BEIT v1
Abstract
Bidirectional Encoder representation from Image Transformers(BEIT)
이미지를 image patches , visual tokens 이 두가지로 봐서 transformer를 masked image modeling 방법으로 pre-train 시키는 방법을 제안한다.
다시 말해, 이미지를 "토큰화"하여 visual tokens 로 쪼개고, 이미지를 쪼개기만 한 image patches 중 일부를 mask하여 mask된 부분의 visual token 값을 예측하도록 학습시켰다.
이후 classification, segmentation에 적용시켜 보았다.
1. Introduction
Transformer가 등장하고, vision 쪽에도 쓰이기 시작하면서, vision transformer를 학습하는데 CNN보다 더 많은 데이터가 필요해졌다.
이를 해결하기 위해 self-supervised 방식으로 해결하려 했고, contrastive learning 과 self-distillation(?) 방식으로 접근하였다.
BERT가 NLP에서 성공적이었던건 input text 일부를 mask하고 맞추는 방식으로 transformer를 학습했기 때문이다.
이 아이디어를 vision으로 끌어와서 할건데 고려할 게 있다.
-> 언어와 다르게 이미지에는 pre-exist vocabulary가 없다.
따라서 mask된 부분을 예측할 때 후보라고 할 만한게 없어 softmax를 무한히 할 수도 없는 노릇이니 애매하다.
-> 이걸 regression으로 각 픽셀값을 예측하게 하면 어떨까. 모델이 너무 세세한 부분(short range dependency, high-frequency detail)을 잡는데 낭비가 커진다는 문제가 생긴다.
이 논문에서 위 문제 해결을 위해 Masked Image Modeling (MIM) 을 제안한다.
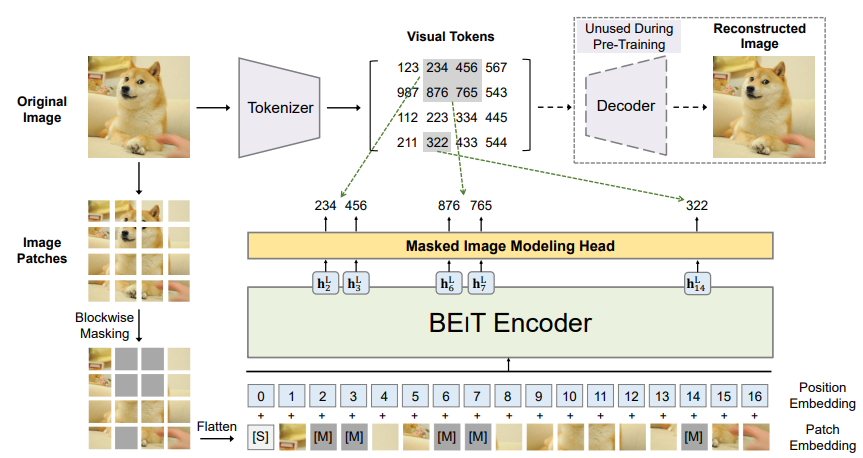
- 이미지를 패치단위로 쪼개고, 그 중 일부를 mask해
special mask embedding [M]으로 대체하여 backbone vision Transformer의 입력으로 넣어준다. -> Image Patches - 이미지를 discrete VAE에서 사용한 코드로 토큰화해 준다.(-자세한건 VAE를 공부해보자) -> Visual Tokens
- Transformer가 Image patch들을 보고 [M] 부분의 Visual token을 예측하도록 학습시킨다.
차이점: 기존엔 [M]부분의 실제 픽셀값을 예측하도록 했다면 BEIT에서는 visual token값을 예측하도록 한다.
2. Methods
input image 가 주어졌을 때 어떤일이 일어나는지 구체적으로 알아보자.
2.1.1 Image Patch
의 shape이 라 하면 이걸 N개의 patch로 쪼개
각 Patch 의 shape이 가 되도록 한다. 그러면 패치의 갯수 가 될 것이다.
이후 패치들을 flatten해 BEIT의 입력으로 사용된다.
구체적으로 논문에서 원본 이미지 224x224짜리를 각 패치 크기가 16x16이 되도록 총 14x14개의 패치로 쪼개 실험했다.
2.1.2 Visual Token
discrete Variational Autoencoder(dVAE)의 tokenizer를 사용했다.
픽셀 값 ; 들이 주어졌을 때 토큰 값 ; 를 계산하는 tokenizer ; 과, 토큰 값 ; 들을 보고 다시 원본 픽셀 값 ; 를 복원하는 decoder ; 로 이루어져있다.
따라서 학습 목표는 복원하는 decoder의 정확도를 높이는
최대화 이다.
근데 visual token값들이 discrete하기 때문에 미분 불가능이라 학습할 때 Gumbel-softmax relaxation(?)을 활용했다.
또 학습시킬때 는 uniform prior로 고정시켜놓고 했다.
image patch를 쪼갤때 처럼, visual token도 14x14개의 값을 가지도록 했고, vocabulary size는 8192로 설정, q는 <DALL-E: Zero-Shot Text-to-Image Generation> 논문의 것을 그대로 가져와 사용했다.
2.2 Backbone Network: Image Transformer
ViT말고, standard Transformer구조를 활용했다.
Image patches 를 linearly project하여 로 만들고,
앞에 Special token [s]를 붙이고,
Position Embedding을 붙여 transformer의 input으로 사용했다.
즉, input vectors 이다.
이후 L layer의 transformer block들을 거쳐 최종 L번째 layer의 output vector가 각 image patch들의 encoded representations이다.
2.3 Pre-Training BEIT: Masked Image Modeling
학습 목표는 모든 이미지 패치에서 visual token을 맞추도록 하는게 아니라 masked patch에서만 softmax를 한 결과를 가지고 계산했다.
이미지 패치들 중 mask할 때 단순 무작위로 하는게 아니라 알고리즘을 활용하여 정해진 범위내에서 0.4비율 이상 mask되도록 하였다.
