DCVC를 시작으로 Microsoft asia 팀에서 해마다 한 두편씩 neural video compression 관련 논문이 나온다.
코드: https://github.com/microsoft/DCVC/tree/main/DCVC-family
아래 표에 내가 생각한 각 논문에서 중요한 포인트를 적어두었다.
| 이름 | 시기 | 특징 |
|---|---|---|
| DCVC | NeurIPS 2021 | Residual 코딩 방식에서 conditional 코딩으로 전환 |
| DCVC-TCM | TMM 2022 | Context 생성 모듈 개선 |
| DCVC-HEM | ACM MM 2022 | Variable bitrate 지원 |
| DCVC-DC | CVPR 2023 | 새로운 entropy model 제안 |
| DCVC-FM | CVPR 2024 | 더 세밀한 qs 조절 지원 |
| DCVC-RT | CVPR 2025 | 모션 모듈 제거 및 경량화 |
RT는 약간 특성이 달라서 이번엔 다루지 않을 예정이다.
그 외 논문들을 하나씩 보자면,
DCVC
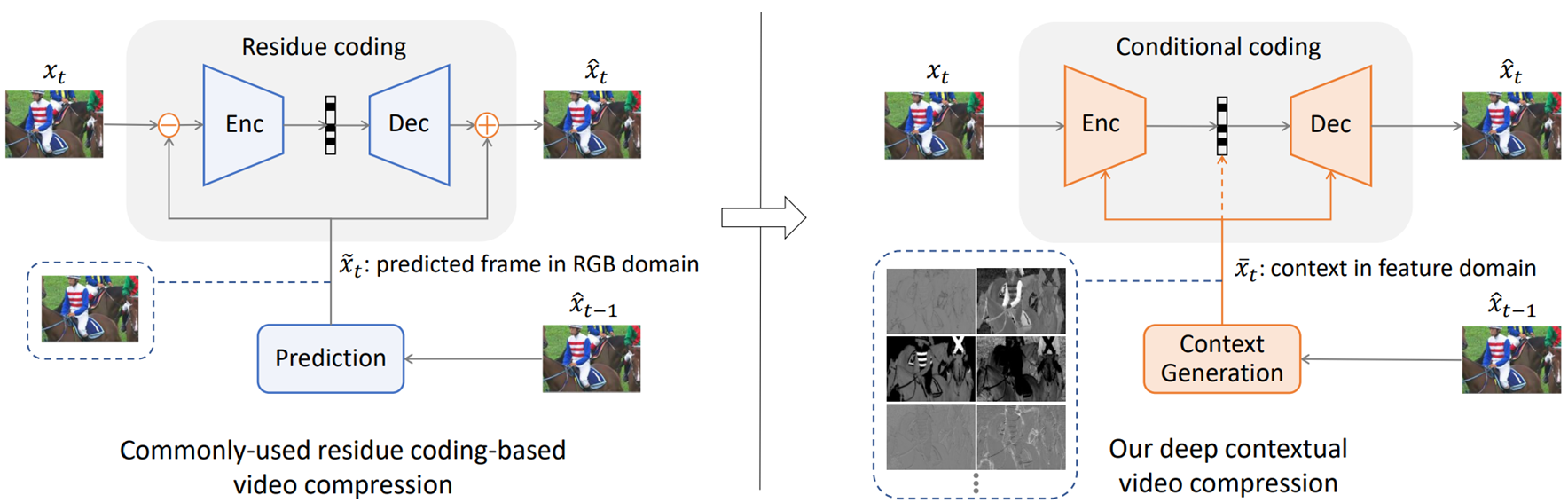
왼쪽은 DCVC 전까지 일반적이던 residual 코딩 방식이다. 이미 코딩해둔 정보들을 바탕으로 현재 프레임을 예측하고 () 그 차이만을 ()를 코딩한다.
DCVC에서 제안한 건 아니지만, 오른쪽의 conditional 코딩 방식은 이미 코딩해둔 정보들을 인코딩, 디코딩할 때 context로 활용해서 압축할 latent를 뽑는 방식이다.
