15-445/645 Intro to Database Systems/Fall 2019 1강을 보고 정리한 내용입니다.
링크: https://www.youtube.com/watch?v=oeYBdghaIjc&list=PLSE8ODhjZXjbohkNBWQs_otTrBTrjyohi&index=1
1. 데이터베이스
Database란 현실 세계의 일부 측면을 서로 관련된 데이터로 표현한 모음이다. 이는 DBMS(database management systems)와 다른 것인데 DBMS는 데이터베이스를 관리하는 Oracle, MySQL, MongoDB와 같은 소프트웨어다. 앞으로의 설명을 위해 예시로 들 데이터베이스를 만들어본다. 우선, 현실 세계의 멜론과 같은 디지털 음악 가게를 데이터베이스로 만들기 위해 필요한 개념을 다음과 같이 정의한다.
- Artist
- Albums
2. Flat File Strawman
데이터베이스화할 현실 세계의 개념들을 정의했으므로 이제 저장할 차례다. 파일을 저장하는 방식으로 가장 먼저 떠오르는 형식은 엑셀 파일이다. 보다 간단한 csv 파일로 데이터를 저장해본다. 이때, 각 개념을 별도의 파일에 저장한다. 아래 그림에서 보면 artist와 album을 별도의 파일로 저장했음을 확인할 수 있다.

이런 형식으로 저장했을 때 아쉬운 점은 기록을 읽거나 업데이트하고 싶을 때마다 parsing 작업을 진행해야 한다는 것이다. 하나의 entity, 즉 객체는 여러가지 속성을 가지고 있는데 각 entity는 줄바꿈으로 나뉘고 각 속성은 쉼표로 나뉜다. Parsing 작업이 요구되는 이유가 여기에 있다.
아래 예시는 Ice Cube가 솔로로 활동하기 시작한 년도를 알아내는 구문이다.

3. Database Management System
DBMS는 데이터를 저장하고 분석하는 소프트웨어로, 데이터베이스의 정의, 생성, 쿼리 작성, 업데이트 및 등록을 해준다. 그런데 만약 위의 경우와 같이 매번 parsing 작업을 진행하는 것은 대용량 데이터를 관리 및 운영 또는 여러 사용자가 데이터를 공유하는데에 적합하지 않기 때문에 새로운 데이터 저장 방식이 등장했다.
초기의 DBMS는 논리 계층과 물리적 계층 간의 긴밀한 결합으로 인해 데이터베이스 애플리케이션을 구축하고 유지하기가 어려웠다. 논리 계층은 데이터베이스가 어떠한 entity와 속성을 가지고 있는지를 정의한다. 물리적 계층은 entity와 속성을 어떻게 저장하는지를 정한다. 초기의 DBMS가 물리적 계층을 애플리케이션 코드에서 정의했으므로 물리적 계층을 바꿀 때마다 코드를 새로 짜야 했다.
4. Relational Model
물리적 계층을 바꿀 때마다 DBMS를 바꾸는 작업을 방지하기 위해 나타난 데이터 모델 바로 Relation Model이다. Relational model의 3가지 주요 특징은 다음과 같다.
- 데이터베이스를 간단한 데이터 구조 및 관계로 표현한다.
- 데이터를 high-level 언어를 통해 접근한다.
- 물리적 계층에서의 저장은 구현 단계에서 해결하도록 한다. 즉, 일일이 코드를 작성하지 않는다.
잠시 중요한 개념들을 정리해본다.
데이터 모델
- 데이터베이스의 데이터를 설명하기 위한 개념들의 모음
예시) Relational model
데이터 모델은 RDBMS, NoSQL 등 여러가지 종류가 있지만 RDBMS를 위주로 정리할 것이다.

