인턴 시절 145만개 정도 되는 공정 데이터를 분석해야 하는 상황이 있었다. 당시 여러 공정 장비를 활용해서 파생변수를 만들어야 했는데, 데이터가 꽤 많다보니 시간이 상당히 걸렸었다. 그 때 데이터 전처리 시 최적화 기법을 찾아봤었고, 그 중 vectorization을 공부하여 지금도 유용하게 사용하고 있다.
만약 몇 천만 정도 되는 대용량 데이터를 사용한다면 반드시 알아야 하는 개념일 것이다(그 때도 apply()나 iterrows()를 사용하면 꽤 손해를 보게된다. 단순 반복문은 지옥이다).
한번 더 제대로 숙지할 겸, 당시 참고한 블로그를 활용해 실험 코드를 돌려보고 이를 정리해보겠다.
Vectorization의 원리를 알고 모르고의 차이는 상당하다. 숙지하는 것이 좋다.
데이터 및 참고 소스코드
https://github.com/s-heisler/pycon2017-optimizing-pandas/tree/master/pyCon%20materials
0. 데이터 및 함수 준비
import pandas as pd
import numpy as np
df = pd.read_csv('new_york_hotels.csv', encoding='cp1252')
print(df.shape)
df.head()
해당 데이터의 크기와 생김새는 다음과 같다. 여기서 하고자 하는 것은 특정 점의 위도(latitude)와 경도(longtitude)를 활용해 지구의 곡률을 조정하고 일련의 거리를 계산하여 "distance"라는 파생변수를 생성하는 것이다.
함수는 다음과 같다.
from math import *
# Haversine - 기본 거리 공식 정의. 지구 상에서 두 점의 직선 거리
def haversine(lat1, lon1, lat2, lon2):
MILES = 3959
lat1, lon1, lat2, lon2 = map(np.deg2rad, [lat1, lon1, lat2, lon2])
dlat = lat2 - lat1
dlon = lon2 - lon1
a = np.sin(dlat/2)**2 + np.cos(lat1) * np.cos(lat2) * np.sin(dlon/2)**2
c = 2 * np.arcsin(np.sqrt(a))
total_miles = MILES * c
return total_miles1. 단순 반복 for문
모든 행을 수동으로 반복하며 일련의 거리를 반환하는 함수를 정의한다. 정말 일반적인 방법이며, 직관적이다. 판다스를 잘 모르는 상태에서 사용하기에 가장 쉬운 방법이다.
참고로 시간 측정은 매직 명령어인 %%timeit를 사용한다. 해당 셀의 가장 위에 위치해야 하는 것을 명심하자.
%%timeit
# 모든 행을 수동으로 반복하며 일련의 거리를 반환하는 함수를 정의함
def haversine_looping(df):
distance_list = []
for i in range(0, len(df)): # 모든 행을 돌면서
# 위도와 경도를 넣어서 (40.671, -73.985)와의 거리 계산
d = haversine(40.671, -73.985, df.iloc[i]['latitude'], df.iloc[i]['longitude'])
distance_list.append(d)
return distance_list
df['distance'] = haversine_looping(df)
>>> 301 ms ± 81.6 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)약 301ms정도의 시간이 소요되었다. 약 1600개 행을 처리하는데 필요한 함수임을 고려하면 느린 편이다. 이를 개선해보자.
2. iterrows()를 사용한 반복
iterrows()는 행을 반복하며 행 자체를 포함하는 객체에 덧붙여 각 행의 색인 반환한다. 제너레이터로 동작하기에, 데이터프레임의 각 행을 하나씩 반환해서 단순 for문에 비해 비교적 효율적으로 연산을 수행할 수 있다. 각 행이 pd.Series 객체로 반환되며 이는 파이썬의 순수 객체가 된다.
%%timeit
# 반복을 통해 행에 적용되는 Haversine 함수
haversine_series = []
for index, row in df.iterrows(): # 행을 하나씩 반환
d = haversine(40.671, -73.985, row['latitude'], row['longitude'])
haversine_series.append(d)
df['distance'] = haversine_series
>>> 174 ms ± 22.9 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)위에보다 절반 가까이 줄어들었다.
- 단순 for문은 위도와 경도 모두 각각 행을 찾아가야 된다.
- iterrows()를 사용하면 두 작업을 한 번에 진행할 수 있다.
3. apply()를 사용한 반복
apply()는 iterrows()보다 더 좋은 옵션이라고 할 수 있다.
apply()는 데이터 프레임의 특정 축(행 또는 열)을 따라 함수를 적용하는데, lambda를 활용하여 haversine 함수를 각 행에 적용해 각 행의 특정 셀을 함수 입력값으로 지정할 수 있다. 축(axis) 옵션을 마지막에 포함하여 행과 열 중 어디에 함수를 적용할지 결정한다.
%%timeit
df['distance'] = df.apply(lambda x : haversine(40.671, -73.985, x['latitude'], x['longitude']), axis = 1)
>>> 46.1 ms ± 2.27 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)apply()는 내부적으로 Cython으로 최적화된 루프를 사용한다.
- Cython : C와 파이썬 사이의 브릿지 역할을 하는 프로그래밍 언어. 파이썬의 동적 타입 시스템을 유지하면서도 C언어의 성능을 얻을 수 있음.
때문에 본질적으로 행을 반복하지만, iterrows()보다 함수 실행 시간이 반으로 줄어든다.