DCVC-TCM
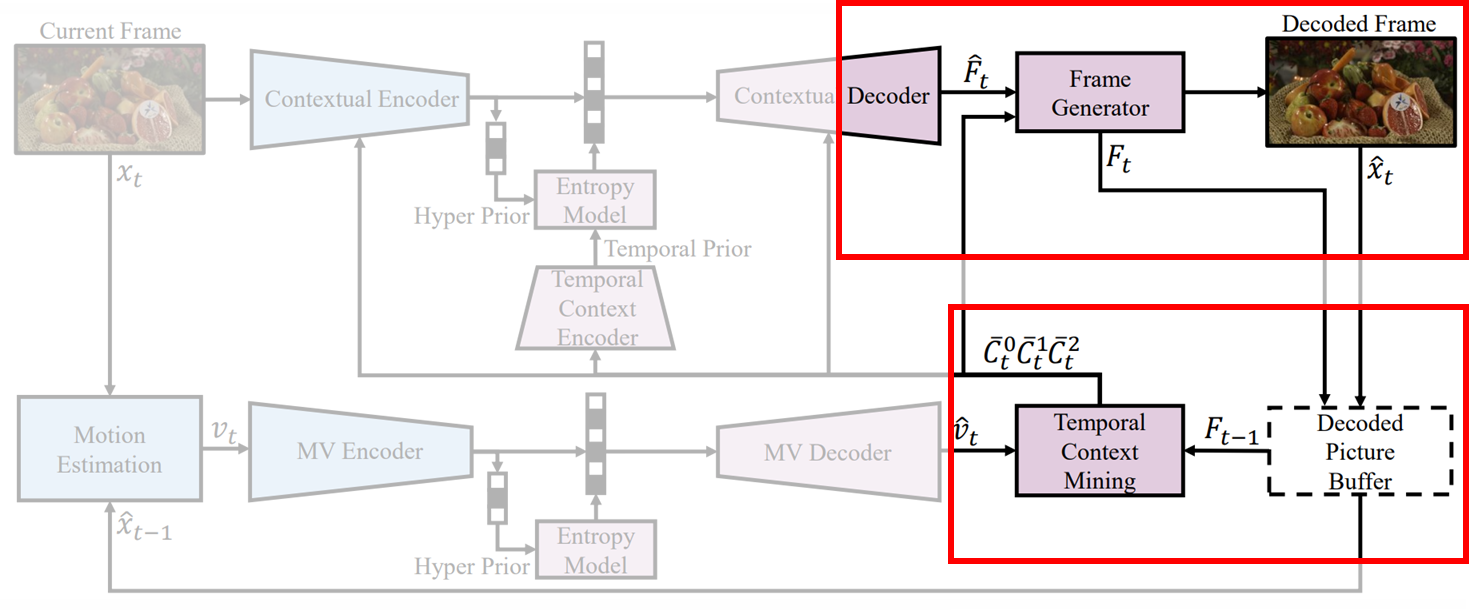
DCVC에서 context를 뽑을 때 복원한 이전 영상을 활용했었다.
하지만, 3채널 짜리 복원 영상은 feature 단계보다 정보가 많이 줄어든 상태이기 때문에, RGB영상을 뽑기 전 feature ()도 같이 저장해 뒀다가, 이걸로 context를 뽑는 방식으로 바꿨다.
