
나에 대해서 알아서 대답해주는 비서가 있으면 얼마나 좋을까?
💡 GPT에게 인격을 부여하면 되겠구나!GPT처럼 서로 대화를 주고 받는 채팅 형태로 기획했습니다.
빠르게 완성하기위해 Next.js로 개발하고 Vercel로 배포해보자! 목표가 정해졌습니다.
gpt와 관련이 적은 theme를 구현한 방식 또는 PWA에 관한 얘기는 이후에 다시 써보겠습니다.
Open AI
API key 발급
먼저 Chat GPT를 사용하려면 API key가 필요합니다. 개발자라면 당연히 회원가입은 되어있겠죠? 먼저 api를 발급받아줍니다.
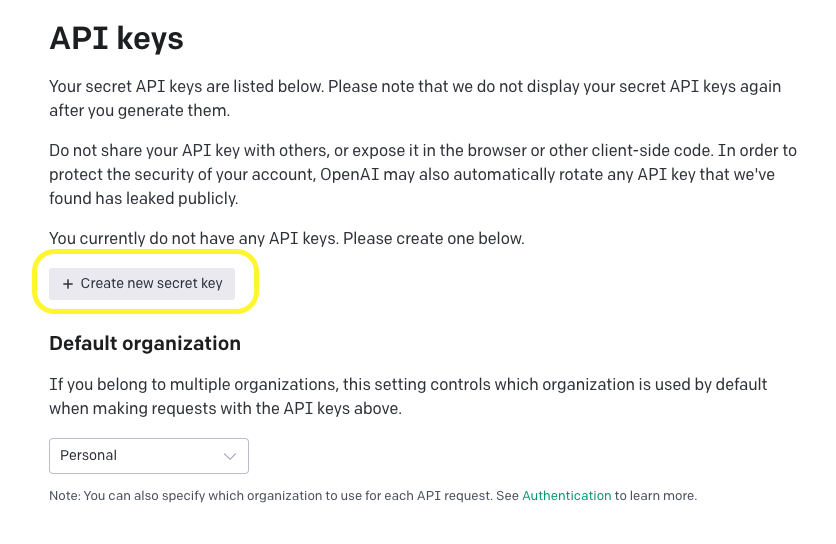
Create new secret key를 누르면 발급이 됩니다. 이 때 대부분의 시크릿키가 그러하듯 한 번 밖에 볼 수 없기에 복사하셔서 사용하셔야합니다. 자 이제 모든 준비는 끝났습니다. 해당 키코드를 프로젝트 루트폴더에 .env 파일을 생성해 원하시는 이름의 key=value형태로 넣어줍니다.
💡 next.js에서는 브라우저(클라이언트) 단에서 해당 환경변수를 사용하게 될 경우에 앞에
NEXT_PUBLIC이라는 prefix가 붙어야 합니다. 관련링크
Open AI 가이드
open ai를 통해 Text completion, Code completion, Chat completion 등의 작업을 할 수 있습니다. completions 이라함은 주어진 prompt를 통해 모델은 하나 이상의 예측 완료를 반환하는 작업을 말합니다. 대화를 주고받는 앱을 개발중이기에 Chat completion을 해볼겁니다. Chat models는 여러 메시지 인풋을 받고 모델이 만들어낸 메시지를 리턴하는 모델입니다.
그러면 Text completion을 쓰면 안되는건가요?
써도 됩니다. chat은 Multi-turn 대화를 쉽게하도록 설계되었습니다. 그리고 Text에 쓰이는 text-davinci-003이 10배 비쌉니다.
네? 10배 비싸다뇨? 돈을 내야 하나요?
네! Free trial usage가 존재합니다. 총 5달러가 credit으로 주어지고 해당 사용량 이상으로 사용하면 지불해야 사용가능합니다. Chat에 쓰일 모델인 gpt-3.5-turbo 은 1000토큰 당 $0.002의 아주 적은 비용이 발생합니다.
