[논문 리뷰] Learned Image Compression with Hierarchical Progressive Context Modeling (ICCV 2025)
Compression

논문 링크: https://arxiv.org/abs/2507.19125
코드 링크: https://github.com/lyq133/LIC-HPCM/tree/master
DCVC-TCM을 쓴 Microsoft 팀에 계시던 저자분 두분이 학교에서 지도하신 논문인듯 하다.
딥러닝 기반의 이미지 압축 논문이다. 구조는 크게 Encoder, Decoder, Entropy module 3개로 구분이 가능한데, 이 논문은 Entropy module 부분이 메인이다.
저자들이 문제삼은 것은, Entropy module이 CNN 기반으로 Local redundancy를 활용하는 것에서 Transformer를 활용하여 global 특성도 활용하게 발전하고 있지만, 여전히 global redundancy 활용이 부족하다는 점이다.
제안한 것은 다음 두가지이다.
1. Hierarchical coding schedule
2. Progressive context fusion
별개로 다른 논문의 아이디어를 가져와 활용한 몇가지까지 있다.
최근 대부분 압축 논문에서 활용하고 있는 Autoregressive entropy module 기반이다.
Overview
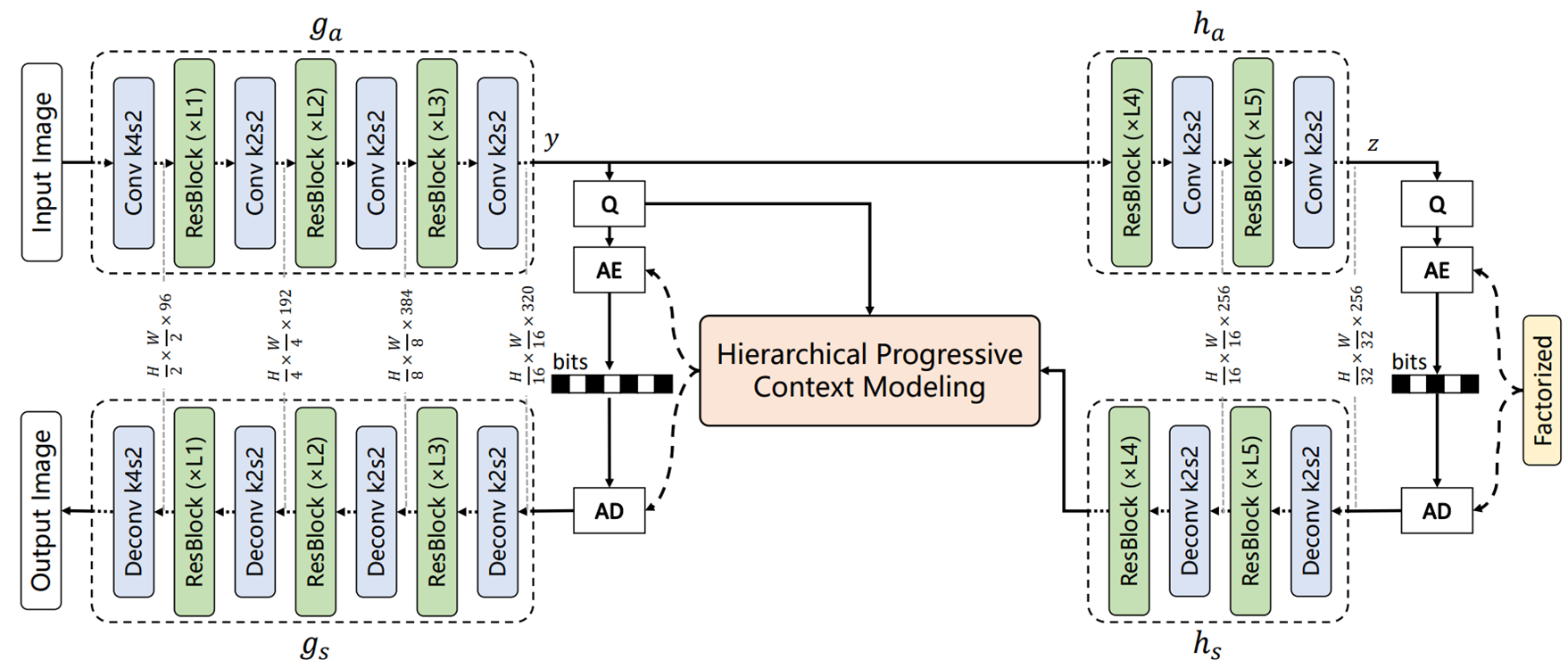
일반적인 이미지 압축 구조와 같이
1) 입력 영상이 인코더를 통과하여 latent y
2) hyperprior 인코더로 z
3) entropy module로 y의 확률 분포 예측
4) 디코더로 영상 복원
하는 구조이다. 이 논문에서는 3번이 중요하다.
