Disk & File
DB에서 Query를 처리하는 과정

**Query**
⬇︎⬇︎
**Query Optimizer and Execution** : 쿼리 최적화기를 실행함으로써 데이터 구조&통계를 이용해 효율적인 수행 계획을 수립 후 실행
⬇︎⬇︎
**Relation Operators** : 관계 연산자를 통한 데이터에 대한 질의 생성
⬇︎⬇︎
**Buffer Manager** : 버퍼관리자를 통해서 메모리의 버퍼에 적재된 주기억 장치 공간(HDD, SDD)의 데이터를 프레임 단위로 구분해서 관리
⬇︎⬇︎
**File and Access Manager** : 파일 관리자를 통해 여러 형태의 파일 내의 페이지를 추적 감시하여 한 패이지내에 정보들을 조직하는 방법을 수행
⬇︎⬇︎
**Disk Manager** : 데이터가 저장될 디스크 공간을 관리
⬇︎⬇︎
**DataBase**의 과정을 거친다.
레코드를 삽입 또는 삭제함에 따라 데이터베이스 역시 확장되고 축소되는데, 디스크 관리자는 어떤 디스크 블록들이 사용중이고, 어떤 페이지가 어느 디스크 블록에 있는지를 추적 감시하는데 DB를 사용하는 과정에 처음에는 빈 공간에 디스크에 블록들이 할당되지만 할당, 반환 등의 과정이 반복되며 순차적인 구조는 무너지고, 중간에 빈 공간이 생기게 된다
이러한 빈 공간을 효율적으로 관리해야만 새로운 데이터를 잘 저장 할 수 있는데, 두가지 방법이 있다.
- 블록 반환시마다 비어있는 공간의 포인터를 리스트에 저장해 나중에 사용할 수 있도록 한다.
- 빈공간을 쉽게 찾을 수 있으며, 관리가 간단
- 연속된 큰 공간을 찾기 어려울 수 있다.
- 각 디스크 블록마다 1bit 블록 사용 여부를 나타내는 비트맵을 유지
- 연속된 빈 공간을 빨리 찾을 수 있으며, 전체 공간 상태를 한눈에 파악할 수 있다.
- 단, 데이터 구조에 따라 관리가 복잡할 수 있다.
버퍼 관리
대부분의 데이터베이스는 주기억장치보다 큰 용량을 가지는데, CPU는 메모리에 적재된 데이터만 처리할 수 있다.
따라서 DBMS는 필요시 데이터를 주 기억장치에 적재하여, 언제 페이지를 교체해야하는지 결정해야 한다.
이 때 버퍼 관리자는 하드디스크에서 필요한 데이터를 가져와 메모리에 임시 저장해두는 역할을 한다.
예시로, 책장(하드디스크)에서 자주 보는 책을 책상(메모리)에 올려두는 과정과 유사하다.
버퍼 풀
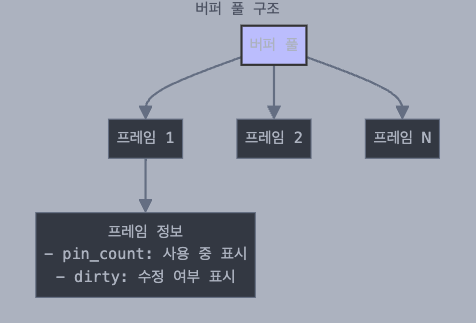
메모리에서 데이터를 임시로 보관하는 공간이며, 여러개의 프레임으로 나누어져있다.
책상 위에 책을 올려놓을 수 있는 여러개의 공간을 나눈 것과 같은데, 각 칸은 두가지 정보를 가지고 있다.
프레임이 가지고 있는 정보
- pin_count : 특정 페이지가 사용중인 상태를 나타내며, 여러 트랜잭션이 동시 접근 가능함 (pin_count가 0이 아닌 경우 해당 페이지는 교체 대상에서 제외)
- dirty : 데이터가 수정되었는지 표시하는 flag (수정시 1, 메모리의 페이지를 디스크에 기록 하기 전 dirty 상태의 페이지는 디스크에 반영해야 함)
간단한 버퍼 관리의 동작 과정
1. 우선 서버로 데이터 요청이 들어오면 해당 데이터가 있는지 버퍼 풀에서 먼저 탐색한다.