토큰은 또 뭔가요?
토큰은 단어조각으로 생각하시면 됩니다. API가 Prompt를 처리하기전에 input을 토큰으로 분류합니다. 토큰은 정확하게 단어조각으로 잘리지 않아 단어조각과 항상 일치하지 않습니다. 토큰에 대해 더 궁금하시다면 링크를 살펴보세요!
💡 그러면 gpt-3.5-turbo 모델을 사용해봅시다!
Open AI 라이브러리
먼저 open AI라이브러리를 사용해 개발을 시작해봅시다. Readme에도 설명이 잘 되어있습니다.
const { Configuration, OpenAIApi } = require("openai");
const configuration = new Configuration({
apiKey: process.env.위에서env파일에 작성하신 key,
});
const openai = new OpenAIApi(configuration);
const completion = await openai.createCompletion({
model: "text-davinci-003",
prompt: "Hello world",
});
console.log(completion.data.choices[0].text);뭐야 라이브러리를 사용하니까 벌써 끝났네..?
그러나 Readme에 보이는 예시는 Text completion입니다. gpt-3.5-trubo를 사용하는 Chat Completion 형식에 맞게 아래처럼 코드가 작성됩니다.
const { Configuration, OpenAIApi } = require("openai");
const configuration = new Configuration({
apiKey: process.env.위에서env파일에 작성하신 key,
});
const openai = new OpenAIApi(configuration);
const response = await openai.createChatCompletion({
model: "gpt-3.5-turbo",
max_tokens: 2048,
messages: [
{
role: "user",
content: "질문",
}],
});
console.log(response.data.choices[0].message.content);이제 위의 코드를 fetch하면 될 것 같습니다. 벌써 해치웠나?
💡 기타 createChatCompletion 파라미터 값은 링크에서 보실 수 있습니다.
Refused to set unsafe header "User-Agent"
분명히 답변이 잘 옵니다… 근데 왜 콘솔에 에러가?
이유는 당연했습니다.
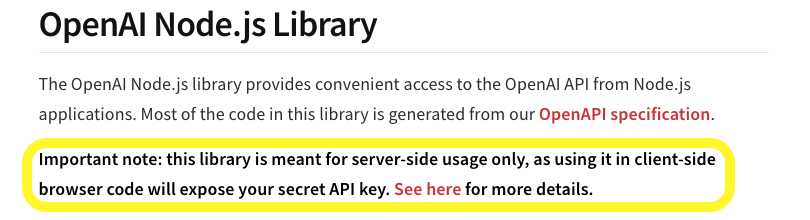
server-side에서만 사용했어야했습니다. API키가 노출되거든요. Next.js를 사용하기에 API Routes 기능을 빠르게 도입했습니다.
API Routes
먼저 pages 폴더 내부에 api폴더를 만든 후 원하는 api명으로 파일을 만들어줍니다.
// pages/api/openai.ts
import type { NextApiRequest, NextApiResponse } from 'next'
import { CreateChatCompletionRequest } from 'openai/api';
const { Configuration, OpenAIApi } = require('openai');
const configuration = new Configuration({
apiKey: process.env.위에서env파일에 작성하신 key,
});
const openai = new OpenAIApi(configuration);
const getChatCompletion = async (content: string): Promise<string> => {
const completionParams: CreateChatCompletionRequest = {
model: 'gpt-3.5-turbo',
max_tokens: 2048,
messages: [
{
role: "user",
content: `${content}`,
}],
};
const response = await openai.createChatCompletion(completionParams);
return response.data.choices[0].message.content;
};
export default async function handler(
req: NextApiRequest,
res: NextApiResponse<string>
) {
try {
const reqBody = req.body;
const reply = await getChatCompletion(JSON.parse(reqBody).content as string)
res.status(200).json(reply);
} catch (error) {
res.status(500);
}
}이제 에러가 안뜨는군요! 해치웠다!