DCVC-HEM
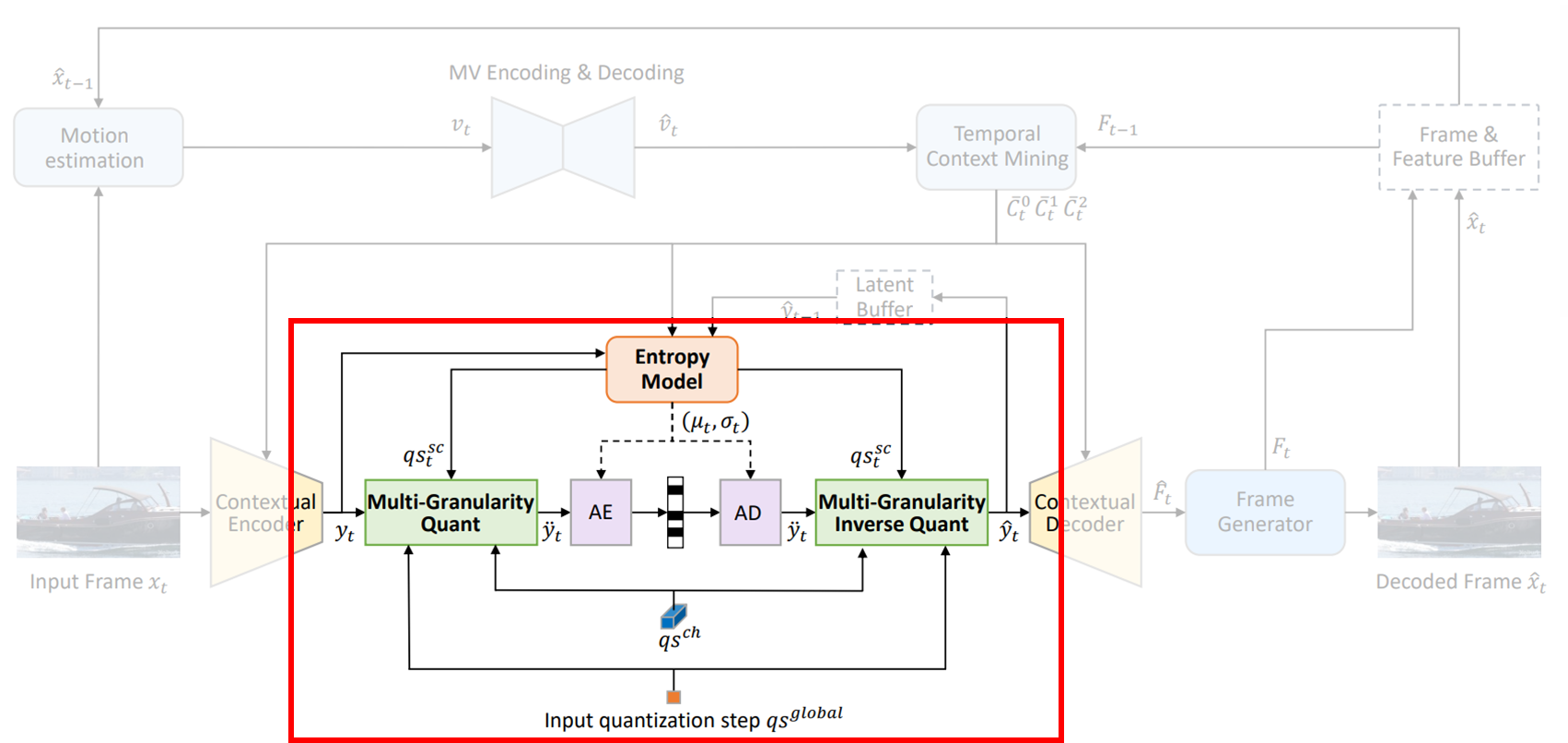
다른 모듈 구성이나 이런건 동일한데, 단일 모델에서 여러 qs를 지원할 수 있도록 연산 중간중간에 learnable vector를 곱하는 연산을 추가해줬다.
