[논문 리뷰] Learned Rate Control for Frame-Level Adaptive Neural Video Compression via Dynamic Neural Network (ECCV 24)
Compression
논문 링크: https://arxiv.org/abs/2508.20709
딥러닝 기반의 video compression 논문이다.
문제 제기
고전 코덱들은 비트레이트(bit rate)를 세세하게 조절해서 원하는 환경에 맞게 압축이 가능했다.
그러나, 딥러닝 기반의 비디오 압축 기법들은
고정된 값을 사용하여 Rate-Distortion 손실함수를 최소화 하기 때문에, 세세한 조절이 안된다.
기존 기법
딥러닝 기반 비디오 압축에서 세밀한 비트 조절을 위한 방식은 두가지로 구분 가능하다.
1. Multi-granularity quantization
DCVC-DC가 대표적인 예시인데, 피쳐단에서 qs 몇개에 대한 learnable vector를 곱하는 것으로 값을 크게 변화시키는게 아니라 scaling만 한다. -> quantization step 변화와 비슷함
2. Feature modulating
1과 다르게 실제 값이 바뀌게끔 하는 scaling 이상의 연산이 들어간다.
저자들이 제기한 문제
1번 같은 경우는 단순 선형 변환이라 당연히 네트워크를 따로 두는 것보다 제한적이라는 것, 그리고
1, 2번 모두 bit-rate 예측과정이 없기 때문에 정확하게 조절이 어렵다는 점이다.
제안 기법
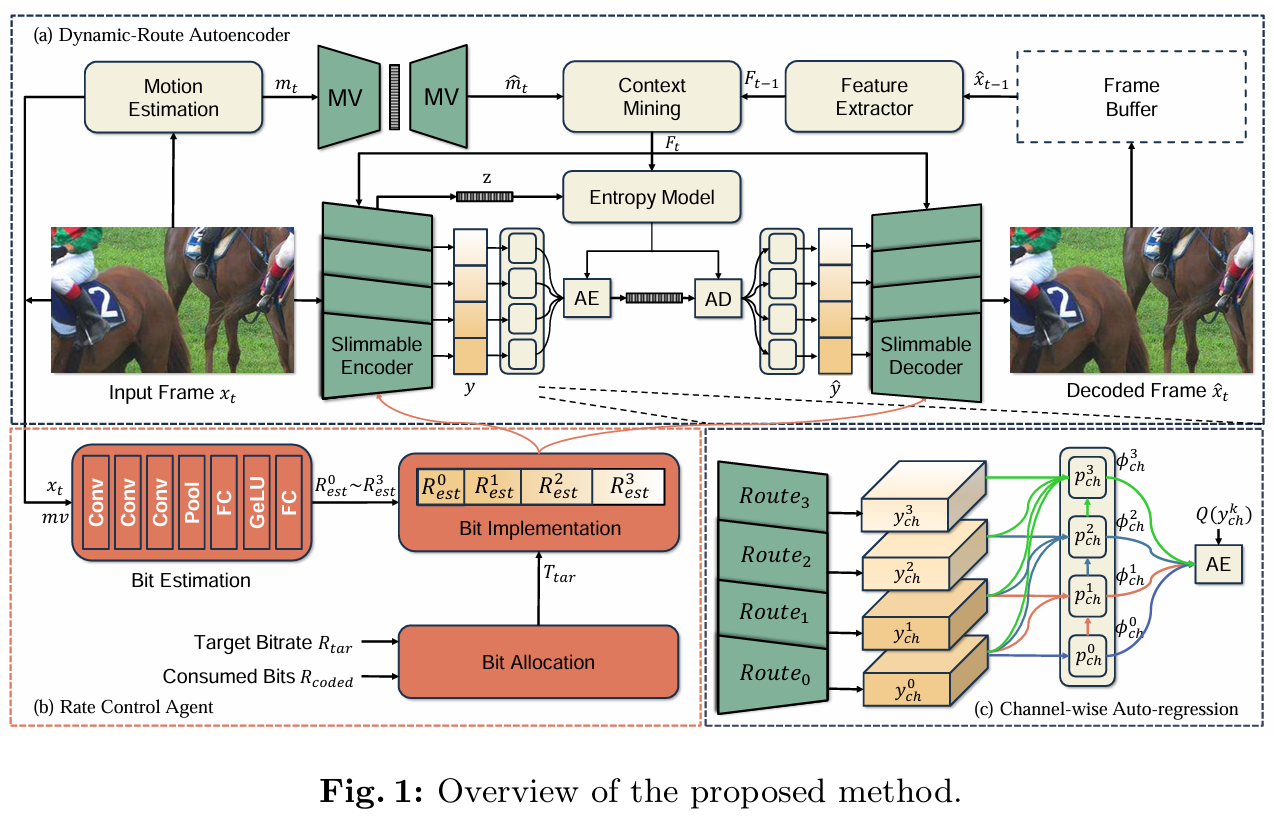
요약
세가지를 제안한다.