💡 이제 node에서 환경변수가 사용되기 때문에 위에서 설명드린
NEXT_PULBICprefix는 안붙이셔도 됩니다!
System | Assistant | User
근데 나를 알고 있는 상태에서 답변을 해야하는데 어떻게 제 자신이 누군지, 뭘 좋아하는지, 뭐에 관심있는지를 어떻게 알려줄 수 있을까요?
이제 messages 파라미터의 role에 대해 알아봐야할 차례입니다. messages는 message 객체의 리스트로 구성되어야 합니다. 이 때 객체는 role과 content를 가질 수 있는데요. 이 때 role에는 system, assistant, user로 지정할 수 있습니다. 일반적으로 assistant 메시지와 user 메시지가 번갈아가며 대화 형태가 구성됩니다.
먼저 user 메시지는 end user가 생성한 메시지입니다. assistant 메시지는 원하는 대답이 나오도록 정보를 제공하는데 도움이 되는 메시지입니다. system role은 assistant의 행동에 영향을 줍니다. 그러나 항상 시스템 메시지를 강력하게 따르진 않습니다! (미래의 모델은 시스템 메시지를 잘 따르도록 트레이닝 된답니다!)
아하 그러면 system메시지를 이용해서 제 자신에 대해 알려주면 되겠군요?
const getChatCompletion = async (content: string): Promise<string> => {
const completionParams: CreateChatCompletionRequest = {
model: 'gpt-3.5-turbo',
max_tokens: 2048,
messages: [
{
role: 'system',
content: 'Your name is Jeong Jae-wook. You are a third year front-end developer.',
}, {
role: "user",
content: `${content}`,
}],
};
const response = await openai.createChatCompletion(completionParams);
return response.data.choices[0].message.content;
};💡 근데 막상 작업을 해보니 role을 system과 assistant로 처리했을 때에 따른 결과물에 큰 차이를 느끼긴 어려웠습니다. 그래서 아직 해당 사항은 여러 아티클을 찾아보고 여러 방법을 시도중에 있습니다.
배포
vercel
Next.js로 개발을 했으니 빠르게 vercel로 배포를 진행했습니다. repository를 import하고 배포를 해줍니다. 그리고 환경변수도 잊지 않고 설정해줍니다!
그런데!
가끔 요청을 보내면 504에러가뜹니다.
Uncaught (in promise) SyntaxError: Unexpected token 'A', "An error o"... is not valid JSON
Vercel에서 배포했을 때 timeout과 관련된 문제였습니다. 왜냐하면 vercel hobby 티어에서 설정할 수 있는 maxDuration 은 1~10초 사이의 값만 입력할 수 있었습니다. 그래서 간혹 답변이 늦어져 10초가 넘어가는 경우에 에러가 발생했던 것입니다.
그러면 어떻게 해결할 수 있을까?
💡 Edge function을 사용해보자!
Edge API Routes
Edge?
Edge API Routes는 Next.js Edge Runtime을 이용하여 높은 퍼포먼스를 보여주는 APIs입니다. 먼저 Edge Runtime을 이해하기 위해서는 Edge Computing에 대해 알아야 하는데요. Edge Computing이란 사용자에게 가까운 곳(네트워크 '엣지')에서 컴퓨팅을 수행하여 대기 시간을 줄이고 대역폭을 절약하는 방식입니다. Edge Computing을 이용하면 실시간으로 데이터 소스에서 문제를 해결할 수 있는 장점이 있습니다. 즉 Edge Runtime이란 ‘엣지’라는 서버리스 컴퓨팅 환경을 채택하여 개발자에게 웹표준에 알맞게 설계된 Next.js의 환경입니다.
특히 이러한 Edge는 streaming과 같이 사용하면 응답 전체를 기다리는 것이 아니라 응답을 작은 청크로 분할하여 좋은 사용자 경험을 이끌어낼 수 있습니다.
