Learned video compresssion 관련 논문이고, 사람을 위한 지표(PSNR 등)가 아니라, 기계가 사용하기 좋은 형태로 코딩하는 것을 목표로 한다.
제안 기법
크게 3개로 구분할 수 있다.
1. 프레임의 개념
2. 프레임 코딩 과정
3. GOP 구성
Overview
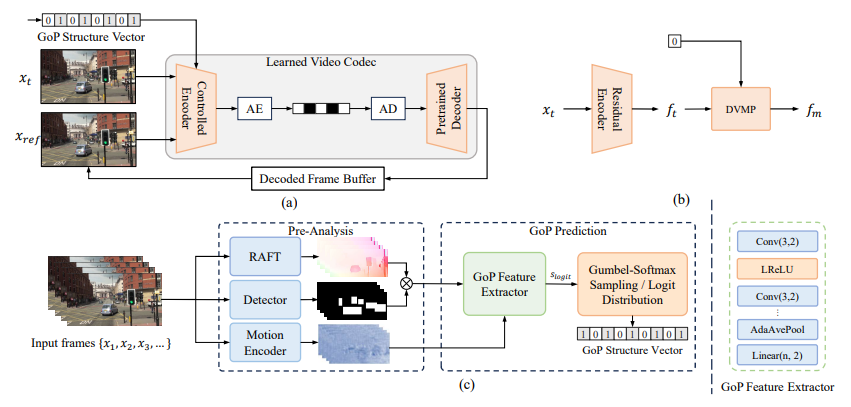
이미 학습 된 인코더, 디코더에서 디코더는 그대로 두고, 인코딩 과정에만 변화를 준다.
1. 프레임의 개념
P 프레임이랑 이전 정보를 사용해서 코딩한다는 점은 같다.
다만 프레임은 기계가 필요로 하는 부분을 보존한다.
논문의 예시로, 프레임은 모션에 할당되는 비트가 20% 미만으로 매우 적은데, object detection을 위해서는 모션 정보가 더 필요하니까, 프레임으로 코딩할 땐 모션에 비트가 좀 더 할당 될 수도 있다.
2. 프레임 코딩
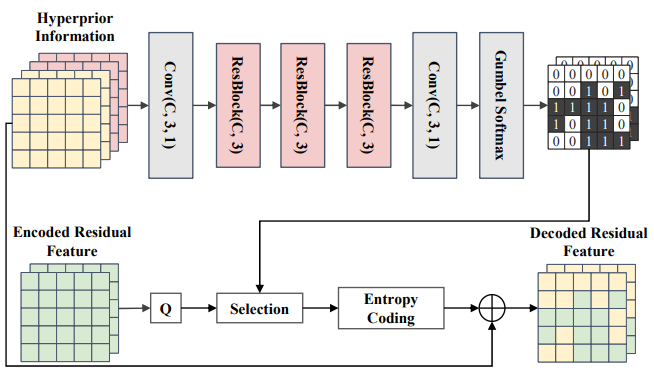
Hyperprior를 코딩해서 얻은 로 부터 1 채널짜리 mask ()를 얻는다.
(+Gumbel softmax로 학습 시에도 미분 가능한 binary mask를 얻는다.)
0: 필요 없는 부분 (entropy coding 수행 x)
- 다만, 구체적으로 어떻게 한다는 언급은 없어서 그냥 예측한 로 대체하는 것으로 추정됨
1: 기계가 필요로 하는 부분 (entropy coding을 수행)
*Autoregressive 지원하는 버전도 서플에 있는데, 단순히 이전 정보를 중간에 concat해서 연산에 추가해준다.
3. GOP 구성
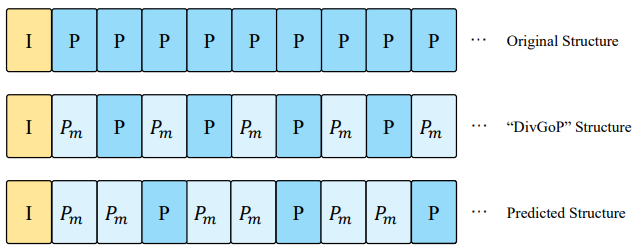
프레임을 마구 사용하면 기계에 좋을 것 같으나 그렇게 하면, 다음 프레임 복원 자체가 잘 안된다고 한다.
그래서 두번째 줄에 있는 것과 같이 우선 임의로 , 반복하는 구조를 채택했다.
이것보다 좋은 GOP 구조가 있기 때문에, 으로 할 지, 로 할지 예측하는 모듈을 추가한다.
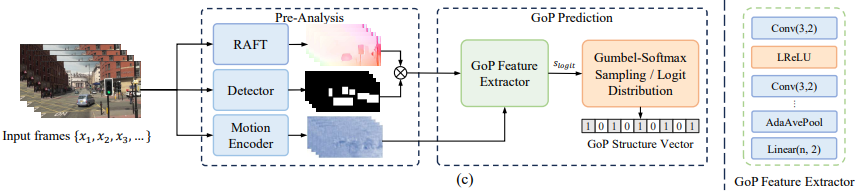
Overview의 아랫줄에 해당하는 부분이고, RAFT, Detector, Motion encoder feature 3개로 0 또는 1을 예측한다. 왜 이 3개인지는 언급이 없으나, 기계 인식을 위한 특징을 위 3개 정도로 정리한 것으로 보인다.
실험 / 결과
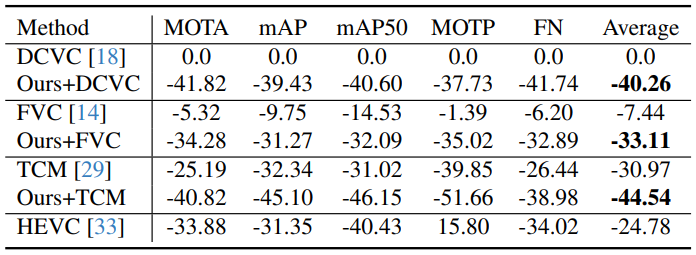
당연하게도, PSNR 자체는 baseline에 비해 떨어지고, 각종 인식 task 성능은 올라간다.
의견 정리
새로운 프레임 종류인 프레임을 개발한 것이 contribution으로써 좋아보인다.
GOP 구조 예측은 아마 잘 안될 것 같아보이는데, DFS로 가장 좋은 구조를 찾은 것과의 비교만 있고, 예측한 것과의 비교는 없다.
사용한 baseline들이 굉장히 옛날 것들이라 (가장 최근이 22년 논문) 최신 기법들에도 적용하면 어떨지 궁금하다.