1. Hierarchical coding schedule
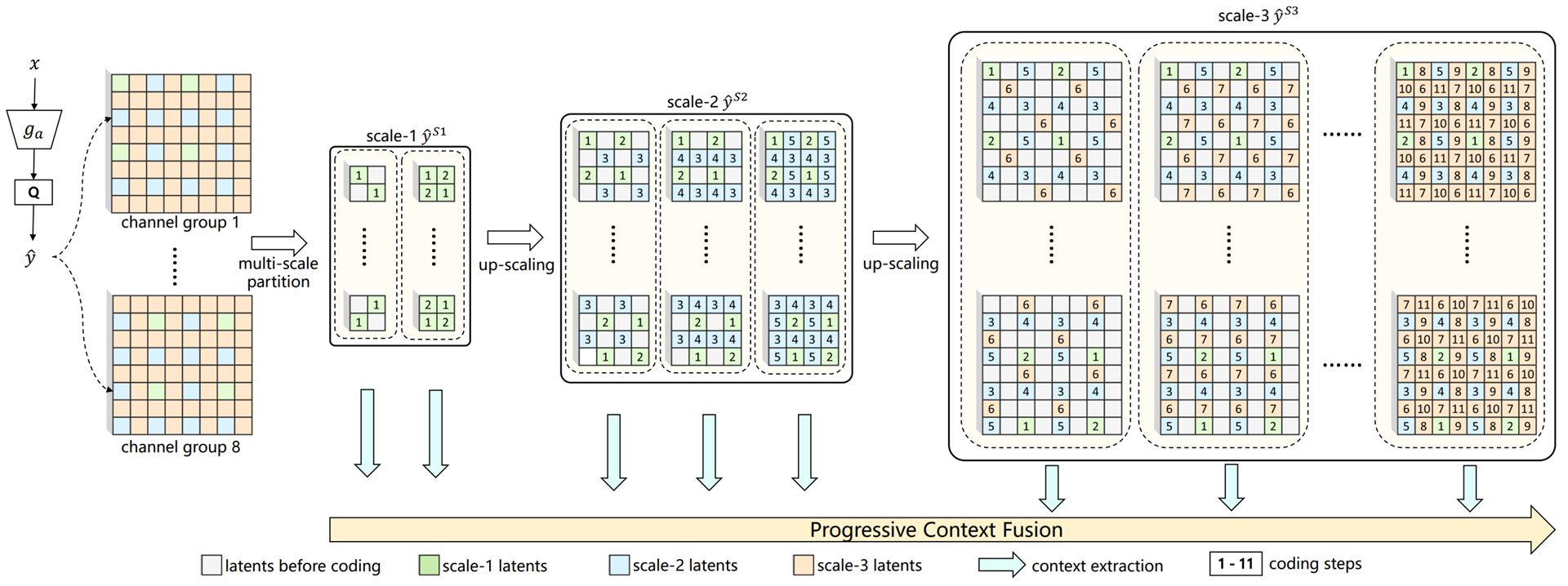
Autoregressive 구조로 y를 잘게 쪼개서 순차적으로 코딩을 하는데, 쪼개는 방식에 대한 제안이다.
