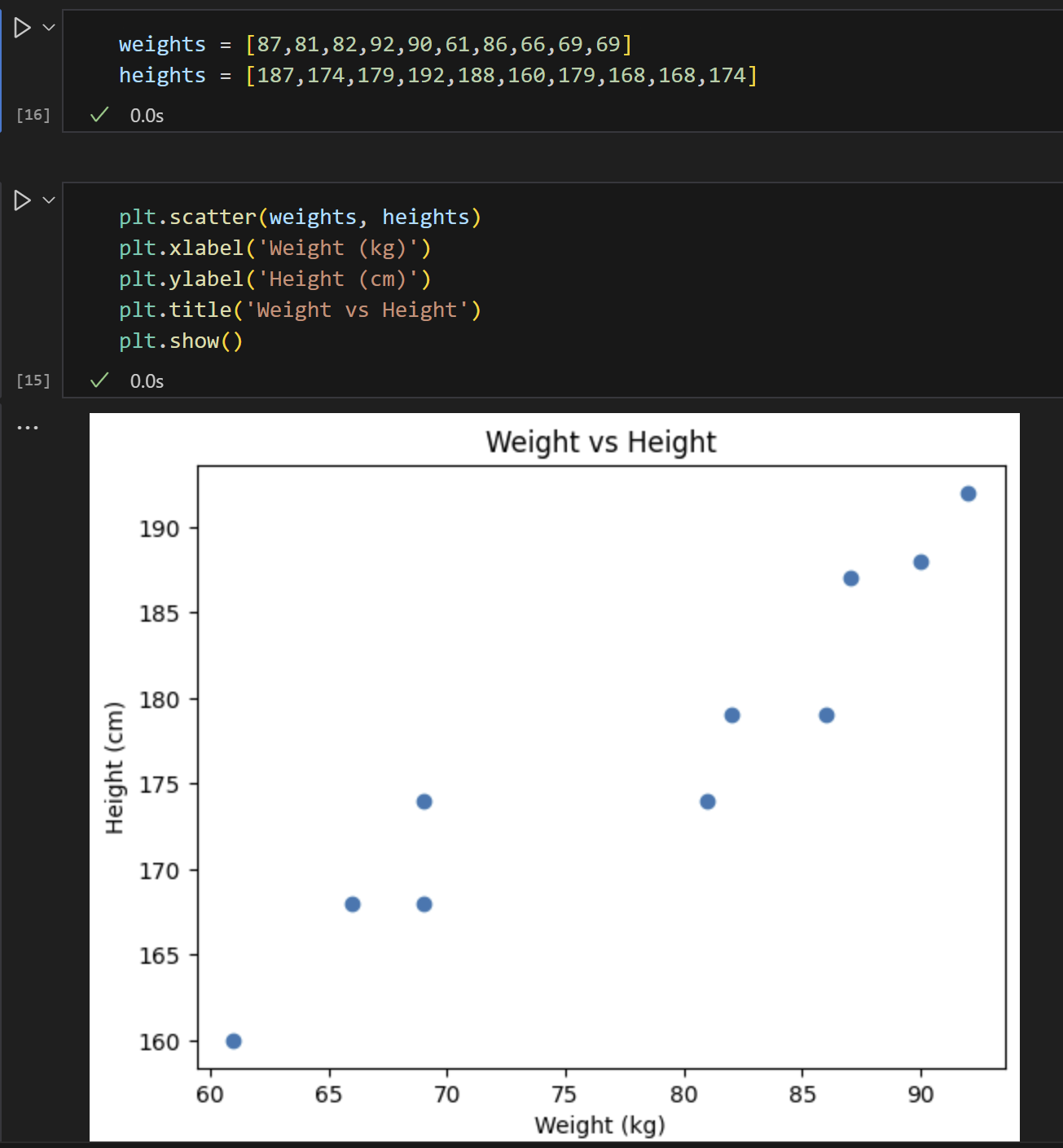
- 머신이는 키와 몸무게에 대한 데이터가 너무 많아서 두 점을 이어 직선을 만들지 고민 되었지만, 수 많은 점들을 관통하는 여러개의 직선을 많이 그려보기로 했다.
