1 노이즈
1.1 노이즈(Noise)
- 측정된 변수에 무작위의 오류(random error) 또는 분산(variance)이 존재하는 것
1.1-1 정형 데이터의 노이즈
- 정형 데이터에서 노이즈는 분산(varianve)으로 나타냄
- 분산 : 데이터의 무작위 변동을 의미함
- 이상치 : 데이터의 무작위 변동을 초과하는 특정한 값으로 별도로 처리함
- 통계 모형에서는 오차항으로 나타남
- 오차항 : 모형에서 설명하지 못하는 무작위 변동을 의미함
- ex) 단순선형회귀모형 -> 오차항 ϵi가 노이즈
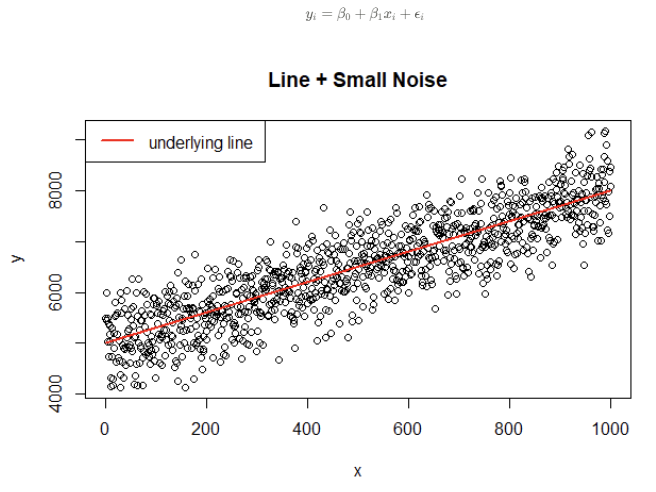
1.1-2 이미지/영상 데이터의 노이즈
- 이미지/영상에서 노이즈는 blur, white noise, pink noise, Guasian noise등 다양한 형태로 나타남
- blur : 이미지가 흐릿하게 보이는 현상
- white noise : 백색 잡음, 모든 주파수를 가진 잡음
- pink noise : 특정 주파수 대역 (일반적으로 낮은 주파수) 에서 강하게 나타나는 노이즈
- Gaussian noise : 가우시안 분포를 따르는 잡음
- 이미지/노이즈의 주요 원인
- 이미지 획득 과정에서 너무 낮은 수집된 광자의 양, 센서/렌즈의 열화 (degradation 등
- 이미지 전송 중 무선 통신의 에코 및 대기 왜곡 등

1.1-3 시계열/음성/신호 데이터의 노이즈
- 시계열/음성/신호에서 노이즈는 일반적으로 white noise (백색잡음) or Gaussian noise (가우시안 잡음) 으로 나타남
- 백색잡음 : 모든 주파수 영역에서 동일한 에너지를 갖는 잡음
- 가우시안 잡음 : 평균이 0, 분산이 1인 정규분포를 따르는 잡음
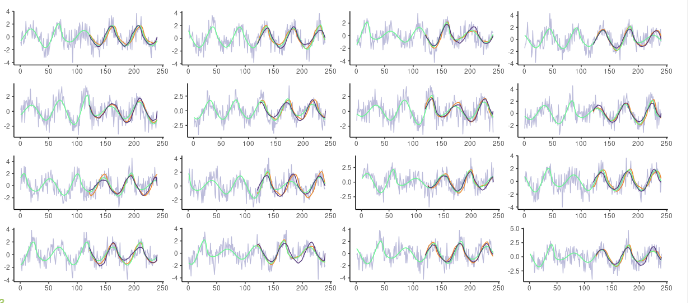
1.1-4 텍스트 데이터의 노이즈
- 일반적으로 철자, 오류, 약어, 비표준 단어, 반복, 구두점 누락, 대소문자 정보누락, "음" 및 "어"와 같은 의성어 등
- 텍스트 데이터의 노이즈는 자연어 처리의 성능을 저하시키는 중요한 요인
- 자동 음성 인식, 광학 문자 인식, 기계 번역, Web Scraping 등으로 수집한 데이터에 노이즈가 많음
👉 ex) 음성 인식