Relational model
- structure: Relation과 그 내용에들에 대한 정의. Relation들이 갖고 있는 속성들과 그 속성들이 가질 수 있는 값들
- integrity: 데이터베이스가 제약 조건들을 만족하고 있는지에 대한 보장
- manipulation: 데이터베이스의 내용에 대한 접근 및 수정
schema
- 데이터 모델이 주어졌을 때, 특정 개념들의 모음에 대한 설명
relation
- 정렬되지 않은 set으로 entity를 나타내는 속성들을 포함
- Relation들이 정렬되어 있지 않기 때문에 DBMS가 저장하고 싶은 대로 저장하여 최적화가 가능
N개의 column, 즉 속성을 가지고 있는 테이블을 n-ary relation이라고 한다. 다음 그림은 relational model의 예시로, 3-ary relation이다.
tuple
- 속성값들의 집합
- 참고로 모든 속성들은 NULL이 될 수 있는데, 해당 튜플에 대하여 속성이 정의되지 않았다는 뜻
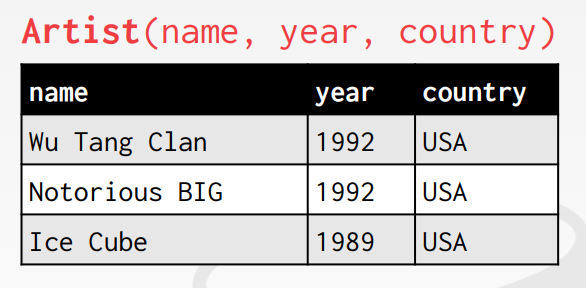
primary key: 하나의 튜플을 고유하게 정의
- 만일 직접 정의를 해주지 않으면 몇몇 DBMS들은 자동으로 primary key를 정의해준다. 이때, 많은 경우 자동으로 증가하는 키를 사용한다. MySQL에서의 AUTO_INCREMENT가 해당된다.
아래와 같은 테이블에서 primary key는 id 값이 된다.
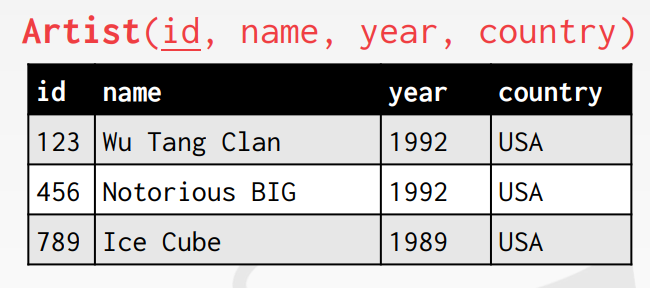
foreign key: 하나의 관계에서의 속성이 다른 관계에서의 속성에 매핑되도록 함
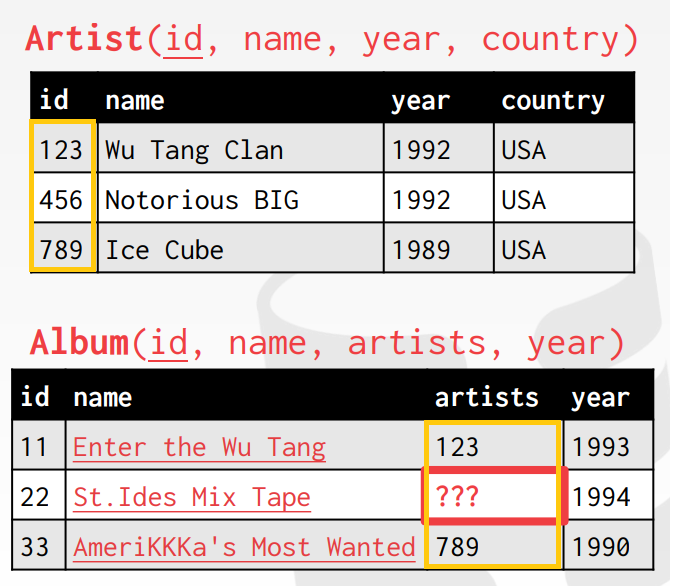
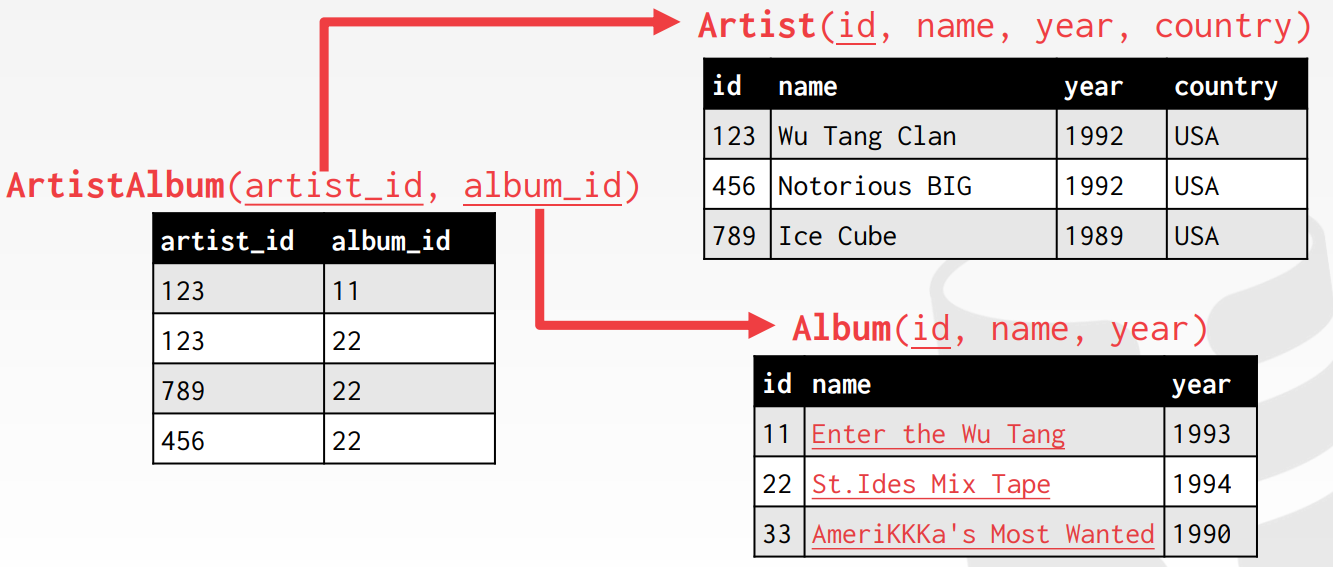
위와 같은 테이블에서 가수와 앨범을 매핑시켜줄 때 Artist 테이블의 id값이 foreign key다. 하지만 만약에 하나의 앨범에 여러 명의 가수를 매핑해야한다면 위와 단순히 id값을 foreign key로 지정해주기 곤란하다. 그 이유는 하나의 칼럼에 하나의 entity 당 하나의 값만 지정해줄 수 있기 때문이다. 따라서, 이 때는 아래 그림에서 볼 수 있듯이 새로운 테이블을 생성해서 join table로 쓰기도 한다.
5. Data Manipulation Languages(DMLs)
Data manipulation은 앞서 데이터베이스의 내용에 대한 접근 및 수정을 의미한다고 언급했었다. Data manipulation 언어에는 두 가지 카테고리가 있는데 다음과 같다.
Procedural
DBMS의 쿼리가 high-level 전략을 어떻게 써야할지를 정의해준다. Relational algebra가 여기에 해당된다.
Non-Procedural(Declaritive)
쿼리가 어떤 데이터를 원하는지에 대해서만 정의하고 어떻게 그 데이터를 찾는지에 대해선 구체화하지 않는다. SQL이 해당된다.
6. Relational Algebra
이번 강의에선 procedural 언어인 relational algebra를 설명하고 다음 강의에선 declaritive 언어인 SQL에 대해 자세히 다룬다.
Relational algebra는 relation에 있는 연산들을 반환하고 조작하는 기본 연산들의 집합이다. 각 연산자는 하나 또는 더 많은 relation을 입력으로 받고 새로운 relation을 출력한다. 쿼리를 쓸 때 연산자들을 chain함으로써 더 복잡한 연산을 작성할 수 있다.