1. Dynamic-Route Autoencoder (DRA)
: Slimmable autoencoder를 사용해서 bit-rate에 맞게 전체 네트워크의 일부(Route)만으로도 코딩이 가능하다.
2. Rate Control Agent (RCA)
: 원하는 bit-rate에 따라 route를 결정해준다.
3. Joint-Routes Optimization Strategy
: 네트워크 일부만 쓰고, 공유하고 이런 스타일은 학습이 어렵기 때문에 학습 과정을 고안하였다.
1. Dynamic-Route Autoencoder (DRA)
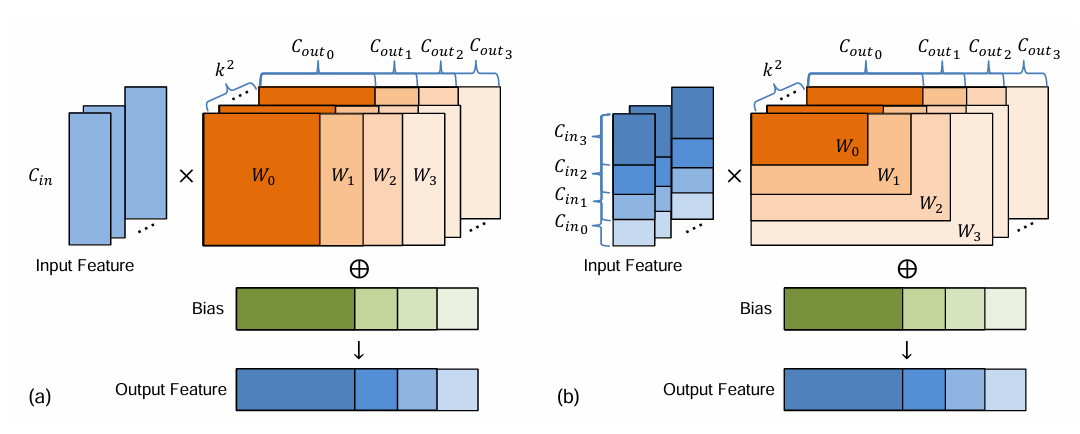
간단하게 말하면 파라미터 일부만 사용해서 출력되는 절대적인 양을 줄여버린다.
그림은 Slimmable convolution 내용이다.
(a) 출력이 잘리는 경우
(b) 입력이 잘려 있는 경우
이고, 자르는 단계가 0~3 단계라고 하면
0단계는 만, 1단계는 을 사용하는 이런식이다.