1.2 Defact(결함) vs Fault(불량) vs Artifact(아티팩트) vs Noise(잡음, 노이즈)
- Defact, Falut, Artifact, Noise는 의미는 명확하게 구분되지만, 혼재되어 사용됨
1. Defact
- Defact는 전체 데이터에 존재하는 일부 오류(error) 데이터
- 범위에서 벗어난 이상치(outlier)가 아니라, 잘못된(error) 데이터
- 주로 생산, 제조 분야에서 사용하는 용어
- Defact가 제품/설비의 기능에 손상을 야기하면 제품/설비가 Fault(불량/기능이상)이 됨
- 모든 defect가 fault를 야기하진 않음
👉 ex) 반도체 결함

- Artifact(아티팩트)는 Defact와 동일한 의미를 갖는 용어
- 주로 과학기술 분야에서 사용하는 용어, 특히 이미지의 defect를 지칭
👉 ex) 두개골
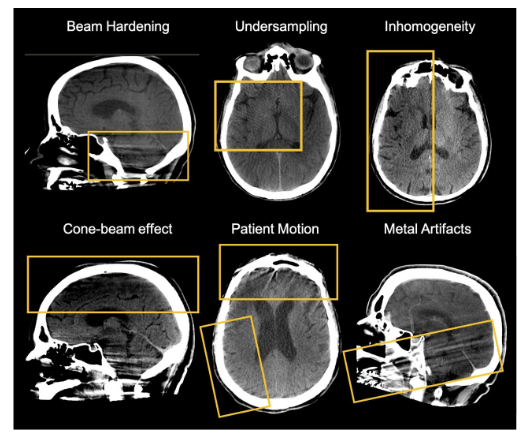
2. Noise(잡음, 노이즈)
- Noise는 일반적으로 그 원인을 알 수 없는 무작위 변동을 의미함
- 무작위(random)가 발생하는 기전(mechanism)을 알 수 없다는 의미임
- 주로 신호처리(signal processing) 분야에서 사용하는 용어임
- 데이터 과학에서는 데이터의 무작위 변동을 의미
- 동작 기전을 모르므로 제거는 불가하고, 이를 저감(Denoising) 해야함
- 디노이징 기법은 기본적으로 평활화(smoothing, 구간평균), 구간화(binning, 구간집계), 필터링(filtering, 주파성분 저감) 기법을 사용함
2 디노이징(Denoising)
- 디노이징은 데이터에서 노이즈를 저감하여 모형이 더 좋은 성능을 할 수 있도록 하는 전처리 과정
2.1 정형 데이터의 디노이징
- 구간화(Binning)
- 정렬된 데이터 값들을 몇 개의 bin(혹은 bucket)으로 분할하여 대표값으로 대체
- 군집화(clustering)
- 유사한 값들을 하나의 군집으로 처리하여 중심점(centroid)을 대표값으로 대체
2.1-1 구간화(Binning)
✍ 구간설정 방법
1. 동일 간격(equal-distance) 구간화 -> pandas의 cut() 사용
- 동일한 간격으로 구간을 설정
- 정상 데이터가 한쪽으로 편중(biassed)되고 outlier에 의해 영향을 많이 받음
- 한쪽으로 몰려있는 데이터들은 다 동일한 bin으로 들어오기 때문에 skewed data를 다룰 수 없음
2. 동일 빈도(eual-frequency) 구간화 → pandas의 qcut() 사용
- 동일한 개수의 데이터를 가지는 구간으로 설정
✍ 구간별 대표값 설정 방법
- 평균값 평활화 : bin에 있는 값들을 평균값으로 대체
- 중앙값 평활화 : 중앙값으로 대체
- 경계값 평활화 : 경계값 중 가까운 값으로 대체