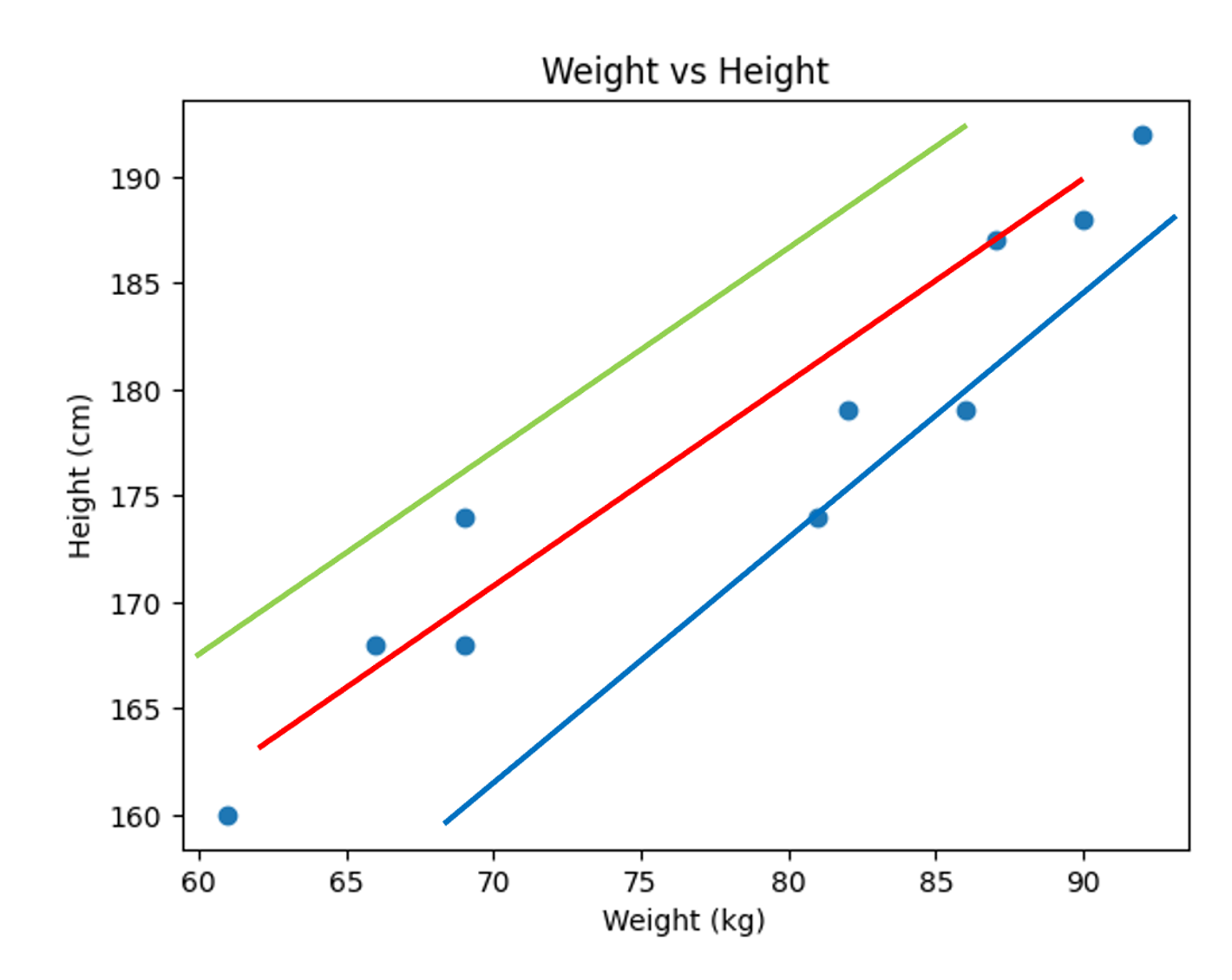
- 어떤 직선이 현재 데이터를 잘 설명한다고 할 수 있나?
= 빨간색 그래프가 적절해 보이지만, 이렇게 대강 직선을 그으면 적절한 그래프를 찾기 어렵다.