그림이 조금 복잡해 보일 수 있으나, DCVC-DC 논문을 본 사람이라면 익숙할 그림이다. DCVC-DC의 quadtree와 매우 유사한 방식을 제안한다.
구체적으론,
1) 채널방향으로 균등하게 8조각으로 자른다.
2) y를 1/4 크기로 샘플링하여 (각 sub-latent마다 다른 위치) 코딩을 진행한다. (stage 1, 2)
3) y를 1/2 크기로 샘플링하여 코딩을 진행한다. (stage 3, 4, 5)
4) 원래 y 크기에서 나머지 부분 코딩을 진행한다. (stage 6, 7, 8, 9, 10, 11)
그림에서 각 칸에 적힌 숫자가 autoregressive 순서를 지칭하는 stage 번호이다.
이렇게 함으로써 초반 코딩 단계(1/4, 1/2 스케일)에서 attention 수행시 메모리를 줄일 수 있다.
2. Progressive context fusion
Autoregressive entropy module에서 중요한 context 생성 부분이다.
Context란 현재 코딩하려는 의 확률 분포 ()를 예측하기 위해 이미 코딩한 latent 와 같이 활용할 정보를 말한다.
1) 이전 stage와 현재 stage의 스케일이 바뀌지 않는 경우
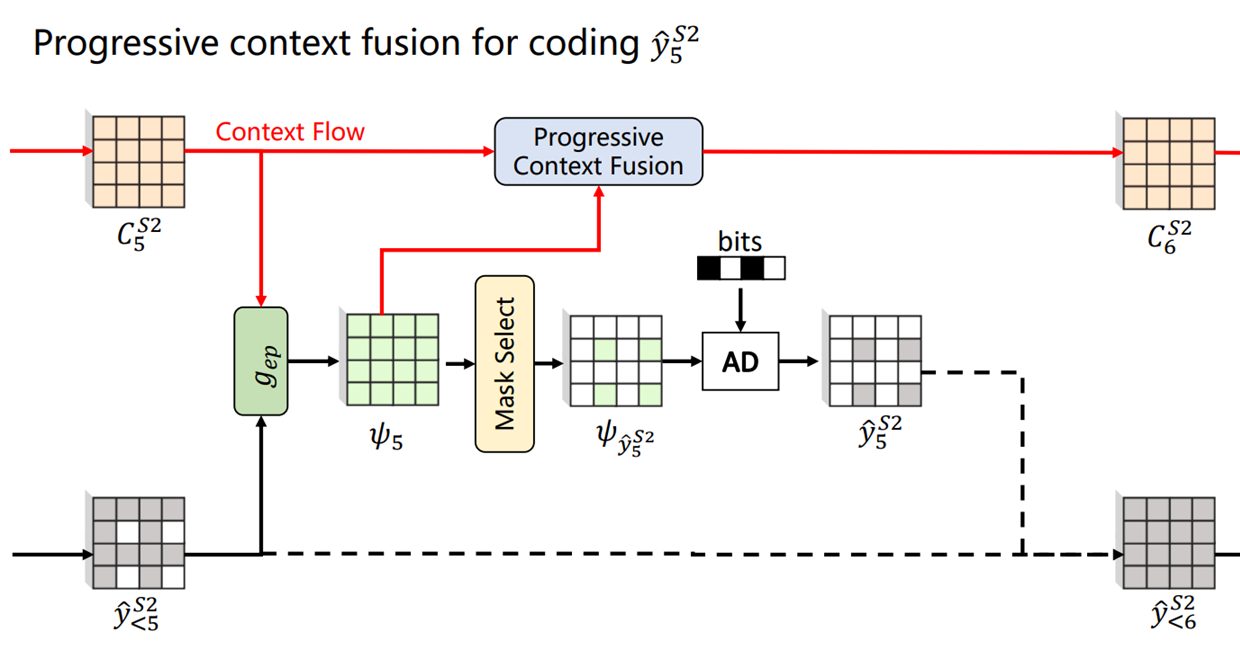
로 확률 분포를 예측하기 위한 파라미터를 얻는다. 이중 현재 코딩하고자 하는 부분()만 사용한다.
