프로젝트
<목차>
1 주제 및 선정 이유
2 코드 및 결과 설명
3 느낀점
1 주제 및 선정 이유
2023-2학기에 '데이터 전처리' 수업을 들으면서 머릿속에 흩어져서 존재하던 데이터 분석 과정과 그 과정에서 활용되는 분석 절차, 코드, 여러가지 툴이 어느정도 정리가 되는것 같았다.
그래서 데이터 전처리 수업 시간에 배운 내용 일부분을 적용하여 내용 정리 겸 실제 데이터 분석에 적용을 해보고자 한다.
주제는 '남산도서관의 도서 대출건수 예측' 이다. 도서관 대출 데이터를 사용해 분석에 불필요한 문자, 행, 열 등을 제거하고 머신러닝 기법을 이용하여 남산도서관의 도서 대출건수를 예측하는 간단한 프로젝트를 해보는 것이다.
(데이터 전처리 과정에서 중간중간 코드 실행은 했지만, 너무 분량이 많아져서 벨로그에 첨부하지 않은 것도 있음!!)
2 코드 및 설명
1. 데이터 전처리 하기
1) 불필요한 데이터 삭제하기
📝 불필요한 행과 열을 제거하기 위해 짧게 여러개씩 작성했던 코드들을 새로운 데이터에 적용하기 쉽도록 일괄처리하는 data_cleansing( ) 이라는 일괄처리용 함수를 만들어서 처리를 해보았다. 남산도서관에서 새로운 도서 데이터를 다운로드 했을때 dropna() 하고 groupby()등을 일일이 하기에는 너무 코드가 길었다. 따라서 필요한 코드만 파이썬 def함수로 만들어서 저장하면 간단하게 함수를 호출하거나 파이썬 스크립트를 실행하여 데이터 전처리를 하는 과정을 단순하게 만들 수 있다.
ns_book4.to_csv('ns_book4.csv', index=False) # 분석에 활용할 csv파일 (한줄한줄씩 전처리해서 만든 데이터프레임 (불필요한 데이터들 제거한거))
# 남산 도서관 장서 csv 데이터 전처리 함수
def data_cleaning(filename):
# 파일을 데이터프레임으로 읽음
ns_df = pd.read_csv(filename, low_memory=False) # 여기서 filename은 csv파일 이름을 말함
# NaN인 열을 삭제함
ns_book = ns_df.dropna(axis=1, how='all')
# 대출건수를 합치기 위해 필요한 행만 추출하여 count_df 데이터프레임을 만듦
count_df = ns_book[['도서명','저자','ISBN','권','대출건수']]
# 도서명, 저자, ISBN, 권을 기준으로 대출건수를 groupby함
loan_count = count_df.groupby(by=['도서명','저자','ISBN','권'], dropna=False).sum()
# 원본 데이터프레임에서 중복된 행을 제외하고 고유한 행만 추출하여 복사함
dup_rows = ns_book.duplicated(subset=['도서명','저자','ISBN','권'])
unique_rows = ~dup_rows
ns_book3 = ns_book[unique_rows].copy()
# 도서명, 저자, ISBN, 권을 인덱스로 설정
ns_book3.set_index(['도서명','저자','ISBN','권'], inplace=True)
# load_count에 저장된 누적 대출건수를 업데이트함
ns_book3.update(loan_count)
# 인덱스 재설정함
ns_book4 = ns_book3.reset_index()
# 원본 데이터프레임의 열 순서로 변경함
ns_book4 = ns_book4[ns_book.columns]
return ns_book4📝 위에서 원본 데이터인 ns_202104.csv 파일을 전달하여 새로운 데이터프레임인 new_ns_book4를 만들고, 내가 개인적으로 한줄한줄씩 전처리해서 만든 ns_book4 데이터프레임과 같은지 비교를 해보았다. 다른 데이터프레임과 비교할때는 equals() 사용!!
(개인적으로 한줄씩 전처리를 해본 ns_book4는 너무 내용이 많아서 못넣었음)
new_ns_book4 = data_cleaning('ns_202104.csv')
ns_book4.equals(new_ns_book4)결과
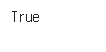
👉 내가 개인적으로 한줄씩 전처리를한 ns_book4 와 위의 일괄처리 함수가 수행한 데이터프레임이 같다고 나왔다. 이를 통해서 남산 도서관을 제외한 새로운 장서 데이터를 분석하고 싶으면, 위의 일괄처리용 함수를 수행해서 전처리 작업을 간단하게 한번에 끝낼 수 있다.
