고민 내용
User에 대해 매일 7천 건 씩 bulljs를 통한 비동기 백그라운드 처리를 진행해야 했다.
관련 작업을 QA에 배포 후 우선 11건 정도만 처리하도록 더미 데이터를 넣었다.
그리고 모니터링 하던 중...

MaxListenersExceededWarning: Possible EventEmitter memory leak detected. 11 global:completed listeners added to [Queue]. MaxListeners is 10. Use emitter.setMaxListeners() to increase limit...
요런 에러가 발생하게 되었다!
물론 이런 오류만 뜨고 로직은 정상적으로 수
🤔 메모리가 새고 있을 수도 있다고..?
찾아보기
에러 메시지를 조금 자세히 보자.
11 global:completed listeners added to [Queue]. MaxListeners is 10. global:completed 라는 이벤트 리스너가 11개라고 한다.
그리고 이벤트 하나 당 Node.js에서 기본으로 두는 리스너의 최대 수는 10이다.
난 이런 거 설정한 적 없는데?!
원인 알아보기
문제의 코드다.

bull 사용하면서 전체 처리 진행을 알기 위해서 사용한 코드다.
의도는, 각각의 작업을 추적해 모든 작업이 완료되면 진행 상황을 찍기 위해 작성되었다.
한 번 라이브러리의 속을 파보자.

우선 Redis pub/sub에서 global:completed, global:failed 메시지를 구독하는 것 부터 시작한다.
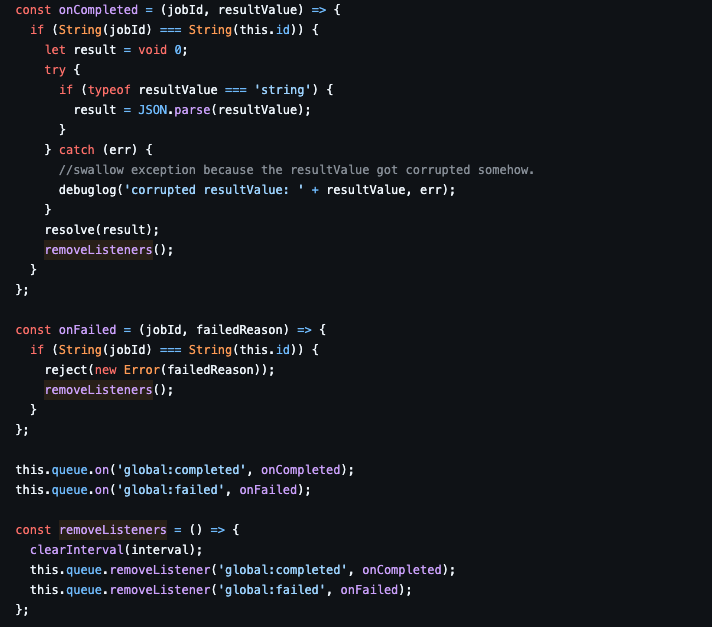
그리고 각각의 메시지가 발생했을 때 터질 콜백을 등록한다.
재밌는 점은 global 이벤트가 발생하면 그게 어떤 작업의 것인지 알 수 없기 때문에 콜백에서 jobId를 비교하고, 맞으면 콜백을 터뜨리고 아니면 패스하는 방식이다.
이때 콜백이 등록되는 건 this.queue.on을 통해서 등록되는데, 조금 더 자세히 보자
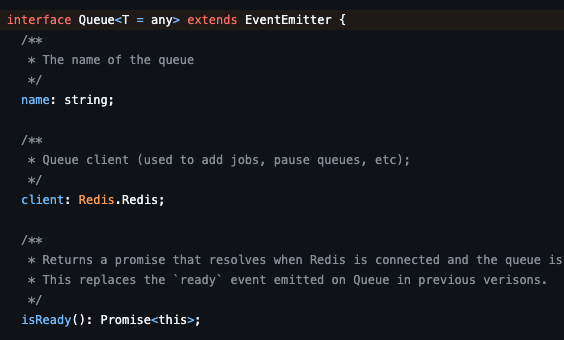
여기서 사용되는 Queue는 사실 EventEmitter의 상속을 받고 있다.
그러니까 Bull의 Queue는 Node.js 내부의 이벤트 관리를 함과 동시에 Redis pubsub을 이용한 큐 로직을 수행하는 것이다.
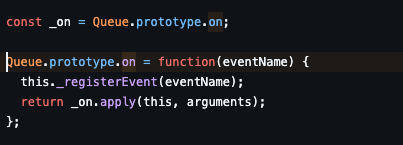
on은 두 가지 일을 수행하는데,
첫 번째는 register를 통해 메시지를 구독하는 것이다.
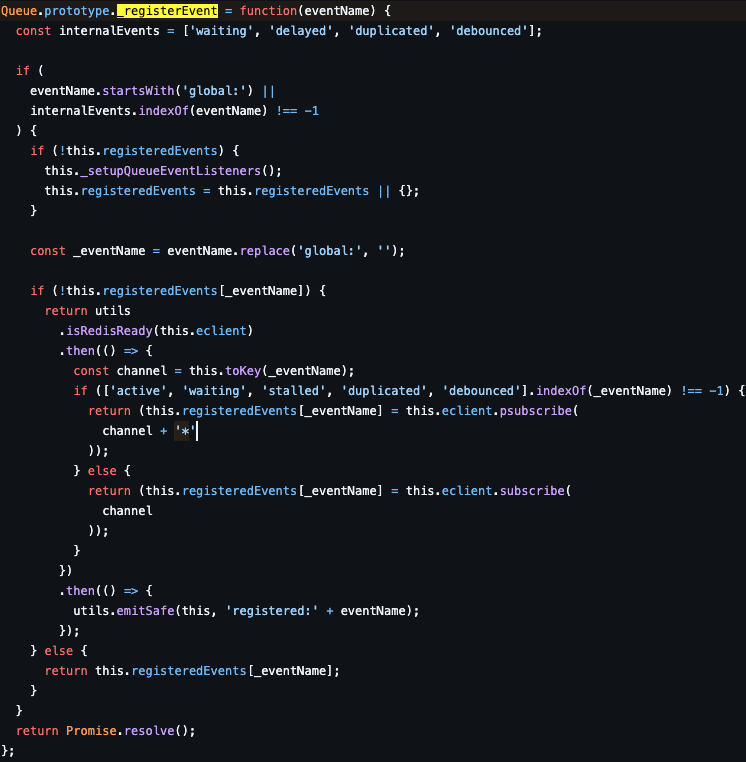
여기서는 크게 볼 건 없지만, 앞선 코드에서 구독을 했는데 왜 또 하지..? 하는 생각에 정리해보았다.
요약하자면, 중복으로 하지 않도록 막는 코드가 존재한다.
this.registeredEvents[_eventName]그리고 node.js 내부에서 관리되는 이벤트 이름은 global을 떼고 저장된다.
두 번째 _on은 EventEmitter의 on이다.