DCVC-DC
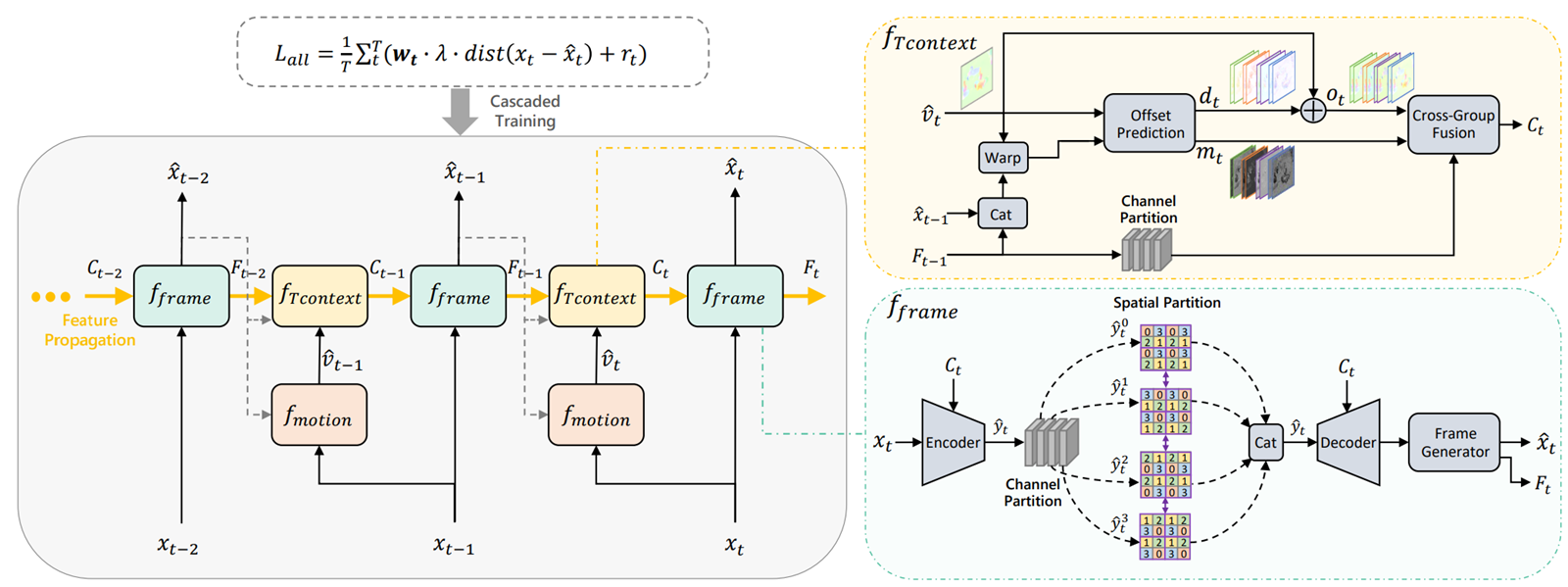
크게 두개 모듈이 추가되었다.
1) 모션 예측시 offset을 여러개 같이 예측하는 모듈
2) Quadtree entropy model
1번은 크게 아이디어적인 것은 없어서 패스
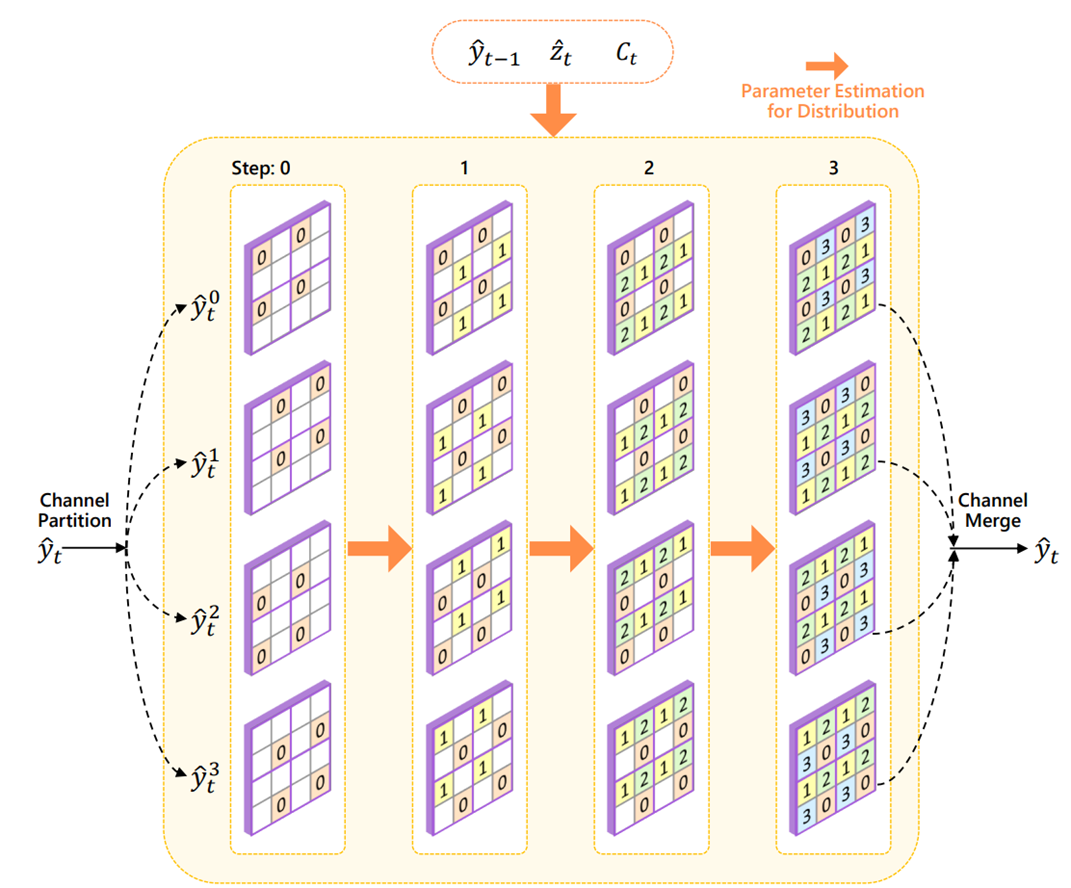
2번의 quadtree entropy model 그림이다. Autoregressive 방식 중 하나로 볼 수 있는데, 비교적 성능도 꽤 좋아지면서 연산 복잡도는 적당히 높아진 밸런스 있는 모델인 것 같다.
