Multi-modal
1.[논문 리뷰] Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks (BEiT-3)
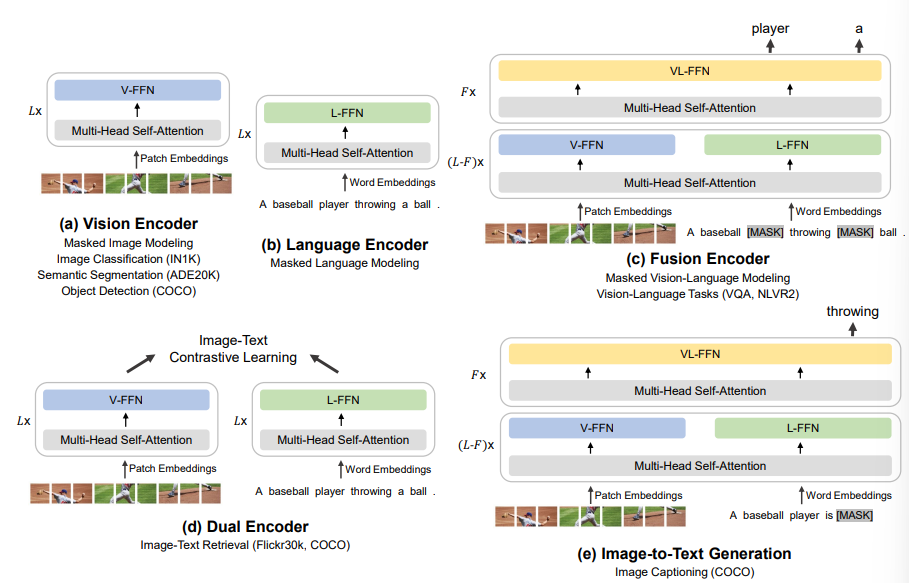
Visual Question Answering(VQA) Task에 관심이 생겨 현재 SOTA 모델인 BEiT-3을 찾아보았다.https://arxiv.org/abs/2208.10442BEiT v1, v2도 읽어볼 예정크게 3가지에 집중할 예정이다.1\. Bac
2.[논문 리뷰] BEIT: BERT Pretraining of Image Transformers
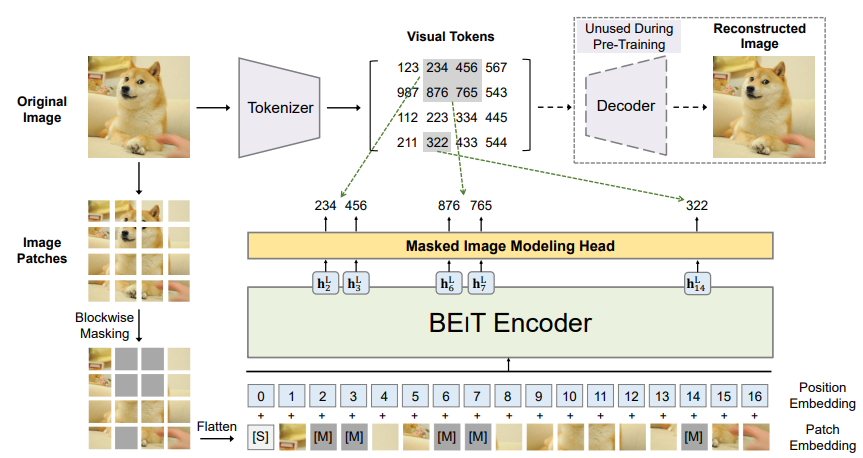
https://arxiv.org/abs/2106.08254Bidirectional Encoder representation from Image Transformers(BEIT)이미지를 image patches , visual tokens 이 두가지로 봐서 tr
3.[논문 리뷰] Visual Question Answering: A survey on Techniques and Common Trends in Recent Literature

https://arxiv.org/abs/2305.11033VQA 분야 23년 6월에 나온 survey논문이다.VQA가 뭐하는건지, 어떤 모델들이 있는지, 등 알아보자VQA는 아무래도 multi-modal task 이기에 다른 modality를 합친다는데에서 어
4.[논문 리뷰] BEIT v2: Masked Image Modeling with Vector-Quantized Visual Tokenizers
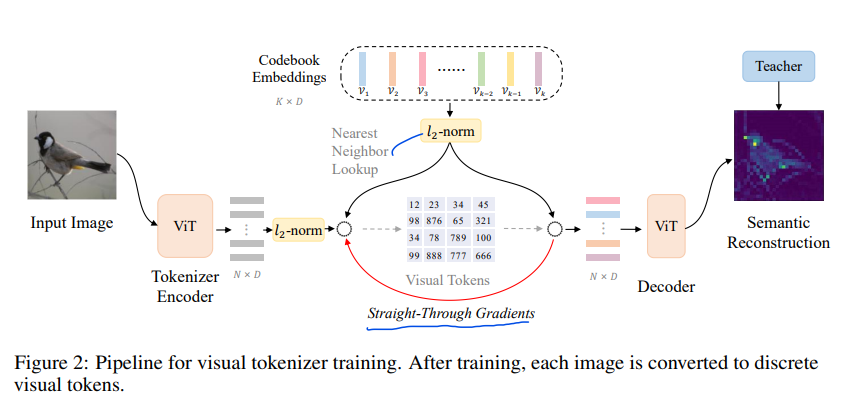
BEIT v3, v1을 읽고 읽었지만, 3개 중 가장 어려운 논문인거 같다.v1 리뷰 / v3 리뷰Knowledge Distillation이라는 처음보는 개념도 등장하는데, 일단 이 논문부터 하나씩 봐보자https://arxiv.org/abs/2208.0636
5.[논문 리뷰] CLIP
clip 논문리뷰
6.[논문 리뷰] e-CLIP: Large-Scale Vision-Language Representation Learning in E-commerce

네이버에서 22년에 출간한 vision-llm multi-modal 관련 논문이다. 네이버 스마트스토어를 통해 얻은 데이터셋을 잘 활용할 수 있는 방법을 담은 논문이다.논문 전체를 하나하나 뜯어보진 않은 상태이다.E-commerce에 활용하기 위한 vision-lang
7.[논문 리뷰] Video-Text Representation Learning via Differentiable Weak Temporal Alignment

nlp-cv, Multi-modal, representation learning, contrastive learning, 고려대 김현우 교수님