import pandas as pd
import numpy as np
# 데이터 생성하기, 결과를 보기 용이하도록 sort
df = pd.DataFrame({'uniform': np.sort(np.random.uniform(0,10,10)),
'normal': np.sort(np.random.normal(5,1,10)),
'gamma': np.sort(np.random.gamma(2, size=10))})
# 데이터 확인하기
df.plot(kind='hist', bins=15, alpha=0.5)
df.describe() ↳ 결과
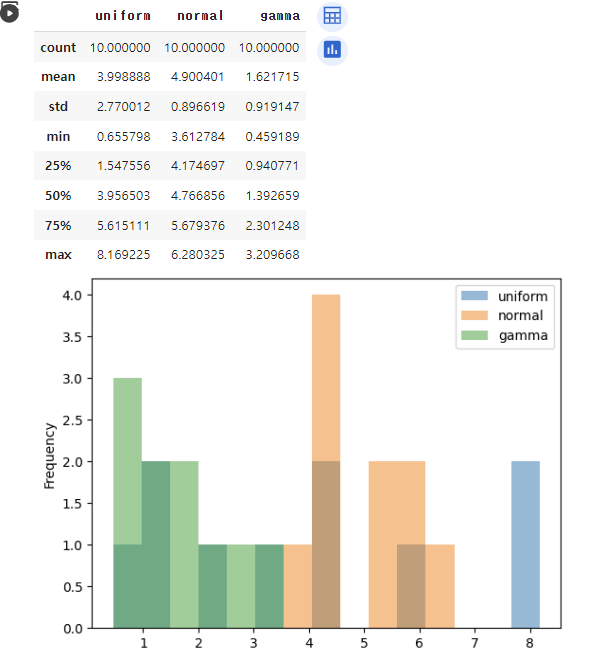
2.1-1-(1) Pandas로 구간화
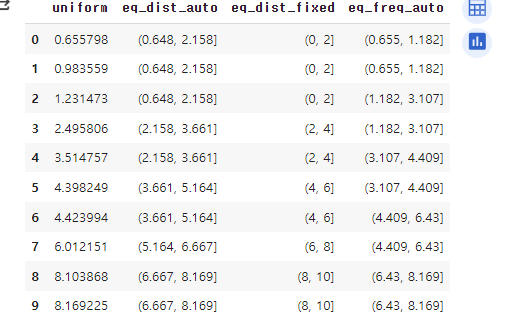
# cut(), qcut() 기본 동작 확인
col = 'uniform'
num_bins = 5
df_binned = pd.DataFrame()
df_binned[col] = df[col].sort_values() # 원 데이터
df_binned['eq_dist_auto'] = pd.cut(df_binned[col], num_bins) # 동일 간격으로 나누기
df_binned['eq_dist_fixed'] = pd.cut(df_binned[col], bins=[0,2,4,6,8,10]) # 지정된 구간으로 나누기
df_binned['eq_freq_auto'] = pd.qcut(df_binned[col], num_bins) # 동일 빈도로 나누기
df_binned↳ 결과
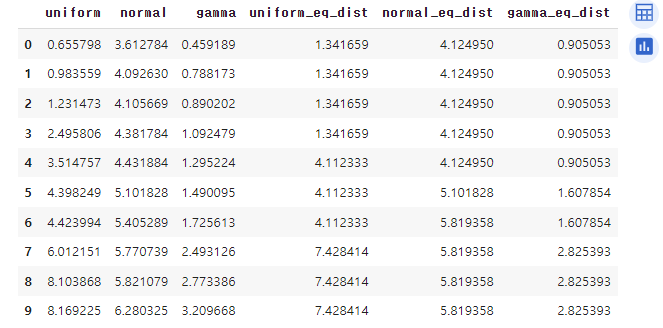
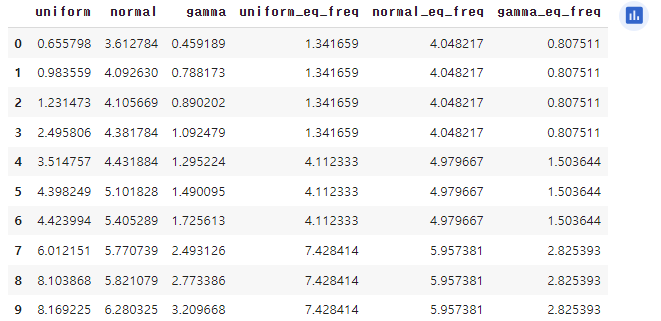
# 구간화하여 평균값 대체하기
cols = ['uniform', 'normal', 'gamma']
# 동일 간격 구간화
df_ew = df.copy()
for col in cols:
df_ew[col+'_eq_dist'] = pd.cut(df_ew[col], 3) # 구간으로 나누기
means = df_ew.groupby(col+'_eq_dist')[col].mean() # 구간별 평균값 계산
df_ew.replace({col+'_eq_dist': means}, inplace=True) # 평균값으로 대체
display(df_ew)
# 동일 빈도 구간화
df_ef = df.copy()
for col in cols:
df_ef[col+'_eq_freq'] = pd.qcut(df_ef[col], 3) # 구간으로 나누기
means = df_ef.groupby(col+'_eq_freq')[col].mean() # 구간별 평균값 계산
df_ef.replace({col+'_eq_freq': means}, inplace=True) # 평균값으로 대체