DCVC-FM
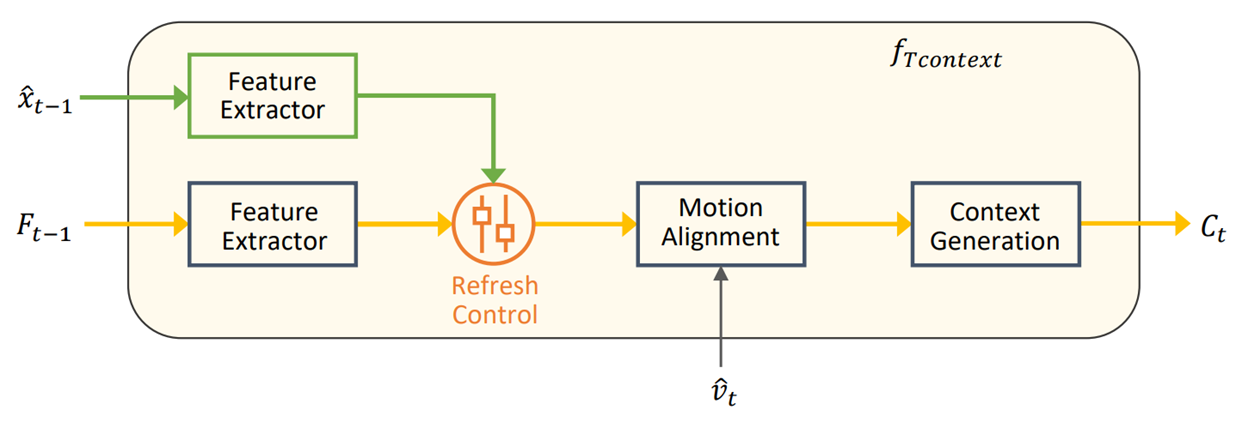
TCM 이후부터 DC까지는 context를 만들 때 feature만을 사용했었다. 이게 언제 문제가 되냐면, I 프레임으로부터 점점 멀어질 수록 (GOP가 커질 수록) 문제가 발생한다.
P 프레임 코딩을 하면서 에러가 점점 누적되는건데, FM에서는 이를 해결하기 위해 context를 생성할 때 주기적으로 feature가 아닌 복원 영상을 활용한다.
