[논문 리뷰] Entroformer: A Transformer-based Entropy model for Learned Image Compression (ICLR 2022)
Compression
목록 보기
4/8
이 논문 역시 transformer 구조를 활용한 entropy model이다.
Overview
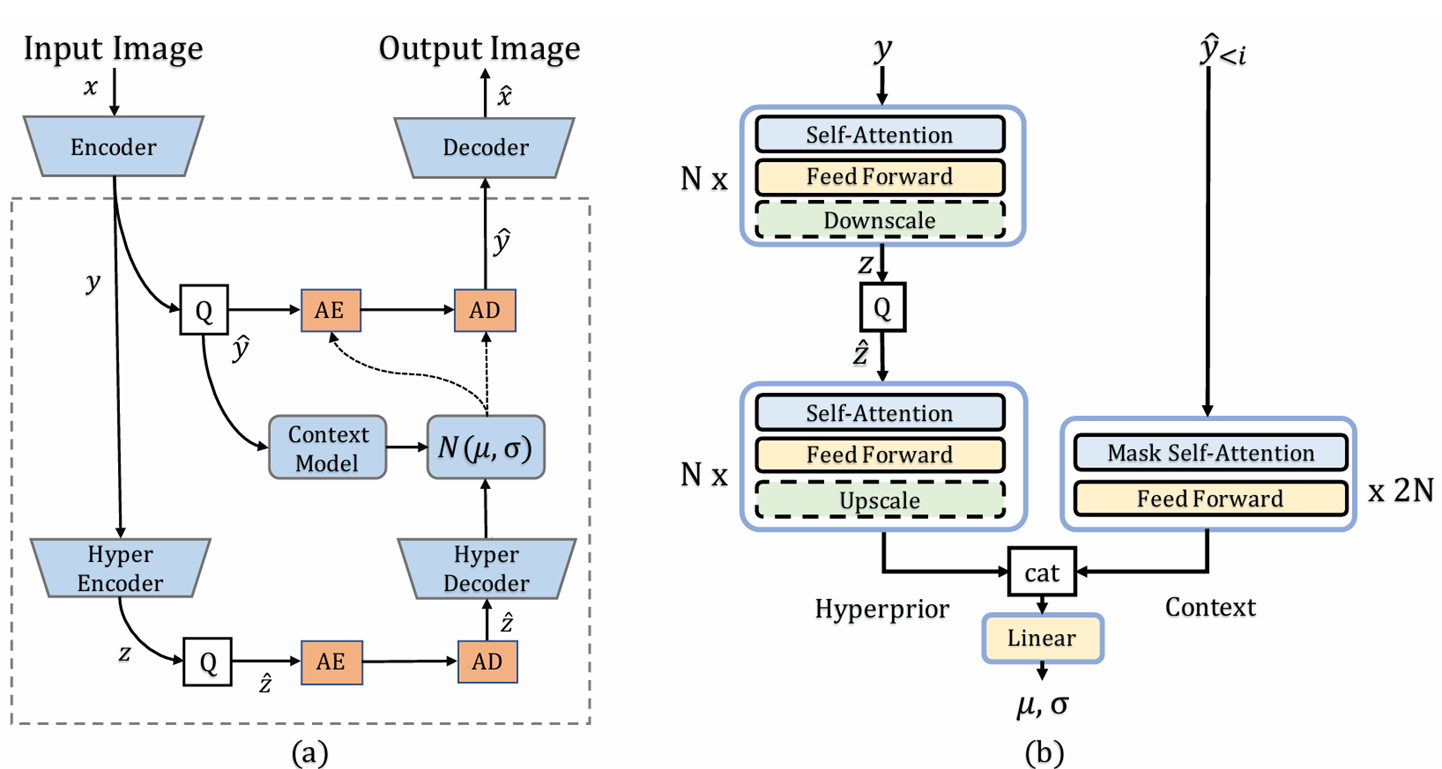
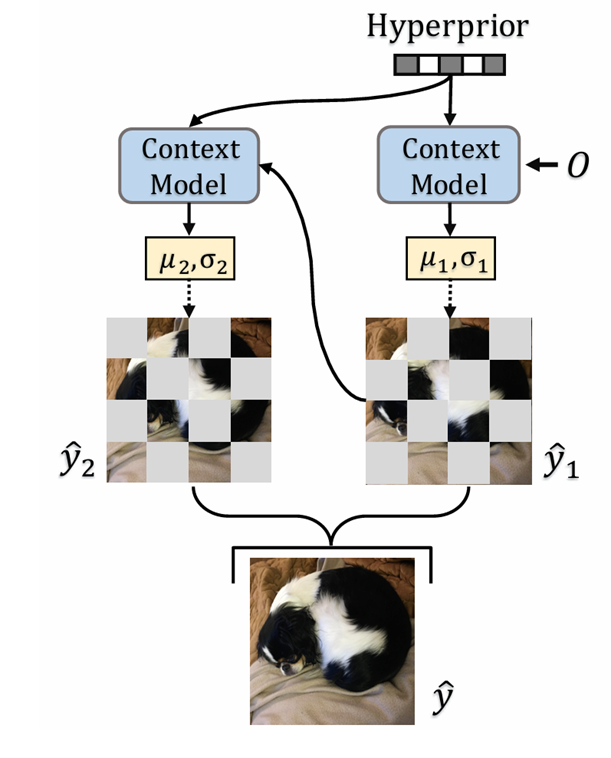
구조 자체는 hyperprior 기반의 autoregressive entropy model 과 동일하게, 인코더로 얻은 latent y 중 이미 전송한 과 hyper encoder로 얻은 z, 으로 확률분포를 예측한다.
뒤에서 말하겠지만 autoregressive 방식은 아니고 y를 2단계로만 나누어서 코딩한다.
총 3가지 contribution으로 정리할 수 있다.
Diamond relative positional encoding