2) 잘못된 데이터 수정하기
📝 1)의 '불필요한 데이터 삭제하기' 과정에서도 말했듯이 2)의 과정도 한줄한줄씩 코랩에서 잘못된 데이터에 한해서 개인적으로 전처리를 해보았다. 그러나 코드가 너무 길어져서 1)과 마찬가지로 일괄처리 함수를 작성하여 그나마 간단하게 잘못된 데이터를 전처리를 해보았다.
ns_book6.to_csv('ns_book6.csv', index=False) # 한줄씩 전처리해서 만든 데이터프레임 (NaN이랑 잘못된거 처리한거)
def data_fixing(ns_book4):
# 도서권수와 대출건수를 int32로 바꿈
ns_book4 = ns_book4.astype({'도서권수':'int32', '대출건수': 'int32'})
# NaN인 세트 ISBN을 빈문자열로 바꿈
set_isbn_na_rows = ns_book4['세트 ISBN'].isna()
ns_book4.loc[set_isbn_na_rows, '세트 ISBN'] = ''
# 발행년도 열에서 연도 네 자리를 추출하여 대체, 나머지 발행년도는 -1로 바꿈
ns_book5 = ns_book4.replace({'발행년도':'.*(\d{4}).*'}, r'\1', regex=True)
unkown_year = ns_book5['발행년도'].str.contains('\D', na=True)
ns_book5.loc[unkown_year, '발행년도'] = '-1'
# 발행년도를 int32로 바꿈
ns_book5 = ns_book5.astype({'발행년도': 'int32'})
# 4000년 이상인 경우 2333년을 뺀다
dangun_yy_rows = ns_book5['발행년도'].gt(4000)
ns_book5.loc[dangun_yy_rows, '발행년도'] = ns_book5.loc[dangun_yy_rows, '발행년도'] - 2333
# 여전히 4000년 이상인 경우 -> -1로 바꿈
dangun_year = ns_book5['발행년도'].gt(4000)
ns_book5.loc[dangun_year, '발행년도'] = -1
# 0~1900년 사이의 발행년도는 -1로 바꿈
old_books = ns_book5['발행년도'].gt(0) & ns_book5['발행년도'].lt(1900)
ns_book5.loc[old_books, '발행년도'] = -1
# 도서명, 저자, 출판사가 NaN이거나 발행년도가 -1인 행을 찾음
na_rows = ns_book5['도서명'].isna() | ns_book5['저자'].isna() \
| ns_book5['출판사'].isna() | ns_book5['발행년도'].eq(-1)
# 교보문고 도서 상세 페이지에서 누락된 정보를 채움
updated_sample = ns_book5[na_rows].apply(get_book_info,
axis=1, result_type ='expand')
updated_sample.columns = ['도서명','저자','출판사','발행년도']
ns_book5.update(updated_sample)
# 도서명, 저자, 출판사가 NaN이거나 발행년도가 -1인 행을 삭제함
ns_book6 = ns_book5.dropna(subset=['도서명','저자','출판사'])
ns_book6 = ns_book6[ns_book6['발행년도'] != -1]
return ns_book6
👉 위의 일괄처리 함수도 엄~청 분량이 많은 편이지만, 한줄한줄 전처리를 했을 때보다는 그래도 적은편이었다. 이렇게 불필요한 데이터들과 결측치, 오류가 있는 데이터들을 처리하면 드디어 분석에 활용할 데이터가 만들어진 것이다.
2. 머신러닝으로 예측하기
📝 위에서 전처리해서 만든 ns_book6 에서 sum(ns_book['도서권수']==0) 으로 도서권수의 열의 값이 0인 행의 개수를 확인했더니, 3206개가 나왔다. 정확하지 않은 판단일수도 있지만 0권은 의미없다고 생각해서 삭제했다.
ns_book7 = ns_book6[ns_book6['도서권수']>0]
# 도서권수가 0인 데이터 제외한것을 ns_book7에 저장함📝 이제 머신러닝에 활용할 데이터는 ns_book7이다.
1) 대출건수 예측하기
✔ 훈련 데이터와 검증 데이터로 나누기
# ns_book7 데이터를 다운받고 데이터프레임으로 불러옴
import gdown
gdown.download('https://bit.ly/3pK7iuu', 'ns_book7.csv', quiet=False)
import pandas as pd
ns_book7 = pd.read_csv('ns_book7.csv', low_memory=False)
ns_book7.head()결과

from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(ns_book7, random_state=42)
print(len(train_set), len(test_set))
결과
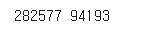
📝 코드 실행결과 전체에서 75%가 훈련 데이터, 25%가 검증 데이터로 나누어졌다. 이제 사이킷런에 있는 선형회귀모델을 위의 데이터로 훈련해본다.
X_train = train_set[['도서권수']]
y_train = train_set['대출건수']
print(X_train.shape, y_train.shape)결과
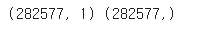
📝 X_train은 282577개의 행과 1개의 열로 이루어진 데이터프레임이고, y_train은 '시리즈 객체' 즉 282577개 원소를 가진 1차원 배열이다. (사이킷런이 입력으로는 2차원 배열, target으로는 1차원 배열을 기대하기 때문에 이런식으로 해줬다.)