2-1. 만약 빈공간이 있다면 바로 사용
2-2. 버퍼 풀에 없다면 새로운 공간을 할당해줘야 하는데 이때 pin_count가 0인 곳을 찾아 수정된 데이터(dirty == true)인 경우 하드디스크에 저장하고 새로운 데이터를 가져온다.
자세히 정리하자면 버퍼 풀의 역할은
디스크 I/O를 줄이기 위해 메모리에 데이터를 캐싱해두는 핵심 공간이며, DBMS는 버퍼 풀에 데이터를 적재함으로써 디스크 접근을 최소화하여 성능을 최적화 시킨다. 즉, 자주 사용하는 데이터에 대해 디스크 대신 메모리에서 읽고 쓰는 작업을 수행
또한 버퍼 풀의 크기는 DB 성능에 중요한 영향을 미치기에 버퍼 풀이 너무 작을 경우 페이지 교체가 빈번해지며(속도 저하?), 너무 크면 메모리 낭비가 발생하므로 최적의 크기를 찾는 것이 DB 성능 최적화를 위한 중요한 요소 중 하나이다.
페이지
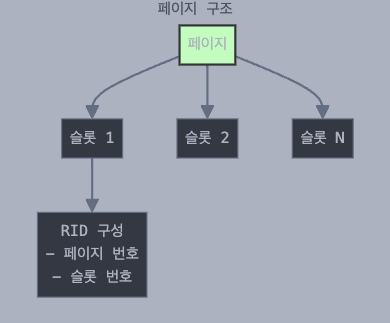
페이지는 버퍼 풀에 저장되는 레코드의 집합이며, 디스크 -> 메모리로 데이터가 전송되는 최소 단위이다.
페이지 역시 각 레코드가 저장되는 슬롯을 가지며, 각 슬롯에 레코드가 저장된다.
레코드는 <페이지 번호>, <슬롯 번호>의 쌍으로 식별되며 이 쌍을 RID(Record ID)라고 하며 레코드의 포인터 역할을 수행한다.
데이터 저장 및 관리
대부분 자료구조에서는 저장된 데이터의 rid를 직접 알 수 없는데, 정렬되지 않은 자료 구조에서 동등 검색을 수행할 경우, 전체 자료 구조를 스캔 해야한다.
이때 index는 선택(Selection) 조건에 맞는 rid를 구할 수 있도록 만든 보조 자료구조인데 이를 활용한다.
스토리지 엔진
MyISAM(ISAM 기반)
- 색인 순차 접근 방식 파일
- 인덱스를 순차적으로 구성하여 큰 인덱스의 성능 문제를 해결
파일 구조
.frm : 테이블 구조
.MYD : 실제 데이터
.MYI : 파일에 인덱스기본적인 연산인 삽입, 삭제, 검색은 매우 간단한데, 이중 동등 셀렉션 탐색의 경우 루트 노드부터 시작하여 크 기밧에 해당하는 레코드가 어떤 서브트리에 있을지 판단한다.
ISAM에서 삽입, 삭제는 단말 페이지의 내용에만 영향을 주는데, 이 경우 하나의 단말 노드에 수많은 삽입이 수행될 때 오버 플로우 체인을 만들 수 있으며, 탐색시 그만큼 탐색해야 하므로 레코드를 찾아내는 시간에 상당한 영향을 미치게 된다.
이를 위해 페이지에 약 20%의 여유 공간이 있도록 트리를 만드는데, 이때도 트리가 가득 찼을 때 데이터 삽입 시 오버 플로우 체인이 만들어지게 될 것이다.
한편으론 단말 페이지만 수정될 수 있어 동시성 제어에서는 이점을 갖게 되는데, 일반적으로 어떤 페이지를 접근하는 요청자는 자신이 이 페이지를 사용하는 동안 다른 사용자들이 그 내용을 동시 수정 할 수 없도록 Lock을 건다.