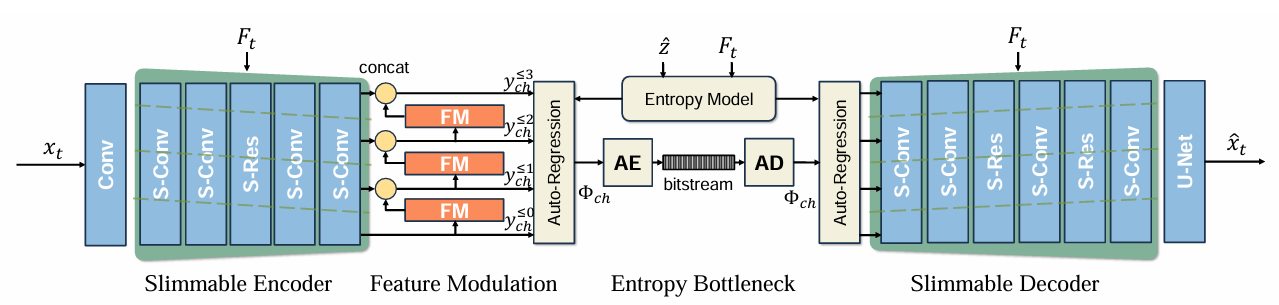
다른 autoregressive 모델과 똑같긴 한데, 엔트로피 모듈에서의 구현은 위 그림과 같다.
이전 route 출력 모두를 현재 route 를 예측하는데 사용한다.
는 확률 분포 예측기, Q는 quantization, FM은 feature modulation 네트워크에 해당한다.
그러면, 위 식은 k번째 route의 확률분포 를 예측하기 위해, 이전 route 출력 와 hyperprior 를 사용한다는 식이 된다.
2. Rate Control Agent (RCA)
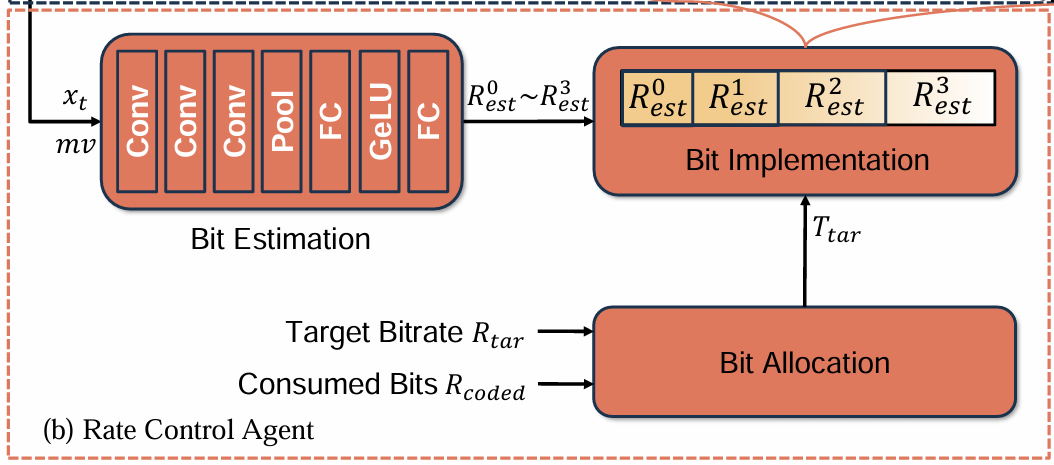
두가지 연산이 이루어진다.
1. 입력 영상 와 모션 벡터 를 받아서 각 route별 bit-rate를 예측한다. ( ~ )
2. 목표 bit-rate 와 이미 사용한 비트수 를 바탕으로 몇번째 route까지 쓸건지 결정한다.
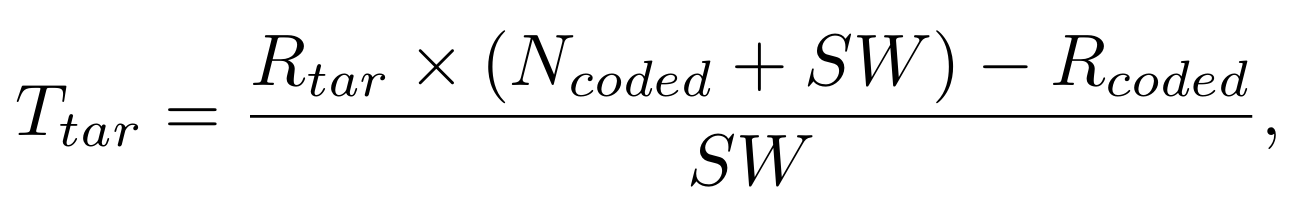
(원 논문에서 notation을 비트레이트, 총 비트수를 같은 R로 써서 헷갈린다.)