display(df_ef)
# 시각화
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 2, figsize=(10,5))
df_ew.astype(float).plot(ax=axes[0])
df_ef.astype(float).plot(ax=axes[1])
plt.show()↳ 결과
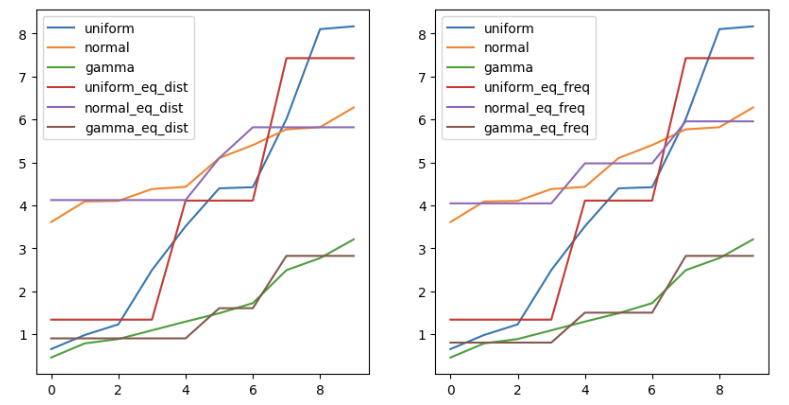
2.1-2 군집화(clustering)
2.1-2-(1) Scikit-Learn으로 구간화
- KBinsDiscretizer() 사용
- encode{‘onehot’, ‘onehot-dense’, ‘ordinal’}, default=’onehot’
- strategy{‘uniform’(동일간격), ‘quantile’(동일빈도), ‘kmeans’(K-Means 군집화)}, default=’quantile’
import warnings
# hide warnings
warnings.filterwarnings("ignore")
from sklearn.preprocessing import KBinsDiscretizer
# 동일 간격 구간화
ed_binner = KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='uniform', subsample=None)
df_ed = ed_binner.fit_transform(df)
# 동일 빈도 구간화
ef_binner = KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='quantile', subsample=None)
df_ef = ef_binner.fit_transform(df)
# K-means 구간화
km_binner = KBinsDiscretizer(n_bins=3, encode='ordinal', strategy='kmeans', subsample=None)
df_km = km_binner.fit_transform(df)
# 결과 확인
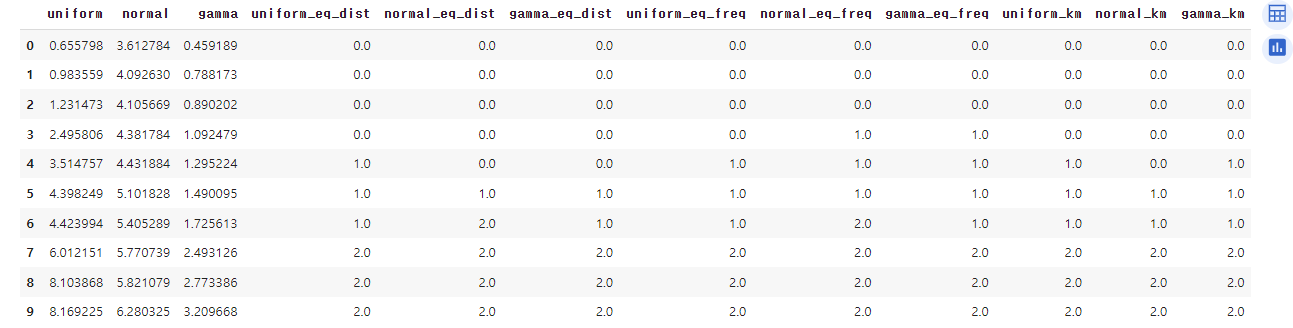
df_ed = pd.DataFrame(df_ed, columns=df.columns+'_eq_dist')
df_ef = pd.DataFrame(df_ef, columns=df.columns+'_eq_freq')
df_km = pd.DataFrame(df_km, columns=df.columns+'_km')
df_bin = pd.concat([df, df_ed, df_ef, df_km], axis=1)
df_bin↳ 결과
# 구간화하여 평균값 대체하기
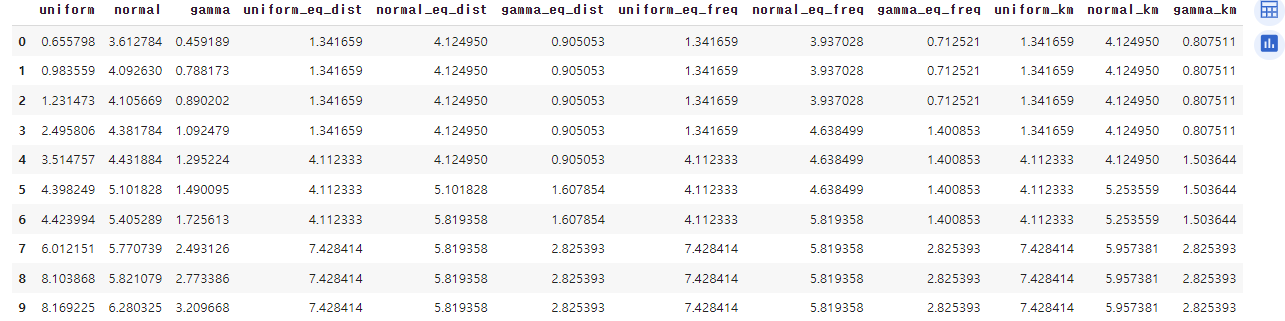
for bin_col in df_bin.columns:
col = bin_col.split('_')[0]
