Python
1.참조(Reference)와 얕은 복사(Shallow copy), 깊은 복사(Deep copy)

데이터 전처리, 분석, 모델링 등등 내가 하는 모든 업무에 파이썬을 빼고 살 수는 없다. 하지만 종종 "왜 이렇게 뜨지?"라며 의문이 들 때가 있었고, 코드 상의 문제도 있지만 많은 경우 파이썬 자체적인 이해가 필요한 부분이기도 했다. 그 중 하나가 참조의 영역이다.참
2024년 4월 18일
2.Mutable과 Immutable, 알아야 하는 이유
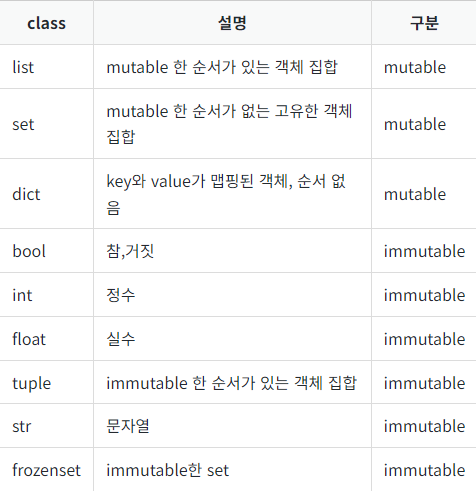
파이썬의 객체는 크게 두 가지 종류로 나눌 수 있다.mutable(값이 변하는 객체)와 immutable(값이 변하지 않는 객체)이다. 이를테면 list, dict 등은 특정 값을 넣고 빼고 할 수 있으므로 mutable하다고 할 수 있지만, str이나 tuple과 같
2024년 4월 19일
3.Vectorization을 활용한 최적화(feat.대용량 데이터)

인턴 시절 145만개 정도 되는 공정 데이터를 분석해야 하는 상황이 있었다. 당시 여러 공정 장비를 활용해서 파생변수를 만들어야 했는데, 데이터가 꽤 많다보니 시간이 상당히 걸렸었다. 그 때 데이터 전처리 시 최적화 기법을 찾아봤었고, 그 중 vectorization을
2024년 8월 4일
4.Type Casting을 활용한 최적화(feat.대용량 데이터)
직전 포스팅에 이어, 데이터를 보다 효율적으로 다룰 수 있는 또 다른 방법을 알아보자. int와 float을 활용한 최적화이다.int(정수형)와 float(부동 소수점) 데이터 타입은 여러 종류가 있고, 각각 메모리 크기와 표현할 수 있는 값의 범위는 다르다.예를 들어
2024년 8월 9일