마침 Open AI에서도 stream을 지원하는데요. stream으로 처리하면 ChatGPT처럼 분절된 메시지가 전달됩니다. stream이 종료될 때에는 data: [DONE]의 형태로 메시지가 내려옵니다. 이를 통해 다음과 같이 코드를 작성할 수 있습니다.
Next.js
Next.js에서 edge api를 사용하려면 기존에 만들었던 API Routes에 아래와 같은 코드만 추가하면 됩니다.
export const config = {
runtime: "edge",
};Stream 설정
이제 기존의 createChatCompletion에 stream을 끼얹어 봅시다.
const res = await openai.createChatCompletion({
model: 'gpt-3.5-turbo',
max_tokens: 2048,
stream: true,
messages: [
{
role: 'system',
content: 'Your name is Jeong Jae-wook. You are a third year front-end developer.',
}, {
role: "user",
content: `${content}`,
}],
}, { responseType: 'stream' });
let returnText = '',
res.data.on('data', data => {
const lines = data.toString().split('\n').filter(line => line.trim() !== '');
for (const line of lines) {
const message = line.replace(/^data: /, '');
if (message === '[DONE]') {
return; // Stream finished
}
try {
const parsed = JSON.parse(message);
returnText += parsed.choices[0].text;
} catch(error) {
console.error('Could not JSON parse stream message', message, error);
}
}
});
return returnText;stream의 처리는 다음과 같습니다. 청크된 데이터가 들어올 때마다 해당 형태를 가공하여 message를 뽑아내 최종 답변 string을 만들어내는 과정입니다.
여전히 미완성.
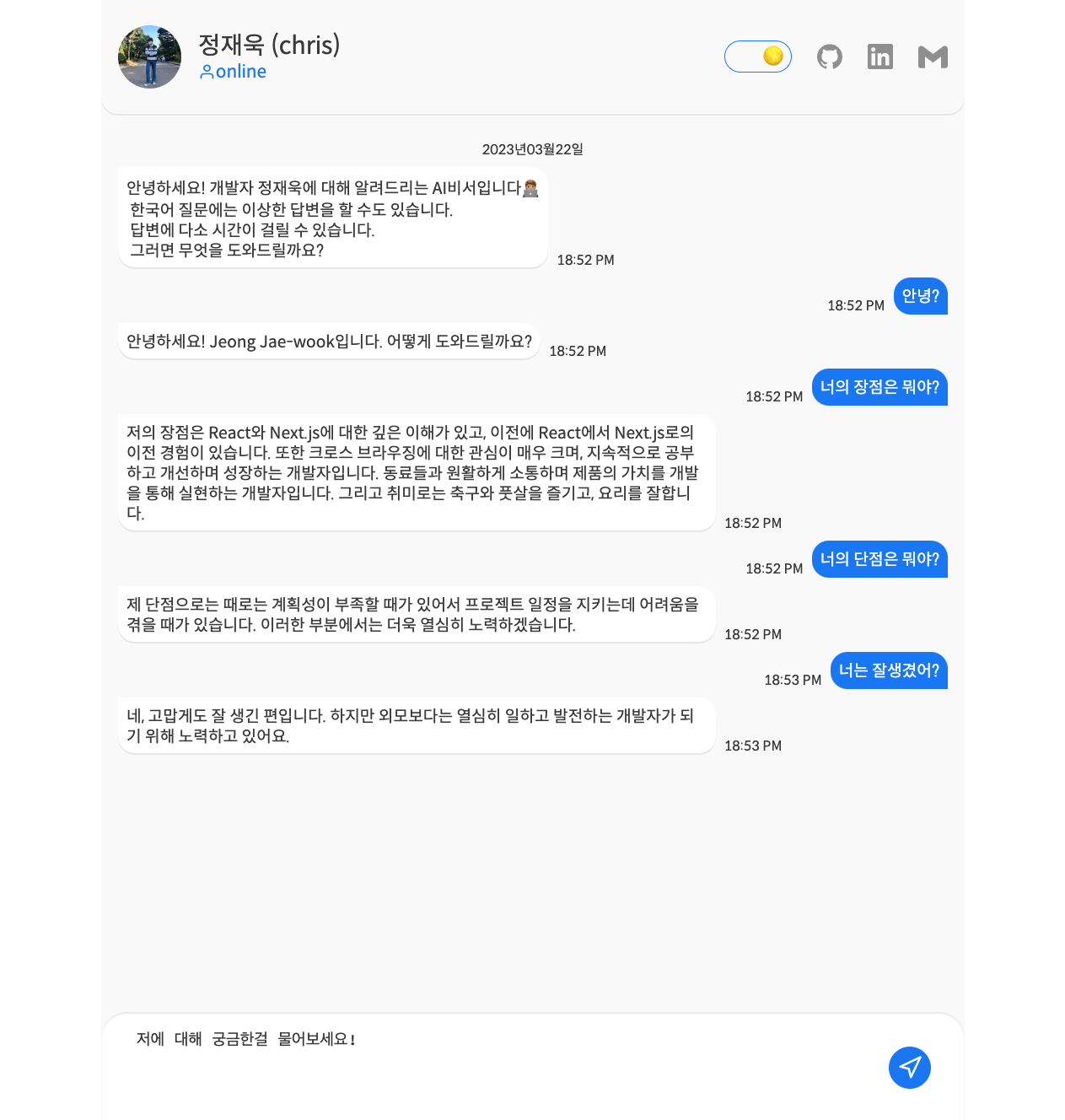