Progressive Context Fusion
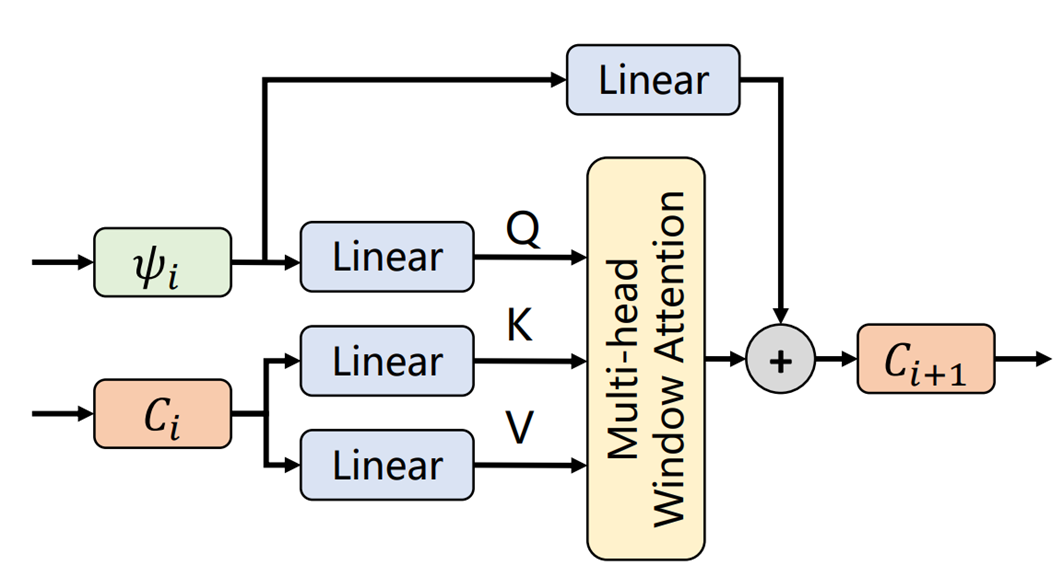
실질적인 Context를 업데이트를 하는 파트다. 구조는 그냥 cross attention이다.
2) 이전 stage와 현재 stage의 스케일이 바뀌는 경우
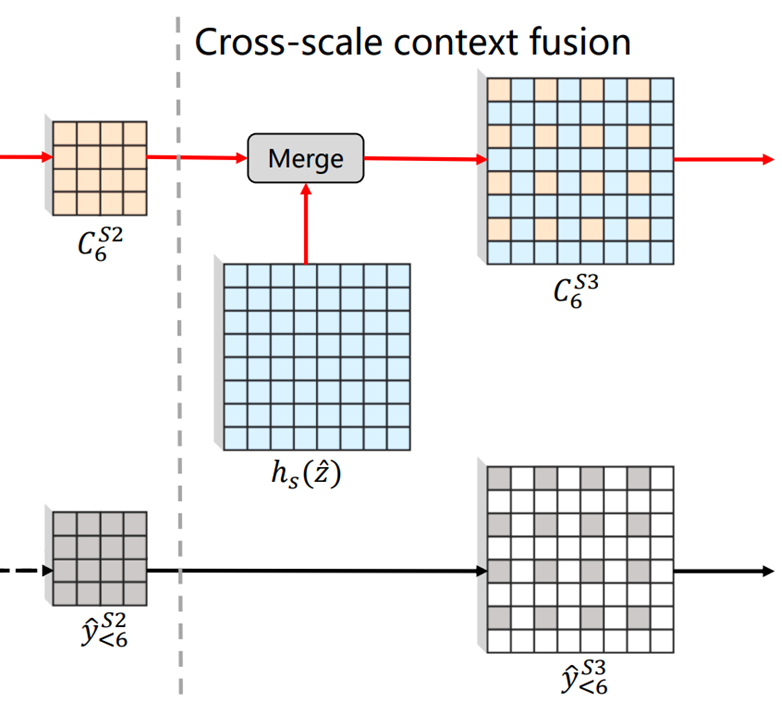
Context 업데이트 시, 원래 샘플링 해왔던 위치에 이전 context를 넣어 주고, 나머지 부분은 hyperprior z에서 얻을 수 있는 확률 분포 파라미터 예측의 초기값인 으로 채워준다.