Data Scientific 한 발상
- 직선과 점 사이의 거리를 계산하는 것이다. 이를 Error라고 정의하고 최소의 Error인 직선을 그리면 된다.
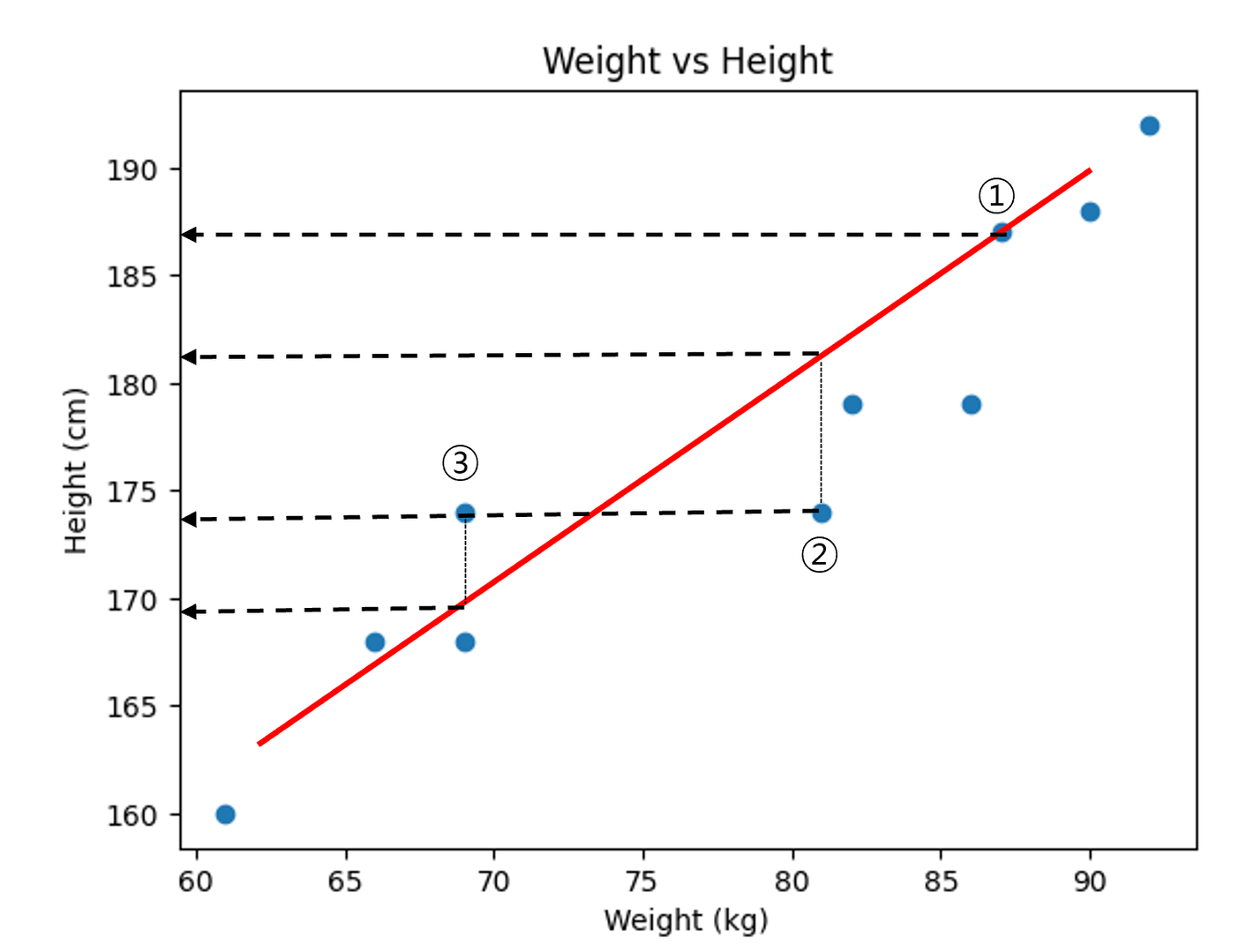
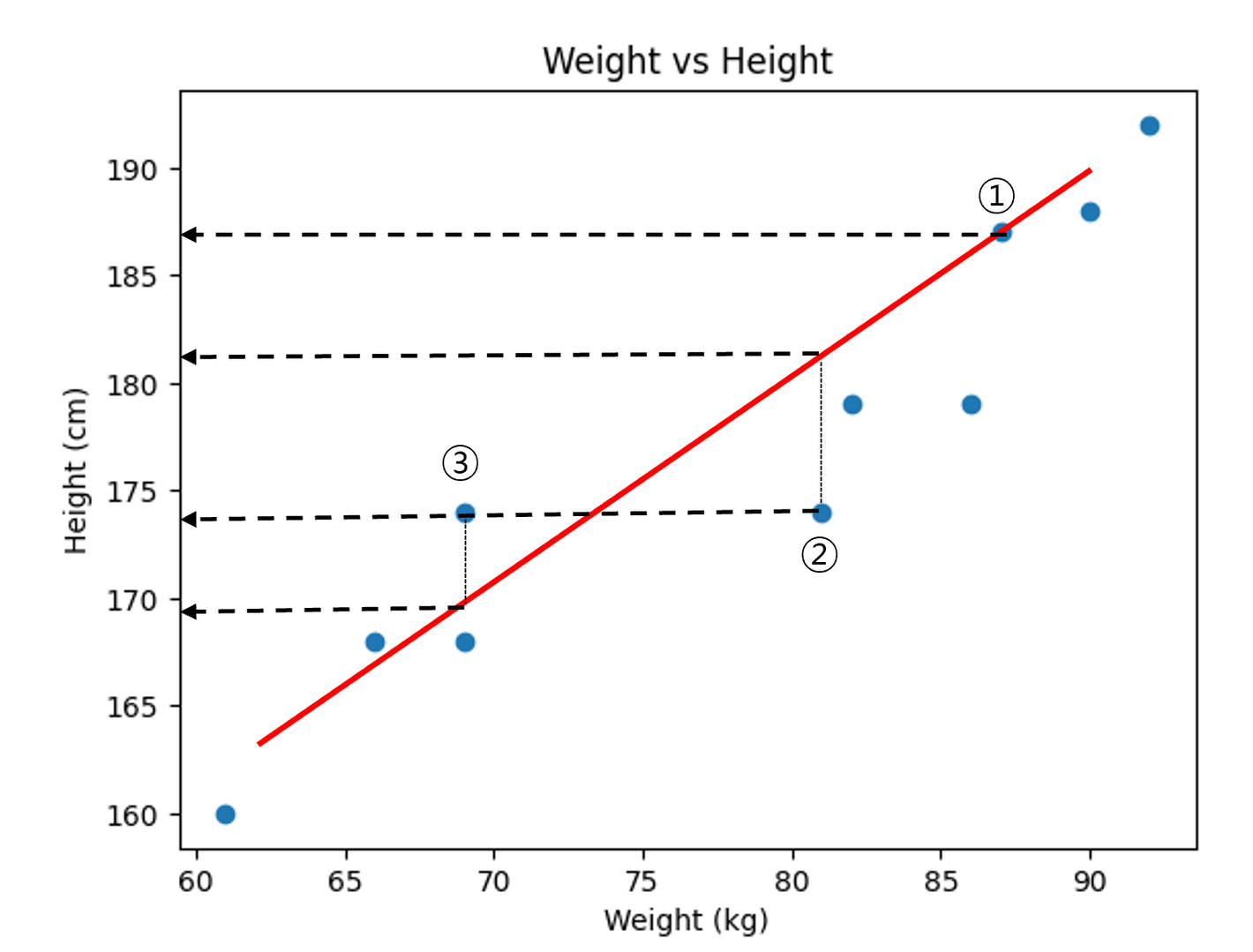
방법 1) 실제 데이터 값 - 직선의 예측 값 = Error
- ①번 실제 데이터 : 187, 예측 데이터 : 187 Error:0
- ②번 실제 데이터 : 174, 예측 데이터 : 181 Error:-7
- ③번 실제 데이터 : 174, 예측 데이터 : 169 Error:+5
But❗ 선분을 기준으로 위에 있는 데이터의 거리를 계산하면 양수이지만, 아래에 있는 데이터는 음수가 된다. 이 경우, 모든 에러를 합치면 서로 상쇄되는 문제가 있었다. 따라서, 음수를 양수로 만들기 위해 제곱을 하는 방법이 있다는걸 생각해 냈다.