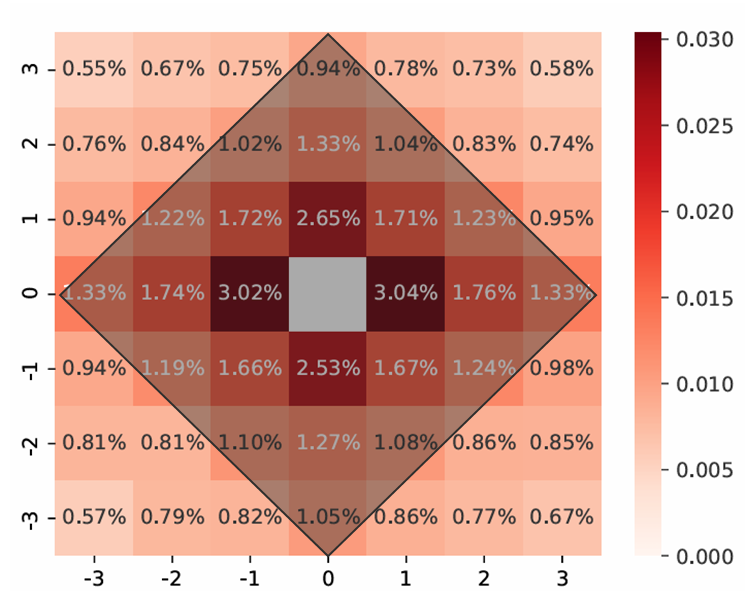
다이아몬드 형태의 positional encoding을 제안한다. 위 그림은 저자들이 한칸씩 직접 마스킹해가며 코딩을 진행하였을 때 떨어지는 성능이라고 한다.
가운데에 가까울수록 성능 하락 폭이 커지는 것을 보고 다이아몬드 형태의 positional encoding을 사용했다.
위 그림 같은 경우는 h=3으로 중간에서 3칸 밖에 있는 부분은 같은 벡터로 인코딩한다. 안쪽은 learnable parameter.
Top-k self attention
이건 특별할 거 없이 어텐션 결과에서 모든 value를 활용하는게 아니라 어텐션 스코어가 높은 k개만 사용해서 상관 없는 정보를 제외하겠다는 의도이다.
Parallel bidirectional context model
빠른 병렬처리를 위해서 checkerboard 형태로 공간상에서 2조각을 내어 하나씩 코딩한다.