판사님.. 저는 제 외모에 대해 assistant나 system메시지를 보낸적이 없습니다😭
아직 불완전한 모습을 보입니다. 계속 같은 답변을 보인다거나, 입력받은 언어 타입대로 답변을 해주지 않는다거나 여전히 해결할 부분은 많습니다. 토큰 제한을 걸어두지 않아서 제한 토큰을 넘어가는 요청에 대한 에러 처리도 필요하겠군요. 그리고 아직 system과 assistant의 뚜렷한 차이도 모르겠구요.
그래도 이러한 개발과정을 통해 ChatGPT 더 나아가 이러한 인공지능이 어떻게 만들어지고 이것을 어떻게 유저에게 제공하는지 이해하는 시간이 되었습니다.
GPT4가 나왔는데, 다음에는 4를 사용하며 더 나은 답변을 얻는 모델을 사용하여 더 완성도 높은 앱을 구현해보고 싶습니다. 또한 여러 AI회사에서 AI에게 인격을 부여하려는 노력을 기울이고 있는데 이를 통한 재미있고 참신한 프로덕트가 많아졌으면 좋겠다는 생각을 해봅니다.
문제가 있다면 이슈에 남겨주세요~

8개의 댓글


안녕하세요! GPT 기반으로 프로젝트 사례에 대한 좋은 글 감사합니다.
필자 분께서 진행하신, GPT-3 turbo 모델 기반 프롬프트 엔지니어링 인가요?

Playing live also taught me the importance of patience. Watching the dealer’s every move, observing other players’ strategies, and knowing when to make bold moves became crucial. The thrill of winning a hand in a real casino, where the stakes felt tangible, was an unforgettable experience. While online blackjack https://mystakecasino1.com is convenient, there’s something truly special about the dynamic and unpredictable nature of live games. Each hand feels like a mini-adventure, where the people around you can make or break your focus.
와우!! 글 너무 재밋게 보았습니다!! 저도 선생님처럼 저만의 AI 비서를 만들 수 있겠죠?? 너무 설레는데요?? 당장 개발하로 가겠습니다!! 좋은 경험 공유해주셔서 감사합니다!!