방법 2) 각각 Error를 제곱하여 모두 더하기
- ①,②,③의 제곱 합 : 49+25=71
But❗나중에 데이터를 더 수집할 예정인데, 데이터가 더 늘어날 수록(④,⑤) 에러는 자연스럽게 값이 커질 수 밖에 없는 것이다! 그래서 데이터의 갯수로 나누고 제곱을 풀기 위해서 root를 씌우기로 했다.
방법 3) 전체 Error 합에 데이터의 갯수로 나누기
- ①,②,③만 고려한다면 71/3 → 23.7 = 오차 합의 평균
즉❗
- 데이터를 관통하는(=잘 설명하는) 직선을 그었을 때, 직선이 '예측하는 모델'이라 생각하고, 실제 값과 예측 값의 차이가 작을 수록 '예측을 잘 했다!' 이다.
- 문제는, 어떤 값은 실제값과 예측값의 차이가 양수이지만, 어떤 값은 음수가 된다.
- 서로 상쇄되지 않도록, 제곱을 씌워 음수를 양수화한다.
- 데이터가 늘어날수록, 데이터의 오차가 생긴다. = 데이터가 늘어날수록 오차의 합이 증가한다. 그래서, 오차 합을 갯수로 나눈다.
선형회귀 이론
- 머신이는 몸무게를 알면 키를 알 수 있을 것이라 생각했다. 이를 이용하여 방정식을 세우고 용어를 정리해보겠어.
선형회귀 용어 정리
- 공통
- Y는 종속 변수, 결과 변수 (= 알고 싶은 값)
- X는 독립 변수, 원인 변수, 설명 변수 (= Y에 영향을 주는 값)
- 통계학에서 사용하는 선형회귀 식
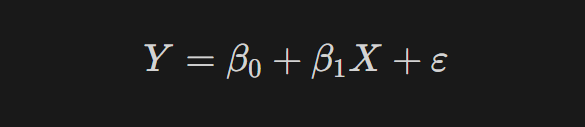
- : 편향(Bias) (=절편)
- : 회귀 계수 (=기울기)
- : 오차(에러), 모델이 설명하지 못하는 Y의 변동성
- 머신러닝/딥러닝에서 사용하는 선형회귀 식
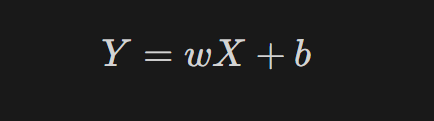
- : 가중치
- b: 편향(Bias)
- 머신러닝/딥러닝 모델에서 오차 항은 명시적으로 다루지 않음
❗결국❗
두 수식이 전달하려고 하는 의미는 같다. 회귀 계수 혹은 가중치의 값을 알면 X가 주어졌을 때, Y를 알 수 있다는 것이다!
(ex. y=5x+5, x=1일때, y=10이다.)
우리는 편의를 위해 X의 계수는 가중치라고 지칭할거다!
- 몸무게와 키 데이터를 이용하여 선형회귀 식을 만들면, y=0.86x+109.37이다.
= 즉, 1kg 증가할때마다 키가 0.86cm 증가한다는 것이다.
⚠️주의
1) 는 1차 방정식의 Y절편에 해당한다. 근데 얘는 왜 따로있냐?
- 선분위에 모든 데이터가 있는건 없다. 실제 데이터와 예측 데이터가 똑같은 완벽한 데이터는 없기 때문에, Error를 통해 보완하는거다.
2) 가중치()를 알게되면 X값에 대해 Y값을 예측할 수 있다는 건데, 그럼 가중치는 어째구함?
- 이게바로 머신러닝을 관통하는 질문이다. 데이터가 충분히 있다면 가중치를 '추정'할 수 있다. 뒤에 따로 설명하겠지만, 간단하게 말하자면 그래프를 수도 없이 그려서 에러를 '최소화'하는 직선을 구하는 것이라고 할 수 있다.

First time, Last time, Every time.