✔ 선형회귀모델 훈련
📝 이제 사이킷런의 linear_model 모듈의 LinearRegression 클래스를 불러와서 선형회귀모델을 훈련시켜본다.
from sklearn.linear_model import LinearRegression
lr = LinearRegression() # LinearRegression 클래스의 객체 lr 만들었음
lr.fit(X_train, y_train) # fit() 메서드를 호출해서 모델을 훈련함결과
✔ 훈련시킨 모델 평가하기
X_test = test_set[['도서권수']]
y_test = test_set['대출건수']
lr.score(X_test, y_test)결과
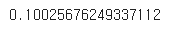
📝 위의 결과를 보면 점수가 0.1이므로 점수가 안좋다. 도서권수로 대출건수를 예측하는건 어렵다고 본다.
✔ 선형회귀로 연속적인 값을 예측하기
- 선형회귀 : 선형함수를 사용하여 모델을 만드는 알고리즘
- 식 : y = ax + b
- 선형회귀알고리즘이 fit() 메서드를 호출했을때 데이터에서 학습한것이 기울기 a와 절편 b이다.
- 식 : y = ax + b
print(lr.coef_, lr.intercept_)
# lr.coef_ : 학습된 기울기, lr.intercept_ : 절편결과
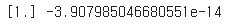
📝 위의 결과를 보면 기울기는 1, 절편은 0에 매우 가까운 음수이다. 따라서 선형회귀모델 : y = x 이다.
✔ 로지스틱회귀로 카테고리 예측하기
- 로지스틱회귀 : 분류 알고리즘의 대표적인 예시
- 로지스틱 함수를 사용하여 연속적인 실수 출력값을 1 또는 0으로 변환한다.
- 로지스틱 함수를 '시그모이드 함수' 라고 한다.
📝 로지스틱회귀 모델을 만들기 전에, 먼저 타겟 y_train과 y_test를 이진 분류에 맞게 바꿔야한다. 즉, 음성 클래스에 해당하는 0과 양성 클래스에 해당하는 1로 바꿔야한다. 아래 코드는 도서권수로 대출건수가 평균보다 높은지 아닌지를 예측하는 이진분류를 하는 코드이다.
borrow_mean = ns_book7['대출건수'].mean()
y_train_c = y_train > borrow_mean
y_test_c = y_test > borrow_meanfrom sklearn.linear_model import LogisticRegression
logr = LogisticRegression()
logr.fit(X_train, y_train_c) # 훈련 세트로 fit() 메서드를 호출함
logr.score(X_test, y_test_c) # 검증 세트로 score() 메서드를 호출함 결과
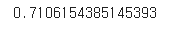
📝 실행 결과를 보면 71%정도를 맞췄다. 나름 괜찮은 결과가 나왔다. 그러나, y_test_c에 있는 음성 클래스와 양성 클래스의 비율이 비슷하지 않다는 문제점이 있다.
✔ 양성 클래스와 음성 클래스 분포 확인해보기
y_test_c.value_counts()결과

📝 음성 클래스가 69% 정도이고 양성 클래스는 31% 정도이다. 이제 더미모델로 score() 메서드의 결과를 확인해본다.
from sklearn.dummy import DummyClassifier
dc = DummyClassifier()
dc.fit(X_train, y_train_c)
dc.score(X_test, y_test_c)결과
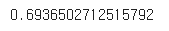
📝 69% 정도로 정확도가 나왔다. 이 값이 모델을 만들때 기준점이 되는 점수이다. 만약 이 점수보다 낮으면 좋은 모델이라고 하기 어렵다.
3 느낀점
이번 프로젝트를 하면서 데이터 전처리 과정은 형식적인 과정은 딱 정해져 있다는걸 알면서도, 막상 해보면 그 안에서 논리적으로 꼼꼼하게 생각해야 할 것들이 많다고 느꼈다.
그렇지만 이러한 점은 내가 전처리를 많이 해보지 않아서 능숙하지 않기 때문에 어렵다고 느끼는 것이다. 많이 해봐야지 실력이 늘 것이기 때문에 방학기간을 활용해서 파이썬으로 데이터 전처리를 능숙하게 할 수 있도록 연습을 해야겠다. 또, 코딩만 잘하면 되는것이 아니라 모델을 사용할 때 통계적 개념이 거의 필수이기 때문에 통계 공부도 같이 해야겠다고 생각했다. 나는 R데이터분석 수업을 들을때도 로지스틱회귀가 정말 헷갈리고 어려웠는데, 여기서도 하는 데에 애를 먹었었다. 로지스틱회귀는 이번에 실습하면서 80%는 이해한것 같다.
더 나아가서 나는 파이썬보다는 R이 그나마 익숙한데, R로 코드를 작성한 것을 파이썬으로 그대로 작성해 보는 공부를 할 예정이다.