출처 : https://nodejs.org/en/learn/asynchronous-work/the-nodejs-event-emitter
이건 Node.js 공식 문서에서도 확인할 수 있다.
EventEmitter를 통해 on을 호출하면, 특정 이벤트 발생 시 동작해야 하는 콜백을 등록할 수 있다.
다시 처음으로 돌아와서,

이 코드는 이제 실제 프로덕션에서는 7천 개의 global:completed 콜백과 global:failed 콜백을 등록한다.
그럼 등록된 콜백은, 런타임에서 알고 있어야 실행을 하기 때문에 JS Heap (메모리)에 저장시킨다.
이벤트가 발생할 경우 이 이벤트의 리스너(콜백) 리스트를 모두 순회한다. 동기적으로 돌기 때문에 이것도 비효율이지만,
의도치 않은 동작으로 이 리스너들이 해제되지 않으면, node.js 입장에서는 이 리스너들이 계속 사용된다고 판단하여 gc가 돌지 않고, 메모리 누수가 발생할 수 있다!
참고: https://nodejs.org/api/events.html
해결해보기
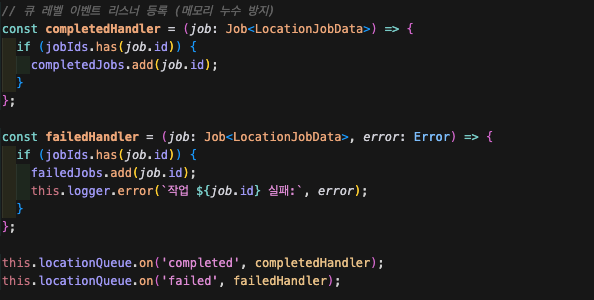
우리는 모든 작업에 대해서 추적할 필요가 없다.
모든 작업이 종료되었을 때, 성공한 작업의 총 개수만 알면 된다.
따라서 작업에 대해 이벤트 리스너를 걸 필요 없이,
그냥 작업 큐에 대해 전체의 리스너를 걸어두면 된다.
각각의 콜백은 성공, 실패의 개수를 카운팅한다.
이전에 리뷰를 받았던 부분이
'Cron에 의해 작업이 중복 실행되는 경우, 이벤트 리스너의 의도가 보장 받을 수 없다'라는 내용이 있었는데,
이를 보장하기 위해 jobId를 실행 시각을 섞어서 만들도록 하였고, 이 id들을 미리 리스트로 만들어 저장해두었다가 이벤트가 터질 때 리스트에 존재하는 id인 경우에만 콜백이 실행되도록 만들었다.
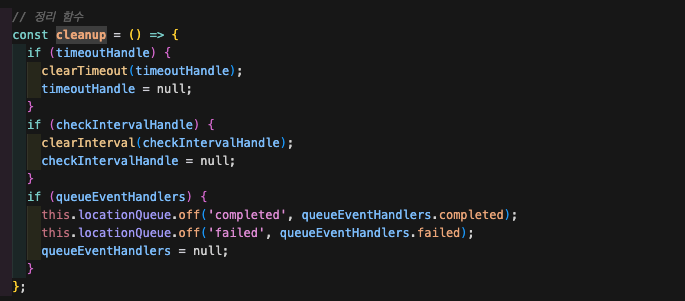
그리고 깔끔하게 finally에서 cleanup을 호출해 리스너들을 모두 해제해주자.
결과
로컬에서 실행
7,000 건의 User 데이터를 처리하는 경우
수정 전
- 작업 전