예를 들어,
이미 코딩한 프레임 수
참고할 프레임 수
이라 하면,
현재 프레임 압축시 목표 bit-rate 가 돼서
목표 비트수 보다 약간 더 써도 된다 는걸 유도할 수 있다.
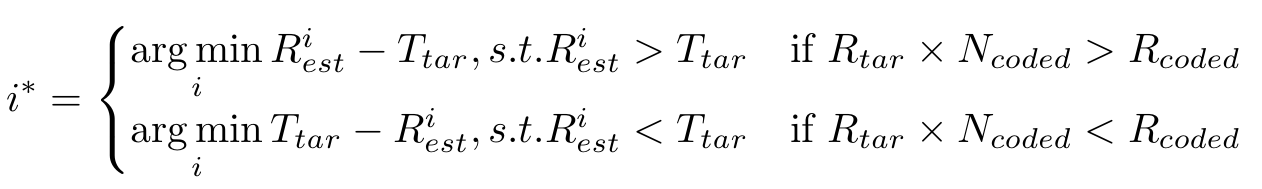
즉, 만약 비트가 좀 여유있다면 ()
보다 큰 들 중에서 젤 가까운 를 route로 선택하는 방식이다.
3. Joint-Routes Optimization Strategy
일반적으로 variable-rate 코덱을 학습하는 방식은 다음과 같다.

모든 route (또는 qs)에 대해 Rate, Distortion loss를 구하고 다 합쳐서 업데이트하는데 사용한다.
Variable-rate를 위해 값을 튜닝한다.
(Line 4, 5에서 만 바꾸고 R, D는 그대로인 것처럼 써놨는데, R, D도 각 qs별로 새로 측정한다.)
qs가 낮을수록 학습이 빠르기 때문에, 높은 qs의 (그림에선 ) 부터 하나씩 고정하면서 학습을 진행한다.
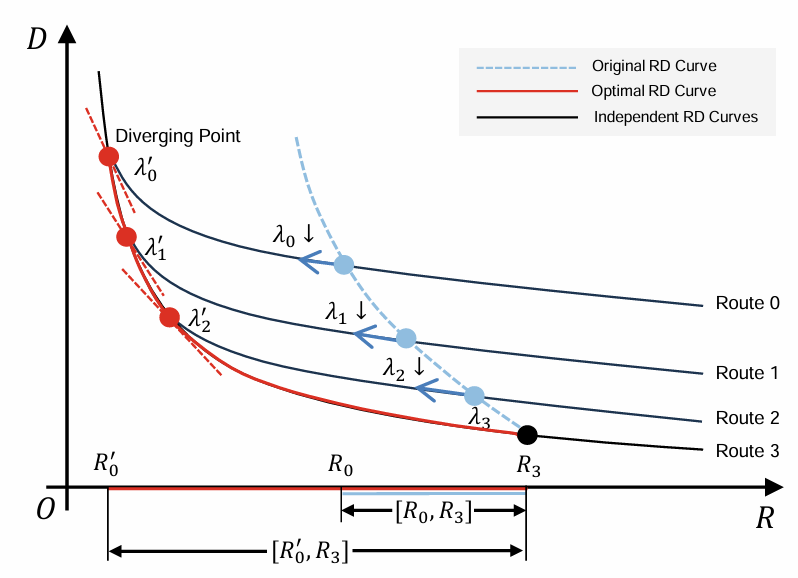
Algorithm 1을 발전시켜서, 값들을 같이 업데이트 하는 방식을 제안한다.

복잡한데, Algorithm 1 기준으로
rate-distortion 변화량 (위 그래프와 같이 음수값을 가짐)이 하나 큰 qs에서의 변화량() 보다 작으면서(더 가파르면서)를 때까지 를 곱해 들을 줄여나간다.