이외 변경사항
Partial convolution(Pconv) in Residual block
인코더 디코더에서 사용하는 Residual block에서 연산량을 줄이기 위해 Partial convolution (Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks CVPR 2023) 을 차용했다.
![]()
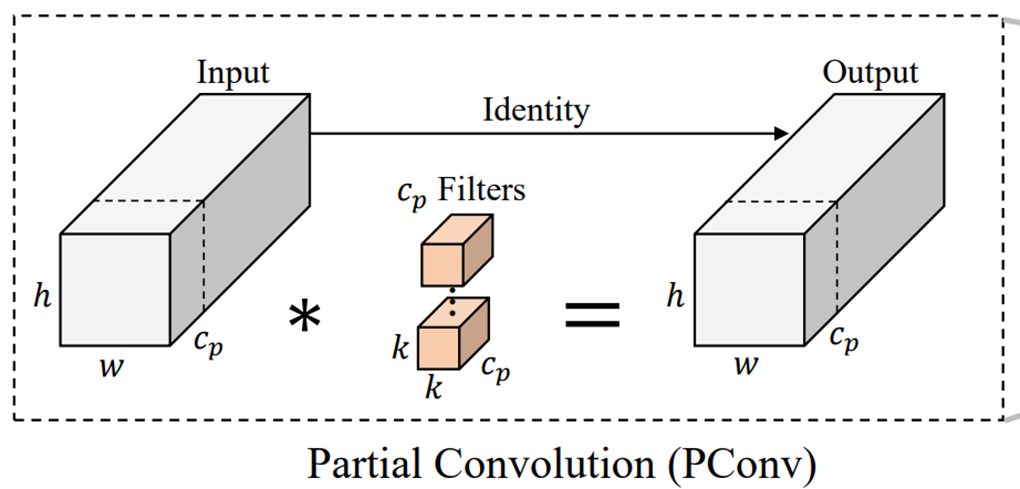
위 그림처럼, 채널 전체에 대해 convolution을 하는 것이 아니라 일부 채널(여기선 1/4)에만 연산을 진행한다.
Weight sharing entropy parameter network
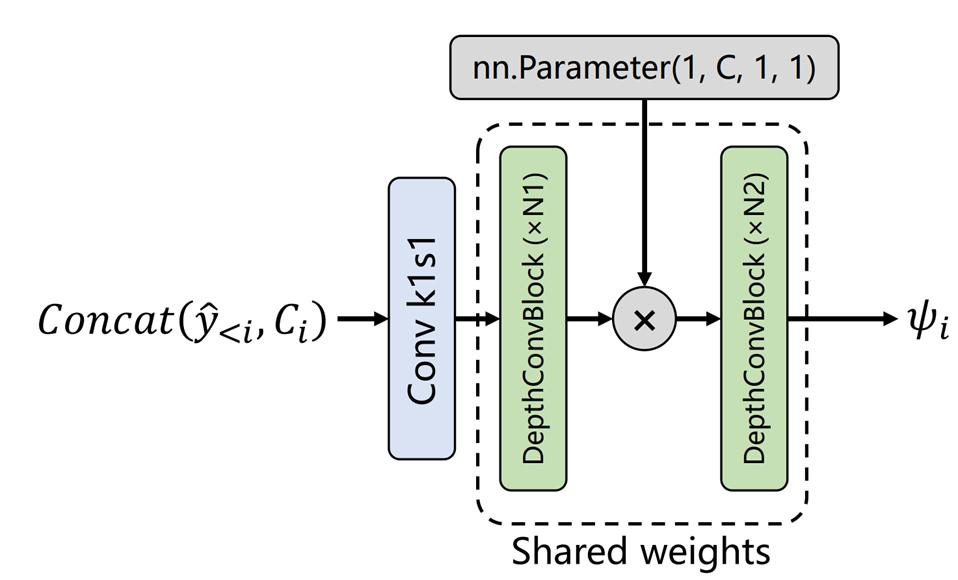
파라미터 수를 줄이기 위해 확률 파라미터 예측 모듈인 를 일부 공유한다. 스케일로 말하자면, 1/4 1/2 스케일에서 같은 파라미터를 사용하고, 1 스케일에서 같은 파라미터를 사용한다.