6-1. Select

Select 연산은 relation을 입력받고 selection 속성을 나타내는 튜플의 부분 집합을 반환한다. 일종의 필터 역할을 하며 SQL의 WHERE 구문이 select 역할을 한다.
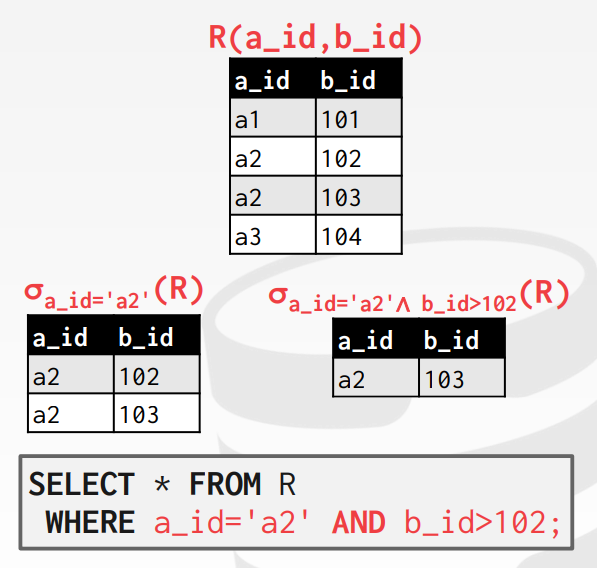
위의 테이블에서 a_id가 a2이고 b_id가 102보다 큰 조건을 만족하는 R 테이블의 부분 집합을 반환한다. 그 결과 a_id가 a2이고 b_id가 102인 entity 하나를 포함하는 테이블을 반환한다.
6-2. Projection

Projection 연산은 relation을 입력받고 지정된 속성만을 포함하는 튜플을 반환한다. 다시 말해서, 특정 칼럼만을 가져온 테이블을 만들 수 있으며 SQL의 SELECT 구문이 projection 역할을 한다. Relational algebra의 select 연산이 SELECT 구문과 같은 역할을 하는 것이 아님을 주의하자.