하지만 결국은 반복문이고, 각 행이 1,631번 이상 실행된다. 아무리 apply()가 날고 긴다해도 1번의 연산으로 문제를 해결하는 vectorization를 이길 수는 없다.
4. pd.Series를 사용한 vectorization
판다스의 기본 단위인 데이터 프레임(pd.DataFrame)과 시리즈(pd.Series)는 모두 배열 기반이다. 그리고 벡터화된 연산은 반복문을 사용하지 않고, 배열 전체에 대한 작업을 수행하는 방식을 의미한다.
판다스는 수학 연산에서 집계부터 문자열 함수에 이르기까지 다양한 벡터화 함수를 포함한다. 판다스의 내장 함수들은 pd.Series와 pd.DataFrame에 최적으로 작동하게끔 되어있다.
지금까지는 Haversine햄수에 스칼라 값을 전달했다. 하지만 Haversine 함수 내에서 사용하는 모든 함수를 배열 위로 작동시킬 수 있다. 이렇게 하면 Haversine 함수를 매우 간단히 벡터화할 수 있다. 스칼라 값으로 각 위도, 경도를 전달하는 대신 전체 Series(열)을 전달하는 것이다. 이를 통해 판다스는 벡터화 함수에 적용 가능한 모든 최적화 옵션을 활용할 수 있으며, 특히 전체 배열에 대한 모든 계산을 동시에 수행하게 된다.
%%timeit
# 각 row를 넣는 대신 벡터 자체를 집어넣는다
df['distance'] = haversine(40.671, -73.985, df['latitude'], df['longitude'])
>>> 1.6 ms ± 68.4 μs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)apply()에 비해 거의 30배 가까이 시간이 개선되었다. 입력 유형이 row단위에서 벡터단위로 바뀐 것 뿐, 어떠한 for문과 같은 추가적인 연산이 활용되지 않았다.
당연히 빠를 수 밖에 없는게, apply()는 for문으로 haversine() 함수를 1,631번 이용하는 동안 pandas를 활용한 벡터화는 함수를 1번만 사용했다. 함수를 전체 배열에 대해 동시에 적용하였기 때문이다.
5. 넘파이 배열(ndarray)를 사용한 vectorization
Numpy는 수학 및 과학 연산을 위한 파이썬 패키지이며, 내부의 상당부분이 C나 포트란으로 작성되어있어 실행속도가 빠르다. 앞서 살펴본 Pandas의 자료형들도 Numpy의 array자료형(ndarrays)을 활용해 생성 및 수정이 이루어진다. 하지만 index, datatype 확인과 같은 작업으로 인한 오버헤드가 많이 발생하지 않기 때문에, 결과적으로 넘파이 배열에 대한 작업은 판다스 시리즈에 대한 작업보다 빠르다.
판다스 시리즈가 제공하는 추가 기능을 사용하지 않을 경우, 넘파이 배열을 판다스 시리즈 대신 사용할 수 있다. 예를 들어 Haversine 함수의 벡터화 구현은 실제로 위도, 경도 시리즈의 index를 사용하지 않기 때문에 사용할 수 있는 색인이 없어도 된다. 이에 비해 색인으로 값을 참조해야 하는 데이터 프레임의 조인 같은 작업을 수행한다면 판다스 개체를 계속 사용하는 편이 좋다.
위도와 경도 배열을 pd.Series의 values()를 활용해 pd.Series에서 np.array로 변환하자. np.array를 직접 함수에 전달하면 판다스가 전체 벡터에 함수를 적용시킨다.
%%timeit
df['distance'] = haversine(40.671, -73.985, df['latitude'].values, df['longitude'].values)
>>> 295 μs ± 71.8 μs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)처음으로 μs(microsecond)단위가 나왔다.
결과
아래 표는 우리의 실험 결과이다.
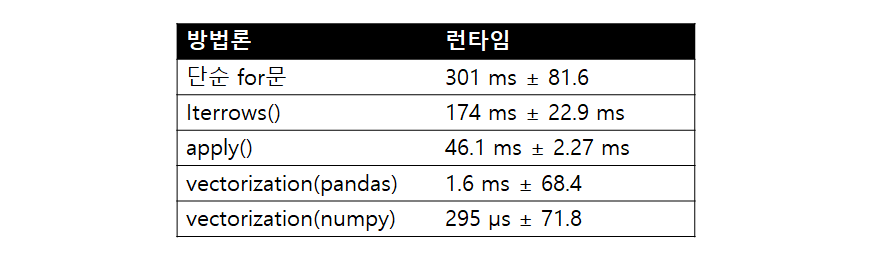
301밀리초(ms)는 295마이크로초(μs)의 약 1020.34배이다. 즉, μs로 1분정도 걸리는 대용량 데이터에서 같은 작업을 단순 for문을 사용하면 약 17시간이 걸린다. 물론 앞서 numpy vectorization에서 이야기했듯이, 어떤 작업이냐에 따라 최적화를 무작정 사용하는 것은 좋지 않을 수도 있다. 꾸준히 사용함으로써 숙지하여 상황에 따라 가장 적절하게 해당 기법들을 활용할 수 있어야 할 것이다.
** reference
https://blog.naver.com/draco6/221675459372
https://aldente0630.github.io/data-science/2018/08/05/a-beginners-guide-to-optimizing-pandas-code-for-speed.html