코딩 stage를 구분짓기 위해 stage별로 따로 있는 Step adaptive embedding을 중간에 곱해주었다.
성능
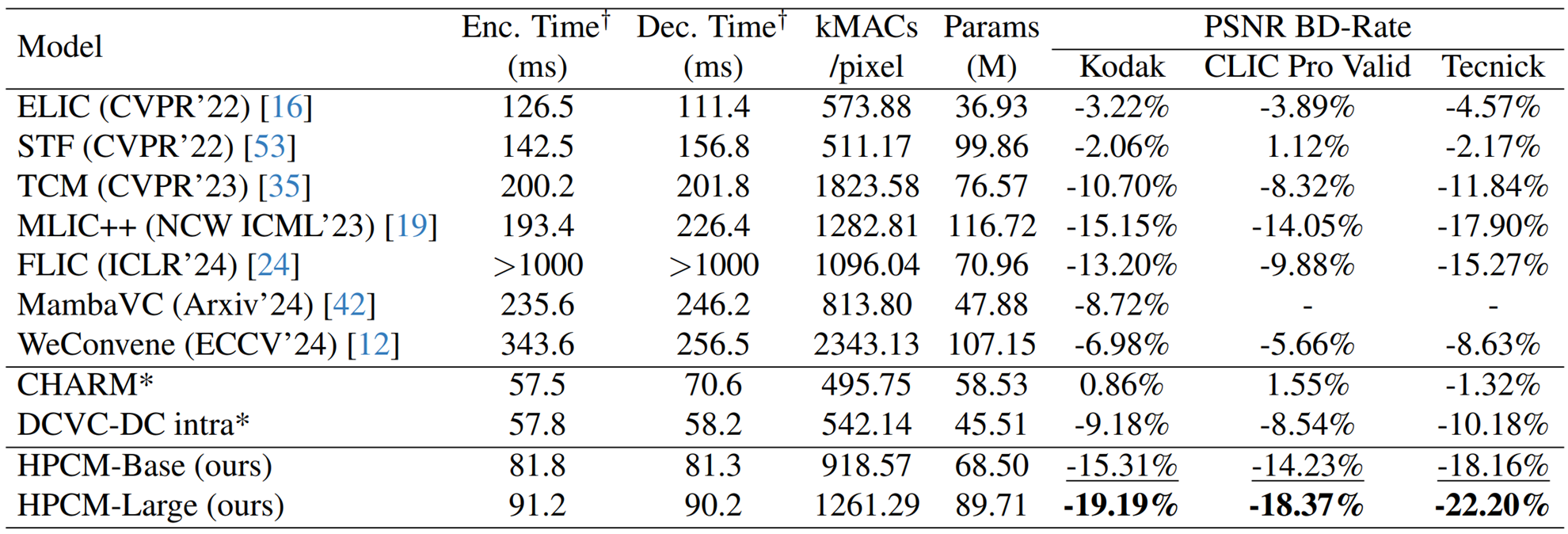
다른 image compression 기법들에 비해 꽤 빠르고 높은 성능을 보인다. 중간의 *표된 두 모델은 인코더 디코더는 동일하지만, entropy model만 제안 기법으로 측정해 준 성능이다.
제안 기법들에서도 느껴지듯이 코드를 봤을 때도 DCVC-DC를 확실히 참고 잘 한듯 하다.
여러가지 아이디어들도 근거 있게 잘 제안 한 것 같다. 어텐션 과정에서 이렇게 스케일 구분해서 차례로 진행한다는 것은 다른 연구 분야에서도 활용할 수 있을 것 같다.

분할정복 방식인가요