[논문 리뷰] Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks (BEiT-3)
Multi-modal
Visual Question Answering(VQA) Task에 관심이 생겨 현재 SOTA 모델인 BEiT-3을 찾아보았다.
BEiT v1, v2도 읽어볼 예정
Abstract
크게 3가지에 집중할 예정이다.
1. Backbone architecture
2. Pretraining task
3. Model scaling up
이 3가지를 하기 위해서 Multiway Transformer 논문에서 제시한다.
이미지를 하나의 언어로 보고 ('Imglish'), image-text pair에 마스크를 씌우는 학습방법을 활용하였다.
이렇게 했더니, 여러 데이터셋에서 Vision-Language multi-modal task 뿐만 아니라, Vision 단일 task에서도 좋은 성능을 보였다.
1. Introduction: The Big Convergence
Abstract에서 제시한 3가지를 어떻게 할 것이냐
1.1 Backbone architecture
Vision-Language 모델링에 있어 다양한 방법들이 존재한다.
- Dual-Encoder: Image-text retrieval task
- Encoder-Decoder: generation task
- Fusion-encoder: image-text encoding
이런 모델들 대부분은 특정 task를 하기 위한 변형을 끝단에 붙여줘야 한다. 게다가 여러 modality에 parameter들이 효과적으로 공유되지 않는데,
Multiway Transformer로 점들을 개선한다.
1.2 Pretraining Task
Pretraining 할 때 task마다 다른 기법으로 학습시키는데, 이건 scaling 하기에 안좋고, 비효율적이다.
General-purpose multi-modal 모델 학습으로 Mask-then-predict 이거 하나만 쓰자.
이미지도 text처럼 취급한다 했으니(Imglish) modality는 다르지만 두 개의 문장이 들어간 것처럼 학습시켜줄 것이다.
1.3 Model Scaling up
모델 크기를 키우고, 데이터 크기를 키우는게 성능을 높이는데 보통 좋다.
이 논문에서는 private한 데이터를 쓰지 않고, 공개된 데이터만 사용해도 SOTA보다 성능이 좋음을 보였다.
2. BEiT-3: A General-Purpose Multimodal Foundation Model
2.1 Backbone Network: Multiway Transformers
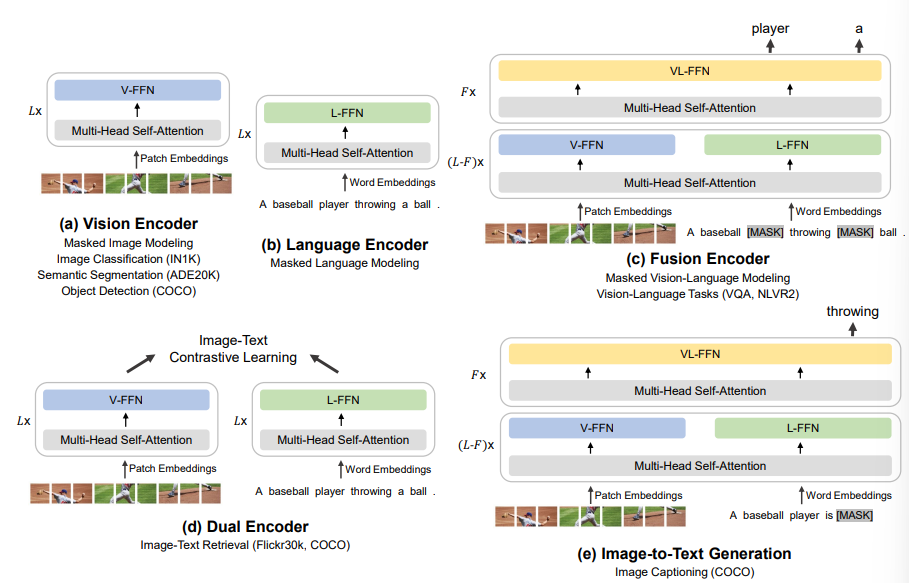
그림에 있는 것 처럼, Multiway Transformer 는 각 modality 마다 shared self-attention module , feed-forward network(FFN)으로 구성되어 있다.
(a),(b) 를 보면 Self-attention module 위에 각 modality에 해당하는 FFN 이 올라가 있고,
(c)는 image와 text가 shared self-attention module, FFN 을 거쳐 나온 결과를 다시 self-attention, FFN 에 넣는데,
이렇게 하면 처음 shared self-attention 에서 다른 modality간의 alignment를 학습하는데 도움이 된다.
Vision task만, text만, multi-modal용이든 다 똑같은 구조로 이루어져 있어서 각종 downstream task에 활용하기에 좋다.
2.2 Pretraining Task: Masked Data Modeling
앞서 BEiT를 학습시킬 때 mask-then-predict 만 사용한다고 언급했다.
이렇게 하면 representation 뿐만 아니라 다른 modality간 alignment를 학습하는데에도 도움이 된다.
구체적으로, Text는 SentencePiece tokenizer 를 이용해서 토큰화 했고, Image는 BEiT v2에서 언급된 tokenizer를 이용했다. (찾아보자)
Text만 학습시킬땐 15%, Image-text pair로 학습할 땐 50%를 mask했다. 이미지는 40% image patch들을 BEiT논문에 등장하는 방식으로 block-wise masking 했다.(이것도 찾아보자)
각 Task마다 학습 방식이 달라지는 다른 Vision-language 모델들과의 차별점으로 똑같은 방식(mask-then-predict)만 사용해서 pretrain 시켰고, Contrastive-based model(CLIP, CoCa 등)들 보다 더 작은 batch size로 학습시킬 수 있었다. -> GPU memory에 있어 좋다.
2.3 Scaling Up: BEiT-3 Pretraining
위의 그림에서 각 부분별 parameter수를 제시
데이터 크기 제시
학습때 사용한 hyperparameter, augmentation종류 제시
3. Experiments on Vision and Vision-Language Tasks
Visual Question Answering(VQA)
VQA v2.0 dataset 으로 finetuning해서 실험했다.
VQA를 일종의 Classification task처럼 해석하여, Trainset에 가장 자주 등장한 3129개의 대답 후보들 중 하나를 예측하도록 했다.
위 그림의 (c) Fusion Encoder 모양을 이용했고, Input으로 주어지는 Question에서 뽑은 embedding과, Image에서 뽑은 embedding을 concat하여 Multiway Transfomer 구조에 넣어 주었다.
이후 나온 output을 classifier layer에 넣어 최종 답을 예측하도록 하였다.
총정리
- 다른 VQA논문을 더 읽어봐야 알겠지만, 이걸 classification 문제로 풀지 않고 다른 방법이 있는지 궁금하다.
- 이 논문에 등장한 BEiT v1, v2의 image tokenizing 방법과 masking 방법을 반드시 알아보자
- 현재 VQA v2.0 데이터셋 기준 SOTA 모델이던데, 다른 논문에선 어떤 모델구조를 띄는지 2등 3등도 알아보자.
- Fusion Encoder에서 Image embedding, text embedding을 어떻게 만져서 모델에 넣었는지 코드를 한번 뜯어보자