즉, 완만했던 파란색 그래프에서 qs가 작아질 수록 점점 급해지는 빨간색 그래프로 변해 가면서 bit-rate 범위를 늘린다.
여기서도 높은 qs의 값부터 하나씩 고정시켜 나간다.
실험
DCVC-DC를 인용은 했는데, 같이 성능을 비교 안한걸로 봐서 잘 안나와서 뺀 것으로 의심이 된다..
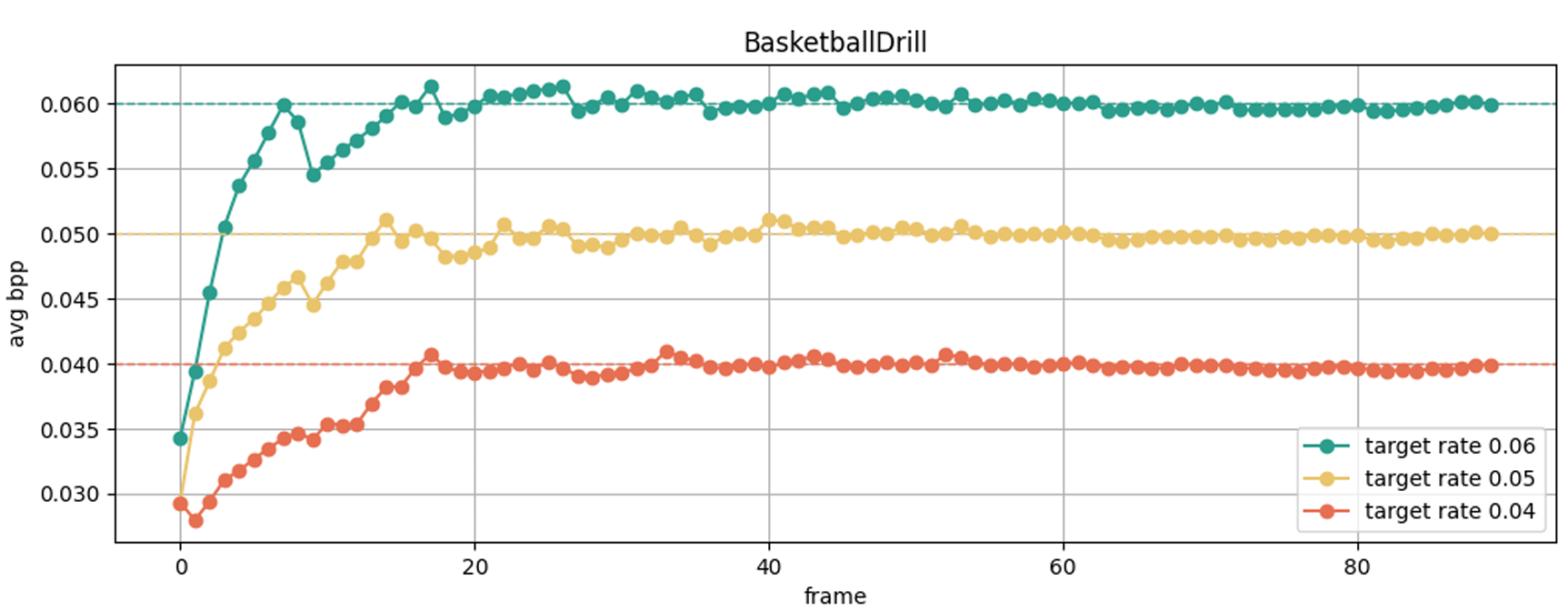
그래도 이렇게 원하는 bpp에 딱맞게 나오는 것은 신기하다.
주관적인 생각
코드상에 모션 코딩 관련해선 엔 이런 처리를 안하고 모든 qs에서 똑같은 처리를 하는것으로 되어 있던데 왜 모션엔 따로 뭔갈 안했는지 궁금하다.
학습 난이도가 꽤 될 것 같은데, 구체적으로 어떻게 했을지 궁금하다.