페이지 수정시에도 그 페이지를 잠근 사용자가 없을 경우에만 허용되는 전용(exclusive) 잠금을 강제함으로써 그 페이지에 대한 접근을 시도하는 트랜잭션을 기다리도록 할 수 있다.
인덱스 계층 페이지를 잠글 필요가 없는 것은 , B+ 트리와 같은 동적 구조에 비해 커다란 이점이 되며, 데이터의 분포와 크기가 상대적으로 정적일 경우(오버 플로우 체인이 거의 없다면) ISAM은 B+ 트리보다 좋은 구조가 된다.
또한 외래키를 미지원 하며 테이블 레벨 잠금, 읽기 작업에 최적화 되어 있다고 볼 수 있다.
- 시스템 장애시 수동 복구가 필요하며, 데이터 손상 위험이 있다.
InnoDB(B+Tree기반 )
ISAM과 같은 정적인 구조는 파일 커짐에 따라 오버 플로우 체인으로 인해 성능 저하의 단점이 있다.
따라서 삽입, 삭제시에도 깔끔히 조정되는 융통성 있는 동적 구조를 개발하게 되는데 이것이 B+Tree이다.
동적 균형 트리 구조를 가지고 있으며, 모든 단말 노드가 같은 레벨이다.
- 균형 유지로 인해 일관된 성능을 보장하며
- 동적이기에 오버 플로우 체인이 없어 효율적인 데이터 관리가 가능하다
하지만 구조가 복잡하고 추가 공간이 필요하며, 읽기 성능은 상대적으로 낮다.
내부 구조
내부 노드 : 키 값, 포인터만 저장
리프 노드 : 실제 데이터 저장
- 리프 노드들은 Linked Llist로 연결되어 순차 접근이 용이자체 버퍼 풀을 사용해 데이터와 인덱스를 모두 캐시하며, ACID 특성을 완벽히 지원한다
ACID 특성
- 원자성 : 트랜잭션은 완전히 실행 되거나, 완전히 취소 되어야 한다.
- 일관성 : 데이터의 무결성을 보장해야한다.
- 격리성 : 동시 실행 트랜잭션은 간섭을 방지해야한다.
- 지속성 : 완료된 트랜잭션은 영구히 보존되어야 한다.
레코드를 탐색할 땐 루트부터 알맞은 단말 노드까지만 가면 되는데 이걸 높이라고 한다. 균형 트리이기에 어떤 단말 노드든 이 값은 같고 이러한 B+Tree는 레코드 파일이 자주 갱신되며, 정렬된 접근이 중요하면 데이터 엔트리로 레코드를 저장한 B+Tree를 쓰는것이 정렬 파일 이용시보다 성능이 우수하다.
인덱스 엔트리 저장을 위한 공간 오버헤드 대신 정렬 파일의 장점과 효과적인 삽입, 삭제 알고리즘의 장점을 모두 얻게 된다.
- 자동 복구 기능과 크래시 복구를 지원해 데이터 안전성이 높다.
비교하기
MyISAM은 테이블 레벨에서 잠금을 하며, InnoDB는 행레벨에서 잠금을 한다
MyISAM은 정적인 구조, InnoDB는 동적인 구조로 데이터를 관리하며 InnoDB의 경우 외래키, 트랜잭션을 지원한다.
즉 선택 기준을 정리하자면
단순히 읽기 위주의 작업이고 데이터의 분포, 크기가 상대적으로 정적일 경우엔 MyISAM이 B+ Tree보다 좋은 구조를 가지지만 보통 InnoDB는 쓰기, 수정 작업에 특화되어 있으며 트랜잭션이 필요하거나, 높은 동시성을 요구하며 빈번한 데이터 수정이 필요할 때 선택한다.
파일은 일반적으로 축소보단 확장되며, 이러한 활용도로 인해 ISAM 방식보다 B+Tree가 전반적으로 우수하다고 평가된다.