means = df_bin.groupby(by=bin_col)[col].mean() # 구간별 평균값 계산
df_bin.replace({bin_col: means}, inplace=True) # 평균값으로 대체
df_bin↳ 결과
# 시각화
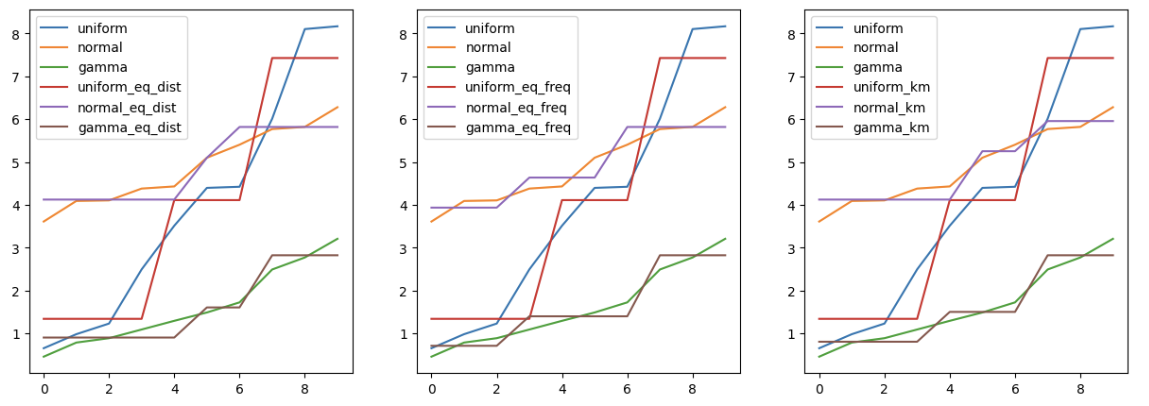
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 3, figsize=(15,5))
pd.concat([df_bin.iloc[:,:3], df_bin.iloc[:,3:6]], axis=1).astype(float).plot(ax=axes[0])
pd.concat([df_bin.iloc[:,:3], df_bin.iloc[:,6:9]], axis=1).astype(float).plot(ax=axes[1])
pd.concat([df_bin.iloc[:,:3], df_bin.iloc[:,9:]], axis=1).astype(float).plot(ax=axes[2])
plt.show()↳ 결과
응용 사례
2 디노이징 응용
# 특성 이산화
# 라이브러리 불러오기
import numpy as np
from sklearn.preprocessing import Binarizer
# 특성 만들기
age = np.array([[6],
[12],
[20],
[36],
[65]])
# Binarizer 객체를 만들기
binarizer = Binarizer(threshold=18)
# 특성 변환하기
binarizer.fit_transform(age)↳ 결과

# 특성을 나눈다
np.digitize(age, bins=[20,30,64])↳ 결과

# 특성을 나눈다
np.digitize(age, bins=[20,30,64], right=True)↳ 결과

# 특성을 나눈다
np.digitize(age, bins=[18])↳ 결과

from sklearn.preprocessing import KBinsDiscretizer
# 네 개의 구간으로 나누기
kb = KBinsDiscretizer(4, encode='ordinal', strategy='quantile')
kb.fit_transform(age)↳ 결과

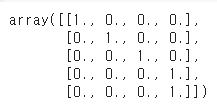
# 원-핫 인코딩을 반환함
kb = KBinsDiscretizer(4, encode='onehot-dense', strategy='quantile')
kb.fit_transform(age)↳ 결과
# 동일한 길이의 구간을 만듦
kb = KBinsDiscretizer(4, encode='onehot-dense', strategy='uniform')
kb.fit_transform(age)↳ 결과

kb.bin_edges_↳ 결과


나의 기록장