- 작업 시작 후

작업 전 메모리 사용량 110MB → 작업 시작 후 184MB (+74MB)

실행 전 %MEM 0.7 → 1.3
수정 후
- 작업 전

- 작업 시작 후

작업 전 메모리 사용량 107MB → 작업 시작 122MB (+15MB)
작업이 계속 진행되어도, 초기 메모리 사용량에서 크게 변동되지 않았다.

%MEM 변동 없음
결론
🎉 작업 처리 로직 메모리 사용량 79.73% 개선!
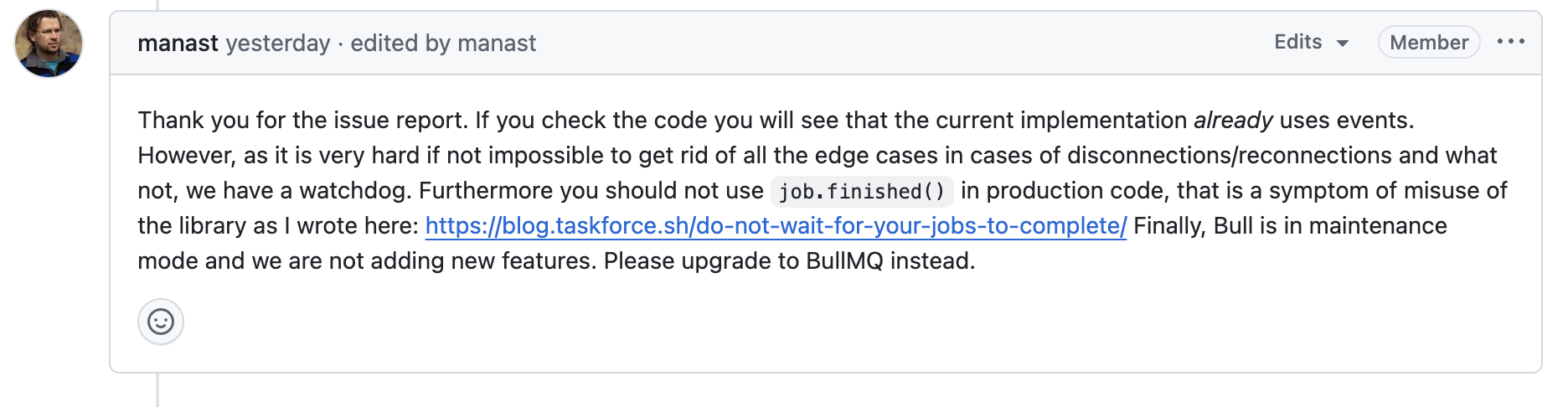
사실 Bull 사용에 있어서는 아래 내용을 참고해보면 좋다.
https://blog.taskforce.sh/do-not-wait-for-your-jobs-to-complete/
Bull은 비동기 백그라운드 처리를 위한 라이브러리이기 때문에, 기다리지 말라는 것이다.
사실 많은 IO 작업과 초당 작업 제한을 편리하게 관리할 수 있고, 여러 큐를 통한 확장성 때문에 장점이 있었지만,
전체 진행에 대한 모니터링이 필요했기 때문에 Bull 사용에 살짝 의문이 생겼던 부분이기도 하다.
+) Bull 개발자도 production에서 job.finished()는 사용하지 말라고 권고하고 있다.
결론
Node.js에서 이벤트를 사용한다면, 메모리 누수를 주의하자!
번외: 오픈소스 주석 수정해보기
코드 뜯어보다가 주석이 이상해서 작게나마 기여했다.. 하하