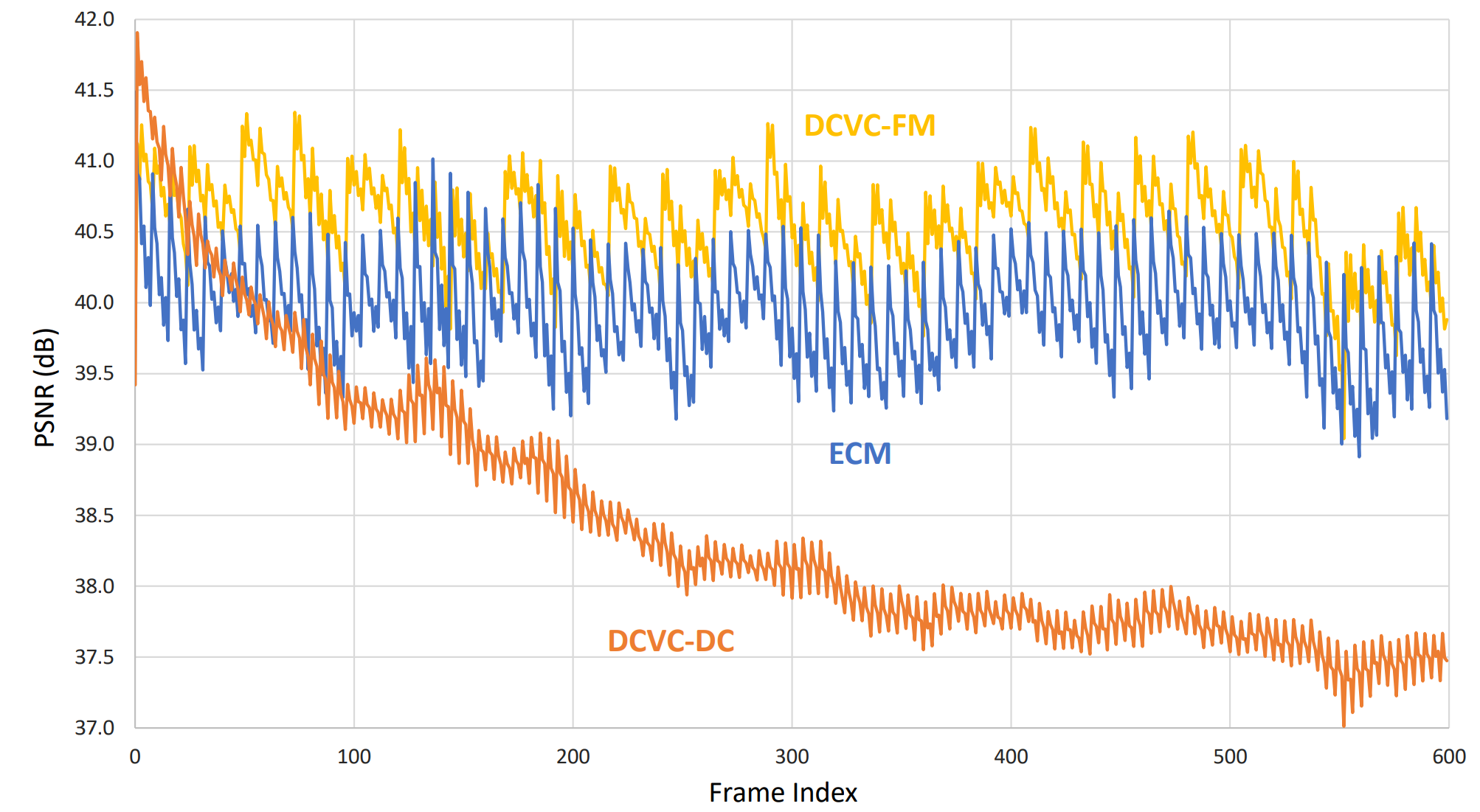
그 결과, I 프레임 하나로 동영상 전체를 코딩하더라도 비교적 안정적인 모습을 보인다. (ECM은 딥러닝이 아닌 전통적인 코덱 방식)
정리
다음엔 어떤식으로 Neural video compression을 발전시킬지 기대가 된다.
다 좋은데 학습 코드가 없어서 재현이 어렵다. 그래서 점점 이 연구팀이랑 다른 팀간에 격차가 커지는 것 같다..