위의 테이블에서 a_id가 a2인 select 연산을 마친 후 R 테이블의 a_id과 b_id 칼럼에서 100을 빼준 칼럼을 선택한다.
6-3. Union
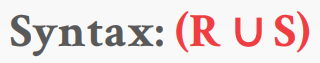
Union 연산은 두 개의 relation을 입력받아 해당 relation들에 나타나는 모든 튜플을 출력한다. 이때 주의할 점은 입력받는 두 개의 relation들은 정확히 같은 속성을 가지고 있어햐 한다는 점이다. SQL의 UNION ALL 구문이 union 역할을 한다.

R 테이블과 S 테이블을 union한 테이블을 보면 a3 103 entity가 중복으로 나타나는 것을 확인할 수 있다. 여기서 SQL이 키 값의 중복을 허용하기 떄문에 set이 아닌 multiset임을 알 수 있다.
6-4. Intersection
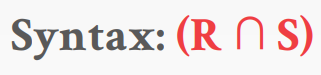
Intersection 연산은 두 개의 relation을 입력받아 해당 relation들에 동시에 나타나는 튜플을 출력한다. Intersection 역시 입력받는 두 개의 relation들은 정확히 같은 속성을 가지고 있어햐 한다. SQL의 INTERSECT 구문이 intersection 역할을 한다.

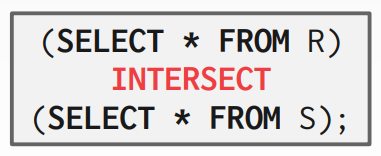
6-5. Difference
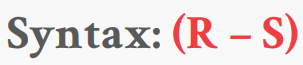
Difference 연산은 두 개의 relation을 입력받아 두 번째 relation에는 포함하되지 않지만 첫 번째 relation에 나타나는 모든 튜플을 포함하는 테이블을 출력한다. Intersection 역시 입력받는 두 개의 relation들은 정확히 같은 속성을 가지고 있어햐 한다. SQL의 EXCEPT 구문이 intersection 역할을 한다.


6-6. Product
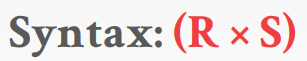
Product 연산은 두 개의 relation을 입력받아 튜플에 대해 가능한 모든 조합을을 출력한다. SQL의 CROSS JOIN 구문이 intersection 역할을 한다.
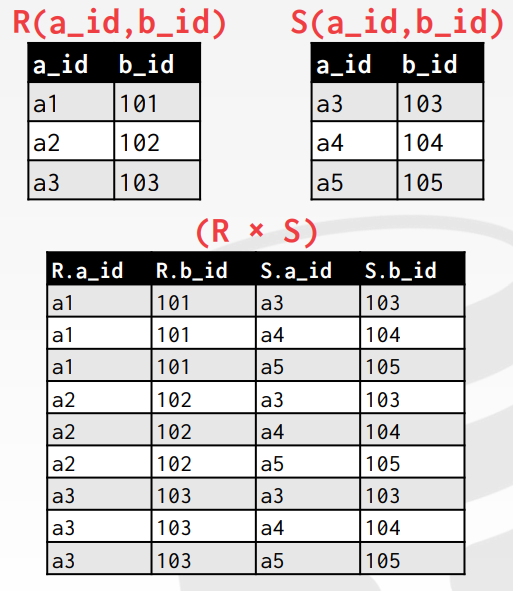

위의 테이블에서 볼 수 있듯이 각 속성이 어느 테이블에 속해있는지도 함께 나타낸다.
6-7. Join
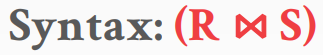
Join 연산은 두 개의 relation을 입력받아 튜플에 대해 가능한 모든 조합을 구한 후(product), key 값이 일치하는 튜플들을 필터링한 결과를 출력한다. SQL의 NATURAL JOIN 구문이 join 역할을 한다.

위의 R과 S를 intersection한 결과와 join한 결과가 같아서 헷갈린다. Intersection의 경우 두 개의 relation들은 정확히 같은 속성을 가져야하는 반면에, 테이블에선 공유되는 이름이 동일하지 않은 추가 속성이 있을 수 있다. 예를 들어서 R 테이블에만 c_id라는 속성이 있으면 은 빈 테이블이 되지만, 는 하나의 a3 entity를 갖는 테이블이 반환된다.
결과
Relational algebra는 procedural language로 순서에 따라 연산의 성능이 달라진다. 예를 들어 b_id의 수가 많다는 가정하에 와 의 속도를 비교해보면 가 현저히 빠를 것이다.
매번 어떤 연산이 더 효율적일지 직접 최적화를 하기보단 DBMS에 최적화를 맡기고 원하는 결과만 표현하는 declaritive language인 SQL이 더 좋은 접근 방식이다. 따라서, relational model에서 SQL을 주로 쓰고, 2강에선 SQL 에 대해 더 자세히 알아볼 것이다.
